
Rumah >Peranti teknologi >AI >Semua orang memahami ChatGPT Bab 1: ChatGPT dan pemprosesan bahasa semula jadi
Semua orang memahami ChatGPT Bab 1: ChatGPT dan pemprosesan bahasa semula jadi

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-29 15:54:591407semak imbas

ChatGPT (Chat Generative Pre-training Transformer) ialah model AI yang tergolong dalam bidang Natural Language Processing (NLP ialah cabang kecerdasan buatan). Apa yang dipanggil bahasa semula jadi merujuk kepada bahasa Inggeris, Cina, Jerman, dsb. yang orang
bersentuhan dan menggunakannya dalam kehidupan seharian mereka. Pemprosesan bahasa semula jadi merujuk kepada membenarkan komputer memahami dan mengendalikan bahasa semula jadi dengan betul untuk menyelesaikan tugas yang ditentukan oleh manusia. Tugas biasa dalam NLP termasuk pengekstrakan kata kunci daripada teks, klasifikasi teks, terjemahan mesin, dsb.
Terdapat satu lagi tugas yang sangat sukar dalam NLP: sistem dialog, yang juga boleh dipanggil secara umumnya sebagai chatbot, adalah apa yang dicapai oleh ChatGPT.
ChatGPT dan Ujian Turing
Sejak kemunculan komputer pada tahun 1950-an, orang ramai telah mula mengkaji bagaimana komputer boleh membantu manusia dalam memahami dan memproses bahasa semula jadi bidang NLP yang paling terkenal adalah ujian Turing.
Pada tahun 1950, Alan Turing, bapa kepada komputer, memperkenalkan ujian untuk memeriksa sama ada mesin boleh berfikir seperti manusia Ujian ini dipanggil ujian Turing. Kaedah ujian khususnya adalah sama dengan kaedah ChatGPT semasa, iaitu membina sistem dialog komputer, di mana seseorang dan model yang diuji bercakap antara satu sama lain Jika orang itu tidak dapat membezakan sama ada pihak lain adalah model mesin atau orang lain, ini bermakna model itu telah lulus Selepas lulus ujian Turing, komputer itu pintar.
Sejak sekian lama, ujian Turing telah dianggap oleh kalangan akademik sebagai kemuncak yang sukar difahami. Disebabkan ini, NLP juga dikenali sebagai permata mahkota kecerdasan buatan. Kerja yang boleh dilakukan oleh ChatGPT jauh melebihi skop robot sembang Ia boleh menulis artikel mengikut arahan pengguna, menjawab soalan teknikal, melakukan masalah matematik, melakukan terjemahan bahasa asing, bermain permainan perkataan, dsb. Jadi, dalam satu cara, ChatGPT telah mengambil permata mahkota.
Borang pemodelan ChatGPT
Borang kerja ChatGPT adalah sangat mudah Jika pengguna bertanyakan sebarang soalan kepada ChatGPT, model akan menjawabnya.

Antaranya, input pengguna dan output model kedua-duanya dalam bentuk teks. Satu input pengguna dan satu output yang sepadan daripada model dipanggil perbualan. Kita boleh mengabstrak model ChatGPT ke dalam proses berikut:
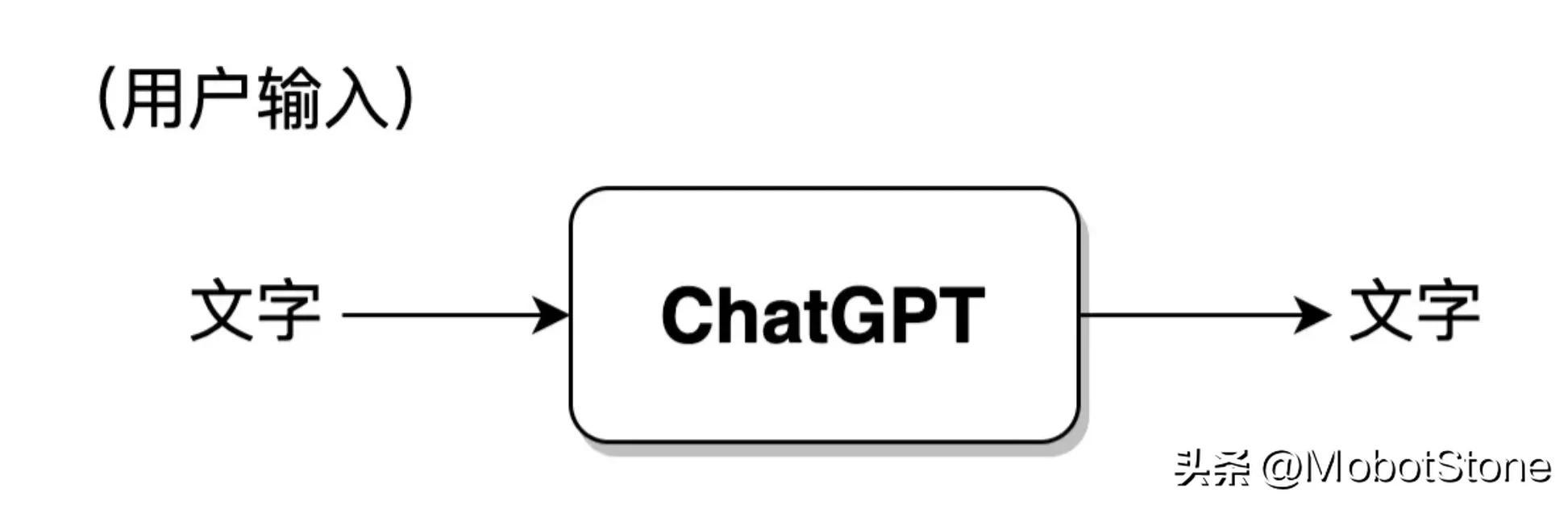
Selain itu, ChatGPT juga boleh menjawab soalan berterusan daripada pengguna, iaitu, beberapa pusingan dialog, dan terdapat Maklumat berkaitan. Bentuk khususnya juga sangat mudah Apabila pengguna memasukkan untuk kali kedua, sistem akan menggabungkan maklumat input dan output kali pertama secara lalai untuk ChatGPT merujuk kepada maklumat perbualan terakhir.
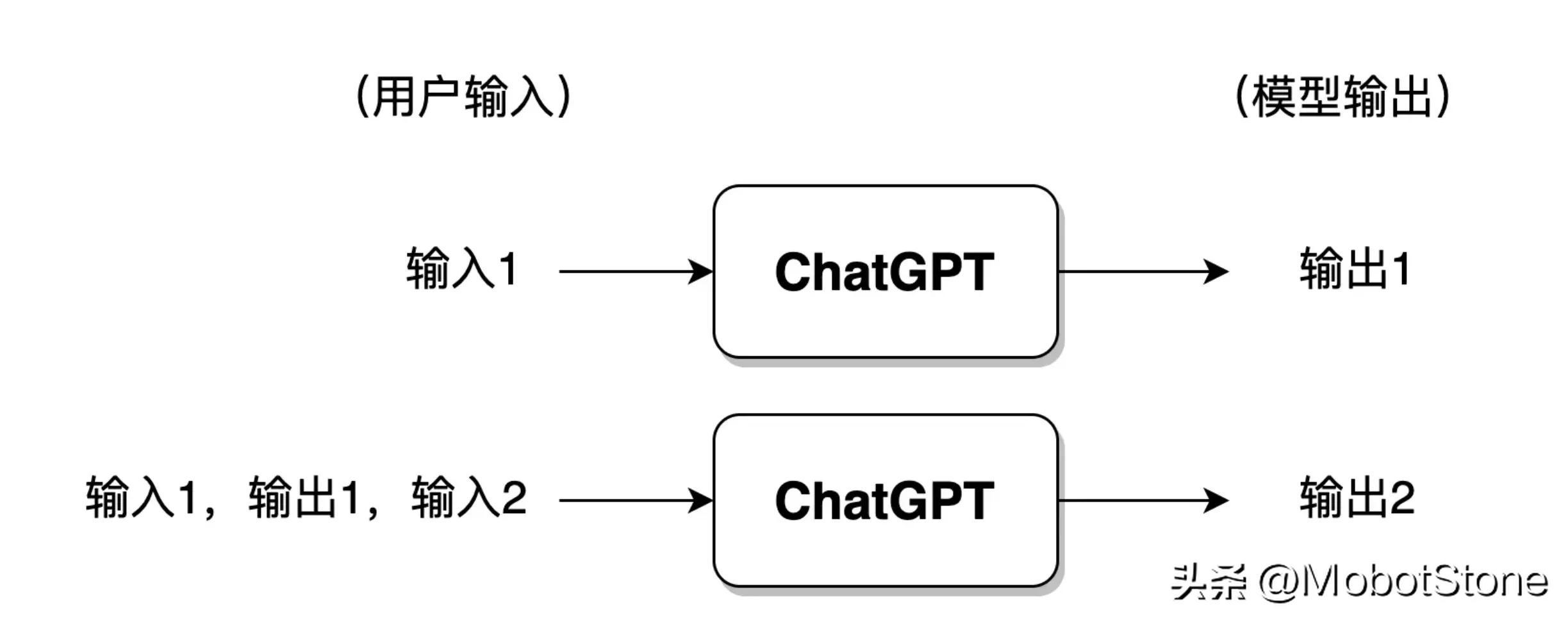
Jika pengguna telah melakukan terlalu banyak perbualan dengan ChatGPT, secara amnya, model hanya akan mengekalkan maklumat daripada pusingan perbualan terkini dan maklumat perbualan sebelumnya akan dilupakan .
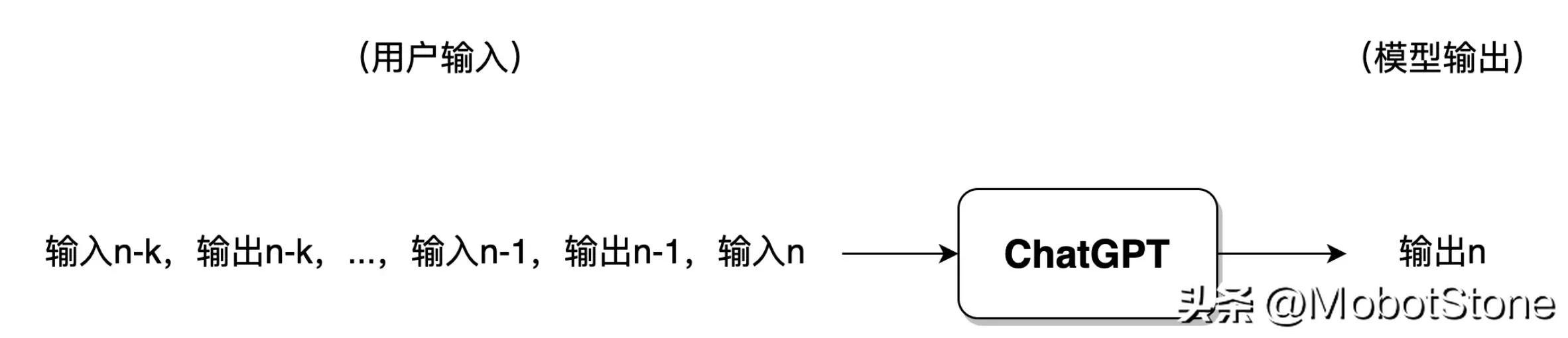
Selepas ChatGPT menerima input soalan pengguna, teks output tidak dijana secara langsung dalam satu nafas, tetapi dijana perkataan demi perkataan jenis ini, iaitu , Generatif . Seperti yang ditunjukkan di bawah.
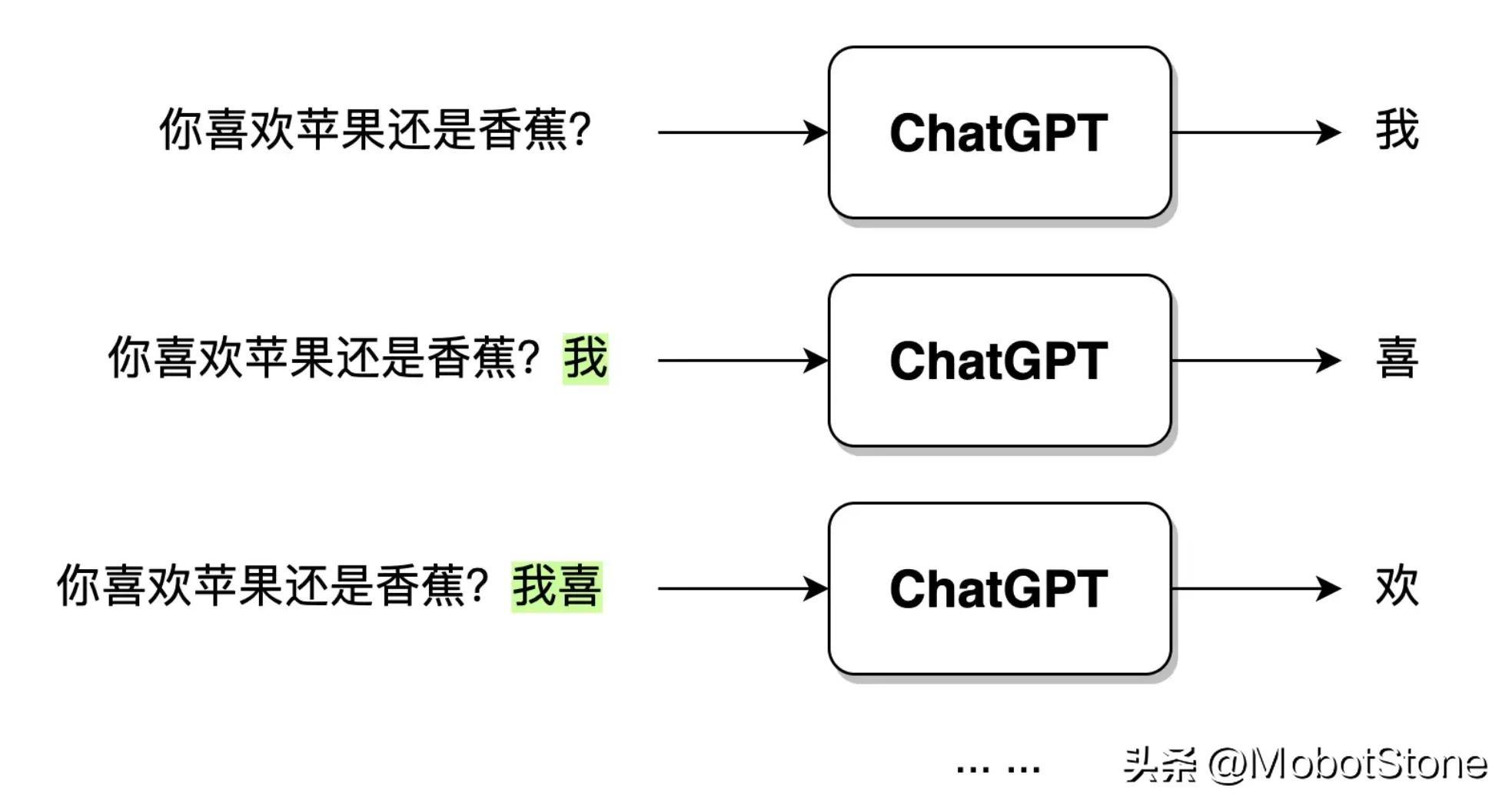
Apabila pengguna memasukkan soalan: "Adakah anda suka epal atau pisang?", selepas ChatGPT menerima data, ia mula-mula menjana perkataan "I", dan kemudian model akan mensintesis Soalan pengguna dan perkataan yang dihasilkan "I" terus menghasilkan perkataan "hi" seterusnya. Dan seterusnya sehingga ayat lengkap "Saya suka epal" dijana.
Sejarah pembangunan ChatGPT dan NLP
Bentuk pemodelan ChatGPT telah diperkenalkan lebih awal, bayangkan, jika anda diminta untuk melaksanakan model ChatGPT, apakah idea dan kaedah yang akan anda miliki? Sebenarnya, terdapat kira-kira dua strategi, NLP berdasarkan peraturan dan NLP berdasarkan statistik. Sejak bermulanya ChatGPT, bidang NLP telah memasuki era pembelajaran pengukuhan iaitu NLP berasaskan pembelajaran pengukuhan.
NLP berasaskan peraturan
NLP berasaskan peraturan merujuk kepada penggunaan peraturan bertulis secara manual untuk memproses bahasa semula jadi. Peraturan ini biasanya berdasarkan pengetahuan tatabahasa, semantik, dan pragmatik dan boleh digunakan untuk menghuraikan dan menjana bahasa semula jadi. Contohnya, kita boleh mereka bentuk sistem dialog berdasarkan peraturan berikut:
Peraturan 1: Apabila model menerima soalan pengguna, alih keluar perkataan " dalam soalan dan gantikannya dengan "? " "."
Peraturan 2: Gantikan "anda" dengan "Saya" dan "Saya" dengan "anda"
Daripada ini, kita boleh membuat mengikut peraturan ini Dialog model, mod dialog dihidupkan.
Pengguna: Hello. Model: Hello. Pengguna: Adakah anda ChatGPT? Model: Ya, saya ChatGPT. Pengguna: Adakah anda suka komuniti Nuggets? Model: Saya suka komuniti Nuggets. Pengguna: Adakah anda pernah menggunakan kit alat jionlp? Model: Saya telah menggunakan kit alat jionlp.
Di atas adalah contoh yang sangat kasar bagi sistem dialog berasaskan peraturan. Saya percaya pembaca mudah mengetahui masalah yang wujud. Bagaimana jika masalah pengguna terlalu kompleks? Bagaimana jika tiada tanda soal dalam soalan? Kita perlu sentiasa menulis pelbagai peraturan untuk merangkumi situasi istimewa di atas. Ini menunjukkan bahawa terdapat beberapa kelemahan yang jelas berdasarkan peraturan:
- Dalam bahasa semula jadi, tiada peraturan yang dapat menampung keperluan sepenuhnya, jadi ia tidak berkesan apabila menangani tugas bahasa semula jadi yang kompleks
- Terdapat peraturan yang tidak berkesudahan, dan ia akan menjadi sejumlah besar kerja untuk bergantung pada kuasa manusia
- Pada asasnya, tugas pemprosesan bahasa semula jadi tidak diserahkan kepada komputer, ia masih dikuasai oleh manusia.
Beginilah cara NLP dibangunkan pada peringkat awal: membina sistem model berdasarkan peraturan. Pada zaman awal, ia juga dipanggil simbolisme.
NLP berasaskan statistik
NLP berasaskan statistik menggunakan algoritma pembelajaran mesin untuk mempelajari ciri biasa bahasa semula jadi daripada sebilangan besar korpora Ia juga dipanggil connectionism pada zaman awal. Kaedah ini tidak memerlukan penulisan peraturan secara manual. Peraturan terutamanya tersirat dalam model dengan mempelajari ciri statistik bahasa. Dalam erti kata lain, dalam kaedah berasaskan peraturan, peraturan adalah eksplisit dan ditulis secara manual; dalam kaedah berasaskan statistik, peraturan tidak dapat dilihat, tersirat dalam parameter model, dan dilatih oleh model berdasarkan data.
Model ini telah berkembang pesat dalam beberapa tahun kebelakangan ini, dan ChatGPT adalah salah satu daripadanya. Di samping itu, terdapat pelbagai model dengan bentuk dan struktur yang berbeza, tetapi prinsip asasnya adalah sama. Kaedah pemprosesan mereka adalah seperti berikut:
Fokusnya adalah untuk mempelajari model bahasa berdasarkan korpus asal berskala besar, dan model ini tidak secara langsung mempelajari cara menyelesaikan tugasan tertentu, tetapi belajar daripada tatabahasa, morfologi, pragmatik, kepada akal, Pengetahuan dan maklumat lain disepadukan ke dalam model bahasa. Secara intuitif, ia lebih seperti ingatan pengetahuan daripada menggunakan pengetahuan untuk menyelesaikan masalah praktikal. Pra-latihan mempunyai banyak faedah, dan ia telah menjadi langkah yang perlu untuk hampir semua latihan model NLP. Kami akan mengembangkannya dalam bab-bab seterusnya. Kaedah berasaskan statistik jauh lebih popular daripada kaedah berasaskan peraturan Walau bagaimanapun, kelemahan terbesarnya ialah ketidakpastian kotak hitam, iaitu peraturan tidak dapat dilihat dan tersirat dalam parameter. Sebagai contoh, ChatGPT juga akan memberikan beberapa keputusan yang samar-samar dan tidak dapat difahami.Model latihan=> digunakan ) teknologi untuk melengkapkan pembelajaran model NLP berasaskan statistik. Pada awalnya, pra-latihan dalam bidang NLP mula diperkenalkan oleh model ELMO (Pembenaman daripada Model Bahasa), dan kaedah ini telah diterima pakai secara meluas oleh pelbagai model rangkaian neural dalam seperti ChatGPT.

NLP berdasarkan pembelajaran pengukuhan
Model ChatGPT adalah berdasarkan statistik, tetapi ia juga menggunakan kaedah baharu, Pembelajaran Pengukuhan dengan Maklum Balas Maklum Balas Manusia, RLHF), yang telah mencapai keputusan yang cemerlang dan membawa pembangunan NLP ke peringkat baharu.
Beberapa tahun lalu, Alpha GO mengalahkan Ke Jie. Ini hampir dapat membuktikan bahawa jika pembelajaran pengukuhan berada dalam keadaan yang sesuai, ia dapat mengalahkan manusia sepenuhnya dan menghampiri had kesempurnaan. Pada masa ini, kita masih dalam era kecerdasan buatan yang lemah, tetapi terhad kepada bidang Go Alpha GO ialah kecerdasan buatan yang kuat, dan terasnya terletak pada pembelajaran pengukuhan.
Apa yang dipanggil pembelajaran tetulang ialah kaedah pembelajaran mesin yang bertujuan untuk membenarkan ejen (ejen, dalam NLP terutamanya merujuk kepada model rangkaian neural dalam, iaitu model ChatGPT) belajar cara membuat keputusan melalui interaksi dengan persekitaran yang optimum.
Kaedah ini seperti melatih anjing (ejen) mendengar siulan (persekitaran) dan makan (matlamat pembelajaran).
Anak anjing akan diberi ganjaran makanan apabila mendengar pemiliknya meniup wisel; Dengan berulang kali makan dan kelaparan, anak anjing itu boleh mewujudkan refleks terkondisi yang sepadan, yang sebenarnya melengkapkan pembelajaran pengukuhan.
Dalam bidang NLP, persekitaran di sini jauh lebih kompleks. Persekitaran untuk model NLP bukanlah persekitaran bahasa manusia yang sebenar, tetapi model persekitaran bahasa yang dibina secara buatan. Oleh itu, penekanan di sini adalah kepada pembelajaran pengukuhan dengan maklum balas buatan.

Kaedah berasaskan statistik boleh membenarkan model untuk memuatkan set data latihan dengan tahap kebebasan yang paling besar, pembelajaran pengukuhan adalah untuk memberi model tahap kebebasan yang lebih besar, membenarkan model untuk belajar secara bebas, menerobos had set data yang ditetapkan. Model ChatGPT menyepadukan kaedah pembelajaran statistik dan kaedah pembelajaran pengukuhan Proses latihan modelnya ditunjukkan dalam rajah di bawah:
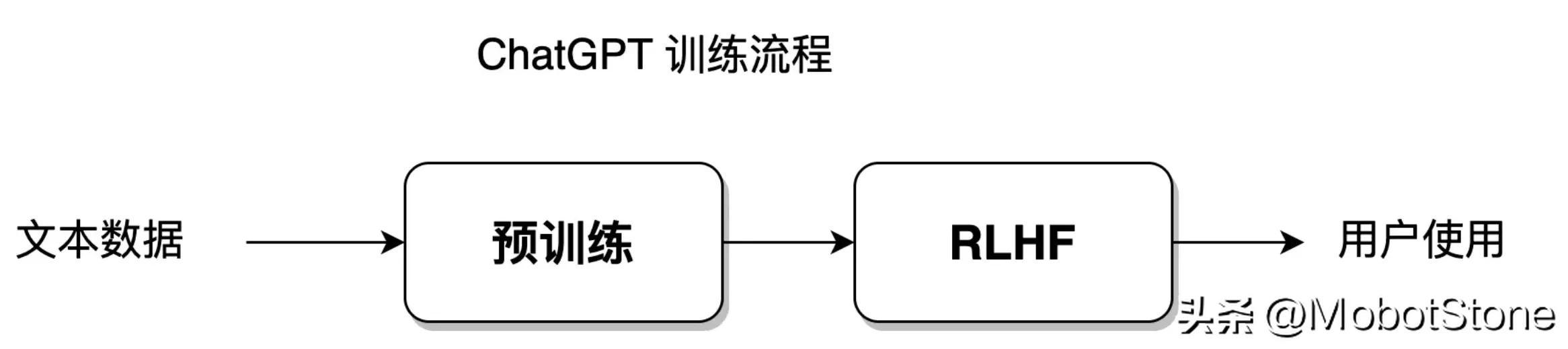
Bahagian proses latihan ini akan dilancarkan dalam Bahagian 8. -11 bercakap.
Trend pembangunan teknologi NLP
Sebenarnya, ketiga-tiga kaedah berdasarkan peraturan, berdasarkan statistik, dan berdasarkan pembelajaran pengukuhan bukan sekadar cara memproses bahasa semula jadi, tetapi cara memproses bahasa semula jadi. Model algoritma yang menyelesaikan masalah tertentu selalunya merupakan hasil gabungan ketiga-tiga penyelesaian ini.
Jika komputer dibandingkan dengan kanak-kanak, pemprosesan bahasa semula jadi adalah seperti manusia yang mendidik anak untuk membesar.
Pendekatan berasaskan peraturan adalah seperti ibu bapa mengawal anak 100%, memerlukan dia bertindak mengikut arahan dan peraturannya sendiri, seperti menetapkan beberapa jam belajar setiap hari dan mengajar anak itu. setiap soalan. Sepanjang proses, penekanan diberikan kepada arahan secara langsung, dengan inisiatif dan tumpuan diberikan kepada ibu bapa. Untuk NLP, inisiatif dan tumpuan keseluruhan proses terletak pada pengaturcara dan penyelidik yang menulis peraturan bahasa.
Pendekatan berasaskan statistik adalah seperti ibu bapa hanya memberitahu anak-anak mereka cara belajar, dan bukannya mengajar setiap soalan khusus. Untuk NLP, tumpuan pembelajaran adalah pada model rangkaian saraf, tetapi inisiatif masih dikawal oleh jurutera algoritma.
Berdasarkan kaedah pembelajaran pengukuhan, seperti ibu bapa hanya menetapkan matlamat pendidikan untuk anak-anak mereka contohnya, mereka memerlukan anak mereka mencapai 90 mata dalam peperiksaan, tetapi mereka tidak mengambil berat tentang cara anak-anak belajar dan bergantung sepenuhnya pada pembelajaran sendiri Kanak-kanak mempunyai tahap kebebasan dan inisiatif yang sangat tinggi. Ibu bapa hanya memberi ganjaran atau menghukum keputusan akhir dan tidak mengambil bahagian dalam keseluruhan proses pendidikan. Untuk NLP, tumpuan dan inisiatif keseluruhan proses terletak pada model itu sendiri.
Pembangunan NLP telah beransur-ansur menghampiri kaedah berdasarkan statistik, dan akhirnya kaedah berdasarkan pembelajaran pengukuhan dicapai kemenangan lengkap, dan tanda kemenangan ialah ChatGPT Kemunculan ; dan kaedah berasaskan peraturan secara beransur-ansur menurun dan menjadi kaedah pemprosesan tambahan. Sejak awal, pembangunan model ChatGPT telah berkembang dengan tidak berbelah bahagi ke arah membiarkan model belajar dengan sendirinya.
Pengubah struktur rangkaian saraf ChatGPT
Dalam pengenalan sebelumnya, untuk memudahkan pemahaman pembaca, struktur dalaman khusus model ChatGPT tidak disebutkan.
ChatGPT ialah rangkaian neural yang besar. Struktur dalamannya terdiri daripada beberapa lapisan Transformer ialah struktur rangkaian saraf. Sejak 2018, ia telah menjadi struktur model standard biasa dalam bidang NLP, dan Transformer boleh didapati dalam hampir semua model NLP.
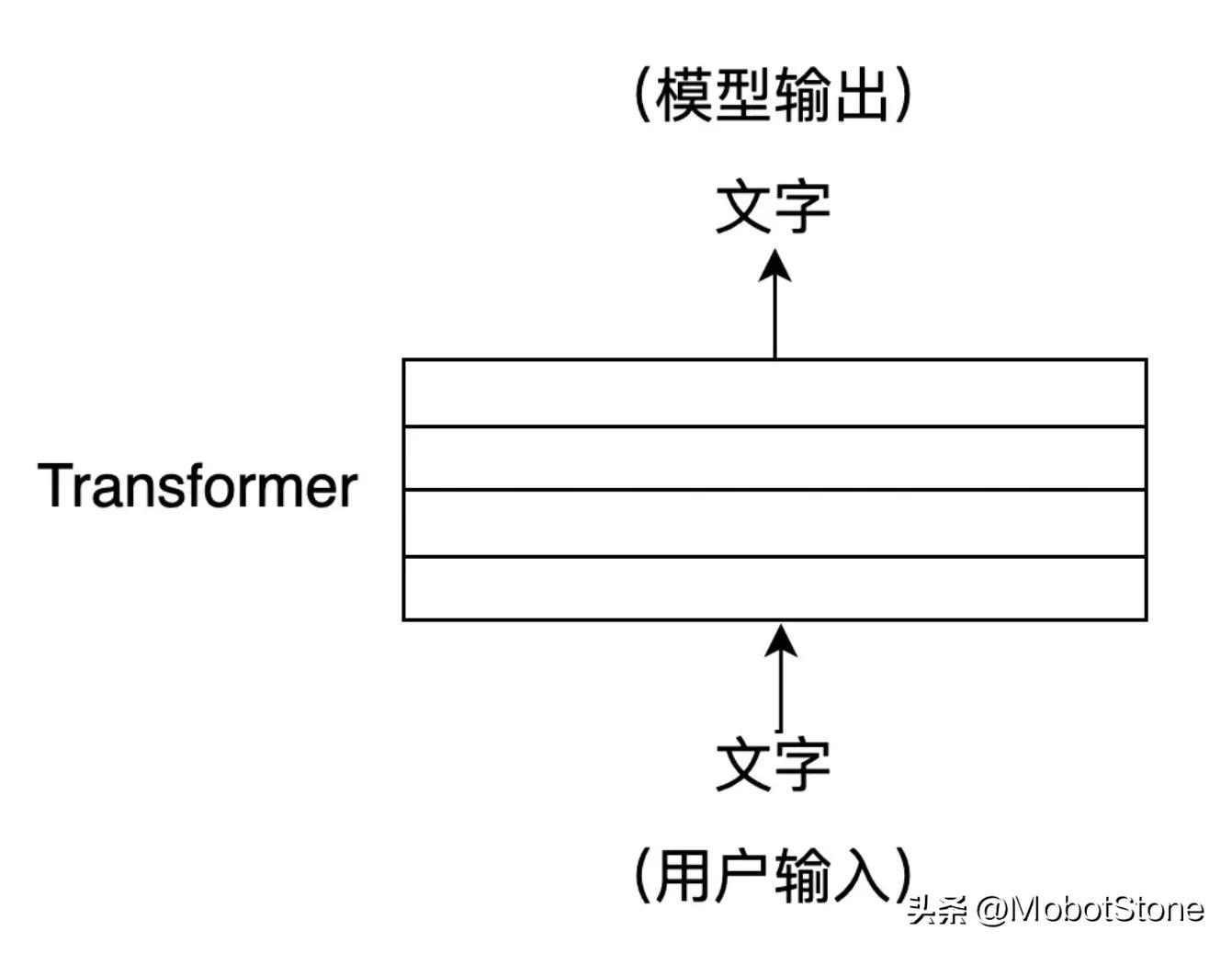
Jika ChatGPT adalah sebuah rumah, maka Transformer ialah batu bata yang membina ChatGPT.
Inti Transformer ialah mekanisme perhatian kendiri (Self-Attention), yang boleh membantu model secara automatik memberi perhatian kepada aksara kedudukan lain yang berkaitan dengan watak kedudukan semasa semasa memproses urutan teks input. Mekanisme perhatian kendiri boleh mewakili setiap kedudukan dalam urutan input sebagai vektor, dan vektor ini boleh mengambil bahagian dalam pengiraan pada masa yang sama, dengan itu mencapai pengkomputeran selari yang cekap. Berikan contoh:
Dalam terjemahan mesin, apabila menterjemah ayat Inggeris "Saya seorang pelajar yang baik" ke dalam bahasa Cina, model terjemahan mesin tradisional mungkin menterjemahkannya kepada pelajar "Saya seorang pelajar yang baik"" , tetapi terjemahan ini mungkin tidak cukup tepat. Artikel "a" dalam bahasa Inggeris perlu ditentukan berdasarkan konteks apabila diterjemahkan ke dalam bahasa Cina.
Apabila menggunakan model Transformer untuk terjemahan, anda boleh mendapatkan hasil terjemahan yang lebih tepat, seperti "Saya seorang pelajar yang baik".
Ini kerana Transformer boleh menangkap perhubungan antara perkataan merentasi jarak jauh dalam ayat bahasa Inggeris dengan lebih baik dan menyelesaikan kebergantungan panjang dalam konteks teks. Mekanisme perhatian kendiri akan diperkenalkan dalam Bahagian 5-6, dan struktur terperinci Transformer akan diperkenalkan dalam Bahagian 6-7.
Ringkasan
- Pembangunan medan NLP telah beralih secara beransur-ansur daripada menulis peraturan secara manual dan mengawal atur cara komputer secara logik kepada menyerahkan sepenuhnya kepada model rangkaian untuk menyesuaikan diri dengan persekitaran bahasa.
- ChatGPT pada masa ini ialah model NLP yang paling hampir untuk lulus ujian Turing, dan GPT4 dan GPT5 akan menjadi lebih dekat pada masa hadapan.
- Aliran kerja ChatGPT ialah sistem dialog generatif.
- Proses latihan ChatGPT termasuk pra-latihan model bahasa dan pembelajaran pengukuhan RLHF dengan maklum balas manual.
- Struktur model ChatGPT menggunakan Transformer dengan mekanisme perhatian kendiri sebagai teras.
Atas ialah kandungan terperinci Semua orang memahami ChatGPT Bab 1: ChatGPT dan pemprosesan bahasa semula jadi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI