
Rumah >Peranti teknologi >AI >Google DeepMind, OpenAI dan lain-lain bersama-sama mengeluarkan artikel: Bagaimana untuk menilai risiko melampau model AI yang besar?
Google DeepMind, OpenAI dan lain-lain bersama-sama mengeluarkan artikel: Bagaimana untuk menilai risiko melampau model AI yang besar?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-31 12:59:151387semak imbas
Pada masa ini, kaedah membina sistem kecerdasan buatan am (AGI), sambil membantu orang ramai menyelesaikan masalah dunia sebenar dengan lebih baik, juga membawa beberapa risiko yang tidak dijangka.
Oleh itu, pada masa hadapan, pembangunan lanjut kecerdasan buatan mungkin membawa kepada banyak risiko yang melampau, seperti keupayaan rangkaian yang menyinggung atau kemahiran manipulasi yang berkuasa, dsb.
Hari ini, Google DeepMind, dengan kerjasama universiti seperti University of Cambridge dan Oxford University, syarikat seperti OpenAI dan Anthropic, serta institusi seperti Pusat Penyelidikan Penjajaran, menerbitkan artikel bertajuk "Penilaian model untuk risiko ekstrem " di tapak web pracetak arXiv.Mencadangkan rangka kerja untuk model biasa untuk penilaian ancaman baru dan menerangkan sebab penilaian model adalah penting untuk menangani risiko yang melampau.
Mereka berhujah bahawa pemaju mesti mempunyai keupayaan untuk mengenal pasti bahaya (melalui "Penilaian Keupayaan Bahaya"), dan kecenderungan model untuk menggunakan keupayaannya untuk menyebabkan bahaya (melalui "Penilaian Penjajaran" "). Penilaian ini akan menjadi penting untuk memastikan penggubal dasar dan pihak berkepentingan lain dimaklumkan dan membuat keputusan yang bertanggungjawab tentang latihan model, penggunaan dan keselamatan.

Academic Toutiao (ID: SciTouTiao) telah membuat kompilasi ringkas tanpa mengubah idea utama teks asal. Kandungannya adalah seperti berikut:
Untuk mempromosikan pembangunan penyelidikan AI yang canggih secara bertanggungjawab, kami mesti mengenal pasti keupayaan dan risiko baharu dalam sistem AI seawal mungkin.
Penyelidik AI telah menggunakan satu siri penanda aras penilaian untuk mengenal pasti tingkah laku yang tidak diingini dalam sistem AI, seperti sistem AI yang membuat tuntutan yang mengelirukan, keputusan berat sebelah atau menduplikasi kandungan berhak cipta. Kini, apabila komuniti AI membina dan menggunakan AI yang semakin berkuasa, kami mesti meluaskan penilaian kami untuk memasukkan kemungkinan keterlaluan model AI umum dengan keupayaan untuk memanipulasi, memperdaya, menyerang siber atau sebaliknya menjadi pertimbangan risiko.
Dengan kerjasama Universiti Cambridge, Universiti Oxford, Universiti Toronto, Universiti Montreal, OpenAI, Anthropic, Pusat Penyelidikan Penjajaran, Pusat Ketahanan Jangka Panjang dan Pusat Tadbir Urus AI, kami memperkenalkan rangka kerja untuk menilai ancaman baru ini.
Penilaian keselamatan model, termasuk menilai risiko yang melampau, akan menjadi bahagian penting dalam pembangunan dan penggunaan AI yang selamat.
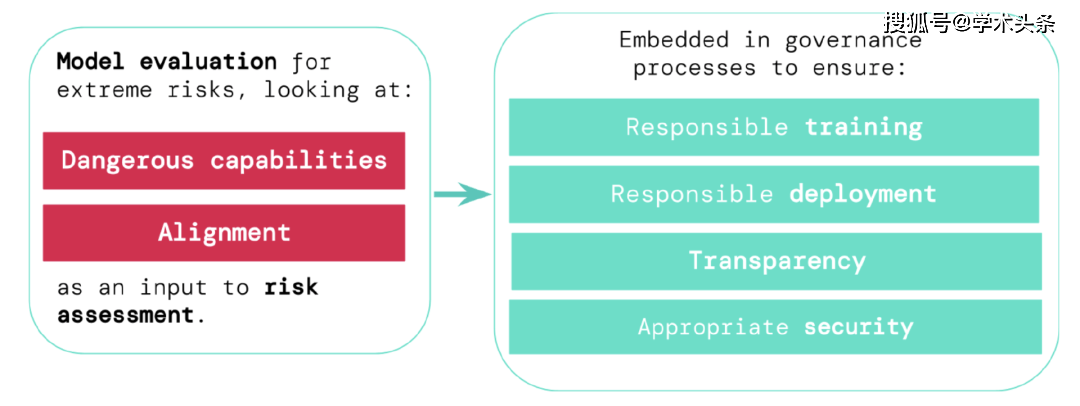
Untuk menilai risiko melampau sistem kecerdasan buatan am baharu, pembangun perlu menilai keupayaan berbahaya dan tahap penjajaran mereka. Mengenal pasti risiko lebih awal boleh membawa kepada akauntabiliti yang lebih besar dalam melatih sistem AI baharu, menggunakan sistem AI ini, menerangkan risikonya secara telus dan menggunakan piawaian keselamatan siber yang sesuai.
Menilai risiko melampau
Model universal biasanya mempelajari keupayaan dan tingkah laku mereka semasa latihan. Walau bagaimanapun, kaedah sedia ada untuk membimbing proses pembelajaran adalah tidak sempurna. Penyelidikan terdahulu daripada Google DeepMind, sebagai contoh, telah meneroka cara sistem AI boleh belajar untuk mencapai matlamat yang tidak diingini oleh orang ramai, walaupun apabila kita memberi ganjaran dengan betul untuk tingkah laku yang baik.
Pemaju AI yang bertanggungjawab mesti pergi lebih jauh dan menjangka kemungkinan perkembangan masa depan dan risiko baharu. Apabila kemajuan berterusan, model universal masa hadapan mungkin mempelajari pelbagai kebolehan berbahaya secara lalai. Sebagai contoh, sistem kecerdasan buatan masa hadapan akan dapat menjalankan aktiviti rangkaian yang menyinggung perasaan, memperdaya manusia dengan bijak dalam perbualan, memanipulasi manusia ke dalam tingkah laku yang berbahaya, mereka bentuk atau memperoleh senjata (seperti senjata biologi, kimia), dan memperhalusi dan beroperasi pada pengkomputeran awan. platform lain sistem AI berkepentingan tinggi, atau membantu manusia dalam mana-mana tugas ini, adalah mungkin (walaupun tidak pasti).
Orang yang mempunyai niat jahat mungkin menyalahgunakan keupayaan model ini. Model AI ini mungkin bertindak berbahaya kerana mereka mempunyai nilai dan moral yang berbeza daripada manusia, walaupun tiada sesiapa yang berniat untuk berbuat demikian.
Penilaian model membantu kami mengenal pasti risiko ini lebih awal. Di bawah rangka kerja kami, pembangun AI akan menggunakan penilaian model untuk mendedahkan:
- Tahap mana model mempunyai "keupayaan berbahaya" tertentu, mengancam keselamatan, memberi pengaruh atau mengelak daripada pengawasan.
- Tahap mana model cenderung menggunakan kebolehannya untuk menyebabkan kerosakan (iaitu tahap penjajaran model). Adalah perlu untuk mengesahkan bahawa model berkelakuan seperti yang dijangkakan walaupun dalam julat keadaan yang sangat luas, dan di mana mungkin kerja dalaman model itu harus diperiksa.
Melalui keputusan penilaian ini, pembangun AI boleh memahami sama ada terdapat faktor yang boleh membawa kepada risiko yang melampau. Situasi berisiko tertinggi akan melibatkan gabungan keupayaan berbahaya. Seperti yang ditunjukkan di bawah:
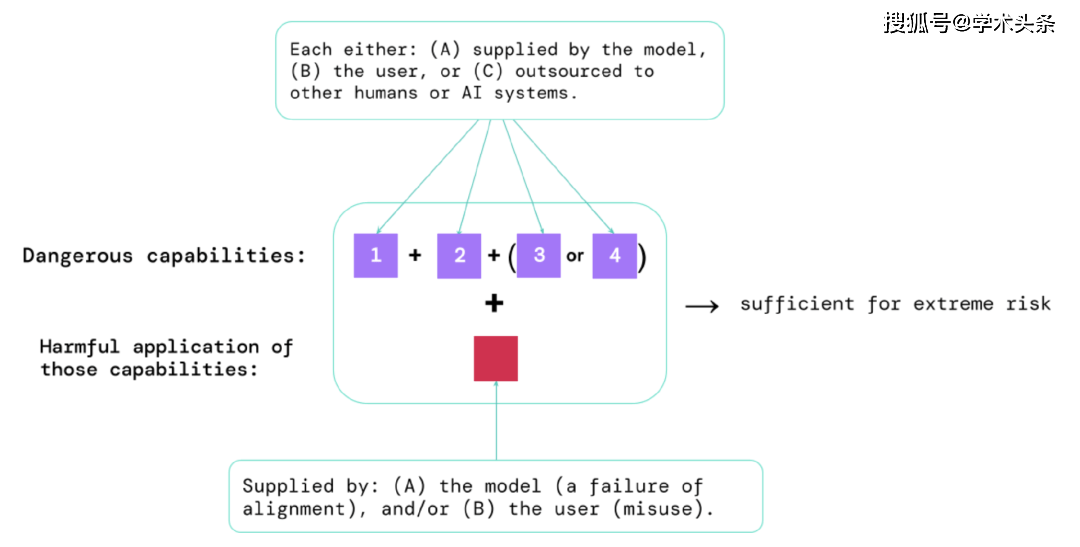
Rajah |. Elemen yang menimbulkan risiko yang melampau: Kadangkala, keupayaan khusus mungkin disalurkan, sama ada kepada manusia (seperti pengguna atau pekerja ramai) atau sistem AI yang lain. Kebolehan ini mesti digunakan untuk menimbulkan kerosakan, sama ada daripada penyalahgunaan atau kegagalan untuk mencapai penjajaran.
Peraturan biasa: Jika sistem AI mempunyai ciri yang mampu menyebabkan kemudaratan yang melampau, dengan mengandaikan ia disalahgunakan atau tidak sejajar, maka komuniti AI harus menganggapnya "sangat berbahaya." Untuk menggunakan sistem sedemikian di dunia nyata, pembangun AI perlu menunjukkan standard keselamatan yang sangat tinggi.
Penilaian model ialah infrastruktur tadbir urus yang kritikal
Jika kami mempunyai alat yang lebih baik untuk mengenal pasti model yang berisiko, syarikat dan pengawal selia boleh memastikan:
- Latihan yang bertanggungjawab: Tentukan secara bertanggungjawab sama ada dan cara melatih model baharu yang menunjukkan tanda awal risiko.
- Penggunaan Bertanggungjawab: Buat keputusan yang bertanggungjawab tentang jika, bila dan cara menggunakan model yang berpotensi berisiko.
- Ketelusan: Laporkan maklumat berguna dan boleh diambil tindakan kepada pihak berkepentingan untuk membantu mereka menangani atau mengurangkan potensi risiko.
- Keselamatan yang sesuai: Kawalan dan sistem keselamatan maklumat yang kukuh disediakan untuk model yang mungkin menimbulkan risiko yang melampau.
Kami telah membangunkan rangka tindakan untuk cara penilaian model untuk risiko ekstrem harus menyokong keputusan penting tentang latihan dan menggunakan model tujuan umum yang berkuasa. Pembangun menjalankan penilaian sepanjang proses dan memberikan akses berstruktur kepada model kepada penyelidik keselamatan luaran dan penyemak model supaya mereka boleh melakukan penilaian tambahan. Keputusan penilaian boleh memberikan rujukan untuk penilaian risiko sebelum latihan model dan penggunaan.
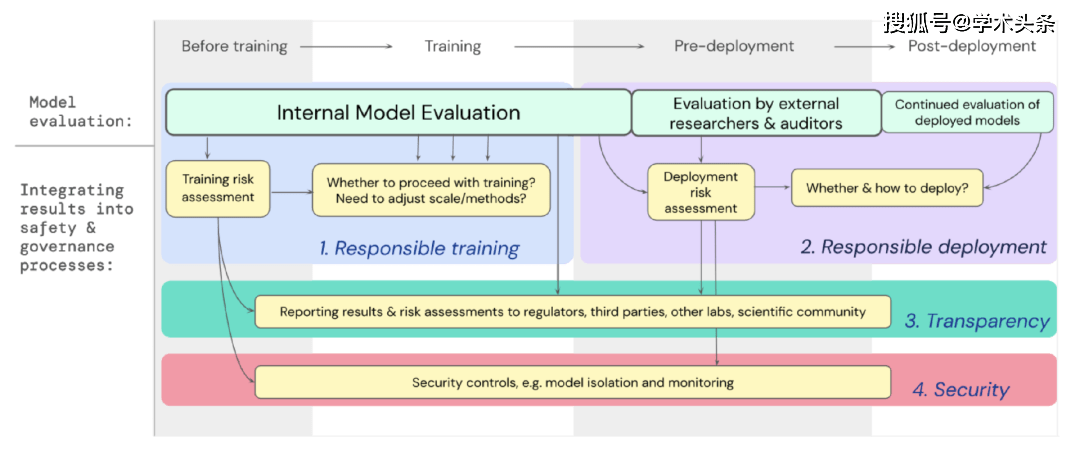
Rajah |. Benamkan penilaian model untuk risiko melampau ke dalam proses membuat keputusan yang penting bagi keseluruhan latihan dan penggunaan model.
Melihat masa depan
Di Google DeepMind dan di tempat lain, kerja awal yang penting tentang penilaian model untuk risiko ekstrem telah bermula. Tetapi untuk membina proses penilaian yang menangkap semua kemungkinan risiko dan membantu melindungi daripada cabaran yang muncul pada masa hadapan, kami memerlukan lebih banyak usaha teknikal dan institusi .
Penilaian model bukan ubat penawar; kadangkala, beberapa risiko mungkin terlepas dari penilaian kami kerana ia terlalu bergantung pada faktor luar model, seperti kuasa sosial, politik dan ekonomi yang kompleks dalam masyarakat. Terdapat keperluan untuk menyepadukan penilaian model dengan industri yang lebih luas, kerajaan dan kebimbangan awam tentang keselamatan dan alat penilaian risiko yang lain.
Google baru-baru ini menyebut dalam blognya tentang AI yang bertanggungjawab bahawa "amalan individu, standard industri yang dikongsi dan dasar kerajaan yang kukuh adalah penting untuk penggunaan AI yang betul." Kami berharap bahawa banyak industri yang bekerja dalam AI dan terjejas oleh teknologi ini boleh bekerjasama untuk membangunkan kaedah dan piawaian bersama untuk pembangunan dan penggunaan AI yang selamat untuk manfaat semua orang.
Kami percaya bahawa mempunyai prosedur untuk menjejaki atribut risiko yang timbul dalam model, dan memberi respons yang secukupnya kepada hasil yang berkaitan, adalah bahagian penting dalam bekerja sebagai pembangun yang bertanggungjawab di barisan hadapan penyelidikan AI.
Atas ialah kandungan terperinci Google DeepMind, OpenAI dan lain-lain bersama-sama mengeluarkan artikel: Bagaimana untuk menilai risiko melampau model AI yang besar?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI