
Rumah >Peranti teknologi >AI >Amalan algoritma graf dalam sistem kawalan risiko Alibaba
Amalan algoritma graf dalam sistem kawalan risiko Alibaba

- 王林ke hadapan
- 2023-05-29 19:28:041462semak imbas

1 Pengenalan kepada algoritma graf dalam senario kawalan risiko e-dagang
Pertama sekali, berikan ringkasan gambaran keseluruhan risiko e-dagang Alibaba Ciri-ciri, sejarah aplikasi dan status semasa algoritma graf.
1 Ciri-ciri risiko e-dagang Alibaba
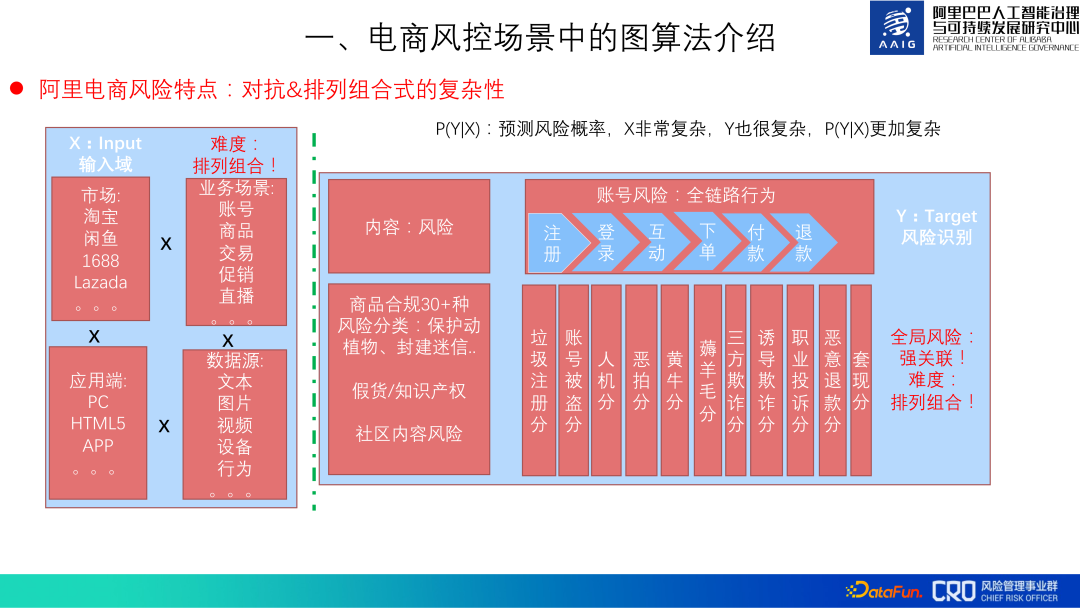
Ciri-ciri utama risiko e-dagang Alibaba: konfrontasi & permutasi dan kerumitan formula gabungan.
Risiko mestilah konfrontasi, dan risiko e-dagang Alibaba juga kompleks dalam pilih atur dan gabungan. Pengenalpastian risiko terutamanya menggunakan X (data) untuk meramalkan Y (risiko): P(Y|X). Dalam e-dagang Alibaba , Tmall, 1688, Lazada, dsb., ciri-ciri risiko pasaran yang berbeza adalah berbeza; , promosi, dsb., dan Dengan lelaran dan inovasi perniagaan, risiko baharu akan timbul; setiap terminal perlu Lakukan pencegahan dan kawalan;
④ Sumber data yang pelbagai memerlukan keupayaan untuk memproses dan menyepadukan data dalam modaliti yang berbeza.
Pada masa yang sama, Y juga sangat kompleks, terutamanya dicerminkan dalam tiga aspek. Yang pertama ialah jenis risiko Banyak, risiko kandungan biasa, risiko tingkah laku, dsb. hanyalah penurunan dalam lautan banyak risiko kedua, risiko ini berkaitan, seperti penipuan penjual berkaitan dengan pendaftaran, kecurian dan kandungan produk; ; ketiga, risiko akan dipindahkan Satu jenis risiko lebih baik dicegah, tetapi kos melakukan jenayah adalah tinggi, dan kemudiannya dipindahkan kepada risiko lain atau mewujudkan risiko baru.
Jadi keseluruhan pencegahan dan kawalan risiko adalah sangat rumit, dengan pilih atur dan gabungan kerumitan.
2. Kepentingan algoritma graf
Algoritma graf boleh meningkatkan keupayaan konfrontasi model pengenalan risiko. Kebanyakan "perkara buruk" di platform hanya dilakukan oleh beberapa orang "orang jahat" mempunyai banyak jaket Kita boleh mengetahui petunjuk melalui "hubungan" dan mengenal pasti dan berurusan dengan mereka terlebih dahulu. Sebagai contoh, titik kuning dalam gambar di bawah, dengan mengandaikan ia adalah pengguna yang mempunyai tingkah laku yang tidak normal, sukar untuk menilai bahawa dia adalah pengguna penipuan berdasarkan tingkah lakunya sendiri sahaja, tetapi ia boleh dianalisis dengan menganalisis tiga pengguna penipuan yang lain. dikaitkan dengannya (titik hitam) untuk menentukan bahawa dia adalah pengguna yang menipu. Pada masa yang sama, kami mendapati semua akaun yang berkait rapat dengan keempat-empat akaun ini dan mendapati bahawa mereka adalah geng Jika melupuskan akaun ini secara berkelompok terlebih dahulu boleh meningkatkan kos melakukan kejahatan.
Selain itu, graf heterogen secara semula jadi dan global boleh mengintegrasikan pelbagai modaliti dan objek risiko Data, kira perwakilan objek yang berbeza, dan kemudian kenal pasti risiko yang berbeza untuk menangani kerumitan pilih atur dan kombinasi
3 Sejarah dan situasi semasa algoritma graf
Berdasarkan kepentingan algoritma graf, kawalan risiko e-dagang Alibaba telah menggunakan algoritma graf sejak 2013.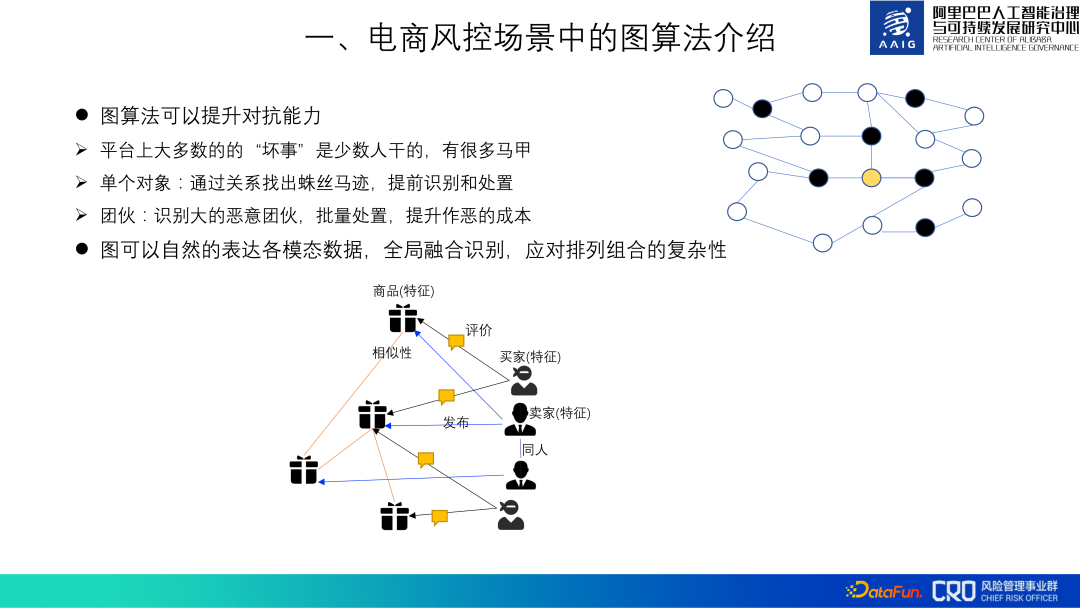
