
Rumah >pangkalan data >tutorial mysql >Apakah peranan indeks MySQL
Apakah peranan indeks MySQL

- 王林ke hadapan
- 2023-05-27 23:52:391904semak imbas
Mula-mula buat jadual pangkalan data:
create table single_table(
id int not auto_increment,
key1 varchar(100),
key2 int,
key3 varchar(100),
key_part1 varchar(100),
key_part2 varchar(100),
key_part3 varchar(100),
common_field varchar(100),
primary key(id), # 聚簇索引
key idx_key1(key1), # 二级索引
unique key uk_key2(key2), # 二级索引,而且该索引是唯一二级索引
key idx_key3(key3), # 二级索引
key idx_key_part(key_part1,key_part2,key_part3) # 二级索引,也是联合索引
)Engine=InnoDB CHARSET=utf8;1
Pelan pelaksanaan pertanyaan yang paling asas ialah mengimbas semua rekod dalam jadual dan menyemak sama ada setiap rekod carian memenuhi syarat carian. Jika ia sepadan, hantarkannya kepada pelanggan, jika tidak langkau rekod. Skim pelaksanaan ini dipanggil imbasan jadual penuh.
Untuk enjin storan InnoDB, imbasan jadual penuh bermakna bermula daripada rekod pertama nod daun pertama indeks berkelompok dan mengimbas ke belakang di sepanjang senarai terpaut sehala di mana rekod terletak sehingga tamat Untuk rekod terakhir nod daun, jika anda boleh menggunakan pepohon B+ untuk mencari rekod yang nilai lajur indeksnya bersamaan dengan nilai tertentu, anda boleh mengurangkan bilangan rekod yang perlu diimbas.
Memandangkan rekod dalam nod daun pokok B+ diisih dari kecil ke besar mengikut nilai lajur indeks, hanya mengimbas rekod dalam selang waktu tertentu atau selang tertentu boleh mengurangkan dengan ketara bilangan rekod yang perlu diimbas.
Untuk pernyataan pertanyaan:
select * from single_table where id>=2 and id<=100;
Pernyataan ini sebenarnya ingin mencari semua rekod indeks berkelompok yang nilai idnya berada dalam julat [2,100] pengelompokan Pokok B+ yang sepadan dengan indeks gugusan dengan cepat mencari rekod indeks berkelompok id=2, dan kemudian mengimbas ke belakang di sepanjang senarai terpaut sehala di mana rekod itu terletak sehingga nilai id rekod indeks berkelompok tidak berada dalam julat [2,100] Setakat ini, berbanding dengan mengimbas semua rekod indeks berkelompok, kaedah ini sangat mengurangkan bilangan rekod yang perlu diimbas, jadi ia meningkatkan kecekapan pertanyaan.
Malah, untuk pepohon B+, selagi lajur indeks dan pemalar disambungkan menggunakan operator =、、in、not in、is null、is not null、>、=、, selang imbasan boleh dijana, dengan itu meningkatkan kecekapan pertanyaan.
2. Indeks digunakan untuk mengisih
Apabila kita menulis pernyataan pertanyaan, kita selalunya perlu menggunakan klausa order by untuk mengisih rekod yang ditanya mengikut peraturan tertentu. Dalam keadaan biasa, kami hanya boleh memuatkan rekod ke dalam ingatan, dan kemudian menggunakan beberapa algoritma pengisihan untuk mengisih rekod ini dalam ingatan. Kadangkala set hasil pertanyaan mungkin terlalu besar untuk diisih dalam ingatan Dalam kes ini, perlu menggunakan ruang cakera buat sementara waktu untuk menyimpan hasil perantaraan, dan kemudian mengembalikan hasil yang diisih kepada klien selepas operasi pengisihan selesai.
Dalam MySQL, kaedah pengisihan dalam memori atau cakera ini dipanggil pengisihan fail Walau bagaimanapun, jika lajur indeks digunakan dalam klausa order by, adalah mungkin untuk meninggalkan keperluan untuk mengisih dalam memori atau cakera. .
1. Analisis pernyataan pertanyaan berikut:
select * form single_table order by key_part1,key_part2,key_part3 limit 10;
Set hasil pernyataan pertanyaan ini perlu diisih mengikut nilai key_part1 terlebih dahulu jika nilai key_part1 direkodkan yang sama, kemudian susun mengikut key_part2 Isih nilai, jika nilai key_part1 dan nilai key_part2 adalah sama, kemudian isi mengikut key_part3. Indeks bersama idx_key_part yang kami tentukan diisih mengikut peraturan di atas Berikut ialah gambar rajah ringkas indeks idx_key_part:
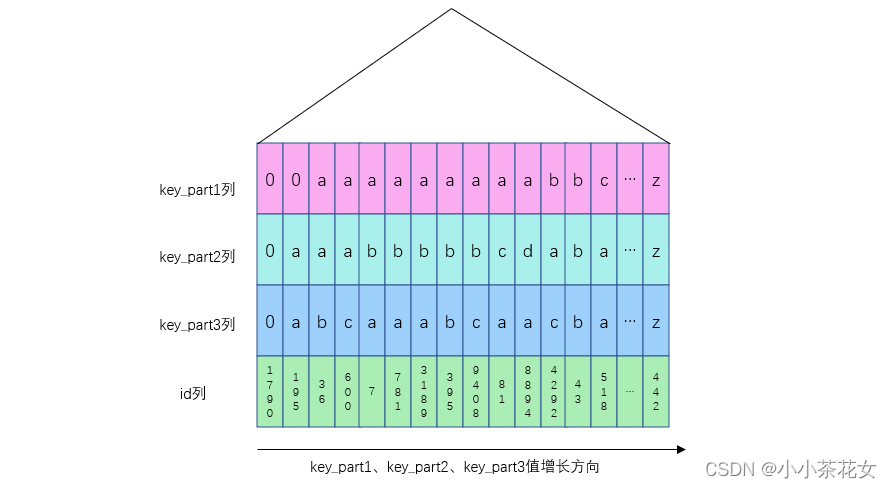
Jadi kita boleh mulakan daripada. pertama idx_key_part 🎜>Mulakan daripada rekod indeks sekunder, imbas ke belakang di sepanjang senarai terpaut sehala di mana rekod itu terletak dan dapatkan 10 rekod indeks sekunder. Oleh kerana senarai pertanyaan kami ialah *, iaitu, kami perlu membaca rekod pengguna yang lengkap, jadi kami melakukan operasi pemulangan jadual untuk setiap rekod indeks sekunder yang diperoleh dan menghantar rekod pengguna lengkap kepada klien. Ini menjimatkan masa mengisih 10,000 rekod.
Di sini kami menambah penyataan had semasa melaksanakan pernyataan pertanyaan Jika bilangan rekod yang akan diperolehi tidak terhad, ia akan menghasilkan operasi pemulangan jadual untuk sejumlah besar rekod indeks sekunder, yang akan menjejaskan. prestasi keseluruhan.
2. Perkara yang perlu diberi perhatian apabila menggunakan indeks bersama untuk mengisih
Apabila menggunakan indeks bersama, anda perlu memberi perhatian: Susunan lajur selepas klausa order by juga mesti diberikan dalam susunan lajur indeks keluar; jika tertib order by key_part3,key_part2,key_part1 diberikan, indeks pokok B+ tidak boleh digunakan.
Sebab anda tidak boleh menggunakan indeks jika anda membalikkan susunan lajur pengisihan ialah peraturan pengisihan untuk halaman dan rekod dalam indeks bersama ditetapkan, iaitu, isih mengikut nilai key_part1 dahulu. Jika nilai key_part1 rekod adalah sama, Kemudian susun mengikut nilai key_part2 Jika nilai key_part1 dan nilai key_part2 yang direkodkan adalah sama, kemudian susun mengikut nilai key_part3. Jika kandungan klausa order by ialah order by key_part3,key_part2,key_part1, ia dikehendaki mengisih mengikut nilai key_part3 terlebih dahulu Jika nilai key_part3 yang direkodkan adalah sama, kemudian mengisih mengikut nilai key_part2. . Jika nilai key_part3 yang direkodkan adalah sama dengan nilai key_part2 semuanya sama, dan kemudiannya diisih mengikut nilai key_part1 Ini jelas merupakan konflik.
3、不可以使用索引进行排序的情况:
(1) ASC、DESC混用;
对于使用联合索引进行排序的场景,我们要求各个排序列的排序规则是一致的,也就是要么各个列都是按照升序规则排序,要么都是按照降序规则排序。
(2) 排序列包含非一个索引的列;
有时用来排序的多个列不是同一个索引中的,这种情况也不能使用索引进行排序,比如下面的查询语句:
select * from single_table order by key1,,key2 limit 10;
对于idx_key1的二级索引记录来说,只按照key1列的值进行排序,而且在key1列相同的情况下是不按照
key2列的值进行排序的,所以不能使用idx_key1索引执行上述查询。
(3) 排序列是某个联合索引的索引列,但是这些排序列在联合索引中并不连续;
(4) 排序列不是以单独列名的形式出现在order by子句中;
3、索引用于分组
有时为了方便统计表中的一些信息,会把表中的记录按照某些列进行分组。比如下面的分组查询语句:
select key_part1,key_part2,key_part3,count(*) fron single_table group by key_part1,key_part2,key_part3;
这个查询语句相当于执行了3次分组操作:
先按照
key_part1值把记录进行分组,key_part1值相同的所有记录划分为一组;将
key_part1值相同的每个分组中的记录再按照key_part2的值进行分组,将key_part2值相同的记录放到一个小分组中,看起来像是在一个大分组中又细分了好多小分组。再将上一步中产生的小分组按照
key_part3的值分成更小的分组。所以整体上看起来就像是先把记录分成一个大分组,然后再把大分组分成若干个小分组,最后把若干个小分组再细分为更多的小分组。
上面这个查询语句就是统计每个小小分组包含的记录条数。
如果没有idx_key_part索引,就得建立一个用于统计的临时表,在扫描聚簇索引的记录时将统计的中间结果填入这个临时表。当扫描完记录后,再把临时表中的结果作为结果集发送给客户端。
如果有了idx_key_part索引,恰巧这个分组顺序又与idx_key_part的索引列的顺序一致,因此可以直接使用idx_key_part的二级索引进行分组,而不用建立临时表了。
与使用B+树索引进行排序差不多,分组列的顺序页需要与索引列的顺序一致,也可以值使用索引列中左边连续的列进行分组。
Atas ialah kandungan terperinci Apakah peranan indeks MySQL. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!