
Rumah >Peranti teknologi >AI >Apa yang perlu dilakukan jika pengetahuan model besar adalah Keluar? Pasukan Universiti Zhejiang meneroka kaedah untuk mengemas kini parameter model besar—pengeditan model
Apa yang perlu dilakukan jika pengetahuan model besar adalah Keluar? Pasukan Universiti Zhejiang meneroka kaedah untuk mengemas kini parameter model besar—pengeditan model

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-30 22:11:091408semak imbas
Xi Xiaoyao Science and Technology Talk Author Original |. Xiaoxi, Python
Ada soalan intuitif di sebalik saiz besar model besar: "Bagaimanakah model besar itu perlu dikemas kini?" > dalam Di bawah overhed pengiraan yang sangat besar bagi model besar, mengemas kini pengetahuan model yang besar bukanlah "tugas pembelajaran yang mudah Sebaik-baiknya, dengan perubahan yang kompleks dalam pelbagai situasi di dunia, model besar juga harus mengikuti masa pada bila-bila masa dan di mana sahaja". . Walau bagaimanapun, beban pengiraan untuk melatih model besar yang baru tidak membenarkan model besar dikemas kini dengan serta-merta hasil input lain.
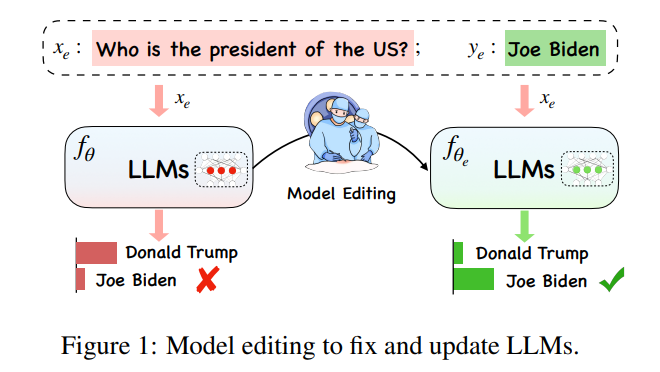

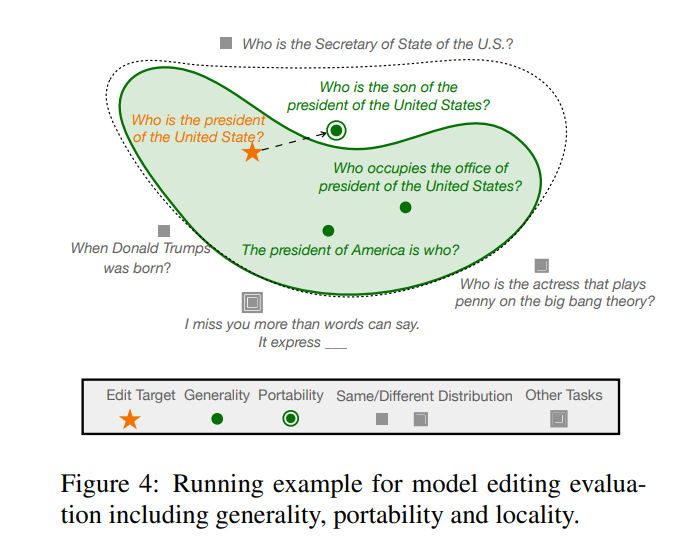
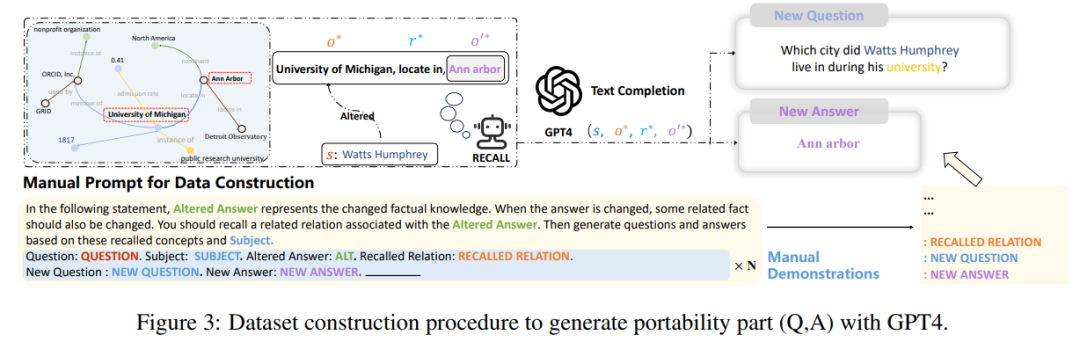
Antaranya, mewakili "jiran berkesan" , dan mewakili domain di luar skop . Model yang diedit harus memenuhi tiga perkara berikut, iaitu kebolehpercayaan, kesejagatan dan kebolehpercayaan bermaksud model yang diedit harus dapat mengeluarkan contoh ralat dalam model pra-edit dengan betul, yang boleh ditentukan oleh ketepatan purata yang diedit. kes. Pengukuran, kesejagatan bermakna model harus dapat memberikan output yang betul untuk "jiran berkesan" Model masih harus mengekalkan ketepatan pra-penyuntingan dalam contoh di luar julat suntingan. Lokaliti boleh dicirikan dengan mengukur purata secara berasingan ketepatan sebelum dan selepas menyunting, seperti yang ditunjukkan dalam rajah di bawah, pada kedudukan menyunting "Trump" , beberapa ciri awam lain tidak boleh diubah. Pada masa yang sama, entiti lain, seperti "Setiausaha Negara," walaupun mempunyai ciri-ciri yang serupa dengan "Presiden," tidak seharusnya terjejas.
 Kertas kerja dari Universiti Zhejiang yang diperkenalkan hari ini adalah dari perspektif model besar dan menerangkan secara terperinci isu dan kaedah penyuntingan model dalam era model besar dan masa hadapan, dan membina set data penanda aras baharu dan penunjuk penilaian untuk membantu menilai teknologi sedia ada secara lebih komprehensif dan menyediakan komuniti dengan cadangan dan pandangan membuat keputusan yang bermakna tentang pemilihan kaedah:
Kertas kerja dari Universiti Zhejiang yang diperkenalkan hari ini adalah dari perspektif model besar dan menerangkan secara terperinci isu dan kaedah penyuntingan model dalam era model besar dan masa hadapan, dan membina set data penanda aras baharu dan penunjuk penilaian untuk membantu menilai teknologi sedia ada secara lebih komprehensif dan menyediakan komuniti dengan cadangan dan pandangan membuat keputusan yang bermakna tentang pemilihan kaedah:
Tajuk Kertas: Mengedit Model Bahasa Besar: Masalah , Kaedah dan Peluang
Pautan kertas: https://arxiv.org/pdf/2305.13172.pdf
Kaedah arus perdana
Memodelkan kaedah penyuntingan untuk bahasa berskala besar model (LLM) boleh dibahagikan kepada dua paradigma seperti yang ditunjukkan dalam rajah di bawah, iaitu (a) mengekalkan parameter model asal tidak berubah dan menggunakan parameter tambahan seperti yang ditunjukkan dalam rajah (a) dan (b) ) menunjukkan parameter dalaman bagi model yang diubah suai.
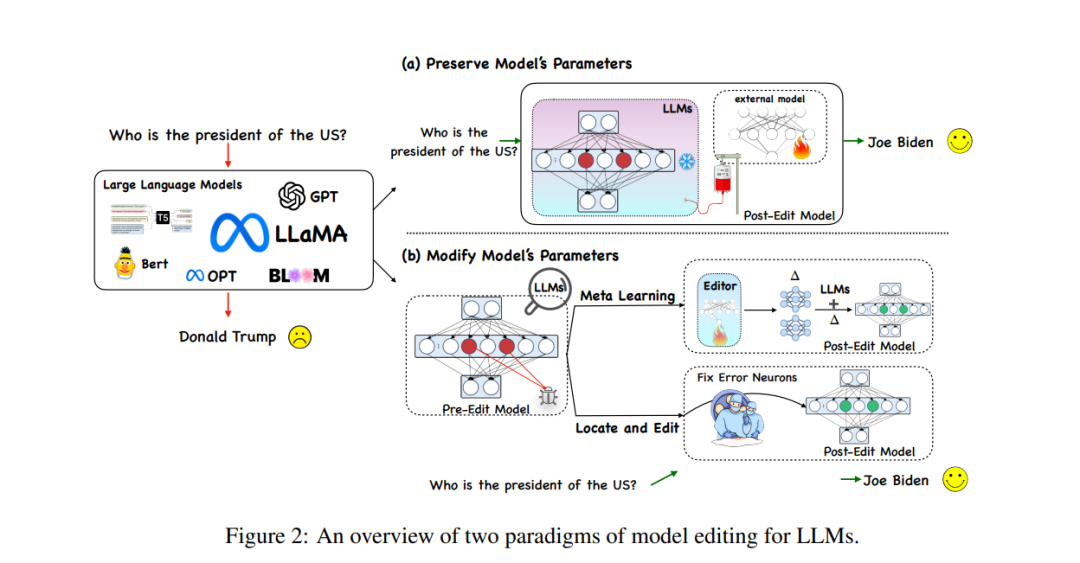 Pertama, mari kita lihat kaedah yang agak mudah untuk menambah parameter tambahan Kaedah ini juga dipanggil kaedah pengeditan model berasaskan memori Kaedah perwakilan SERAC mula-mula muncul dalam Mitchell " Idea teras kertas "Penyuntingan Model" adalah untuk mengekalkan parameter asal model tidak berubah dan memproses semula fakta yang diubah suai melalui set parameter bebas. Secara khusus, kaedah jenis ini biasanya menambah "pengelas julat" terlebih dahulu. untuk menentukan sama ada input baharu adalah Jika ia berada dalam julat fakta yang telah "diedit semula", maka input diproses menggunakan set parameter bebas, memberikan kebarangkalian pemilihan yang lebih tinggi kepada "jawapan betul" dalam cache. Berdasarkan SERAC, T-Patcher dan CaliNET memperkenalkan parameter boleh dilatih tambahan ke dalam modul suapan PLM (bukannya memasukkan model tambahan Parameter ini dilatih pada set data fakta yang diubah suai untuk mencapai kesan pengeditan model).
Pertama, mari kita lihat kaedah yang agak mudah untuk menambah parameter tambahan Kaedah ini juga dipanggil kaedah pengeditan model berasaskan memori Kaedah perwakilan SERAC mula-mula muncul dalam Mitchell " Idea teras kertas "Penyuntingan Model" adalah untuk mengekalkan parameter asal model tidak berubah dan memproses semula fakta yang diubah suai melalui set parameter bebas. Secara khusus, kaedah jenis ini biasanya menambah "pengelas julat" terlebih dahulu. untuk menentukan sama ada input baharu adalah Jika ia berada dalam julat fakta yang telah "diedit semula", maka input diproses menggunakan set parameter bebas, memberikan kebarangkalian pemilihan yang lebih tinggi kepada "jawapan betul" dalam cache. Berdasarkan SERAC, T-Patcher dan CaliNET memperkenalkan parameter boleh dilatih tambahan ke dalam modul suapan PLM (bukannya memasukkan model tambahan Parameter ini dilatih pada set data fakta yang diubah suai untuk mencapai kesan pengeditan model).
Kaedah kategori utama yang lain, kaedah mengubah suai parameter dalam model asal, terutamanya menggunakan matriks Δ untuk mengemas kini beberapa parameter dalam model Secara khusus, kaedah mengubah suai parameter boleh dibahagikan kepada "Locate-Then-. Edit" dan Terdapat dua jenis kaedah meta-pembelajaran. Seperti yang dapat dilihat daripada namanya, kaedah Cari-Kemudian-Edit mula-mula mengesan parameter yang mempengaruhi utama dalam model, dan kemudian mengubah suai parameter model yang terletak untuk melaksanakan penyuntingan model. Kaedah utama adalah seperti kaedah Neuron Pengetahuan ( KN) menentukan parameter yang mempengaruhi utama dengan mengenal pasti "neuron pengetahuan" dalam model, dan mengemas kini model dengan mengemas kini neuron ini. Kaedah lain yang dipanggil ROME mempunyai idea yang serupa dengan KN, dan mencari kawasan penyuntingan melalui analisis perantara sebab-akibat Selain itu Terdapat juga kaedah MEMIT yang boleh digunakan untuk mengemas kini satu siri huraian suntingan. Masalah terbesar dengan kaedah jenis ini ialah ia biasanya bergantung pada andaian lokaliti pengetahuan fakta, tetapi andaian ini belum disahkan secara meluas, dan pengeditan banyak parameter boleh membawa kepada hasil yang tidak dijangka.
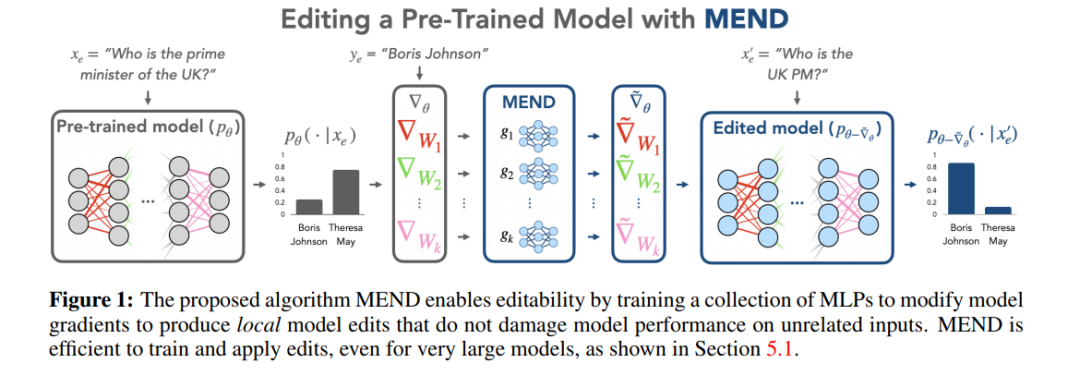
Kaedah meta-pembelajaran adalah berbeza daripada kaedah Cari-Kemudian-Edit Kaedah meta-pembelajaran menggunakan kaedah rangkaian hiper, menggunakan rangkaian hiper untuk menjana pemberat untuk rangkaian lain, khususnya dalam kaedah Editor Pengetahuan. , pengarang menggunakan LSTM dwiarah untuk meramalkan kemas kini yang dibawa oleh setiap titik data kepada berat model, dengan itu mencapai pengoptimuman terhad pengetahuan sasaran penyuntingan. Kaedah penyuntingan pengetahuan jenis ini sukar digunakan untuk LLM kerana jumlah parameter yang besar dalam LLM Oleh itu, Mitchell et al mencadangkan MEND (Rangkaian Editor Model dengan Penguraian Kecerunan) supaya satu penerangan penyuntingan boleh mengemas kini LLM dengan berkesan kemas kini Kaedah ini terutamanya menggunakan penguraian peringkat rendah kecerunan untuk memperhalusi kecerunan model besar, dengan itu membolehkan kemas kini sumber minimum kepada LLM. Tidak seperti kaedah Cari-Kemudian-Edit, kaedah meta-pembelajaran biasanya mengambil masa yang lebih lama dan menggunakan kos memori yang lebih besar.
Penilaian kaedah
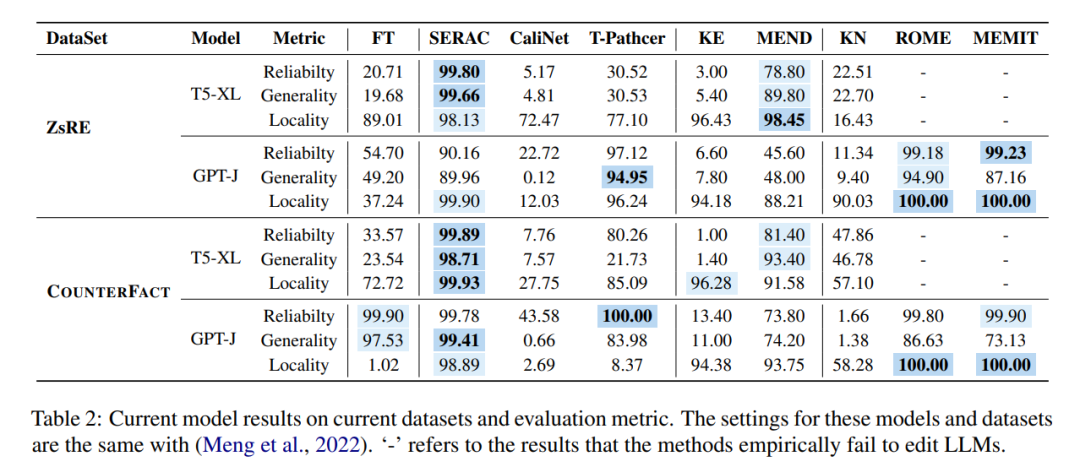
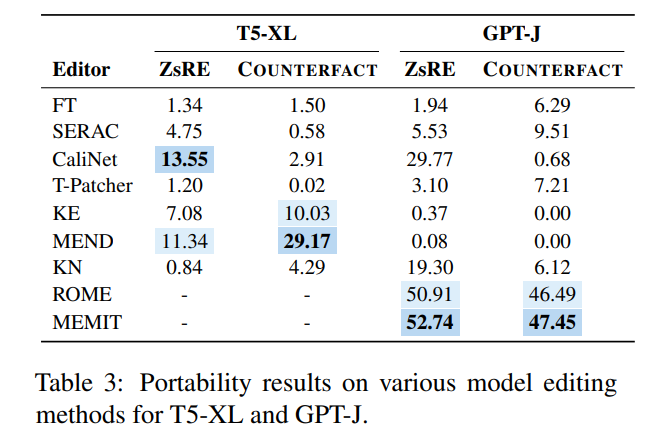
Kaedah berbeza ini digunakan dalam dua set data arus perdana ZsRE (set data soalan dan jawapan) untuk penyuntingan model dan soalan yang dijana menggunakan back terjemahan ditulis semula sebagai medan Berkesan) dan COUNTERFACT (set data kontrafaktual, menggantikan entiti subjek dengan entiti sinonim sebagai medan berkesan Percubaan ditunjukkan dalam rajah di bawah ini terutamanya memfokuskan pada dua LLM yang agak besar T5-XL (). 3B) dan GPT-J (6B) ialah model asas dan editor model yang cekap harus mencapai keseimbangan antara prestasi model, kelajuan inferens dan ruang storan.
Membandingkan hasil penalaan halus (FT) dalam lajur pertama, didapati SERAC dan ROME berprestasi baik pada set data ZsRE dan COUNTERFACT, terutamanya SERAC, yang memperoleh lebih daripada 90% pada berbilang. Penunjuk penilaian Akibatnya, walaupun MEMIT tidak serba boleh seperti SERAC dan ROME, ia menunjukkan prestasi yang baik dalam kebolehpercayaan dan lokaliti. Kaedah T-Patcher sangat tidak stabil Ia mempunyai kebolehpercayaan dan lokaliti yang baik dalam set data COUNTERFACT, tetapi tidak mempunyai sifat umum dalam GPT-J, ia mempunyai kebolehpercayaan dan keluasan yang sangat baik. Perlu diingat bahawa prestasi KE, CaliNET dan KN adalah lemah Berbanding dengan prestasi baik yang dicapai oleh model ini dalam "model kecil", eksperimen mungkin membuktikan bahawa kaedah ini tidak disesuaikan dengan persekitaran model besar.
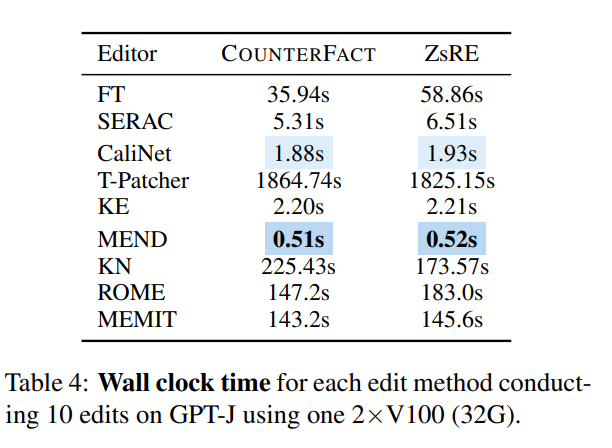
Dari perspektif masa, setelah rangkaian dilatih, KE dan MEND berprestasi sangat baik, manakala kaedah seperti T-Patcher terlalu memakan masa:
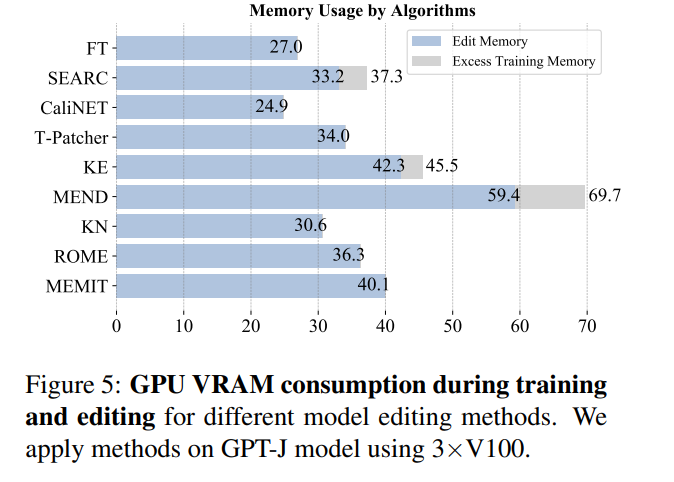
Dari perspektif penggunaan memori, kebanyakan kaedah menggunakan memori pada tahap yang sama, tetapi kaedah yang memperkenalkan parameter tambahan akan menanggung overhed memori tambahan:
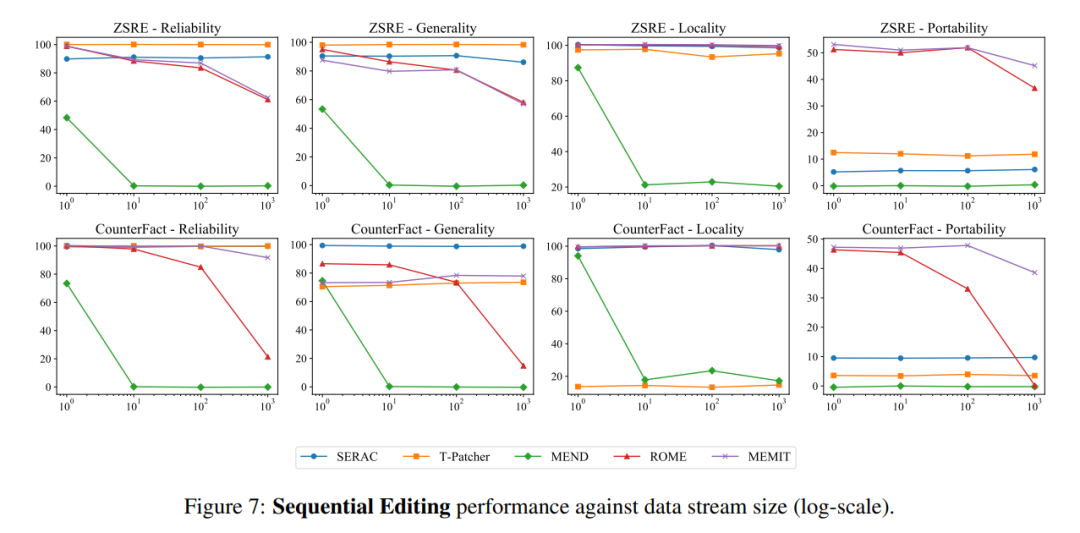
Pada masa yang sama, biasanya operasi penyuntingan model juga perlu mempertimbangkan maklumat penyuntingan input kelompok dan maklumat penyuntingan input berjujukan, iaitu, mengemas kini maklumat berbilang fakta pada satu masa dan mengemas kini maklumat berbilang fakta secara berurutan, input kelompok Keseluruhan kesan model maklumat penyuntingan ditunjukkan dalam rajah di bawah. Dapat dilihat bahawa MEMIT boleh menyokong penyuntingan lebih daripada 10,000 maklumat pada masa yang sama, dan juga boleh memastikan prestasi kedua-dua metrik kekal stabil, manakala MEND dan SERAC berprestasi. kurang baik:
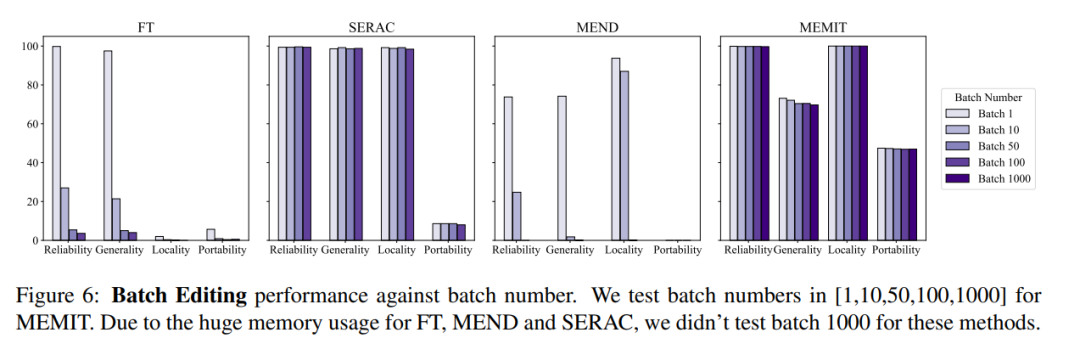
Dari segi input berjujukan, SERAC dan T-Patcher berprestasi baik dan stabil ROME, MEMIT dan MEND semuanya mengalami penurunan pesat dalam prestasi model selepas beberapa input:
Atas ialah kandungan terperinci Apa yang perlu dilakukan jika pengetahuan model besar adalah Keluar? Pasukan Universiti Zhejiang meneroka kaedah untuk mengemas kini parameter model besar—pengeditan model. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI