
Rumah >pangkalan data >tutorial mysql >Cara menggunakan Python untuk membaca berpuluh-puluh juta data dan secara automatik menulisnya ke pangkalan data MySQL
Cara menggunakan Python untuk membaca berpuluh-puluh juta data dan secara automatik menulisnya ke pangkalan data MySQL

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-30 11:55:281784semak imbas
Senario 1: Data tidak perlu kerap ditulis ke mysql
Gunakan fungsi wizard import alat navicat. Perisian ini boleh menyokong pelbagai format fail, dan boleh membuat jadual secara automatik berdasarkan medan fail atau memasukkan data ke dalam jadual sedia ada, yang sangat pantas dan mudah.
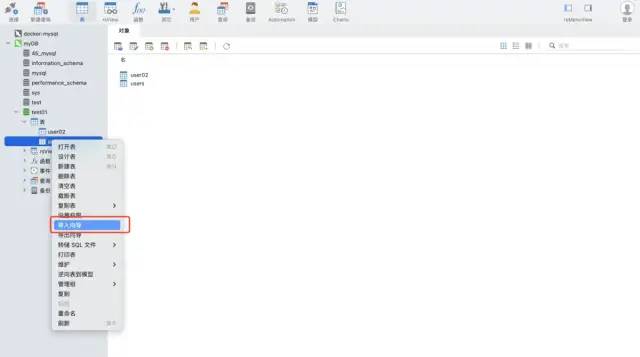
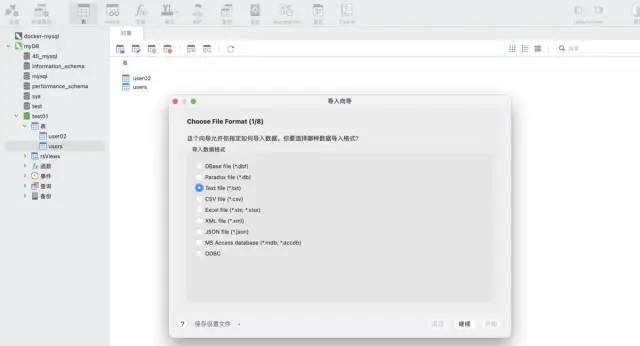
Senario 2: Data adalah tambahan dan perlu diautomatikkan dan kerap ditulis ke mysql
Data Ujian: format csv, kira-kira 12 juta baris
import pandas as pd data = pd.read_csv('./tianchi_mobile_recommend_train_user.csv') data.shape
Cetak hasil:

Kaedah 1: python ➕ perpustakaan pymysql
Pasang arahan pymysql:
pip install pymysql
Pelaksanaan kod:
rreee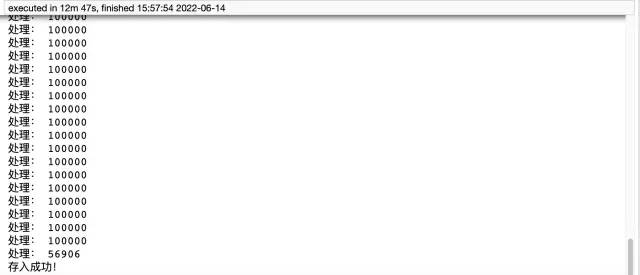
pandas ➕ sqlalchemy: panda perlu memperkenalkan sqlalchemy untuk menyokong sql dengan sokongan sqlalchemy, ia boleh melaksanakan pertanyaan, kemas kini dan operasi lain bagi semua jenis pangkalan data biasa.
Pelaksanaan kod:import pymysql
# 数据库连接信息
conn = pymysql.connect(
host='127.0.0.1',
user='root',
passwd='wangyuqing',
db='test01',
port = 3306,
charset="utf8")
# 分块处理
big_size = 100000
# 分块遍历写入到 mysql
with pd.read_csv('./tianchi_mobile_recommend_train_user.csv',chunksize=big_size) as reader:
for df in reader:
datas = []
print('处理:',len(df))
# print(df)
for i ,j in df.iterrows():
data = (j['user_id'],j['item_id'],j['behavior_type'],
j['item_category'],j['time'])
datas.append(data)
_values = ",".join(['%s', ] * 5)
sql = """insert into users(user_id,item_id,behavior_type
,item_category,time) values(%s)""" % _values
cursor = conn.cursor()
cursor.executemany(sql,datas)
conn.commit()
# 关闭服务
conn.close()
cursor.close()
print('存入成功!')Ringkasan
Kaedah pymysql mengambil masa 12 minit dan 47 saat. Ia mengambil masa yang lama dan mempunyai jumlah yang besar kod, manakala panda Ia hanya memerlukan lima baris kod untuk mencapai keperluan ini, dan ia hanya mengambil masa kira-kira 4 minit. Akhir sekali, saya ingin menambah bahawa kaedah pertama memerlukan membuat jadual terlebih dahulu, tetapi kaedah kedua tidak. Oleh itu, adalah disyorkan agar anda menggunakan kaedah kedua, yang mudah dan berkesan. Jika anda masih merasakan ia lambat, anda boleh mempertimbangkan untuk menambah berbilang proses dan berbilang benang.
Tiga kaedah paling lengkap untuk menyimpan data ke dalam pangkalan data MySQL:
- Storan langsung, menggunakan fungsi wizard import navicat
- Python pymysql
- Panda sqlalchemy
Atas ialah kandungan terperinci Cara menggunakan Python untuk membaca berpuluh-puluh juta data dan secara automatik menulisnya ke pangkalan data MySQL. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!