
Rumah >pangkalan data >Redis >Mengapa Redis begitu pantas?
Mengapa Redis begitu pantas?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-30 20:27:382885semak imbas
Redis ialah pangkalan data NoSQL berdasarkan pasangan nilai kunci Nilai Redis boleh terdiri daripada pelbagai struktur data dan algoritma seperti String, cincang, senarai, set, zset, Bitmaps, HyperLogLog, dll. Redis mempunyai banyak fungsi, seperti tamat tempoh kunci, menerbitkan dan melanggan, transaksi, skrip Lua, pengawal, Kluster, dsb.
Menurut data prestasi rasmi, Redis boleh melaksanakan arahan pada kelajuan yang sangat pantas, dan QPSnya boleh mencapai lebih daripada 100,000. Jadi artikel ini terutamanya memperkenalkan di mana Redis adalah pantas Perkara utama adalah seperti berikut:
1 Bahasa pembangunan
Sekarang kita semua menggunakan bahasa peringkat tinggi untuk. pengaturcaraan, seperti Java, python dll. Anda mungkin berfikir bahawa bahasa C adalah sangat lama, tetapi ia benar-benar berguna Lagipun, sistem Unix dilaksanakan dalam C, jadi bahasa C adalah bahasa yang sangat dekat dengan sistem pengendalian. Redis dibangunkan dalam bahasa C, jadi pelaksanaan akan lebih cepat.
Seperkara lagi, pelajar harus fokus pada pembelajaran bahasa C kerana ia membantu memahami sistem pengendalian komputer dengan lebih baik. Jangan fikir selepas belajar bahasa peringkat tinggi, anda tidak perlu memberi perhatian kepada lapisan bawah. Berikut ialah buku yang lebih sukar untuk dicadangkan, "Pemahaman Mendalam Sistem Pengkomputeran".
2. Akses memori tulen
Redis menggunakan memori untuk menyimpan semua data, jadi tidak perlu membaca data dari cakera untuk penyegerakan bukan data semasa operasi biasa, jadi Bilangan IO ialah 0. Masa tindak balas memori adalah kira-kira 100 nanosaat, yang merupakan asas penting untuk kelajuan pantas Redis. Mari kita lihat dahulu kelajuan CPU:
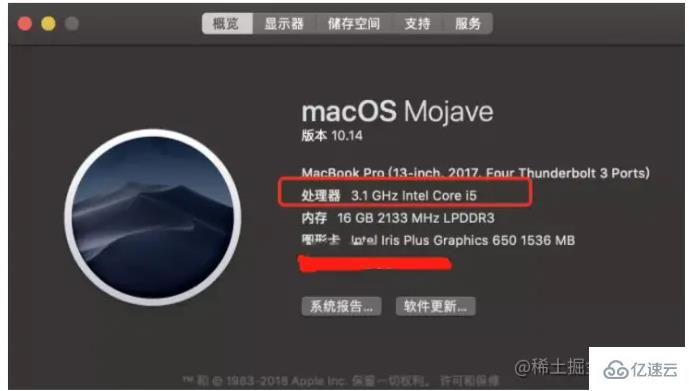
Mengambil komputer saya sebagai contoh, kekerapan utamanya ialah 3.1G, yang bermaksud ia boleh melaksanakan 3.1 bilion arahan sesaat. Kelajuan pemprosesan pandangan dunia CPU adalah sangat perlahan Sebagai perbandingan, memori adalah 100 kali lebih perlahan dan cakera adalah 1,000,000 kali lebih perlahan.
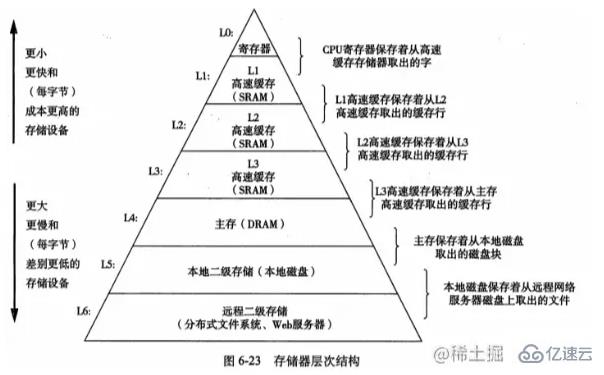
Saya meminjam gambar daripada "Pemahaman Mendalam Sistem Komputer", yang menunjukkan hierarki memori biasa Pada lapisan L0, CPU boleh mengaksesnya dalam satu kitaran jam, dan cache berasaskan SRAM diperbaharui. Mereka boleh diakses dalam beberapa kitaran jam CPU, dan kemudian memori utama berasaskan DRAM, yang boleh diakses dalam puluhan hingga ratusan kitaran jam.
3. Benang tunggal
Benang tunggal boleh memudahkan pelaksanaan algoritma, tetapi melaksanakan struktur data serentak bukan sahaja sukar tetapi juga sukar untuk diuji. Dalam pembangunan bahagian pelayan, kunci dan penukaran benang biasanya merupakan pembunuh prestasi, dan menggunakan satu utas boleh mengelakkan penggunaan yang mereka bawa. Sudah tentu, benang tunggal juga akan mempunyai kekurangannya, yang juga mimpi ngeri Redis: menyekat. Jika pelaksanaan perintah terlalu panjang, ia akan menyebabkan arahan lain disekat, yang sangat mematikan untuk Redis, jadi Redis ialah pangkalan data untuk senario pelaksanaan pantas.
Selain Redis, Node.js juga berbenang tunggal, dan Nginx juga berbenang tunggal, tetapi kedua-duanya adalah model pelayan berprestasi tinggi.
4. Mekanisme pemultipleksan I/O berbilang saluran yang tidak menyekat
Sebelum itu, mari kita bincangkan cara penyekatan tradisional I/O berfungsi: apabila menggunakan Apabila dibaca atau tulis membaca atau menulis deskriptor fail tertentu (File Descriptor FD), jika data tidak diterima, benang akan digantung sehingga data diterima.
Walaupun model penyekatan mudah difahami, ia tidak akan digunakan apabila berbilang tugasan pelanggan perlu diproses.
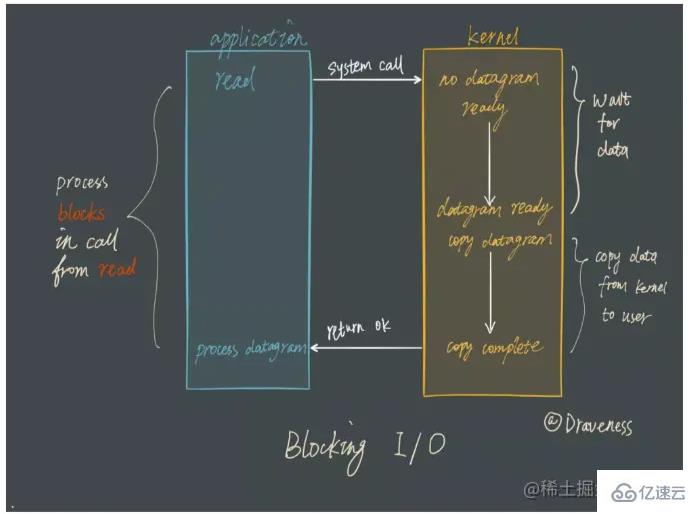
Pemultipleksan I/O sebenarnya bermakna pengurusan berbilang sambungan boleh berada dalam proses yang sama. Berbilang saluran merujuk kepada sambungan rangkaian, pemultipleksan hanyalah benang yang sama. Dalam perkhidmatan rangkaian, peranan pemultipleksan I/O adalah untuk memberitahu kod perniagaan tentang berbilang peristiwa sambungan pada satu masa Kaedah pemprosesan ditentukan oleh kod perniagaan.
Dalam model pemultipleksan I/O, panggilan fungsi yang paling penting ialah fungsi pemultipleksan I/O Kaedah ini boleh memantau pembacaan dan penulisan beberapa deskriptor fail (fd) pada masa yang sama fd boleh dibaca/boleh ditulis, kaedah ini akan mengembalikan bilangan fd boleh dibaca/ditulis.
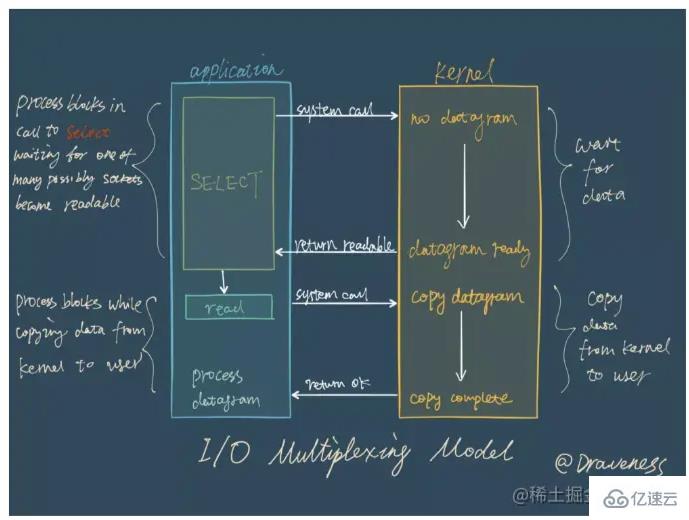
Redis menggunakan epoll sebagai pelaksanaan teknologi pemultipleksan I/O, dan model pemprosesan acara Redis sendiri menukar acara baca, tulis, tutup, dsb. epoll tanpa membuang terlalu banyak masa pada rangkaian I/O. Realisasikan pemantauan berbilang bacaan dan tulis FD untuk meningkatkan prestasi.
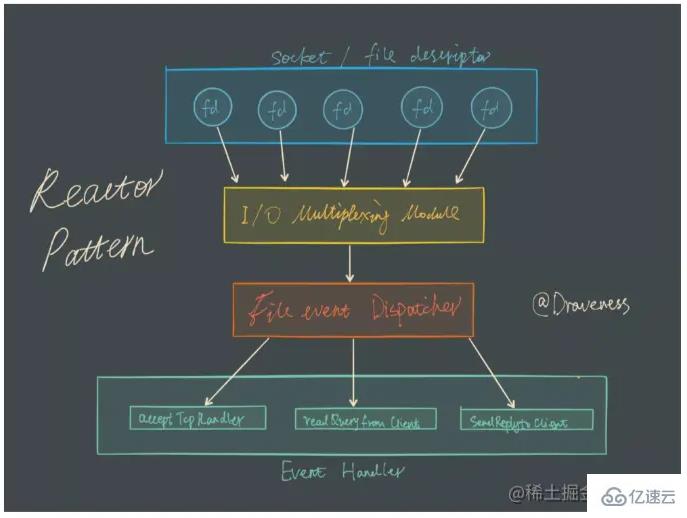
Mari kita berikan contoh yang jelas. Sebagai contoh, pelayan tcp mengendalikan 20 soket pelanggan.
Pelan A: Pemprosesan berurutan Jika soket pertama lambat membaca data disebabkan kad rangkaian, sebaik sahaja ia disekat, selebihnya akan menjadi kacau.
Pelan B: Buat sub-proses klon untuk setiap permintaan soket Apatah lagi setiap proses menggunakan banyak sumber sistem dengan hanya menukar proses sudah cukup untuk meletihkan sistem pengendalian.
Skim C (model pemultipleksan I/O, epoll): Daftarkan fd yang sepadan dengan soket pengguna ke dalam epoll (sebenarnya apa yang dihantar antara pelayan dan sistem pengendalian bukanlah fd soket tetapi struktur data fd_set ), dan kemudian epoll Hanya beritahu soket yang perlu dibaca/ditulis, dan hanya perlu memproses fd soket yang aktif dan berubah itu.
Dengan cara ini, keseluruhan proses hanya akan disekat apabila epoll dipanggil, dan penghantaran serta penerimaan mesej pelanggan tidak akan disekat.
Atas ialah kandungan terperinci Mengapa Redis begitu pantas?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!