
Rumah >Peranti teknologi >AI >40% lebih pantas daripada Transformer! Meta mengeluarkan model Megabait baharu untuk menyelesaikan masalah kehilangan kuasa pengkomputeran
40% lebih pantas daripada Transformer! Meta mengeluarkan model Megabait baharu untuk menyelesaikan masalah kehilangan kuasa pengkomputeran

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-30 20:04:581124semak imbas
Transformer sudah pasti model paling popular dalam bidang pembelajaran mesin sejak beberapa tahun lalu.
Sejak ia dicadangkan dalam kertas kerja "Perhatian Adalah Semua yang Anda Perlukan" pada tahun 2017, struktur rangkaian baharu ini telah meledak dalam tugas terjemahan utama dan mencipta banyak rekod baharu.
Tetapi Transformer mempunyai kecacatan apabila memproses jujukan bait panjang, iaitu kuasa pengkomputeran hilang dengan serius, dan Meta Keputusan terkini penyelidik dapat menyelesaikan kekurangan ini dengan baik.
Mereka telah melancarkan seni bina model baharu yang boleh menjana lebih daripada 1 juta token merentasi pelbagai format dan mengatasi keupayaan seni bina Transformer sedia ada di sebalik model seperti GPT-4.
Model ini dipanggil "Megabait" dan merupakan seni bina penyahkod berbilang skala yang boleh memproses lebih daripada satu juta bait Urutannya ialah pemodelan boleh dibezakan hujung ke hujung.

Pautan kertas: https://arxiv.org/abs/2305.07185
Mengapa Megabait lebih baik daripada Transformer Anda mesti melihat dahulu kekurangan Transformer.
Kelemahan Transformer
Setakat ini, beberapa jenis model AI generatif berprestasi tinggi, seperti GPT-4 OpenAI dan Bard Google, semuanya berdasarkan Transformer Model seni bina.
Tetapi pasukan penyelidik Meta percaya bahawa seni bina Transformer yang popular mungkin mencapai ambangnya, dengan sebab utamanya ialah dua kelemahan penting yang wujud dalam reka bentuk Transformer:
- Apabila panjang bait input dan output meningkat, kos perhatian diri juga meningkat dengan cepat, seperti muzik input, fail imej atau video biasanya mengandungi beberapa megabait, walau bagaimanapun penyahkod besar (LLM) biasanya hanya menggunakan beberapa ribu token kontekstual
- Rangkaian suapan hadapan membantu model bahasa memahami dan memproses perkataan melalui satu siri operasi dan transformasi matematik, tetapi sukar untuk skala pada sifat asas setiap kedudukan, rangkaian ini beroperasi pada kumpulan watak atau kedudukan secara bebas, menghasilkan jumlah overhed pengiraan yang besar
Apakah kekuatan Megabait
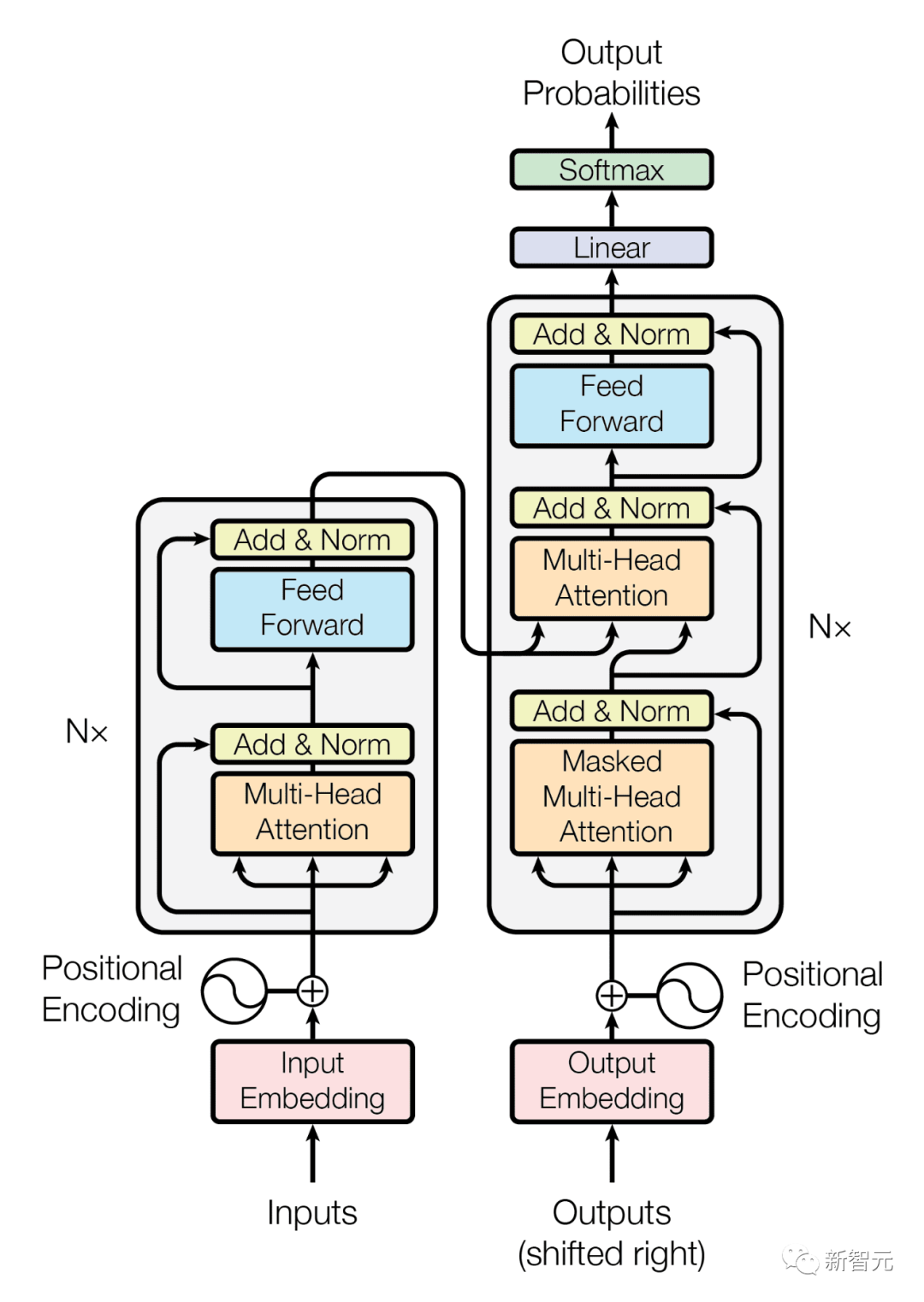
Berbanding dengan Transformer, model Megabait menunjukkan seni bina yang berbeza secara unik yang membahagikan urutan input dan output kepada tampalan dan bukannya token individu.
Seperti yang ditunjukkan di bawah, dalam setiap tampung, model AI tempatan menjana hasil, manakala model global mengurus dan menyelaras keluaran akhir semua tampung.
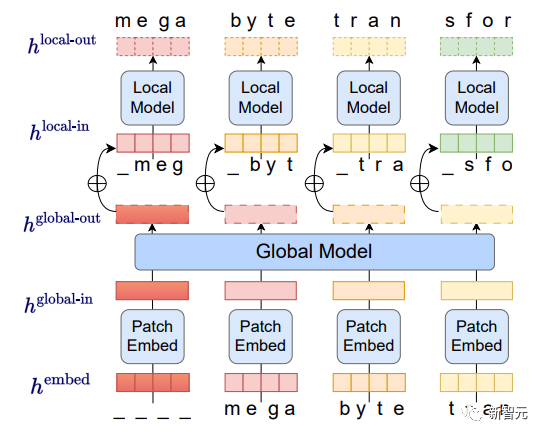
Pertama, jujukan bait dibahagikan kepada tampung bersaiz tetap, kira-kira serupa dengan token Model ini terdiri daripada tiga bahagian Komposisi:
(1) pembenam tampalan: hanya kodkan tampung
(2) Model global: pengubah autoregresif besar yang mewakili patch input dan output
(3) Model tempatan: model autoregresif kecil yang meramalkan bait dalam patch
Para penyelidik memerhatikan bahawa ramalan bait adalah agak mudah untuk kebanyakan tugas (seperti melengkapkan perkataan yang diberikan beberapa aksara pertama), yang bermaksud bahawa setiap perkataan Rangkaian simpulan yang besar tidak diperlukan dan model yang lebih kecil boleh digunakan untuk ramalan dalaman.
Pendekatan ini menyelesaikan cabaran kebolehskalaan yang lazim dalam model AI hari ini Sistem tampalan model Megabyte membolehkan satu rangkaian suapan ke hadapan untuk dijalankan pada tampung yang mengandungi berbilang token, dengan berkesan menyelesaikan masalah Penskalaan kendiri.
Antaranya, seni bina Megabait telah membuat tiga penambahbaikan utama pada Transformer untuk pemodelan jujukan panjang:
- Perhatian Kendiri Kuadratik (Sub -perhatian diri kuadratik)
Kebanyakan kerja pada model jujukan panjang telah menumpukan pada mengurangkan kos kuadratik perhatian diri, manakala Megabait menguraikan jujukan panjang kepada dua jujukan lebih pendek yang masih mudah untuk mengendalikan walaupun untuk urutan yang panjang.
- Lapisan suapan hadapan setiap tampung
Lebih 98% FLOPS dalam model bersaiz GPT-3 Untuk mengira lapisan suapan hadapan kedudukan, Megabait menggunakan suapan hadapan yang besar lapisan setiap tampalan untuk mencapai model yang lebih besar dan lebih berprestasi pada kos yang sama. Dengan saiz tampung P, penukar garis dasar akan menggunakan lapisan suapan hadapan yang sama dengan parameter m P kali dan Megabait boleh menggunakan lapisan dengan parameter mP sekali pada kos yang sama.
- Paralelisme dalam Penyahkodan
Transformer mesti melakukan semua pengiraan secara bersiri semasa penjanaan kerana setiap kali Input kepada langkah adalah output dari sebelumnya langkah masa, dan dengan menjana perwakilan tampalan secara selari, Megabait membolehkan paralelisme yang lebih besar dalam proses penjanaan.
Sebagai contoh, model Megabait dengan parameter 1.5B menjana jujukan 40% lebih pantas daripada 350MTransformer standard, di samping menambah baik kebingungan apabila menggunakan jumlah pengiraan yang sama untuk latihan.
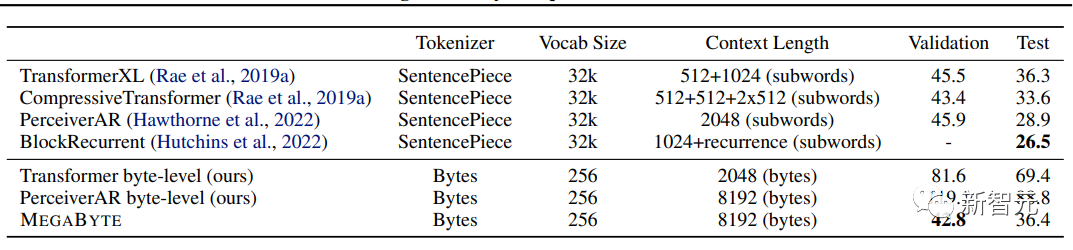
Megabait jauh mengatasi model lain dan memberikan hasil yang berdaya saing dengan model sota yang dilatih pada subkata
Dalam perbandingan, GPT-4 OpenAI mempunyai had 32,000 token, dan Claude Anthropic mempunyai had 100,000 token.
Selain itu, dari segi kecekapan pengiraan, dalam saiz model tetap dan julat panjang jujukan, Megabait menggunakan lebih sedikit token daripada Transformers dan Linear Transformer dengan saiz yang sama, membenarkan kos pengiraan yang sama Gunakan model yang lebih besar.
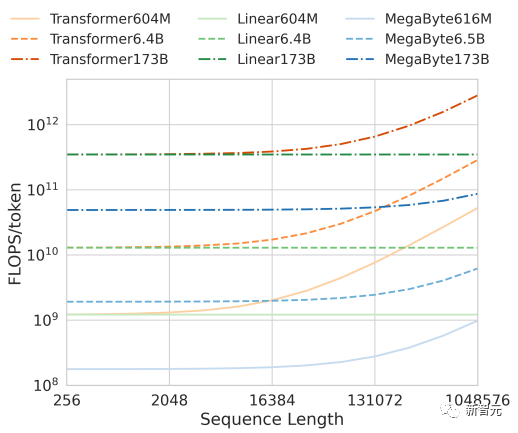
Bersama-sama, peningkatan ini membolehkan kami berlatih di bawah belanjawan pengiraan yang sama Lebih besar , model berprestasi lebih baik yang menskalakan kepada jujukan yang sangat panjang dan meningkatkan kelajuan binaan semasa penggunaan.
Apakah rupa masa hadapan
Dengan perlumbaan senjata AI secara rancak, prestasi model semakin kukuh dan parameter semakin tinggi dan lebih tinggi.
Walaupun GPT-3.5 dilatih pada parameter 175B, terdapat spekulasi bahawa GPT-4 yang lebih berkuasa telah dilatih pada 1 trilion parameter.
Ketua Pegawai Eksekutif OpenAI Sam Altman juga baru-baru ini mencadangkan perubahan dalam strategi Beliau berkata bahawa syarikat sedang mempertimbangkan untuk meninggalkan latihan model besar dan menumpukan pada pengoptimuman prestasi lain.
Dia menyamakan masa depan model AI dengan cip iPhone, manakala kebanyakan pengguna tidak tahu tentang spesifikasi teknikal asal.
Penyelidik meta percaya seni bina inovatif mereka datang pada masa yang sesuai, tetapi mengakui terdapat cara lain untuk mengoptimumkan.
Contohnya, model pengekod yang lebih cekap menggunakan teknologi tampalan, model penyahkodan yang menguraikan jujukan kepada blok yang lebih kecil dan pramemproses jujukan menjadi token termampat, dsb., dan boleh melanjutkan keupayaan Transformer Architectural sedia ada untuk membina model generasi akan datang.
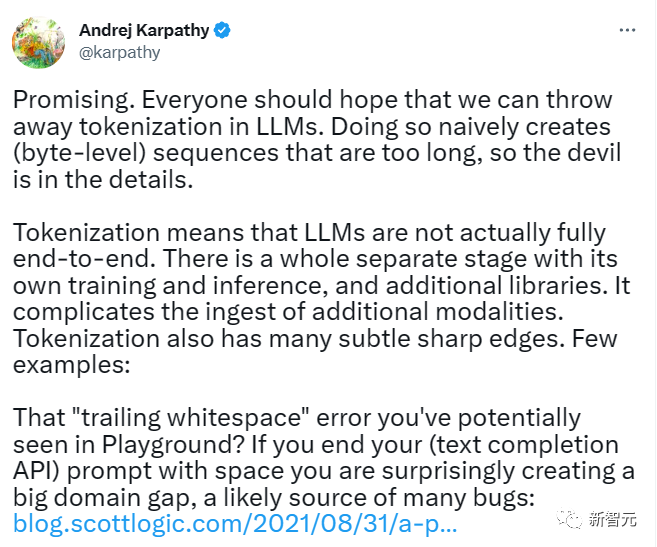
Bekas pengarah Tesla AI Andrej Karpathy turut menyatakan pandangannya mengenai kertas ini Dia menulis di Twitter:
Ini sangat menjanjikan dan semua orang seharusnya berharap kami boleh membuang tokenisasi dalam model besar dan menghapuskan keperluan untuk jujukan bait yang terlalu panjang itu.
Atas ialah kandungan terperinci 40% lebih pantas daripada Transformer! Meta mengeluarkan model Megabait baharu untuk menyelesaikan masalah kehilangan kuasa pengkomputeran. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI