
Rumah >pembangunan bahagian belakang >Tutorial Python >Apakah kaedah visualisasi data Python yang pantas dan mudah digunakan?
Apakah kaedah visualisasi data Python yang pantas dan mudah digunakan?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-29 17:34:161302semak imbas
Penggambaran data ialah bahagian yang sangat penting dalam sains data atau projek pembelajaran mesin. Biasanya, anda perlu melakukan analisis data penerokaan (EDA) awal dalam projek untuk mendapatkan sedikit pemahaman tentang data, dan mencipta visualisasi benar-benar boleh menjadikan tugas analisis lebih jelas dan lebih mudah difahami, terutamanya untuk data berskala besar dan berdimensi tinggi. . Menjelang penghujung projek, penting juga untuk membentangkan hasil akhir dengan cara yang jelas, ringkas dan menarik yang boleh difahami oleh khalayak anda (yang selalunya bukan pelanggan teknikal).
Peta Haba
Kaedah menggunakan warna untuk mewakili nilai setiap elemen dalam matriks data dipanggil Peta Haba. Melalui pengindeksan matriks, dua item atau ciri yang perlu dibandingkan dikaitkan dan warna yang berbeza digunakan untuk mewakili nilai yang berbeza. Peta haba sesuai untuk memaparkan hubungan antara pembolehubah ciri berbilang kerana warna boleh mencerminkan secara langsung saiz elemen matriks pada kedudukan tersebut. Anda boleh membandingkan setiap perhubungan dengan perhubungan lain dalam set data melalui titik lain dalam peta haba. Kerana sifat warna yang intuitif, ia memberikan kita cara yang mudah dan mudah difahami untuk mentafsir data.
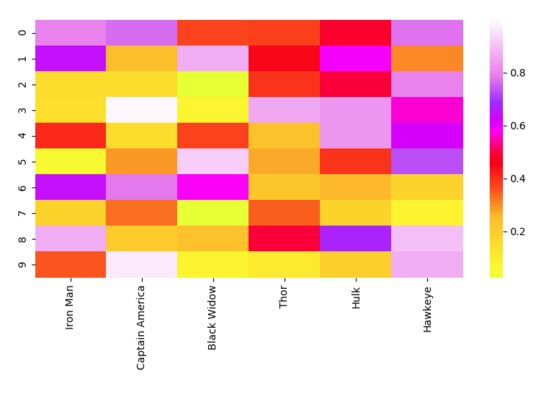
Sekarang mari kita lihat kod pelaksanaan. Berbanding dengan "matplotlib", "seaborn" boleh digunakan untuk melukis grafik yang lebih maju, yang biasanya memerlukan lebih banyak komponen, seperti berbilang warna, grafik atau pembolehubah. "matplotlib" boleh digunakan untuk memaparkan grafik, "NumPy" boleh digunakan untuk menjana data, dan "pandas" boleh digunakan untuk memproses data! Lukisan hanyalah fungsi mudah "seaborn".
# Importing libs import seaborn as sns import pandas as pd import numpy as np import matplotlib.pyplot as plt # Create a random dataset data = pd.DataFrame(np.random.random((10,6)), columns=["Iron Man","Captain America","Black Widow","Thor","Hulk", "Hawkeye"]) print(data) # Plot the heatmap heatmap_plot = sns.heatmap(data, center=0, cmap='gist_ncar') plt.show()
Plot ketumpatan dua dimensi
Plot ketumpatan dua dimensi (Plot Ketumpatan 2D) ialah lanjutan intuitif versi satu dimensi bagi plot ketumpatan versi, kelebihannya ialah ia dapat melihat hubungan antara dua taburan kebarangkalian pembolehubah. Plot skala di sebelah kanan menggunakan warna untuk mewakili kebarangkalian setiap titik dalam plot ketumpatan 2D di bawah. Tempat di mana data kami mempunyai kebarangkalian kejadian tertinggi (iaitu, di mana titik data paling tertumpu) nampaknya adalah sekitar saiz=0.5 dan kelajuan=1.4. Seperti yang anda ketahui sekarang, plot ketumpatan 2D sangat berguna untuk mencari dengan cepat kawasan di mana data kami paling tertumpu dengan dua pembolehubah, berbanding hanya satu pembolehubah seperti plot ketumpatan 1D. Memerhati data dengan plot ketumpatan dua dimensi berguna apabila anda mempunyai dua pembolehubah yang penting kepada output dan ingin memahami cara ia berfungsi bersama untuk menyumbang kepada pengagihan output.
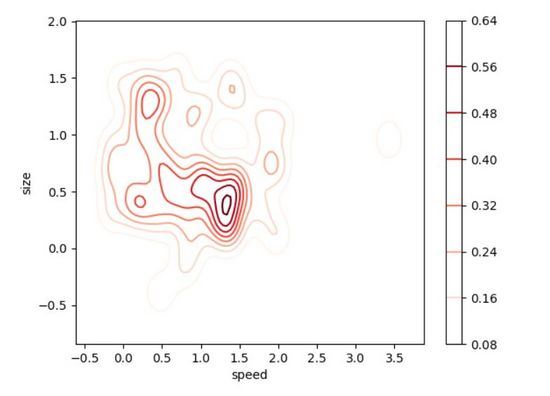
Fakta sekali lagi membuktikan bahawa menggunakan "seaborn" untuk menulis kod adalah sangat mudah! Kali ini, kami akan mencipta pengedaran yang condong untuk menjadikan visualisasi data lebih menarik. Anda boleh melaraskan kebanyakan parameter pilihan untuk menjadikan visualisasi kelihatan lebih jelas.
# Importing libs import seaborn as sns import matplotlib.pyplot as plt from scipy.stats import skewnorm # Create the data speed = skewnorm.rvs(4, size=50) size = skewnorm.rvs(4, size=50) # Create and shor the 2D Density plot ax = sns.kdeplot(speed, size, cmap="Reds", shade=False, bw=.15, cbar=True) ax.set(xlabel='speed', ylabel='size') plt.show()
Plot labah-labah
Plot labah-labah ialah salah satu cara terbaik untuk memaparkan perhubungan satu-dengan-banyak.. Dengan kata lain, anda boleh memplot dan melihat nilai berbilang pembolehubah berhubung dengan pembolehubah atau kategori tertentu. Dalam gambar rajah web labah-labah, kepentingan satu pembolehubah berbanding yang lain adalah jelas dan jelas kerana kawasan yang diliputi dan panjang dari pusat menjadi lebih besar dalam arah tertentu. Anda boleh memplot kategori objek yang berbeza yang diterangkan oleh pembolehubah ini bersebelahan untuk melihat perbezaan antara mereka. Dalam carta di bawah, adalah mudah untuk membandingkan sifat berbeza Avengers dan melihat di mana mereka masing-masing cemerlang! (Sila ambil perhatian bahawa data ini ditetapkan secara rawak dan saya tidak berat sebelah terhadap ahli Avengers.)
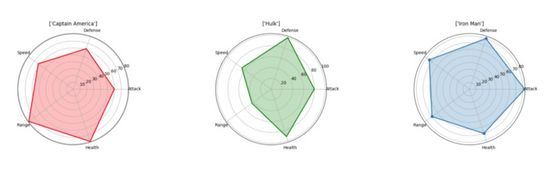
Kita boleh menggunakan "matplotlib" untuk menjana hasil visualisasi, dan Tidak perlu menggunakan "seaborn". Kita perlu mempunyai setiap atribut sama jarak di sekeliling lilitan. Akan ada label pada setiap sudut dan kami akan memplot nilai sebagai titik yang jaraknya dari pusat adalah berkadar dengan nilai/saiznya. Untuk menunjukkan ini dengan lebih jelas, kami akan mengisi kawasan yang dibentuk oleh garisan yang menghubungkan titik harta dengan warna separa lutsinar.
# Import libs
import pandas as pd
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
# Get the data
df=pd.read_csv("avengers_data.csv")
print(df)
"""
# Name Attack Defense Speed Range Health
0 1 Iron Man 83 80 75 70 70
1 2 Captain America 60 62 63 80 80
2 3 Thor 80 82 83 100 100
3 3 Hulk 80 100 67 44 92
4 4 Black Widow 52 43 60 50 65
5 5 Hawkeye 58 64 58 80 65
"""
# Get the data for Iron Man
labels=np.array(["Attack","Defense","Speed","Range","Health"])
stats=df.loc[0,labels].values
# Make some calculations for the plot
angles=np.linspace(0, 2*np.pi, len(labels), endpoint=False)
stats=np.concatenate((stats,[stats[0]]))
angles=np.concatenate((angles,[angles[0]]))
# Plot stuff
fig = plt.figure()
ax = fig.add_subplot(111, polar=True)
ax.plot(angles, stats, 'o-', linewidth=2)
ax.fill(angles, stats, alpha=0.25)
ax.set_thetagrids(angles * 180/np.pi, labels)
ax.set_title([df.loc[0,"Name"]])
ax.grid(True)
plt.show()Peta Pokok
Kami telah belajar menggunakan peta pokok sejak sekolah rendah. Kerana rajah pokok secara semula jadi intuitif, ia mudah difahami. Nod yang bersambung secara langsung adalah berkait rapat, manakala nod dengan berbilang sambungan kurang serupa. Dalam visualisasi di bawah, saya memplot dendrogram subset kecil set data permainan Pokemon berdasarkan statistik Kaggle (kesihatan, serangan, pertahanan, serangan khas, pertahanan khas, kelajuan).
因此,统计意义上最匹配的口袋妖怪将被紧密地连接在一起。例如,在图的顶部,阿柏怪 和尖嘴鸟是直接连接的,如果我们查看数据,阿柏怪的总分为 438,尖嘴鸟则为 442,二者非常接近!但是如果我们看看拉达,我们可以看到其总得分为 413,这和阿柏怪、尖嘴鸟就具有较大差别了,所以它们在树状图中是被分开的!当我们沿着树往上移动时,绿色组的口袋妖怪彼此之间比它们和红色组中的任何口袋妖怪都更相似,即使这里并没有直接的绿色的连接。
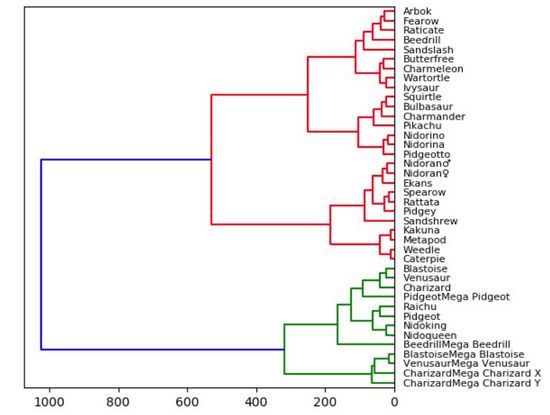
实际上,我们需要使用「Scipy」来绘制树状图。一旦读取了数据集中的数据,我们就会删除字符串列。这么做只是为了使可视化结果更加直观、便于理解,但在实践中,将这些字符串转换为分类变量会得到更好的结果和对比效果。我们还创建了数据帧的索引,以方便在每个节点上正确引用它的列。告诉大家的最后一件事是:在“Scipy”中,计算和绘制树状图只需一行简单代码。
# Import libs import pandas as pd from matplotlib import pyplot as plt from scipy.cluster import hierarchy import numpy as np # Read in the dataset # Drop any fields that are strings # Only get the first 40 because this dataset is big df = pd.read_csv('Pokemon.csv') df = df.set_index('Name') del df.index.name df = df.drop(["Type 1", "Type 2", "Legendary"], axis=1) df = df.head(n=40) # Calculate the distance between each sample Z = hierarchy.linkage(df, 'ward') # Orientation our tree hierarchy.dendrogram(Z, orientation="left", labels=df.index) plt.show()
Atas ialah kandungan terperinci Apakah kaedah visualisasi data Python yang pantas dan mudah digunakan?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!