Pada mulanya algoritma graf digunakan untuk membina rangkaian perhubungan seluruh pustaka akaun. Data perhubungan ini adalah data asas yang diperlukan untuk semua senario pencegahan dan kawalan risiko seperti penipuan, keselamatan akaun, anti-penipuan dan barangan palsu. Data utama yang digunakan termasuk data media seperti maklumat peranti dan nombor telefon mudah alih. Ia terutamanya menerangkan korelasi antara akaun, jenis perhubungan, pengenalan kumpulan, dsb. Saluran maklum balas gelung tertutup daripada pengeluaran kepada aplikasi telah diwujudkan untuk rangkaian perhubungan ini. Terdapat banyak data hubungan asas Kos keseluruhan pengagregatan, pembersihan, pengiraan graf dan penyimpanan data hubungan adalah sangat tinggi, dan ia mesti dikemas kini secara berterusan kemudian, jadi membina hubungan Kos. rangkaian adalah tinggi, tetapi kerana banyak model dan strategi risiko kami bergantung pada rangkaian perhubungan ini, ia masih berbaloi. 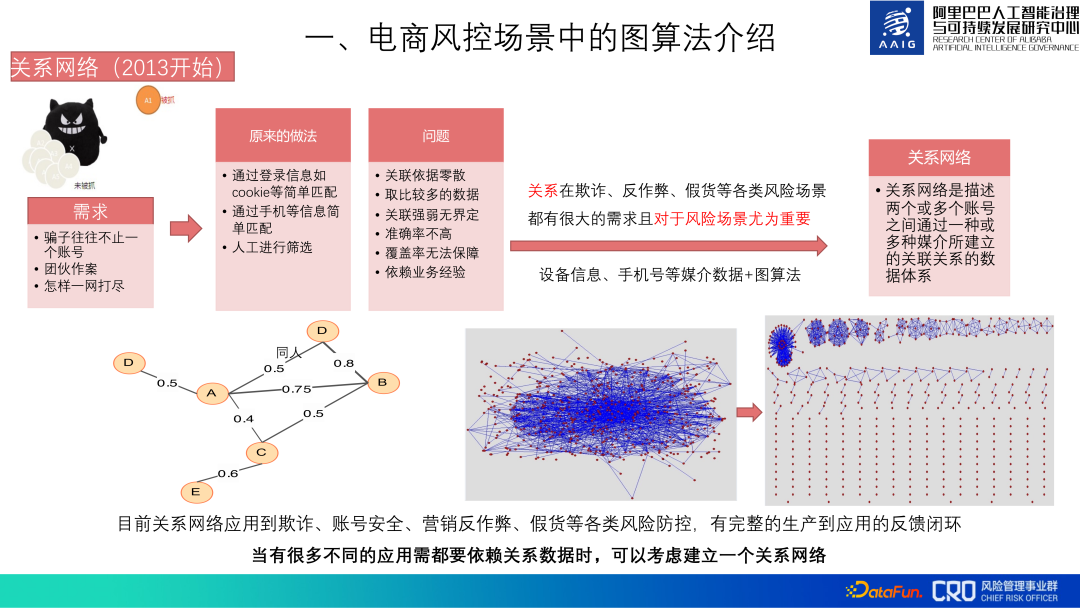
Bagi rangkaian neural graf, kami mula meneroka aplikasi pada 2016. Kami juga dipanggil GGL (Pembelajaran Graf Geometrik Pada masa itu, tiada rangka kerja algoritma rangkaian saraf graf yang tersedia, jadi kami melaksanakan rangka kerja algoritma GGL dalam C++. Pada tahun 2018, ia telah dipindahkan ke Graph learning yang disediakan oleh Alibaba Computing Platform Rangka kerja ini juga merupakan sumber terbuka Kami turut menyumbang beberapa kod algoritma graf kepada rangka kerja ini.
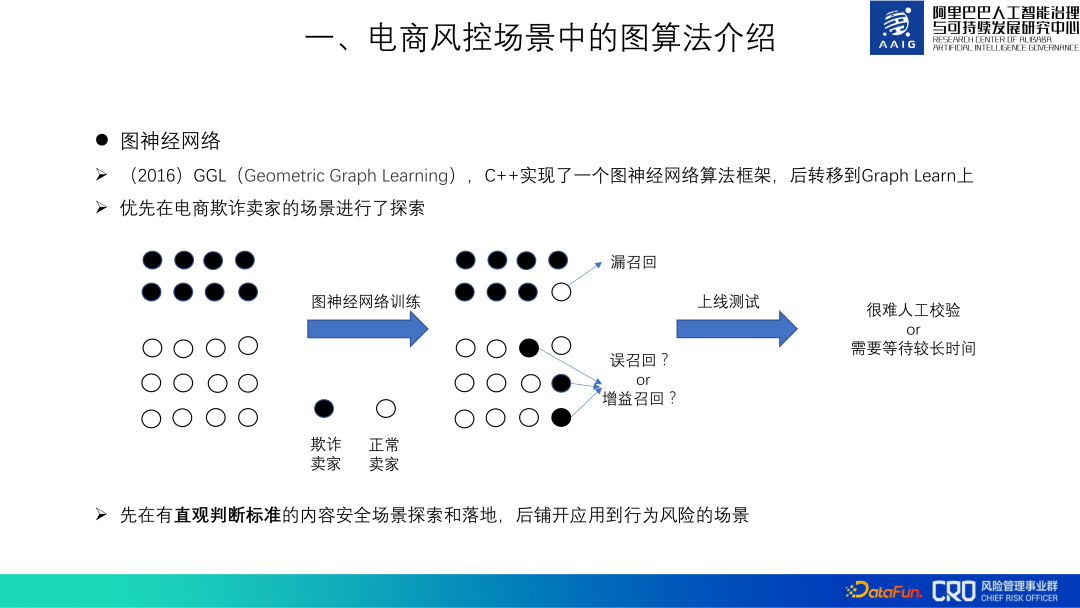
Terdapat banyak senario kawalan risiko e-dagang, dan ia juga penting untuk dipilih senario yang sesuai semasa fasa pengesahan algoritma graf Terutama penting. "Kriteria penilaian" untuk risiko tingkah laku, yang menyumbang sebahagian besar dalam senario risiko, tidak intuitif Dalam senario industri, sampel putih risiko tingkah laku dicampur dengan banyak sampel hitam yang belum ditemui Apabila algoritma graf menilai sampel putih sebagai hitam sampel, adalah sukar untuk menilai sama ada ia adalah sampel hitam atau tidak sama ada ia adalah panggilan palsu atau perolehan semula, ini akan menjejaskan penalaan model dan pertimbangan kesan dalam talian. Sebaliknya, senario keselamatan kandungan, seperti spam dan penghinaan, adalah senario dengan "kriteria pertimbangan intuitif" dan lebih sesuai untuk mengesahkan keberkesanan algoritma graf. Oleh itu, kami mula-mula meneroka algoritma dalam senario keselamatan kandungan, mengesahkan keberkesanannya dan mengumpul amalan terbaik, dan kemudian menggunakannya pada senario risiko tingkah laku.
Setakat ini, algoritma graf digunakan dalam pelbagai perniagaan berisiko e-dagang Alibaba. Keseluruhan rangka kerja algoritma graf adalah seperti yang ditunjukkan di bawah Pertama, lapisan data relasi dikekalkan di bahagian bawah untuk mengumpul dan membersihkan pelbagai data relasi untuk memudahkan aplikasi lapisan atas, algoritma graf yang biasa digunakan dicetuskan; lapisan seterusnya menggunakan lapisan data hubungan dan lapisan algoritma untuk membina rangkaian perhubungan akaun, yang secara mendatar menyokong pencegahan dan kawalan pelbagai senario risiko di lapisan perniagaan teratas, digabungkan dengan ciri-ciri risiko tertentu , kami menggunakan algoritma graf dan data hubungan ini untuk membina model graf untuk mengenal pasti pelbagai risiko perniagaan.
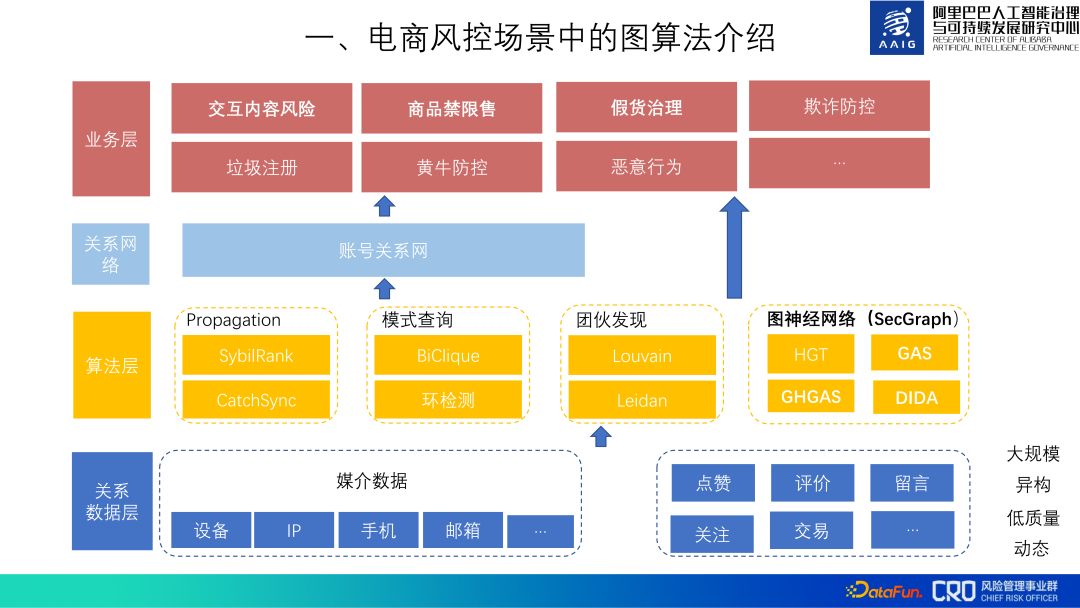
Perkongsian berikut terutamanya akan memperkenalkan "risiko kandungan interaktif", "larangan dan sekatan komoditi", "barangan palsu" Beberapa algoritma graf digunakan untuk tiga jenis risiko ini: "Tadbir urus".
2. Algoritma graf untuk kawalan risiko kandungan interaktif
Platform e-dagang Alibaba mempunyai senario kandungan interaktif yang kaya. Seperti penilaian produk, komen, bertanya kepada semua orang, serta membeli-belah Taobao mudah alih, komuniti Xianyu, dsb. Berikut menggunakan pengenalan iklan spam dalam mesej Xianyu sebagai contoh untuk memperkenalkan algoritma graf kawalan risiko kandungan.
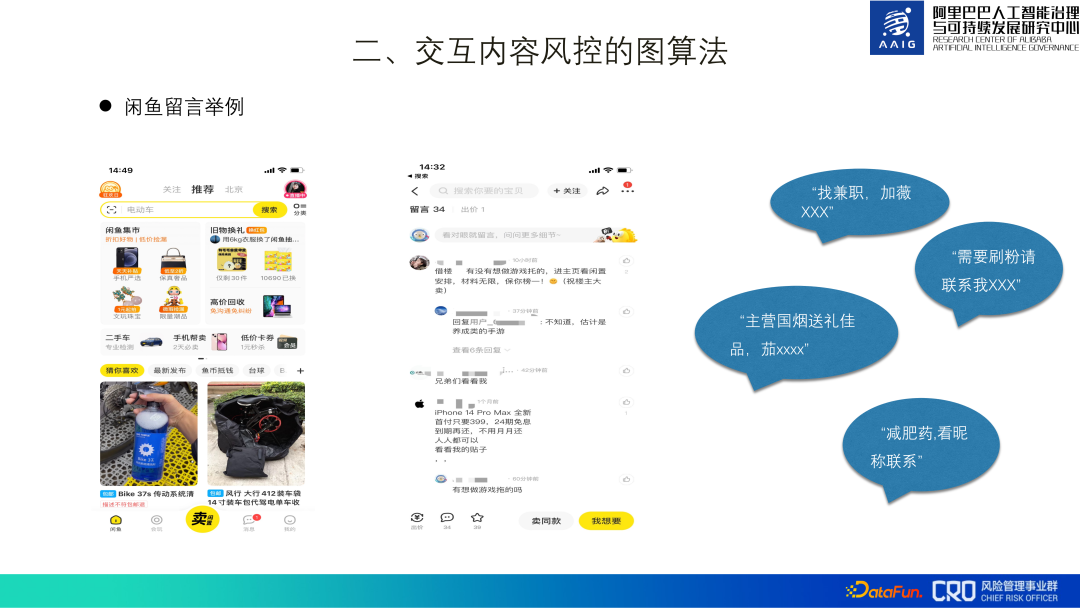
Adalah mudah untuk melihat "iklan spam" dalam ulasan produk dalam risiko Kandungan APP Xianyu seperti kerja sambilan, pesanan palsu, menjual pil penurunan berat badan, dsb., dan sangat berkonfrontasi Sebagai contoh, dalam tangkapan skrin di atas, "Abang, lihat saya," iklan sebenar bukan dalam teks itu sendiri, tetapi. pada halaman utama pengguna.
Pengenalpastian iklan spam dalam Xianyu Messages ialah senario aplikasi pertama bagi algoritma rangkaian saraf graf kami, singkatannya, model pengenalan ini GAS. Keseluruhan model terdiri daripada graf heterogen dan graf homogen. Graf heterogen mempelajari perwakilan tempatan setiap nod, termasuk produk, ulasan dan pengguna Graf homogen ialah graf ulasan yang mempelajari perwakilan global bagi ulasan yang berbeza Akhirnya, empat perwakilan ini disatukan untuk latihan model klasifikasi.
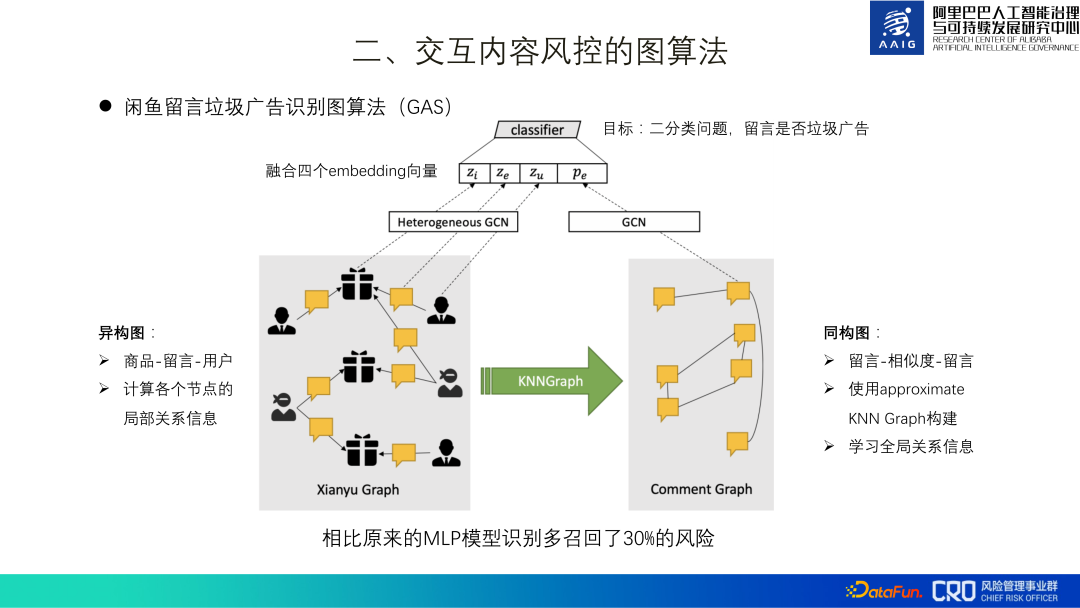
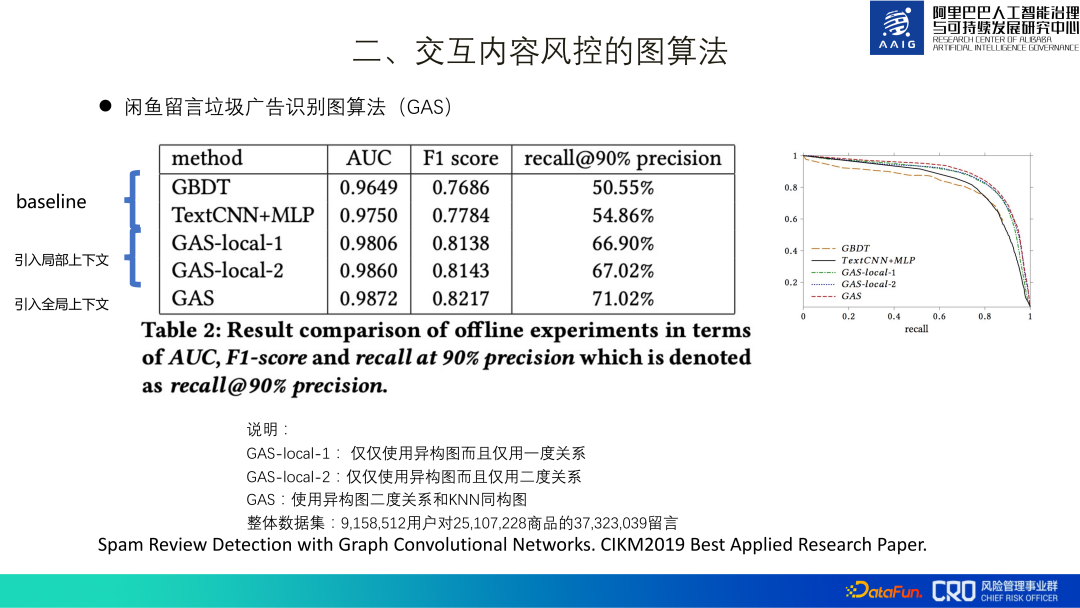
Set data latihan keseluruhan termasuk ulasan 3kw+, produk 2kw+ dan 9 juta+ pengguna Selepas pergi ke dalam talian, ia telah menarik balik risiko 30% daripada model MLP asal. Di samping itu, percubaan ablasi juga telah mengesahkan bahawa menambah maklumat global juga bertambah baik dengan ketara Ini disebabkan oleh ciri-ciri pengiklanan spam itu sendiri - ia memerlukan sejumlah besar pemajuan untuk mencapai faedah yang lebih baik. Karya ini akhirnya disusun dan diterbitkan dalam kertas[1], dan memenangi Kertas Penyelidikan Gunaan Terbaik CIKM2019.
3. >Di sini kami memperkenalkan terutamanya dua jenis algoritma graf untuk kawalan risiko kandungan produk: satu ialah pembelajaran struktur graf produk, dan satu lagi ialah penyepaduan struktur graf produk dan graf pengetahuan profesional.
 Pengurusan risiko komoditi adalah terutamanya untuk mengawal risiko "jualan terlarang dan jualan terhad". dilarang oleh undang-undang dan peraturan negara Untuk dijual, seperti haiwan dan tumbuhan yang dilindungi negara, penipuan dan pemalsuan, peranti perubatan terkawal, dsb.
Pengurusan risiko komoditi adalah terutamanya untuk mengawal risiko "jualan terlarang dan jualan terhad". dilarang oleh undang-undang dan peraturan negara Untuk dijual, seperti haiwan dan tumbuhan yang dilindungi negara, penipuan dan pemalsuan, peranti perubatan terkawal, dsb.
Pengurusan dan kawalan produk adalah sangat rumit Data produk ialah aliran berbilang data, berbilang saluran dan berbilang modal:
① Berbilang aliran data:
Tajuk, perihalan, imej utama, imej kedua, imej butiran, SKU; >② Berbilang saluran:
Bunyi, bentuk dan makna teks, RGB bagi gambar; 🎜>③ Berbilang modal: Teks, gambar, maklumat meta (harga, jualan).
Pada masa yang sama, risiko kandungan produk juga kompleks, pelbagai dan sengit dipertandingkan Contohnya dalam gambar di atas, nampaknya anda sedang menjual manik, tetapi sebenarnya anda menjual gading.
Terdapat dua jenis utama algoritma peta kawalan risiko kandungan produk: satu ialah model gabungan pelbagai mod, yang menggunakan model mendalam untuk membina saraf produk Rangkaian gabungan pelbagai mod menjalankan pembelajaran pelbagai tugas, yang merupakan pembelajaran maklumat tempatan barangan, yang lain adalah untuk meningkatkan penarikan semula risiko, menggunakan graf heterogen untuk mewujudkan hubungan antara barang dan barang, barang dan penjual; dan penjual, menjalankan pembelajaran gabungan maklumat global.1. Pembelajaran struktur graf bagi graf produk
Intipati GCN ialah pelicinan ciri yang menggabungkan ciri jiran, jadi Pembelajaran rangkaian neural graf mempunyai keperluan tertentu terhadap kualiti struktur graf Graf rangkaian yang baik adalah padat dan mempunyai kadar homogeniti yang tinggi. Walau bagaimanapun, graf produk risiko adalah jarang dan kadar homogeniti adalah agak rendah (0.15, dan statistik pada set data awam mendapati bahawa 0.6 atau ke atas adalah lebih baik), jadi kita mesti mempelajari struktur graf.
Terdapat tiga jenis tepi dalam gambar produk, yang membentuk tiga jenis gambar, seperti yang ditunjukkan dalam bingkai di sebelah kanan gambar di bawah: Satu jenis ialah Kedua-dua produk dijual oleh penjual yang sama dan mempunyai imej penjual yang sama Kategori kedua ialah imej semak imbas yang kedua-dua produk telah dilihat oleh pengguna yang sama kategori ialah imej penjual yang berkaitan di mana penjual kedua-dua produk itu sangat berkaitan.
Intipati pembelajaran struktur graf produk ialah proses menambah dan memadam tepi: pertama, gunakan Graf KNN untuk membina graf KNN berdasarkan pembenaman produk, dan kemudian letakkan empat di atas jenis tepi bersama-sama dengan pembenaman produk HGT mempelajari pembenaman produk baharu dan memadamkan tepi dengan nilai perhatian yang lebih rendah sebagai kebisingan. Amalan dalam data sebenar menunjukkan bahawa rangka kerja pembelajaran struktur graf ini mencapai keputusan SOTA berbanding dengan graf homogen/graf heterogen. 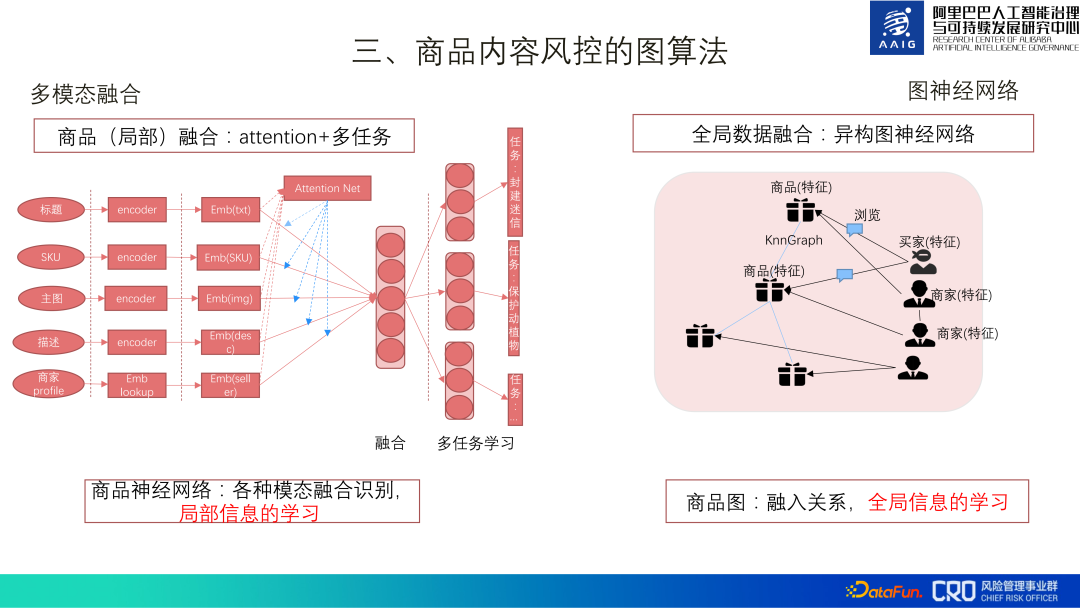
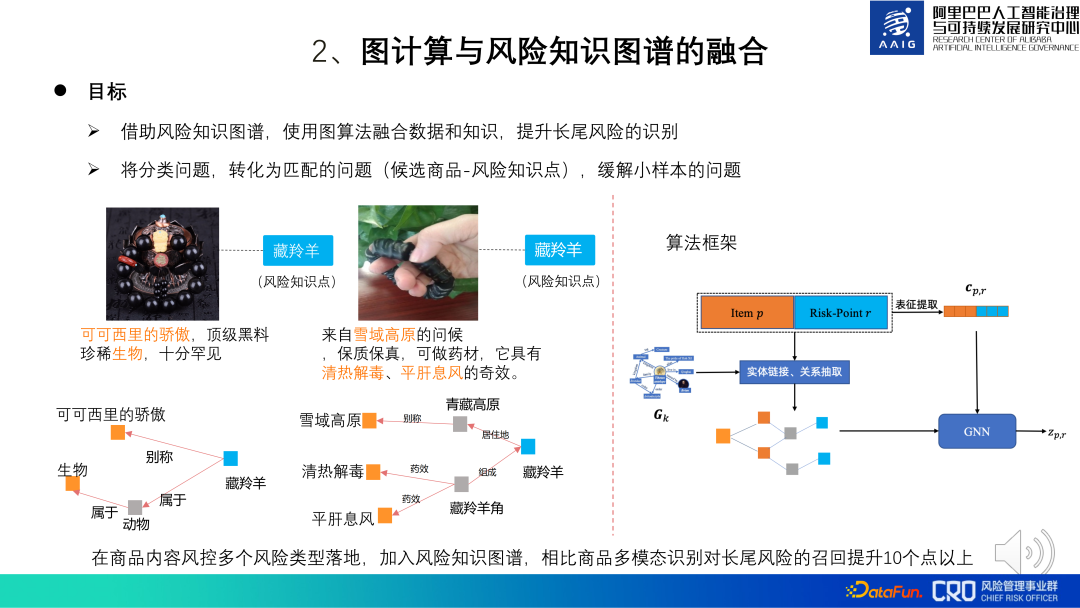
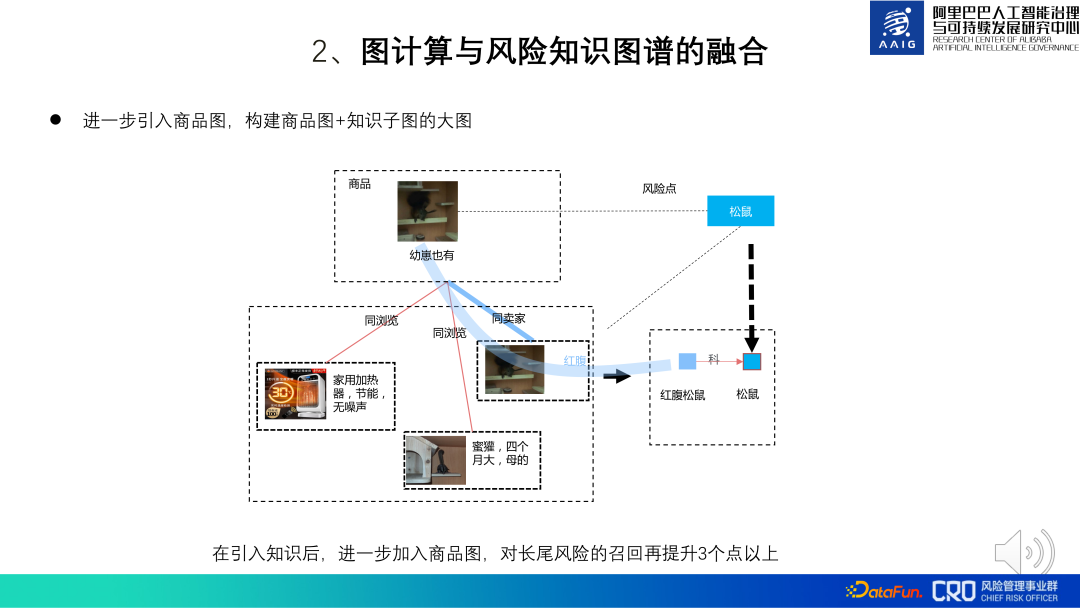
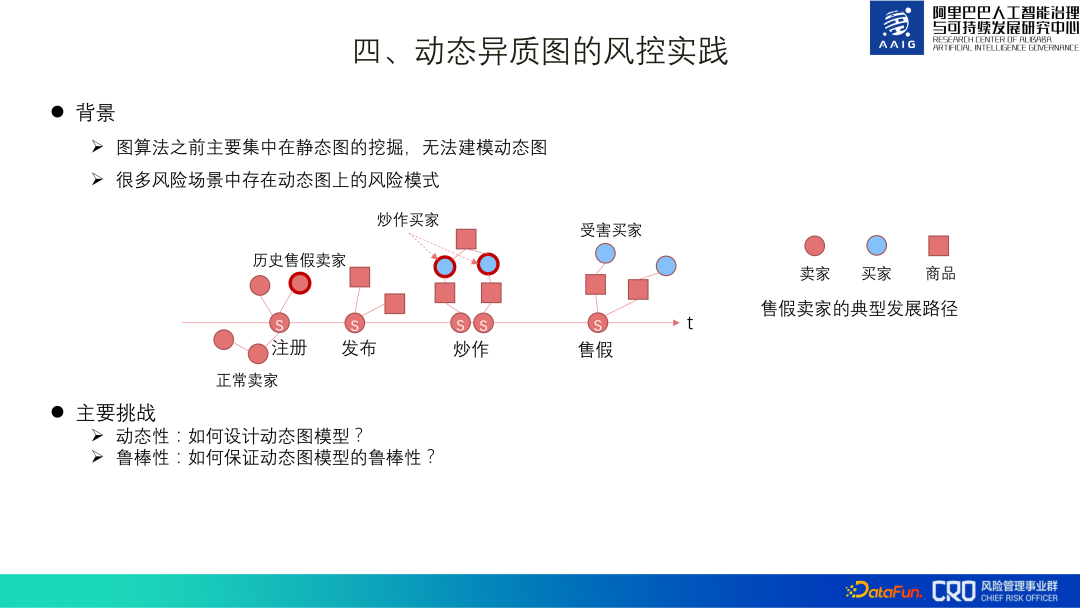
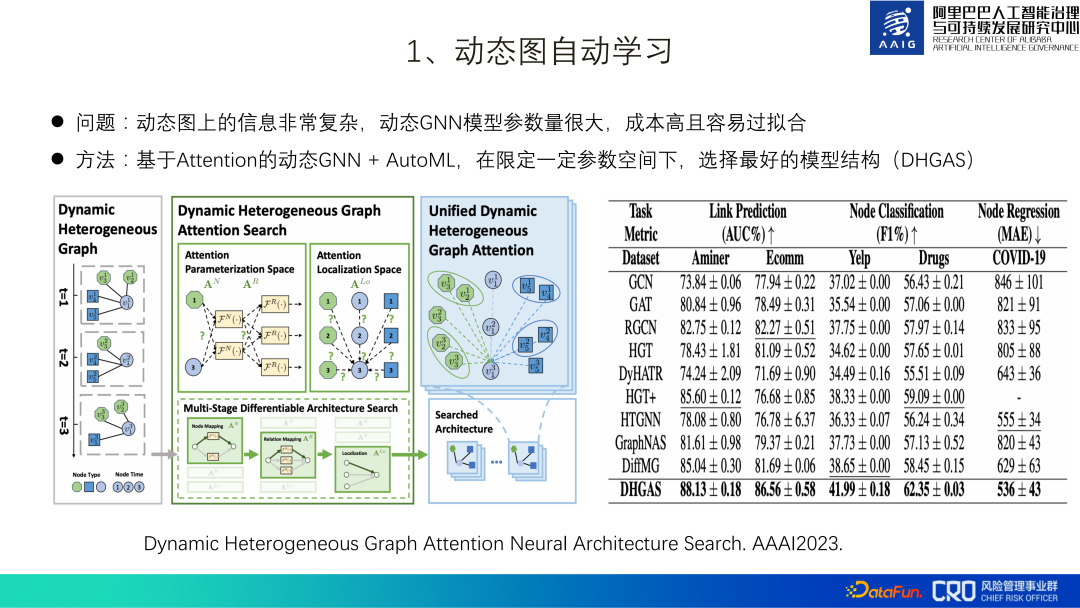
Algoritma penambahbaikan algoritma graf produk ialah gabungan pengkomputeran graf dan graf pengetahuan risiko. Sesetengah risiko komoditi sukar dinilai melalui akal dan memerlukan gabungan pengetahuan domain profesional tertentu. Oleh itu, graf pengetahuan khusus telah dibina untuk mata pengetahuan domain risiko khusus ini untuk membantu pengenalpastian model dan semakan manual. Sebagai contoh, kedua-dua produk yang ditunjukkan di sebelah kiri gambar di bawah nampaknya menjual aksesori ringkas, tetapi mereka sebenarnya menjual tanduk antelop Tibet, dan Antelop Tibet ialah haiwan kebangsaan Ia adalah haiwan yang dilindungi peringkat pertama dan produk berkaitannya adalah diharamkan. Kita boleh mengenal pasti risiko produk ini dengan memadankannya dengan pengetahuan yang berkaitan dengan antelop Tibet. Rangka kerja algoritma gabungan ditunjukkan di sebelah kanan rajah di bawah: matlamat model adalah untuk menentukan sama ada produk calon dan mata pengetahuan risiko sepadan. Item p ialah perwakilan grafik produk, dan Titik Risiko R ialah perwakilan titik pengetahuan Melalui pengiktirafan entiti, pemautan entiti dan pengekstrakan perhubungan, subgraf produk dan titik pengetahuan diperoleh, dan kemudian GNN digunakan. untuk mengira perwakilan subgraf, dan akhirnya perwakilan digunakan Menjalankan klasifikasi dan pengenalpastian risiko. Antaranya, CPR ialah gabungan perwakilan produk dan perwakilan titik pengetahuan Ia digunakan terutamanya untuk membimbing perwakilan graf untuk mempelajari beberapa maklumat global. Amalan menunjukkan bahawa berbanding dengan pengiktirafan pelbagai mod produk, penarikan balik risiko jangka panjang dipertingkatkan sebanyak lebih daripada 10 mata dengan menambahkan graf pengetahuan risiko. Atas dasar ini, kami juga cuba memperkenalkan peta produk global. Apabila kandungan produk berkaitan secara langsung dengan peta pengetahuan dan risikonya tidak dapat dikenal pasti, anda boleh memperkenalkan perkaitan antara produk dan produk untuk membantu dalam pertimbangan Contohnya, dalam gambar di bawah, produk bertanda "Ada juga cubs" dan "tupai perut merah" tidak mempunyai pengetahuan yang kukuh. Terdapat hubungan yang sepadan, tetapi produk ini sepadan dengan pengetahuan penjual tentang produk lain "tupai perut merah" dan "tupai perut merah", jadi boleh disimpulkan bahawa produk sebenarnya menjual tupai perut merah (haiwan dilindungi sekunder, dilarang untuk dijual). Amalan telah menunjukkan bahawa memperkenalkan keseluruhan graf produk besar apabila melakukan penaakulan pengetahuan boleh meningkatkan penarikan semula risiko ekor panjang lebih daripada 3%. Sebelumnya algoritma graf yang diperkenalkan adalah terutamanya aplikasi perlombongan graf statik, tetapi banyak senario risiko mempunyai corak risiko graf dinamik. Contohnya, peniaga yang menjual barangan tiruan mula-mula mendaftar, kemudian mengeluarkan sejumlah besar produk secara berkelompok, menggembar-gemburkan untuk menarik trafik, dan kemudian dengan cepat menjual barangan tiruan barang. Dalam siri tindakan ini, dimensi masa ialah Perubahan dalam struktur graf adalah sangat penting untuk pengenalpastian risiko kami, jadi graf dinamik juga merupakan arah utama dalam penerokaan dan aplikasi algoritma graf. Cabaran terbesar graf dinamik ialah cara mereka bentuk dan mencari struktur graf yang baik. Di satu pihak, graf dinamik memperkenalkan dimensi masa berdasarkan graf heterogen asal Contohnya, jika terdapat 30 momen, maka parameter (jumlah maklumat) graf dinamik adalah 30 kali ganda daripada graf heterogen, yang membawa besar. tekanan kepada pembelajaran; Sebaliknya, disebabkan sifat risiko yang bertentangan, graf dinamik perlu sangat teguh. Menurut ini, kami mencadangkan GNN dinamik berasaskan pada Attention + AutoML, pilih struktur model terbaik (DHGAS) di bawah ruang parameter tertentu. Teras model ini adalah untuk mengoptimumkan struktur model melalui pembelajaran automatik, seperti yang ditunjukkan dalam rajah di bawah: Pertama sekali lebih disukai untuk menguraikan graf dinamik kepada graf heterogen pada momen yang berbeza, dan menetapkan ruang fungsi yang berbeza pada momen dan nod yang berbeza kepada mewakili perubahan dalam perwakilan produk (jenis N*T, N: jenis nod; T: ruang masa), ruang fungsi yang berbeza juga disediakan untuk momen yang berbeza dan jenis tepi yang berbeza untuk mewakili ruang laluan penyebaran maklumat (R*T jenis, R: jenis tepi; T : masa dan ruang), dan akhirnya terdapat kaedah pengagregatan R*T*T apabila nod dan jiran diagregatkan (dua T ialah cap waktu nod pada kedua-dua hujung tepi. Jelas sekali keseluruhan ruang carian adalah besar Kami cuba mengehadkan ruang parameter dan menggunakan teknologi pembelajaran mesin automatik untuk membina supernet supaya model boleh mencari seni bina rangkaian yang optimum. Kaedah khusus: hadkan bilangan ruang fungsi N*T kepada K_N, data ruang fungsi R*T kepada K_R, dan panjang modul R*T*T kepada K_Lo Sebagai contoh, N=6, T=30 , teorinya ialah N*T=180 ruang fungsi, had sebenar ialah K_N=10. Algoritma ini pada masa ini telah digunakan pada senario seperti "pengenalpastian penjual tiruan" dan "pengenalpastian pedagang berniat jahat dengan jualan barangan terhad", dan berbanding dengan algoritma arus perdana dalam industri, ia telah memperoleh keputusan SOTA. Untuk butiran, anda boleh menyemak kertas [ 2]. 2. Integrasi pengkomputeran graf dan graf pengetahuan risiko
4. Amalan kawalan risiko graf heterogen dinamik
1. Pembelajaran automatik graf dinamik
2. Grafik dinamik pembelajaran mantap
kerana sifat konfrontasi risiko , grafik dinamik perlu mempunyai keteguhan yang kuat, dan intipatinya ialah Saya berharap grafik dinamik dapat mempelajari beberapa corak penting Contohnya, corak penting subgraf contoh dalam rajah di bawah ialah peningkatan ais penjualan krim disebabkan cuaca Semakin panas, bukan lagi lemas.
Kami berharap pembelajaran yang mantap dapat menyelesaikan beberapa masalah anjakan pengedaran dalam graf dinamik kawalan risiko e-dagang:
(1) Mengimbangi ciri : Contohnya, jika anda terlalu bergantung pada ciri seperti maklumat pelanggaran sejarah, penarikan balik ahli bermasalah yang baru didaftarkan akan menjadi lemah ;
(2) Anjakan struktur : Contohnya, terlalu bergantung pada substruktur ketumpatan darjah ahli pengiklanan spam akan menyebabkan panggilan palsu aktif bagi ahli biasa; akan mengikuti proses pencegahan dan kawalan Perubahan tingkah laku yang ketara berlaku.
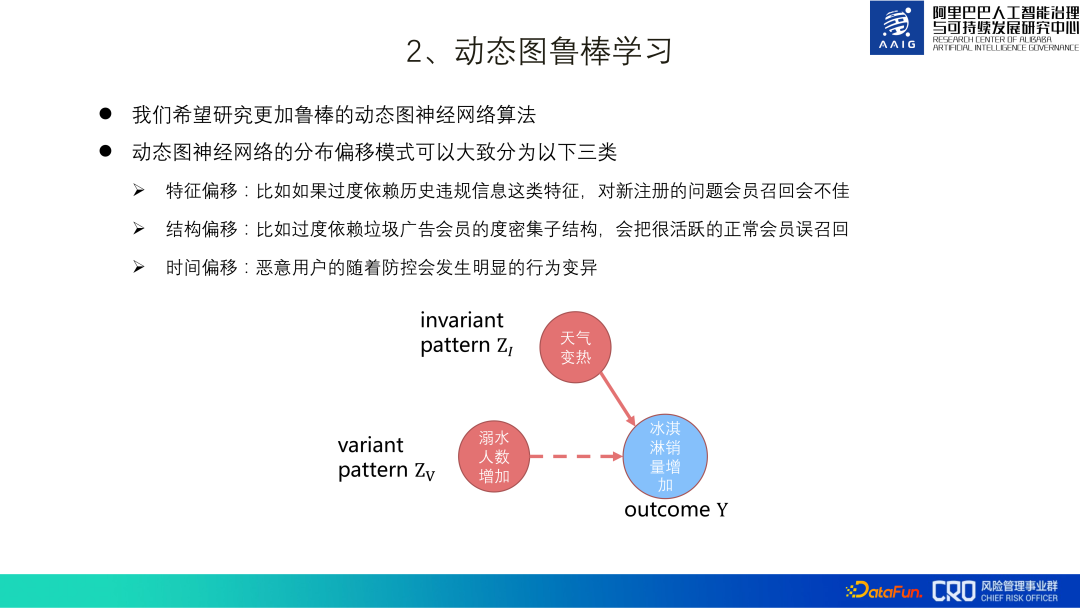
Dalam hal ini, kami mencadangkan algoritma DIDA Idea teras adalah seperti yang ditunjukkan dalam rajah di bawah: pelajari dua corak semasa mempelajari graf dinamik -. oren Corak penting yang diwakili dan corak tidak penting diwakili oleh hijau, hanya kehilangan (L) corak penting + varians kehilangan (Ldo) gabungan corak bukan penting digunakan sebagai kehilangan akhir yang dipelajari oleh model . Idea reka bentuk varians kehilangan (Ldo) gabungan corak tidak penting ialah: dengan mengandaikan bahawa a3 hijau dalam gambar adalah corak tidak penting, kemudian menggantikan a3 hijau ini dengan corak tidak penting yang lain seperti b3, c3, dsb. harus memperbaiki kehilangan (diskriminasi) kebolehan model) mempunyai sedikit impak. Oleh itu, kita boleh menambah varians kehilangan corak tidak penting kepada pembelajaran model, dan dalam peringkat ramalan akhir, hanya corak penting digunakan untuk pengelasan. Pada masa ini, algoritma ini telah dilaksanakan dalam senario kawalan risiko kandungan produk, dan kertas[3] juga telah disusun.
 5. Pertandingan ICDM2022: Pengesanan Produk Berisiko pada Peta E-dagang Berskala Besar
5. Pertandingan ICDM2022: Pengesanan Produk Berisiko pada Peta E-dagang Berskala Besar
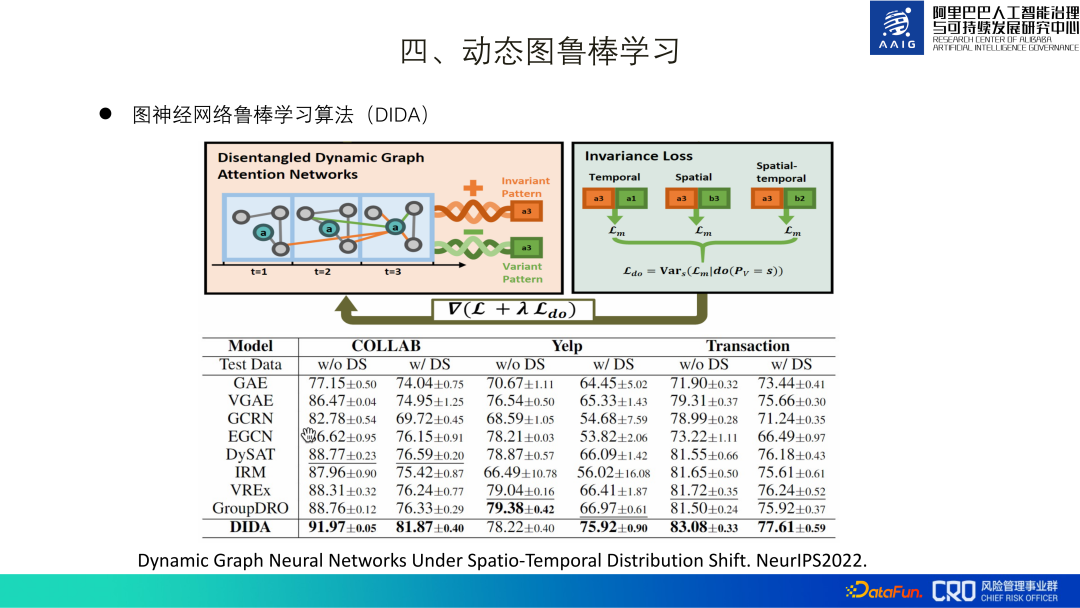
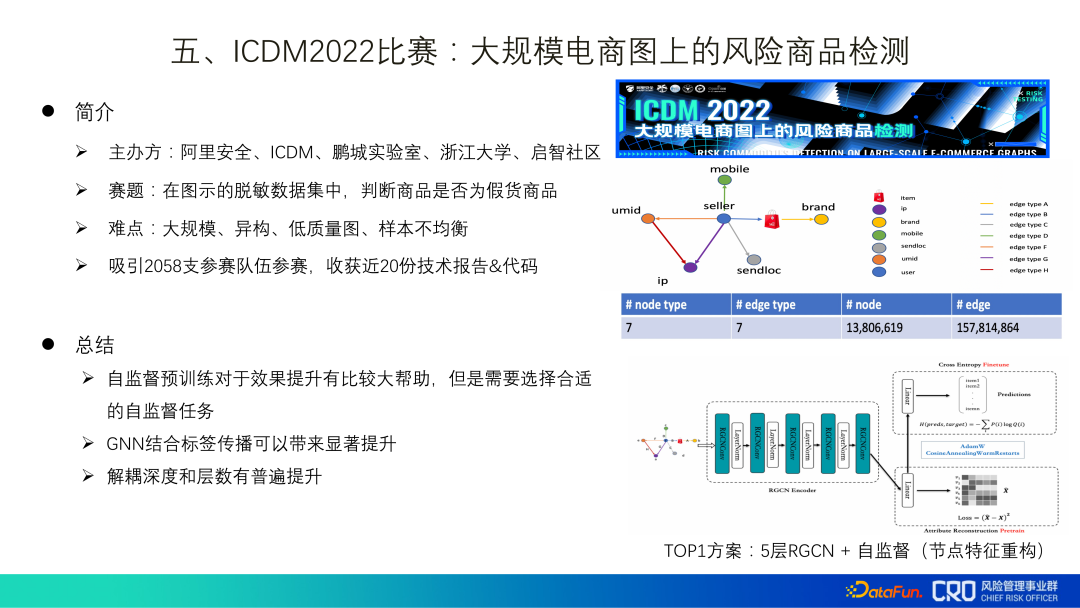
<.> "Persaingan ICDM2022: Pengesanan Produk Berisiko pada Graf E-dagang Berskala Besar" ialah pertandingan algoritma yang kami hos tahun ini, dan data yang diberikan ialah data yang tidak sensitif daripada senario sebenar. Akhirnya, saya juga mendapat inspirasi daripada kod dan laporan teknikal yang diserahkan:
6 Ringkasan dan pandangan tentang pelaksanaan algoritma graf
Digabungkan dengan kami. pengalaman, Kaedah pelaksanaan algoritma graf berikut diringkaskan:
(1) Rangka kerja/platform algoritma graf: Perlu ada rangka kerja algoritma graf untuk mengumpul teknologi dan terbaik amalan dan meningkatkan kebolehgunaan semula teknologi.
(2) Pemodelan separa automatik: Untuk meningkatkan kecekapan pemodelan, pada peringkat data kami lebih baik membersihkan dan meringkaskan media perhubungan yang mendasari data , beberapa komponen (komponen pemilihan MetaPath/MetaGraph, komponen pensampelan graf, komponen pengambilan vektor, dll.) boleh disediakan pada peringkat pemodelan untuk meningkatkan kecekapan pemodelan.
(3) Panggilan automatik: Ia boleh memanggil algoritma graf atau model graf secara automatik yang hanya bergantung pada sampel input Tidak perlu memahami model graf, yang adalah mudah untuk orang lain yang tidak biasa dengan algoritma graf, pelajar kawalan risiko menjalankan pengoptimuman dan penggunaan model, seperti pengenalan kumpulan, pemulihan produk, pemulihan pengguna yang berisiko, dsb.
(4) Perwakilan graf pengeluaran (diawasi sendiri): digunakan sebagai input modal yang berasingan ke dalam model, tanpa menjejaskan kaedah pemodelan asal, sangat dipertingkatkan Rajah senario aplikasi.

Pandangan kerja susulan:
( 1) Pembelajaran perwakilan penyeliaan kendiri graf berskala besar. Kami mempunyai beribu-ribu model risiko, kebanyakannya tidak menggunakan algoritma graf di atas, jadi langkah seterusnya kami ialah melakukan perwakilan penyeliaan sendiri graf berskala besar untuk mengembangkan julat aplikasi ciri graf dan membantu meningkatkan hasil perniagaan. Kerja ini mempunyai dua cabaran dalam kejuruteraan dan algoritma: Pertama, dari segi kejuruteraan, kami mempunyai sekurang-kurangnya berbilion-bilion nod dan berpuluh-puluh bilion tepi untuk pembelajaran berskala besar Kedua, dari segi algoritma, perwakilan graf mestilah bukan sahaja meliputi perkara biasa perwakilan perhubungan yang digunakan, Anda juga perlu mempelajari ciri-ciri struktur graf peringkat tinggi, yang sangat serba boleh dan boleh digunakan pada pelbagai senario.
(2) Terokai keupayaan penaakulan graf dalam senario kawalan risiko tertentu Pada masa ini, algoritma graf lebih kepada gabungan pengetahuan dan keupayaan penaakulan adalah agak lemah , tidak mampu menghadapi antagonisme risiko yang tinggi. Secara objektif kita memerlukan model kita untuk mempunyai kecerdasan yang kuat, jadi keupayaan penaakulan graf adalah sangat penting. Pada masa ini, ia dirancang untuk bergantung pada senario interaktif yang kaya dan kandungan komuniti Xianyu untuk meneroka algoritma.
(3) Lebih banyak penerokaan dan pelaksanaan dalam penyelidikan domain frekuensi dan kebolehtafsiran graf heterogen dinamik. Tujuan penyelidikan domain frekuensi adalah untuk mengetahui lebih banyak butiran tentang perubahan struktur graf dalam graf dinamik. Kebolehtafsiran membantu kami memahami sama ada algoritma telah benar-benar mempelajari ciri-ciri penting Di satu pihak, ia membantu kami meningkatkan algoritma, dan sebaliknya, ia juga boleh diberikan dengan lebih baik kepada pelajar perniagaan untuk pelaksanaan aplikasi.

Kami juga memohon kerjasama akademik dalam arah penerokaan di atas, terutamanya dalam arah penaakulan graf. Pada masa yang sama, kami juga mengambil pelajar untuk algoritma graf pelajar yang berminat boleh menghubungi saya.
7. Rujukan
1 🎜>
2. Carian Seni Bina Neural Graf Heterogen Dinamik Rangkaian Neural Graf Di Bawah Anjakan Taburan Spatio-Temporal NeurIPS2022.
8. Sesi Soal Jawab
S1: Apakah cabaran khas bagi perwakilan graf bagi senario kawalan risiko, berbanding dengan perwakilan graf dalam bidang lain?
A1: Tiga cabaran utama: pertama, struktur graf adalah lemah dan kadar homogeniti adalah rendah, kedua, keteguhan graf, dalam senario kami Terutamanya untuk dinamik graf, hanyut pengedarannya masih sangat serius Terdapat satu lagi masalah Kepekatan risiko sampel hitam adalah sangat rendah 1:1w+, jadi sampel kami sangat tidak seimbang, itulah yang perlu kami selesaikan.
S2: Apakah model algoritma semasa pembelajaran bersekutu graf Adakah terdapat penyelesaian yang matang dalam industri? Adakah anda mempunyai sebarang aplikasi atau pertimbangan untuk pembelajaran bersekutu graf?
J2: Kami masih menggunakannya terutamanya dalam senario e-dagang kami. Sudah tentu kami juga mempunyai beberapa perniagaan bukan e-dagang, tetapi data ini adalah milik kami masih Ia boleh digunakan secara langsung untuk kawalan risiko, jadi pembelajaran bersekutu belum digunakan lagi, tetapi masih perlu menggunakan pembelajaran bersekutu graf kemudian, kerana data sedang dipotong dan diasingkan untuk keselamatan maklumat, dan data daripada domain yang berbeza tidak boleh disambungkan dan digunakan , jadi pembelajaran bersekutu graf harus menjadi hala tuju aplikasi untuk kita terokai kemudian.
Atas ialah kandungan terperinci Amalan algoritma graf dalam sistem kawalan risiko Alibaba. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI