
Rumah >Peranti teknologi >AI >Sepuluh minit untuk memahami logik teknikal dan evolusi ChatGPT (kehidupan lalu, kehidupan sekarang)
Sepuluh minit untuk memahami logik teknikal dan evolusi ChatGPT (kehidupan lalu, kehidupan sekarang)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-30 15:00:081419semak imbas
0. Kata Pengantar
Pada 30 November, OpenAI melancarkan chatbot AI yang dipanggil ChatGPT, yang boleh diuji oleh orang ramai secara percuma di seluruh rangkaian hanya dalam beberapa hari.
Berdasarkan pelbagai promosi pada tajuk berita dan akaun awam, ia bukan sahaja boleh menulis kod dan menyemak pepijat, tetapi juga menulis novel dan perancangan permainan, termasuk menulis aplikasi ke sekolah, dsb. Ia nampaknya mampu melakukan segala-galanya .
Dalam semangat sains (baik) dan pembelajaran (hebat), saya mengambil sedikit masa untuk menguji dan mengesahkan ChatGPT, dan **menyelesaikan mengapa ChatGPT begitu "kuat"**.
Memandangkan penulis tidak mempelajari AI secara profesional dan mempunyai tenaga yang terhad, tidak akan ada bab teknikal yang lebih mendalam seperti AI-003 dalam masa yang singkat dalam skop jisim tembikai.
Terdapat banyak istilah teknikal dalam artikel ini, dan saya akan cuba mengurangkan kesukaran untuk memahaminya.
Pada masa yang sama, memandangkan saya bukan profesional AI, sila nyatakan sebarang ralat atau ketinggalan.
Penghargaan: Saya sangat berterima kasih kepada Encik X dan Encik Z atas ulasan mereka, terutamanya kepada Encik. Terdapat dua perkataan di dalamnya, satu ialah Chat, yang bermaksud anda boleh bercakap. Perkataan lain ialah GPT.
Nama penuh GPT ialah Generative Pre-Trained Transformer (model Transformer pra-latihan generatif).
Anda boleh melihat sejumlah 3 perkataan di dalamnya, Generatif, Pra-Terlatih dan Transformer.
Sesetengah pembaca mungkin menyedari bahawa saya tidak menterjemah Transformer ke dalam bahasa Cina di atas.
Sebab Transformer adalah istilah teknikal, jika diterjemahkan dengan keras, ia adalah transformer. Tetapi mudah untuk kehilangan makna asal, jadi lebih baik tidak menterjemahkannya.
Transformer akan diterangkan dalam Bab 3 di bawah.
2. Garis masa evolusi teknologi GPT
Sejarah pembangunan GPT dari penubuhannya hingga kini adalah seperti berikut:
Pada bulan Jun 2017, Google menerbitkan kertas kerja "Perhatian adalah untuk anda semua need" 》, mula-mula mencadangkan model Transformer, yang menjadi asas kepada pembangunan GPT. Alamat kertas: https://arxiv.org/abs/1706.03762
Pada bulan Jun 2018, OpenAI mengeluarkan kertas kerja "Meningkatkan Pemahaman Bahasa melalui Pra-Latihan Generatif" (Meningkatkan pemahaman bahasa melalui pra-latihan generatif) , mencadangkan model GPT (Generative Pra-Training) buat kali pertama. Alamat kertas: https://paperswithcode.com/method/gpt.
Pada Februari 2019, OpenAI mengeluarkan kertas kerja "Model Bahasa ialah Pelajar Berbilang Tugas Tanpa Diawasi" (model bahasa hendaklah pelajar berbilang tugas tanpa diawasi) dan mencadangkan model GPT-2. Alamat kertas: https://paperswithcode.com/method/gpt-2
Pada bulan Mei 2020, OpenAI mengeluarkan kertas kerja "Model Bahasa adalah Sedikit Pelajar" (Model bahasa hendaklah sejumlah kecil sampel ( few-shot) pelajar dan mencadangkan model GPT-3 Alamat kertas: https://paperswithcode.com/method/gpt-3
Pada penghujung Februari 2022, OpenAI mengeluarkan kertas kerja "Model bahasa latihan. untuk mengikuti arahan dengan maklum balas manusia" (menggunakan aliran arahan maklum balas manusia untuk melatih model bahasa), mengumumkan alamat Kertas Arahan: https://arxiv.org/abs/2203.02155
Pada 30 November, 2022, OpenAI melancarkan ChatGPT Model ini tersedia untuk kegunaan percubaan dan popular di seluruh internet Lihat: AI-001 - Apa yang boleh dilakukan oleh ChatGPT, bot sembang popular di seluruh internet,
3. T-Transformer GPT. (2017)
dalam Bab 1 Dalam bahagian 1, kami mengatakan bahawa Transformer tidak mempunyai terjemahan yang sesuai Walau bagaimanapun, Transformer adalah kata kunci yang paling penting dan asas dalam GPT (Generative Pre-Training Transformer). > (Nota: Transformer GPT dipermudahkan berbanding Transformer asal dalam kertas Google, hanya bahagian Penyahkod dikekalkan, lihat bahagian 4.3 artikel ini)
3.1.1 🎜>
Sama seperti orang yang baik, perkara yang paling penting ialah menjadi baik atau menjadi manusia Pembaca, bukan? seorang yang baik mahupun manusia; Baiklah, mereka juga manusia Nah, ia agak mengelirukan. dari segi asas dan premis, tumpuan adalah pada orang 3.2 Maaf, Anda seorang yang baik Jika anda memanjangkan, bagaimana dengan "Saya minta maaf, anda seorang yang baik"? >Fokus semantik menjadi maaf, tetapi premis semantik masih orang 🎜>3.3 Kembali ke topik, apakah Transfomer
Anda boleh membaca artikel ini "Memahami Transfomer Sepuluh Minit" (https://zhuanlan.zhihu.com/p/82312421)
Jika anda faham, anda boleh mengabaikan kandungan saya yang seterusnya tentang Transfomer dan terus ke Bab 4. Jika anda tidak begitu memahaminya, anda boleh menyemak pemahaman saya, yang mungkin merujuk kepada anda.
3.3.1. Kelemahan utama model RNN generasi sebelumnyaSebelum model Transformer keluar, model RNN (rangkaian neural berulang) adalah model NLP biasa seni bina, berdasarkan Terdapat model varian lain RNN (abaikan nama mereka, selepas Transformer keluar, ia tidak lagi penting), tetapi mereka semua mempunyai masalah yang sama dan tidak dapat diselesaikan dengan baik.
Prinsip asas RNN ialah menyemak imbas setiap vektor perkataan dari kiri ke kanan (contohnya, ini anjing), mengekalkan data setiap perkataan dan setiap perkataan seterusnya bergantung pada perkataan sebelumnya.
Isu utama RNN: ia perlu dikira secara berurutan dan berurutan. Anda boleh bayangkan bahawa buku atau artikel mengandungi sejumlah besar perkataan, dan disebabkan kebergantungan urutan, ia tidak boleh disejajarkan, jadi kecekapannya sangat rendah.
Ini mungkin tidak mudah untuk difahami oleh semua orang Izinkan saya memberi anda satu contoh (pemahaman ringkas, yang sedikit berbeza daripada situasi sebenar):
Dalam gelung RNN, bagaimanakah ayat Anda. lelaki yang baik perlu dikira?
1), Kira Anda dan Anda adalah lelaki yang baik, dan dapatkan keputusan yang ditetapkan $Anda
2), Berdasarkan $Anda, gunakan Are dan Anda adalah lelaki yang baik , hitung $Are
3), berdasarkan $You, $Are, teruskan mengira $a
4), dan seterusnya, hitung $is, $good, $man, akhirnya lengkapkan pengiraan lengkap semua elemen You are a good man
Seperti yang anda lihat, proses pengiraan adalah satu demi satu, pengiraan berurutan, saluran paip tunggal, dan proses seterusnya bergantung pada proses sebelumnya, jadi ia sangat Lambat
3.3.2, Transformer's All in Attention
Seperti yang kami nyatakan sebelum ini, pada Jun 2017, Google mengeluarkan kertas kerja "Perhatian adalah semua yang anda perlukan" , Model Transformer dicadangkan buat kali pertama dan menjadi asas kepada pembangunan GPT. Alamat kertas: https://arxiv.org/abs/1706.03762
Daripada tajuknya "Perhatian adalah semua yang anda perlukan", anda boleh tahu bahawa Transfomer sebenarnya menyokong "All in Attention".
Jadi apa itu Perhatian?
Dalam kertas "Perhatian adalah semua yang anda perlukan", anda boleh melihat definisinya seperti berikut:
Perhatian Diri, kadangkala dipanggil perhatian dalaman, ialah Mekanisme perhatian yang mengaitkan kedudukan yang berbeza bagi satu jujukan untuk mengira perwakilan jujukan. Perhatian kendiri telah berjaya digunakan dalam pelbagai tugas seperti pemahaman bacaan, rumusan abstrak, kemasukan wacana dan pembelajaran perwakilan ayat bebas tugasan.

Pemahaman mudah ialah The korelasi antara perkataan diterangkan oleh vektor perhatian.
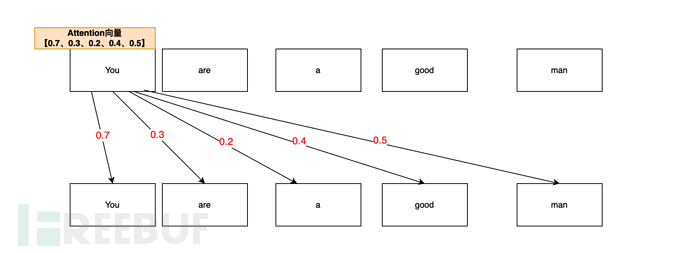
Sebagai contoh, Anda seorang yang baik(Anda seorang yang baik apabila AI menganalisis vektor perhatian Anda, ia mungkin menganalisisnya seperti ini:
Daripada Anda adalah seorang yang baik). Dalam ayat, diukur melalui mekanisme perhatian, kebarangkalian persatuan perhatian Anda dan Anda (diri) adalah yang paling tinggi (0.7, 70%), lagipun, anda (anda) adalah anda (anda) terlebih dahulu , Anda Vektor ialah 0.7
Korelasi perhatian antara Anda dan lelaki (orang) ialah (0.5, 50%), anda (anda) adalah seorang (lelaki), jadi vektor perhatian Anda dan lelaki ialah 0.5
Korelasi perhatian antara Anda dan baik (baik) adalah lagi (0.4, 40%). Jadi nilai vektor perhatian Anda,baik ialah 0.4
Anda,adalahNilai vektor ialah 0.3,a ialah 0.2;
Jadi senarai vektor perhatian Anda yang terakhir ialah [0.7, 0.3, 0.2, 0.4, 0.5] (hanya contoh dalam artikel ini).
3.4 Perihalan nilai perhatian dan pengubah dalam kertas
Dalam kertas kerja, penerangan Google tentang perhatian dan pengubah terutamanya menekankan nilai Sequential model tradisional. pergantungan wujud, dan model Transformer boleh menggantikan model rekursif semasa dan mengurangkan pergantungan berjujukan pada input dan output.


3.5 Kepentingan yang meluas bagi mekanisme Transformer
Selepas kemunculan Transformer, ia segera diganti. satu siri varian rangkaian saraf berulang RNN , menjadi asas seni bina model arus perdana.
Jika selari dan kelajuan yang lebih pantas adalah ciri teknikal yang tidak cukup intuitif untuk orang luar dan orang awam, maka kita boleh melihatnya dari kesan mengejutkan ChatGPT semasa.
**Transformer secara asasnya menyelesaikan dua halangan utama, dan pelancarannya adalah transformatif dan revolusioner**.
3.5.1 Buang anotasi manual set data (mengurangkan bilangan buruh manual dengan ketara)
Halangan utama ini ialah: dalam latihan yang lalu, jika kita ingin melatih secara mendalam model pembelajaran, kita mesti menggunakan pelabelan berskala besar Set data digunakan untuk latihan Set data ini memerlukan anotasi manual, yang sangat mahal.
Sebagai contoh, pembelajaran mesin memerlukan sejumlah besar bahan pengajaran dan sejumlah besar sampel input dan output untuk mesin belajar dan melatih. Bahan pengajaran ini perlu dibuat khusus, dan permintaannya sangat besar.
Sebagai contoh, dulu 10,000 atau 100,000 guru untuk menyusun bahan pengajaran, tetapi kini hanya 10 orang sahaja, pengurangan beribu kali ganda.
Jadi bagaimana untuk menyelesaikan masalah ini? Untuk menerangkannya secara ringkas, ia menggunakan mekanisme Topeng untuk menyekat segmen dalam artikel sedia ada dan membiarkan AI mengisi tempat kosong.
Ia seperti menyekat satu ayat artikel atau puisi sedia ada dan membiarkan mesin mengisi ayat seterusnya berdasarkan model yang dipelajari dan ayat sebelumnya.
Seperti yang ditunjukkan di bawah:


Dengan cara ini, banyak artikel siap sedia, halaman web, Soal Jawab Zhihu, Baidu Zhizhi, dsb. ialah set data beranotasi semula jadi (satu perkataan , sangat menjimatkan wang).
3.5.2 Ubah pengiraan berurutan kepada pengiraan selari, sangat mengurangkan masa latihan
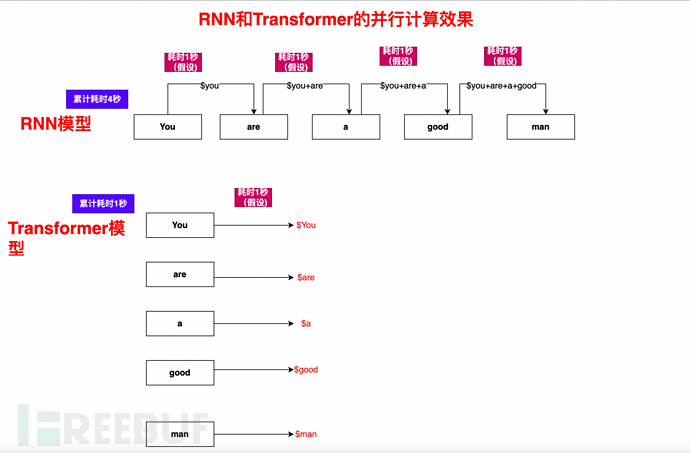
Selain anotasi manual, RNN disebut dalam bahagian 3.3.1 Kepincangan utama adalah masalah pengiraan berurutan dan saluran paip tunggal.
Mekanisme Perhatian Diri, digabungkan dengan mekanisme topeng dan pengoptimuman algoritma, membolehkan artikel, ayat atau perenggan dikira secara selari.
Mari kita ambil Anda seorang lelaki yang baik sebagai contoh Anda boleh melihat bahawa seberapa banyak komputer yang ada, seberapa pantas Transformer boleh:


4. GPT (Generative Pra-Training)-Jun 2018
Seterusnya, datanglah kehidupan ChatGPT-GPT(1) sebelumnya.
Pada bulan Jun 2018, OpenAI mengeluarkan kertas kerja "Meningkatkan Pemahaman Bahasa dengan Pra-Latihan Generatif" (Meningkatkan Kefahaman Bahasa melalui Pra-Latihan Generatif), yang mencadangkan model GPT (Pra-Latihan Generatif) buat kali pertama . Alamat kertas: https://paperswithcode.com/method/gpt.
4.1. Cadangan teras model GPT 1-pra-latihan (pra-latihan)
Model GPT bergantung pada premis bahawa Transformer menghapuskan korelasi berurutan dan pergantungan, dan mengemukakan a cadangan yang membina.
Mula-mula lulus sejumlah besar pra-latihan tanpa pengawasan (pra-latihan tanpa pengawasan),
Nota: Tanpa pengawasan bermakna tiada campur tangan manusia diperlukan dan tiada set data berlabel diperlukan (tiada buku teks dan guru diperlukan) pra-latihan.
Kemudian gunakan sedikit penalaan halus diselia untuk membetulkan pemahamannya.

4.1.1. Contohnya,
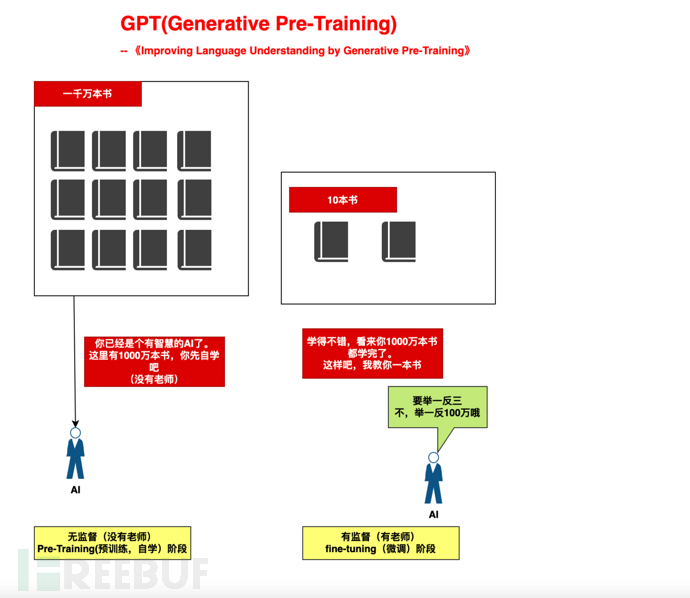
Sebagai contoh, ia seperti kita membesarkan anak dalam dua peringkat :
1) Peringkat pengajian kendiri berskala besar (belajar kendiri 10 juta buku tanpa guru): Sediakan kuasa pengkomputeran yang mencukupi kepada AI dan biarkan ia belajar dengan sendirinya berdasarkan mekanisme Perhatian.
2), peringkat bimbingan berskala kecil (mengajar 10 buku): berdasarkan 10 buku, buat inferens tentang "tiga"

4.1.2 Penerangan tentang pembukaan kertas
Apa yang dipanggil permulaan yang jelas, dari pengenalan pembukaan, anda juga boleh melihat penerangan model GPT untuk pembelajaran diselia dan pelabelan manual data.

4.2. Cadangan Teras model GPT 2-Generatif
Dalam pembelajaran mesin, terdapat model dan penjanaan diskriminatif Terdapat dua perbezaan antara model Generatif.
GPT (Generative Pra-Training), seperti namanya, menggunakan model generatif.
Model generatif lebih sesuai untuk pembelajaran data besar berbanding model diskriminatif, yang lebih sesuai untuk sampel yang tepat (set data sah yang dilabelkan secara manual). Untuk melaksanakan pra-latihan dengan lebih baik, model generatif akan lebih sesuai.
Nota: Fokus bahagian ini adalah pada ayat di atas (lebih sesuai untuk pembelajaran data besar jika anda rasa rumit untuk difahami, anda tidak perlu membaca bahagian ini yang lain).
Dalam bahan model generatif wiki (https://en.wikisensitivity.org/wiki/Generative_model), berikut ialah contoh untuk menggambarkan perbezaan antara keduanya:

Mungkin tidak mudah untuk difahami hanya dengan melihat perkara di atas, jadi berikut adalah penjelasan tambahan.
Bermaksud di atas, dengan mengandaikan terdapat 4 sampel:
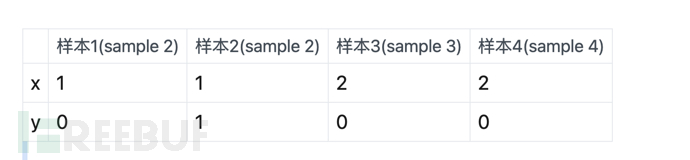
Kemudian ciri Model Generatif ialah kebarangkalian tidak dikumpulkan (kira kebarangkalian dalam sampel dan bahagikannya dengan jumlah sampel Sebagai contoh, dalam jadual di atas, didapati terdapat a jumlah 1 x=1 dan y=0, jadi kita fikir Kebarangkalian bagi x=1, y=0 ialah 1/4 (jumlah sampel ialah 4).
Begitu juga, terdapat sejumlah 2 x=2, y=0, maka kebarangkalian bagi x=2, y=0 ialah 2/4.

Ciri model diskriminatif ialah **pengiraan kumpulan kebarangkalian (kira kebarangkalian dalam kumpulan dan bahagikan dengan jumlah dalam kumpulan)**. Mengambil jadual di atas sebagai contoh, terdapat sejumlah 1 sampel untuk x=1 dan y=0, dan sejumlah 2 sampel untuk kumpulan x=1, jadi kebarangkalian ialah 1/2.
Begitu juga, terdapat sejumlah 2 x=2 dan y=0. Dan pada masa yang sama, terdapat 2 sampel dalam kumpulan dengan x=2, jadi kebarangkalian x=2, y=0 ialah 2/2=1 (iaitu, 100%).

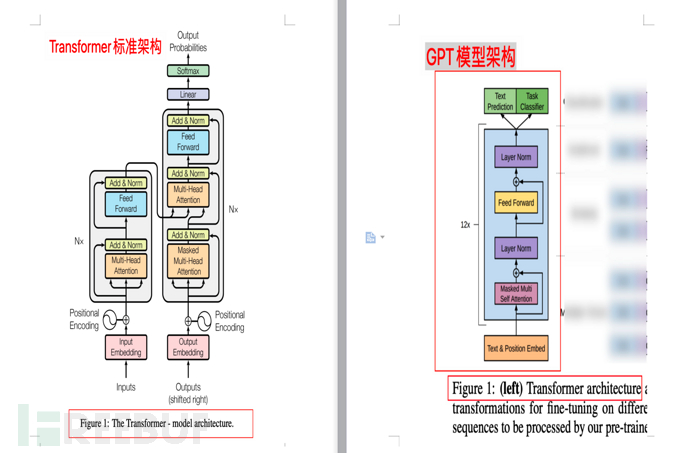
4.3 Penambahbaikan model GPT berbanding Transfomer asal
Berikut ialah penerangan model GPT yang melatih penyahkod 12 lapisan sahaja ( penyahkod sahaja, tiada pengekod), dengan itu menjadikan model lebih mudah.
Nota 1: Transformer asal kertas Google "Perhatian adalah semua yang anda perlukan" mengandungi dua bahagian: Pengekod dan Penyahkod yang pertama sepadan dengan terjemahan, dan yang terakhir (Penyahkod) sepadan dengan penjanaan.
Nota 2: Google telah membina model BERT (Perwakilan Pengekod Dua Arah daripada Transformers, Perwakilan Pengekod Dwi Arah daripada Transformers) dengan Pengekod sebagai teras. Bahagian dalam Dwiarah bermaksud BERT menggunakan kedua-dua konteks atas dan bawah untuk meramal perkataan, jadi BERT lebih baik dalam mengendalikan tugas pemahaman bahasa semula jadi (NLU).
Nota 3: Perkara utama bahagian ini ialah GPT adalah berdasarkan Transformer, tetapi berbanding dengan Transformer, ia memudahkan model, mengeluarkan Pengekod dan hanya mengekalkan Penyahkod. Pada masa yang sama, berbanding ramalan konteks BERT (dua hala), penyokong GPT hanya menggunakan konteks perkataan untuk meramal perkataan (sehala), menjadikan model lebih mudah, lebih cepat untuk dikira, lebih sesuai untuk generasi melampau, dan oleh itu GPT lebih baik dalam memproses Tugas penjanaan bahasa semula jadi (NLG) ialah apa yang kami temui dalam AI-001 - apa yang boleh dilakukan oleh ChatGPT, chatbot popular di Internet, ChatGPT sangat baik dalam menulis "komposisi" dan membuat pembohongan . Selepas memahami perenggan ini, anda tidak perlu membaca bahagian ini yang lain.
Nota 4: Dari perspektif simulasi manusia, mekanisme GPT lebih seperti manusia sebenar. Kerana manusia juga menyimpulkan perkara-perkara berikut (iaitu yang berikut) berdasarkan perkara di atas (apa yang dikatakan sebelum ini) adalah seperti air yang dicurahkan Manusia tidak boleh menyesuaikan perkataan sebelumnya berdasarkan apa yang diucapkan kemudian .Walaupun mereka berkata Salah, kata-kata yang buruk menyakiti hati orang, dan ia hanya boleh diperbaiki dan dijelaskan berdasarkan perkataan yang diucapkan (di atas).

4.3.1. Perbandingan gambar rajah seni bina
Rajah berikut menunjukkan perbandingan antara seni bina model Transformer dan model GPT. seni bina (masing-masing daripada kertas "Perhatian adalah semua yang anda perlukan" dan "Meningkatkan Pemahaman Bahasa oleh Pra-Latihan Generatif")
4.4, skala latihan model GPT
Mod Generatif yang disebut sebelum ini adalah lebih kondusif untuk Pra-Latihan set data besar Jadi berapa besar set data yang digunakan GPT?
Seperti yang dinyatakan dalam kertas kerja, ia menggunakan set data yang dipanggil BooksCorpus, yang mengandungi lebih daripada 7,000 buku yang tidak diterbitkan.

5 . harus menjadi pelajar pelbagai tugas tanpa pengawasan), dan model GPT-2 dicadangkan. Alamat kertas: https://paperswithcode.com/method/gpt-2
5.1 Perubahan teras model GPT-2 berbanding GPT-1
Seperti yang dinyatakan sebelum ini, cadangan teras daripada GPT Terdapat Generatif dan Pra-Latihan. Pada masa yang sama, latihan GPT mempunyai dua langkah:
1), peringkat belajar kendiri berskala besar (Pra-Latihan, belajar sendiri 10 juta buku, tiada guru): menyediakan kuasa pengkomputeran yang mencukupi untuk AI, dan biarkan ia berdasarkan Mekanisme Perhatian, belajar sendiri.
2), peringkat bimbingan berskala kecil (penalaan halus, mengajar 10 buku): Berdasarkan 10 buku, buat inferens tentang "tiga"
Mengenai GPT-2, OpenAI akan Peringkat penalaan halus yang diselia telah dialih keluar secara langsung, menjadikannya model tanpa pengawasan.
Pada masa yang sama, kata kunci **multitask (multitask)** telah ditambah, yang boleh dilihat daripada nama kertas "Model Bahasa ialah Pelajar Berbilang Tugas Tanpa Diawasi" (model bahasa hendaklah pelajar berbilang tugas tanpa pengawasan) Ia juga boleh dilihat.

5.2. Mengapa pelarasan ini? Cuba selesaikan masalah sifar pukulan
Mengapa GPT-2 dilaraskan seperti ini? Dilihat dari huraian kertas itu, ia adalah untuk cuba menyelesaikan sifar-shot (masalah pembelajaran sifar-shot)**.
Apakah masalah dengan sifar pukulan (pembelajaran sifar pukulan)? Ia boleh difahami secara ringkas sebagai kebolehan menaakul. Ini bermakna apabila berhadapan dengan perkara yang tidak diketahui, AI secara automatik boleh mengenalinya, iaitu, ia mempunyai keupayaan untuk menaakul.
Sebagai contoh, sebelum ke zoo, kami memberitahu kanak-kanak bahawa haiwan seperti kuda yang hitam putih seperti panda dan mempunyai belang hitam putih adalah seekor kuda belang boleh mencari kuda belang dengan betul.
5.3. Bagaimana untuk memahami pelbagai tugas?
Dalam ML tradisional, jika anda ingin melatih model, anda memerlukan set data beranotasi khas untuk melatih AI khas.
Sebagai contoh, untuk melatih robot yang boleh mengecam imej anjing, anda memerlukan 1 juta imej yang dilabelkan dengan anjing Selepas latihan, AI akan dapat mengenali anjing. AI ini ialah AI khusus, juga dipanggil tugas tunggal.
Bagi berbilang tugas, ia tidak menyokong AI yang berdedikasi, tetapi memberi sejumlah besar data supaya sebarang tugas boleh diselesaikan.
5.4 Data dan skala latihan GPT-2
Set data telah ditingkatkan kepada 8 juta halaman web dan bersaiz 40GB.

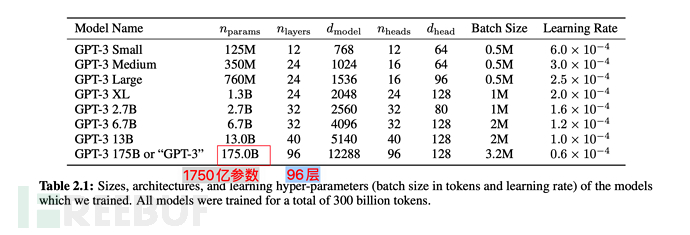
Model itu sendiri juga mencapai maksimum 1.5 bilion parameter, dan timbunan Transformer mencapai 48 lapisan. Analogi mudah adalah seperti mensimulasikan 1.5 bilion neuron manusia (sekadar contoh, tidak setara sepenuhnya).

6. GPT-3 (Mei 2020)
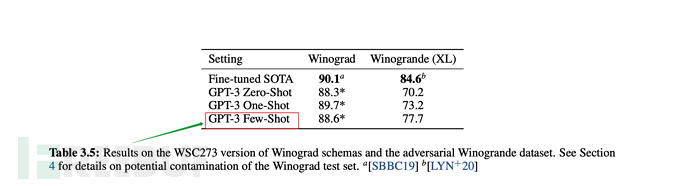
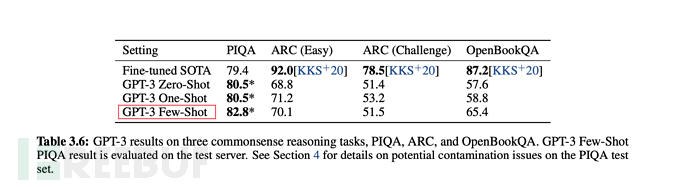
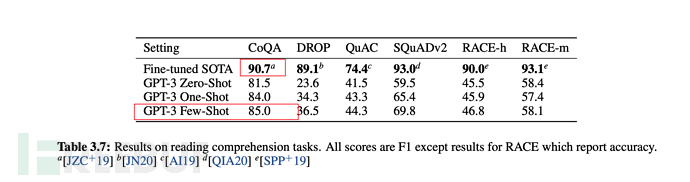
Pada Mei 2020, OpenAI mengeluarkan kertas kerja "Model Bahasa adalah Sedikit Pelajar" ( Bahasa model haruslah pelajar beberapa pukulan), dan model GPT-3 dicadangkan. Alamat kertas: https://paperswithcode.com/method/gpt-3
6.1 Kemajuan kesan terobosan GPT-3
Kesannya diterangkan dalam kertas seperti berikut:
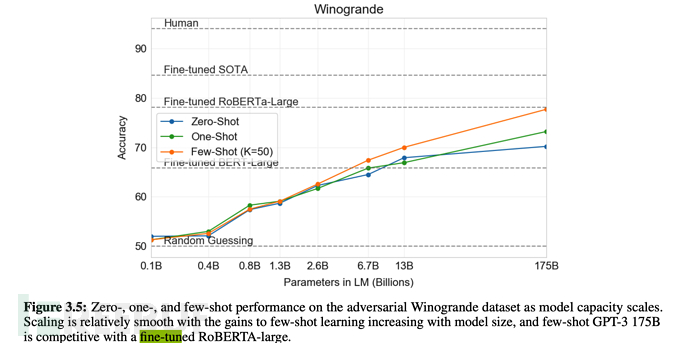
<.>1. GPT-3 menunjukkan prestasi yang kukuh dalam terjemahan, menjawab soalan dan pengisian kloz, sambil dapat mentafsir perkataan, menggunakan perkataan baharu dalam ayat atau melakukan pengiraan 3 digit. 2. GPT-3 boleh menjana contoh artikel berita yang tidak dapat dibezakan lagi oleh manusia. Seperti yang ditunjukkan di bawah:


7 Arahan GPT (Februari 2022)
Pada penghujung Februari 2022, OpenAI mengeluarkan kertas kerja "Melatih model bahasa untuk mengikuti arahan dengan maklum balas manusia" (menggunakan manusia Maklum balas aliran arahan untuk melatih model bahasa), dan menerbitkan model GPT Arahan. Alamat kertas: https://arxiv.org/abs/2203.02155
7.1 Perubahan teras GPT Arahan berbanding GPT-3
GPT Arahan ialah pusingan pengoptimuman yang dipertingkatkan berdasarkan GPT- 3 , jadi ia juga dipanggil GPT-3.5.
Seperti yang dinyatakan sebelum ini, GPT-3 menyokong pembelajaran beberapa pukulan sambil menegaskan pembelajaran tanpa pengawasan.
Tetapi sebenarnya, kesan few-shot jelas lebih teruk daripada kaedah penyeliaan penalaan halus.
Jadi apa yang perlu kita lakukan? Kembali ke penalaan halus untuk menyelia penalaan halus? Nampaknya tidak.
OpenAI memberikan jawapan baharu: Berdasarkan GPT-3, latih model ganjaran (model ganjaran) berdasarkan maklum balas manual (RHLF), dan kemudian gunakan model ganjaran (model ganjaran, RM) untuk melatih dan belajar Model.
Ya Tuhan, saya masih muda. . Sudah tiba masanya untuk menggunakan mesin (AI) untuk melatih mesin (AI). .

7.2 Langkah latihan Teras GPT Arahan
GPT Arahan mempunyai 3 langkah secara keseluruhan:
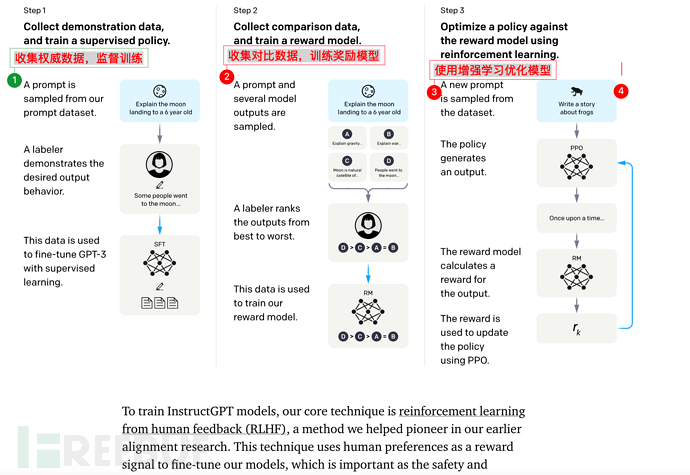


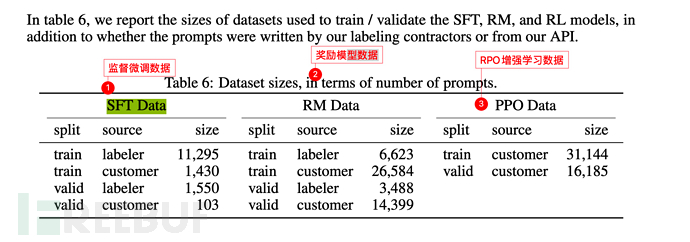
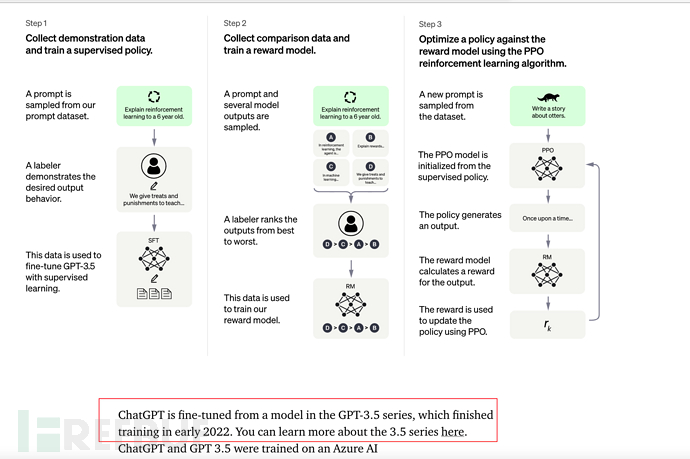
Anda boleh merujuk kepada video Profesor Li Hongyi Universiti Nasional Taiwan "Bagaimana ChatGPT dibuat?" Proses Sosialisasi GPT" adalah ceramah yang sangat bagus. https://www.inside.com.tw/article/30032-chatgpt-possible-4-steps-trainingGPT ialah generasi sehala, iaitu, yang berikut dihasilkan berdasarkan perkara di atas. Sebagai contoh, terdapat ayat: Beri input kepada model GPT Hello, perkataan seterusnya adalah untuk menjemput anda, okay? awak kacak? Adakah anda begitu tinggi? Cantik sangat awak? Tunggu, GPT akan mengira kebarangkalian dan memberikan kebarangkalian tertinggi sebagai jawapan. Dan seterusnya, jika arahan (atau gesaan) diberikan, ChatGPT juga akan mengira (jawapan) berikut berdasarkan perkara di atas (prompt), dan pada masa yang sama memilih kebarangkalian tertinggi di atas untuk jawab. Seperti yang ditunjukkan di bawah:
1). Pada tahun 2017, Google mengeluarkan kertas "Perhatian adalah semua yang anda perlukan" dan mencadangkan model Transformer, yang membuka jalan untuk GPT.
2). Pada Jun 2018, OpenAI mengeluarkan model pra-latihan generatif GPT, yang dilatih melalui set data besar BooksCorpus (7000 buku), dan menganjurkan latihan pra-latihan berskala besar tanpa pengawasan (pra- latihan) + penalaan halus (fine-tuning) diselia untuk pembinaan model.
3). Pada Februari 2019, OpenAI mengeluarkan model GPT-2, mengembangkan lagi skala latihan (menggunakan set data 40GB dengan maksimum 1.5 bilion parameter). Pada masa yang sama, dari segi idea, proses penalaan halus dikeluarkan, dan sifar-shot (pembelajaran sifar-shot) dan multitask (berbilang tugas) ditekankan. Tetapi pada akhirnya, kesan sifar pukulan adalah jauh lebih rendah daripada penalaan halus.
4). Pada Mei 2020, OpenAI mengeluarkan model GPT-3, mengembangkan lagi **skala latihan (menggunakan set data 570GB dan 175 bilion parameter)**. Pada masa yang sama, ia menggunakan model pembelajaran beberapa pukulan (bilangan kecil sampel) dan mencapai keputusan yang cemerlang. Sudah tentu, penalaan halus dibandingkan secara serentak dalam eksperimen, dan kesannya lebih buruk sedikit daripada penalaan halus.
5) Pada Februari 2022, OpenAI mengeluarkan model GPT Arahan Kali ini, ia terutamanya menambah pautan penalaan halus (Supervised Fine-tala) berdasarkan GPT-3, dan berdasarkan ini, penambahan selanjutnya. Model ganjaran Model Ganjaran dipasang, dan model latihan RM digunakan untuk melaksanakan pengoptimuman pembelajaran yang dipertingkatkan RPO pada model pembelajaran.
6). Pada 30 November 2022, OpenAI mengeluarkan model ChatGPT, yang boleh difahami sebagai InstructionGPT selepas beberapa pusingan latihan berulang, dan berdasarkan ini, fungsi dialog Chat telah ditambahkan.
10 Masa depan (GPT-4 atau ?)
Dari pelbagai petunjuk, GPT-4 mungkin akan didedahkan pada tahun 2023? Seberapa kuat ia akan menjadi?
Pada masa yang sama, kesan ChatGPT telah menarik banyak perhatian dalam industri Saya percaya bahawa lebih banyak model latihan berasaskan GPT dan aplikasinya akan berkembang pada masa hadapan.
Mari kita tunggu dan lihat apa yang akan berlaku pada masa hadapan.
Beberapa rujukan
ai.googleblog.com/2017/08/transformer-novel-neural-network.html
https://arxiv.org/abs/ 1706.03762
https://paperswithcode.com/method/gpt
https://paperswithcode.com/method/gpt-2
https://paperswithcode.com / kaedah/gpt-3
https://arxiv.org/abs/2203.02155
https://zhuanlan.zhihu.com/p/464520503
https: / /zhuanlan.zhihu.com/p/82312421
https://cloud.tencent.com/developer/article/1656975
https://cloud.tencent.com/developer/ artikel /1848106
https://zhuanlan.zhihu.com/p/353423931
https://zhuanlan.zhihu.com/p/353350370
https:/ / juejin.cn/post/6969394206414471175
https://zhuanlan.zhihu.com/p/266202548
https://ms.wikisensitivity.org/wiki/Generative_model
https://zhuanlan.zhihu.com/p/67119176https://zhuanlan.zhihu.com/p/365554706https://cloud.tencent .com/developer /article/1877406https://zhuanlan.zhihu.com/p/34656727https://zhuanlan.zhihu.com/p/590311003Atas ialah kandungan terperinci Sepuluh minit untuk memahami logik teknikal dan evolusi ChatGPT (kehidupan lalu, kehidupan sekarang). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI