
Rumah >Peranti teknologi >AI >Amalan pengoptimuman cache untuk latihan pembelajaran mendalam berskala besar
Amalan pengoptimuman cache untuk latihan pembelajaran mendalam berskala besar

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-27 20:49:041309semak imbas

1 Latar belakang projek dan strategi caching
Pertama, mari kongsi latar belakang yang berkaitan.
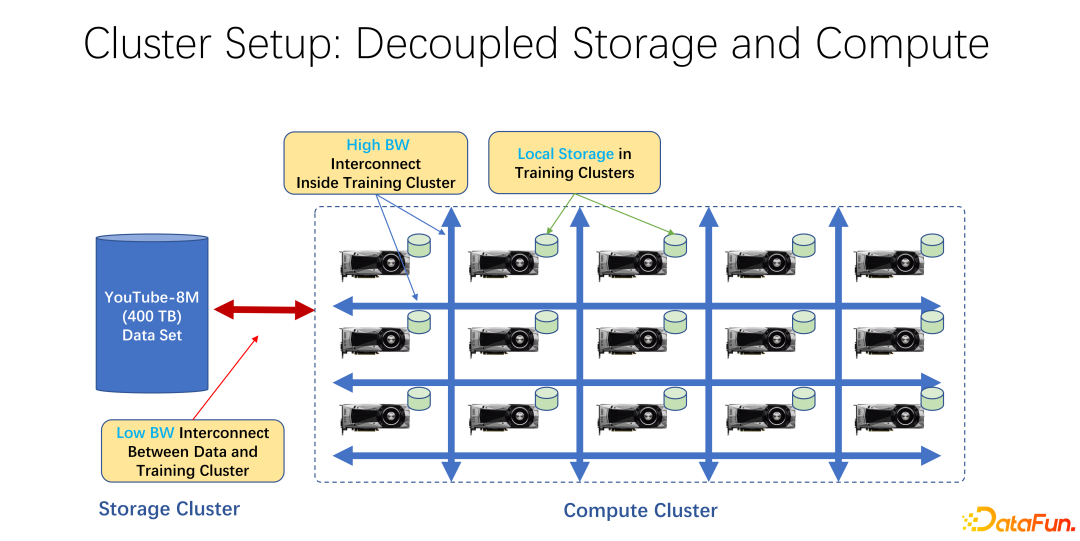
Dalam beberapa tahun kebelakangan ini, latihan AI telah digunakan secara meluas. Dari perspektif infrastruktur, sama ada data besar atau kluster latihan AI, kebanyakannya menggunakan seni bina yang memisahkan storan dan pengkomputeran. Sebagai contoh, banyak tatasusunan GPU diletakkan dalam kelompok pengkomputeran yang besar, dan kelompok lain adalah storan. Ia juga mungkin menggunakan beberapa storan awan, seperti Microsoft Azure atau Amazon S3.
Ciri-ciri infrastruktur sedemikian ialah, pertama sekali, terdapat banyak GPU yang sangat mahal dalam kelompok pengkomputeran, dan setiap GPU selalunya mempunyai jumlah tertentu storan tempatan, seperti SSD Berpuluh-puluh terabait storan sedemikian. Dalam susunan mesin sedemikian, rangkaian berkelajuan tinggi sering digunakan untuk menyambung ke hujung jauh Contohnya, data latihan berskala sangat besar seperti Coco, jaring imej dan YouTube 8M disambungkan melalui rangkaian.
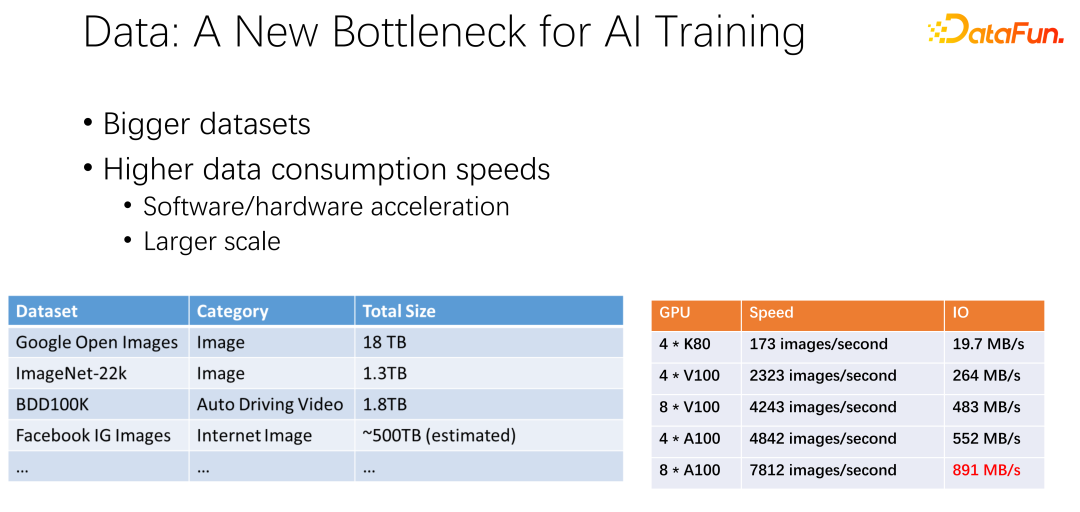
Seperti yang ditunjukkan dalam rajah di atas, data mungkin menjadi hambatan kepada latihan AI seterusnya. Kami telah melihat bahawa set data semakin besar dan lebih besar, dan apabila AI semakin digunakan secara meluas, lebih banyak data latihan terkumpul. Pada masa yang sama trek GPU sangat volumetrik. Sebagai contoh, pengeluar seperti AMD dan TPU telah menghabiskan banyak tenaga untuk mengoptimumkan perkakasan dan perisian untuk menjadikan pemecut, seperti GPU dan TPU, lebih pantas dan pantas. Memandangkan pemecut digunakan secara meluas dalam syarikat, penggunaan kelompok menjadi lebih besar dan lebih besar. Kedua-dua jadual di sini menunjukkan beberapa variasi merentas set data dan kelajuan GPU. Daripada K80 sebelumnya hingga V100, P100 dan A100, kelajuannya sangat pantas. Walau bagaimanapun, apabila ia menjadi lebih pantas, GPU menjadi lebih dan lebih mahal. Sama ada data kami, seperti kelajuan IO, boleh bersaing dengan kelajuan GPU adalah satu cabaran besar.

Seperti yang ditunjukkan dalam rajah di atas, dalam aplikasi banyak syarikat besar, kami telah melihat fenomena sedemikian: apabila membaca Apabila mengakses data jauh, GPU melahu. Oleh kerana GPU sedang menunggu data jauh dibaca, ini bermakna IO menjadi hambatan, menyebabkan GPU yang mahal dibazirkan. Terdapat banyak kerja pengoptimuman sedang dilakukan untuk mengurangkan kesesakan ini, dan caching ialah salah satu arah pengoptimuman yang paling penting. Berikut adalah dua cara.

Jenis pertama ialah dalam banyak senario aplikasi, terutamanya dalam seni bina latihan AI asas seperti K8s plus Docker, banyak cakera tempatan digunakan . Seperti yang dinyatakan sebelum ini, mesin GPU mempunyai storan tempatan tertentu Anda boleh menggunakan cakera setempat untuk melakukan beberapa caching dan cache data terlebih dahulu.
Selepas memulakan GPU Docker, bukannya memulakan latihan GPU AI dengan segera, muat turun data dahulu, muat turun data dari hujung jauh ke Docker, atau pasangkannya dsb. Mulakan latihan selepas memuat turunnya ke Docker. Dengan cara ini, bacaan data latihan seterusnya boleh ditukar kepada bacaan data tempatan sebanyak mungkin. Prestasi IO tempatan pada masa ini mencukupi untuk menyokong latihan GPU. Pada VLDB 2020, terdapat kertas kerja, CoorDL, yang berdasarkan DALI untuk caching data.
Kaedah ini juga membawa banyak masalah. Pertama sekali, ruang tempatan adalah terhad, yang bermaksud bahawa data cache juga terhad Apabila set data menjadi lebih besar dan lebih besar, sukar untuk menyimpan semua data. Selain itu, perbezaan besar antara senario AI dan senario data besar ialah set data dalam senario AI agak terhad. Tidak seperti senario data besar di mana terdapat banyak jadual dan pelbagai perniagaan, jurang kandungan antara jadual data setiap perniagaan adalah sangat besar. Dalam senario AI, saiz dan bilangan set data adalah jauh lebih kecil daripada dalam senario data besar. Oleh itu, sering didapati bahawa banyak tugasan yang dikemukakan dalam syarikat membaca data yang sama. Jika semua orang memuat turun data ke mesin tempatan mereka sendiri, ia tidak boleh dikongsi dan banyak salinan data akan disimpan berulang kali pada mesin tempatan. Pendekatan ini jelas mempunyai banyak masalah dan tidak cukup cekap.
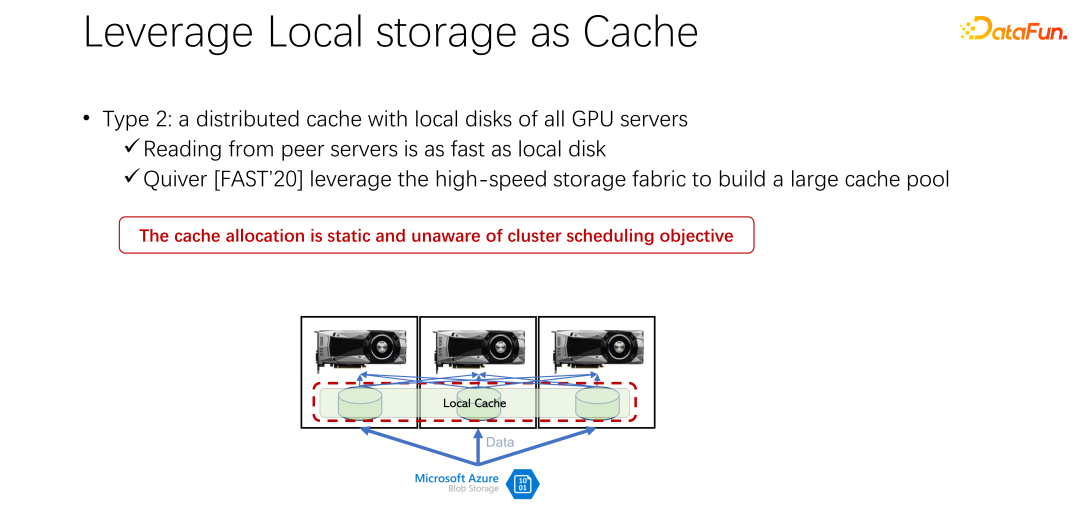
Kaedah kedua diperkenalkan di bawah. Memandangkan storan tempatan tidak begitu baik, bolehkah kita menggunakan cache yang diedarkan seperti Alluxio untuk mengurangkan masalah tadi. Cache yang diedarkan mempunyai kapasiti yang sangat besar untuk memuatkan data. Di samping itu, Alluxio, sebagai cache yang diedarkan, mudah dikongsi. Data dimuat turun ke Alluxio, dan pelanggan lain juga boleh membaca data ini daripada cache. Nampaknya menggunakan Alluxio boleh menyelesaikan masalah yang disebutkan di atas dengan mudah dan meningkatkan prestasi latihan AI dengan banyak. Kertas kerja bertajuk Quiver yang diterbitkan oleh Microsoft India Research di FAST2020 menyebut penyelesaian ini. Walau bagaimanapun, analisis kami mendapati bahawa pelan peruntukan yang kelihatan sempurna itu masih agak statik dan tidak cekap. Pada masa yang sama, jenis algoritma penghapusan cache yang harus digunakan juga merupakan persoalan yang patut dibincangkan.
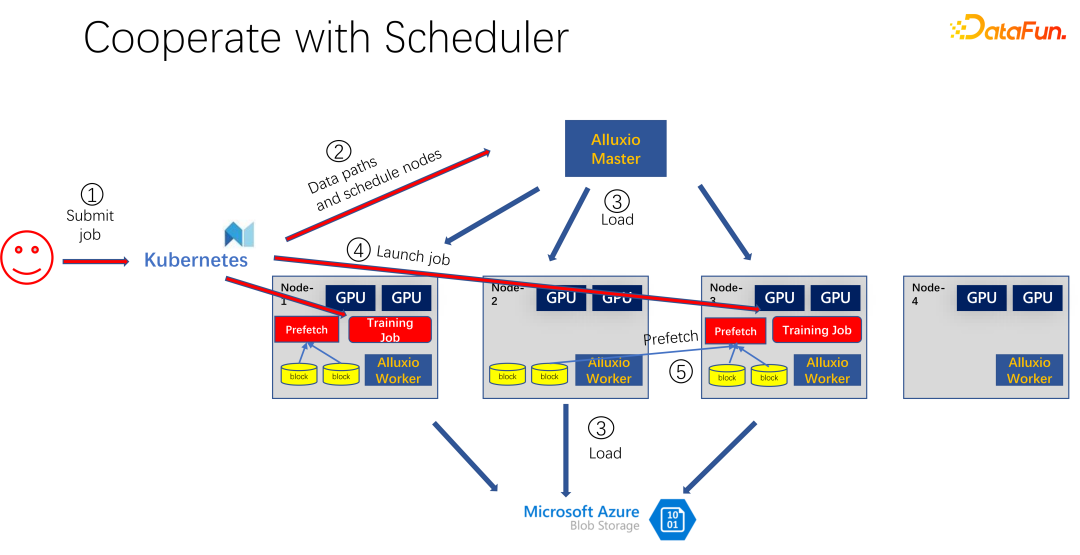
Seperti yang ditunjukkan dalam gambar di atas, ia adalah aplikasi yang menggunakan Alluxio sebagai cache untuk latihan AI. Gunakan K8 untuk menjadualkan keseluruhan tugas kelompok dan mengurus sumber seperti GPU, CPU dan memori. Apabila pengguna menyerahkan tugas kepada K8s, K8s akan membuat pemalam terlebih dahulu dan memberitahu induk Alluxio untuk memuat turun bahagian data ini. Maksudnya, lakukan pemanasan badan terlebih dahulu dan cuba cache beberapa tugasan yang mungkin diperlukan untuk kerja itu. Sudah tentu, ia tidak perlu dicache sepenuhnya, kerana Alluxio menggunakan seberapa banyak data yang ada. Selebihnya, jika ia belum dicache, dibaca dari hujung terpencil. Di samping itu, selepas tuan Alluxio mendapat arahan sedemikian, ia boleh meminta pekerjanya pergi ke hujung terpencil. Ia mungkin storan awan, atau mungkin kluster Hadoop yang memuat turun data. Pada masa ini, K8s juga akan menjadualkan kerja kepada kluster GPU. Sebagai contoh, dalam rajah di atas, dalam kelompok sedemikian, ia memilih nod pertama dan nod ketiga untuk memulakan tugas latihan. Selepas memulakan tugas latihan, data perlu dibaca. Dalam rangka kerja arus perdana semasa seperti PyTorch dan Tensorflow, Prefetch juga terbina dalam, yang bermaksud pra-bacaan data. Ia membaca data cache dalam Alluxio yang telah dicache terlebih dahulu untuk menyediakan sokongan untuk data latihan IO. Sudah tentu, jika didapati bahawa beberapa data belum dibaca, Alluxio juga boleh membacanya dari jauh. Alluxio hebat sebagai antara muka bersatu. Pada masa yang sama, ia juga boleh berkongsi data merentas kerja.
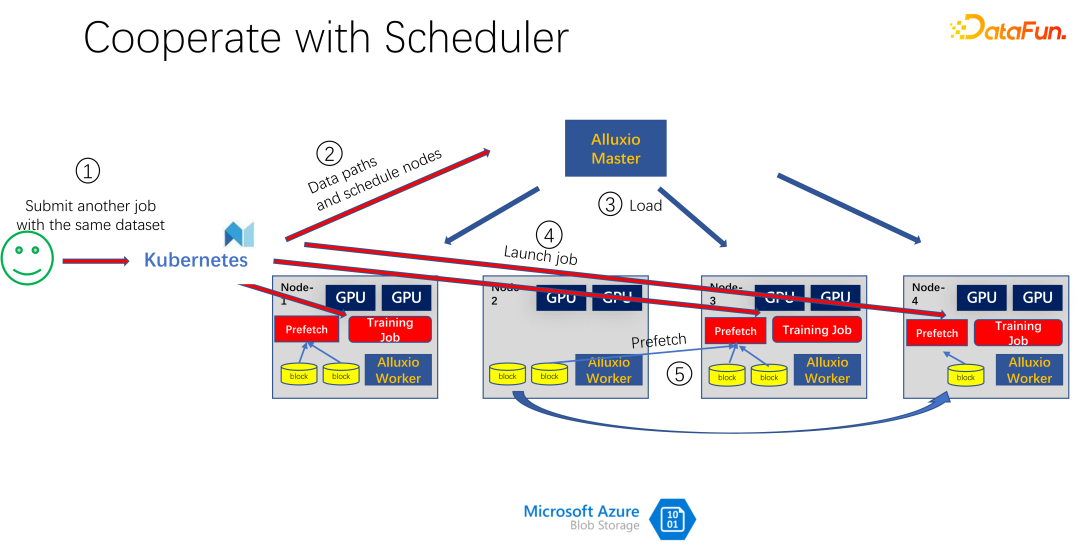
Seperti yang ditunjukkan dalam gambar di atas, sebagai contoh, orang lain menghantar kerja lain dengan data yang sama, menggunakan yang sama Set data, pada masa ini, apabila menyerahkan tugas kepada K8s, Alluxio tahu bahawa bahagian data ini sudah wujud. Jika Alluxio mahu melakukan yang lebih baik, ia juga boleh mengetahui mesin mana data akan dijadualkan. Sebagai contoh, ia dijadualkan ke nod 1, nod 3 dan nod 4 pada masa ini. Anda juga boleh membuat beberapa salinan data nod 4. Dengan cara ini, semua data, walaupun dalam Alluxio, tidak perlu dibaca merentas mesin, tetapi dibaca secara setempat. Jadi nampaknya Alluxio telah banyak mengurangkan dan mengoptimumkan masalah IO dalam latihan AI. Tetapi jika anda melihat dengan teliti, anda akan mendapati dua masalah.

Masalah pertama ialah algoritma penyingkiran cache sangat tidak cekap, kerana dalam senario AI, mod mengakses data sangat berbeza daripada masa lalu. Masalah kedua ialah cache, sebagai sumber, mempunyai hubungan antagonis dengan lebar jalur (iaitu, kelajuan baca storan jauh). Jika cache besar, maka peluang untuk membaca data dari hujung jauh akan berkurangan. Jika cache kecil, banyak data perlu dibaca dari hujung jauh. Cara menjadualkan dan memperuntukkan sumber ini dengan baik juga merupakan isu yang perlu dipertimbangkan.
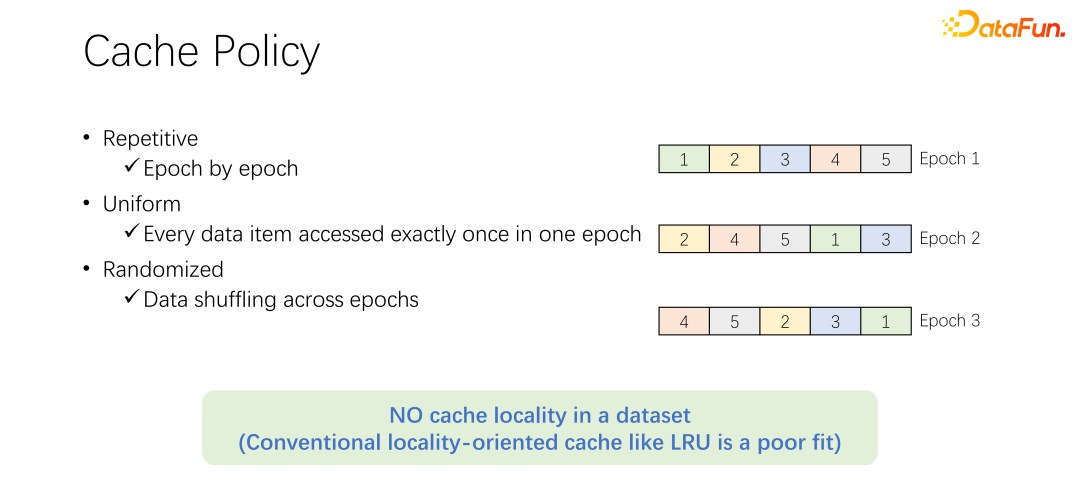 Sebelum membincangkan algoritma penghapusan cache, mari kita lihat dahulu proses akses data dalam latihan AI. Dalam latihan AI, ia akan dibahagikan kepada banyak zaman dan dilatih secara berulang. Dalam setiap zaman latihan, setiap data akan dibaca dan hanya dibaca sekali. Untuk mengelakkan latihan yang terlalu sesuai, selepas setiap zaman tamat, pada zaman seterusnya, susunan bacaan akan berubah dan shuffle akan dilakukan. Maksudnya, semua data akan dibaca sekali setiap zaman, tetapi susunannya berbeza.
Sebelum membincangkan algoritma penghapusan cache, mari kita lihat dahulu proses akses data dalam latihan AI. Dalam latihan AI, ia akan dibahagikan kepada banyak zaman dan dilatih secara berulang. Dalam setiap zaman latihan, setiap data akan dibaca dan hanya dibaca sekali. Untuk mengelakkan latihan yang terlalu sesuai, selepas setiap zaman tamat, pada zaman seterusnya, susunan bacaan akan berubah dan shuffle akan dilakukan. Maksudnya, semua data akan dibaca sekali setiap zaman, tetapi susunannya berbeza.
Algoritma penyingkiran LRU lalai dalam Alluxio jelas tidak boleh digunakan dengan baik pada senario latihan AI. Kerana LRU memanfaatkan lokaliti cache. Lokaliti terbahagi kepada dua aspek Pertama ialah lokaliti masa, iaitu data yang diakses sekarang boleh diakses tidak lama lagi. Ini tidak wujud dalam latihan AI. Kerana data yang diakses sekarang hanya akan diakses pada pusingan seterusnya, dan akan diakses pada pusingan seterusnya. Tiada kebarangkalian tertentu bahawa data lebih mudah diakses daripada data lain. Di sisi lain ialah lokaliti data, dan juga lokaliti spatial. Dalam erti kata lain, sebab Alluxio menggunakan blok yang agak besar untuk cache data adalah kerana apabila sekeping data tertentu dibaca, data sekeliling juga boleh dibaca. Contohnya, dalam senario data besar, aplikasi OLA
P sering mengimbas jadual, yang bermaksud bahawa data di sekeliling akan diakses serta-merta. Tetapi ia tidak boleh digunakan dalam senario latihan AI. Kerana ia dikocok setiap kali, susunan bacaan berbeza setiap masa. Oleh itu, algoritma penyingkiran LRU tidak sesuai untuk senario latihan AI.

Bukan sahaja LRU, malah algoritma penghapusan arus perdana seperti LFU mempunyai masalah sedemikian . Kerana keseluruhan latihan AI mempunyai akses yang sangat sama kepada data. Oleh itu, anda boleh menggunakan algoritma caching paling mudah, yang hanya perlu cache sebahagian daripada data dan tidak perlu menyentuhnya. Selepas kerja datang, hanya sebahagian daripada data sentiasa dicache. Jangan sekali-kali menghapuskannya. Tiada algoritma penyingkiran diperlukan. Ini mungkin mekanisme penghapusan terbaik di luar sana.
Seperti yang ditunjukkan dalam contoh di atas. Di atas ialah algoritma LRU dan di bawah ialah kaedah penyamaan. Hanya dua keping data boleh dicache pada mulanya. Mari kita permudahkan masalah Ia hanya mempunyai dua keping kapasiti, cache D dan B, dan bahagian tengah adalah urutan akses. Sebagai contoh, yang pertama diakses ialah B. Jika ia LRU, B terkena dalam cache. Akses seterusnya ialah C. C tiada dalam cache D dan B. Oleh itu, berdasarkan dasar LRU, D akan diganti dan C akan dikekalkan. Iaitu, cache ialah C dan B pada masa ini. Yang dilawati seterusnya ialah A, yang juga tiada di C dan B. Jadi B akan dihapuskan dan digantikan dengan C dan A. Yang seterusnya ialah D, dan D tiada dalam cache, jadi ia digantikan dengan D dan A. Dengan analogi, anda akan mendapati bahawa semua akses seterusnya tidak akan memukul cache. Sebabnya ialah apabila caching LRU dilakukan, ia diganti, tetapi sebenarnya ia telah diakses sekali dalam satu zaman, dan ia tidak akan dapat diakses lagi dalam zaman ini. LRU menyimpannya bukan sahaja LRU tidak membantu, ia sebenarnya memburukkan lagi. Lebih baik menggunakan seragam, seperti kaedah berikut.
Kaedah seragam berikut sentiasa menyimpan cache D dan B dalam cache dan tidak pernah membuat sebarang penggantian. Dalam kes ini, anda akan mendapati sekurang-kurangnya 50% kadar hit. Oleh itu, anda boleh melihat bahawa algoritma caching tidak perlu rumit. Hanya gunakan seragam.
Untuk soalan kedua, iaitu tentang hubungan antara cache dan lebar jalur jauh. Data baca ke hadapan kini terbina dalam semua rangka kerja AI arus perdana untuk menghalang GPU daripada menunggu data. Oleh itu, apabila GPU sedang berlatih, ia sebenarnya mencetuskan CPU untuk pra-menyediakan data yang mungkin digunakan dalam pusingan seterusnya. Ini boleh menggunakan sepenuhnya kuasa pengkomputeran GPU. Tetapi apabila storan jauh IO menjadi halangan, ini bermakna GPU perlu menunggu CPU. Oleh itu, GPU akan mempunyai banyak masa terbiar, mengakibatkan pembaziran sumber. Saya harap ada kaedah pengurusan penjadualan yang lebih baik untuk mengurangkan masalah IO.

Cache dan IO jauh mempunyai impak yang besar pada daya kerja keseluruhan kerja. Jadi selain GPU, CPU dan memori, cache dan rangkaian juga perlu dijadualkan. Dalam proses pembangunan data besar yang lalu, seperti Hadoop, yarn, sumber saya, K8s, dll., terutamanya berjadual CPU, memori dan GPU. Kawalan ke atas rangkaian, terutamanya cache, tidak begitu baik. Oleh itu, kami percaya bahawa dalam senario AI, mereka perlu dijadualkan dengan baik dan diperuntukkan untuk mencapai pengoptimuman keseluruhan kluster.
2. Rangka kerja SiloD

menerbitkannya di artikel EuroSys 2023, ia adalah rangka kerja bersatu untuk menjadualkan sumber pengkomputeran dan sumber storan.
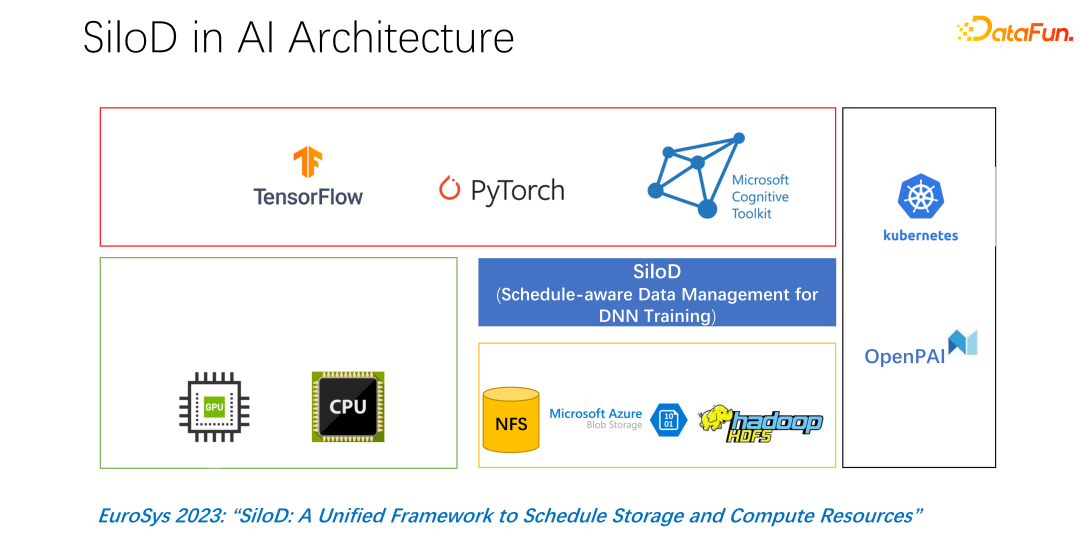
Seni bina keseluruhan ditunjukkan dalam gambar di atas. Sudut kiri bawah ialah sumber pengkomputeran perkakasan CPU dan GPU dalam kluster, serta sumber storan, seperti NFS, storan awan HDFS, dsb. Di peringkat atas, terdapat beberapa rangka kerja latihan AI seperti TensorFlow, PyTorch, dsb. Kami percaya bahawa kami perlu menambah pemalam yang mengurus dan memperuntukkan sumber pengkomputeran dan storan secara seragam, iaitu SiloD yang dicadangkan kami.
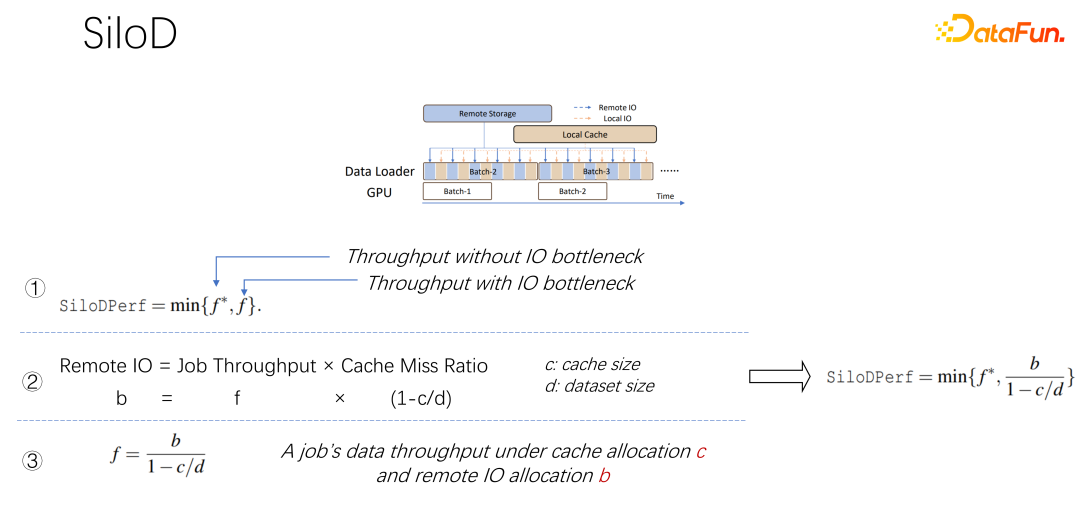
Seperti yang ditunjukkan dalam rajah di atas, jenis pemprosesan dan prestasi kerja yang boleh dicapai ditentukan oleh GPU minimum dan nilai IO ditentukan. Berapa banyak IO jauh digunakan, berapa banyak rangkaian jauh digunakan. Kelajuan capaian boleh dikira melalui formula sedemikian. Kelajuan kerja didarab dengan kadar kehilangan cache, iaitu (1-c/d). Di mana c ialah saiz cache dan d ialah set data. Ini bermakna apabila data hanya mempertimbangkan IO dan mungkin menjadi kesesakan, daya pengeluaran anggaran adalah sama dengan (b/(1-c/d)), dengan b ialah lebar jalur jauh. Menggabungkan tiga formula di atas, kita boleh menyimpulkan formula di sebelah kanan, iaitu jenis prestasi yang akhirnya ingin dicapai oleh pekerjaan Anda boleh menggunakan formula untuk mengira prestasi apabila tiada kesesakan IO dan prestasi apabila ada IO kesesakan.
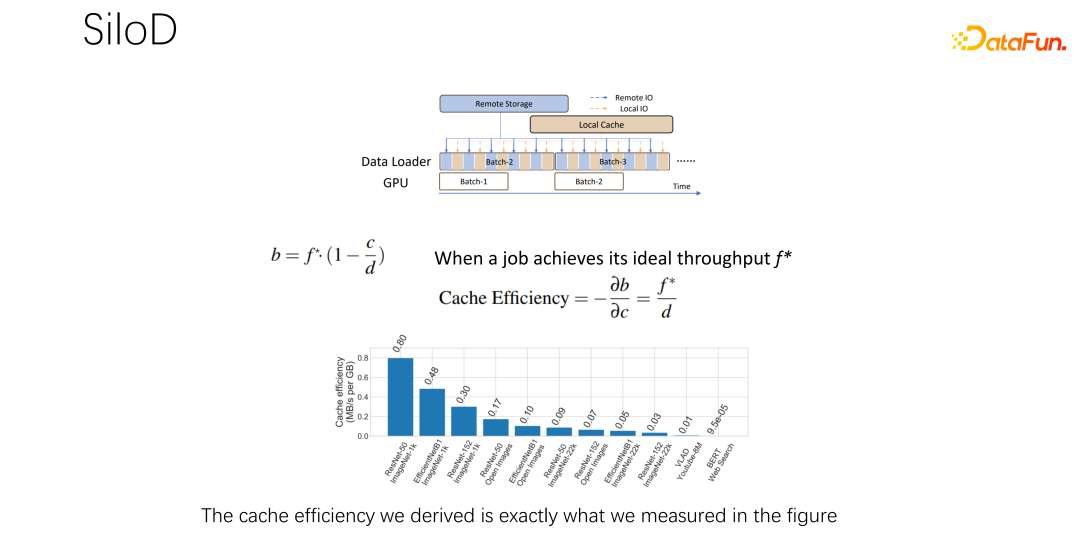
Setelah mendapat formula di atas, bezakan untuk mendapatkan keberkesanan prestasi cache, atau kecekapan cache. Iaitu, walaupun terdapat banyak pekerjaan, mereka tidak boleh dilayan sama apabila memperuntukkan cache. Setiap kerja, berdasarkan set data dan kelajuan yang berbeza, sangat khusus tentang jumlah cache yang diperuntukkan. Berikut ialah contoh, mengambil formula ini sebagai contoh Jika anda menemui kerja yang sangat pantas dan berlatih dengan sangat cepat, dan set data adalah kecil, ini bermakna memperuntukkan cache yang lebih besar dan faedahnya akan lebih besar.
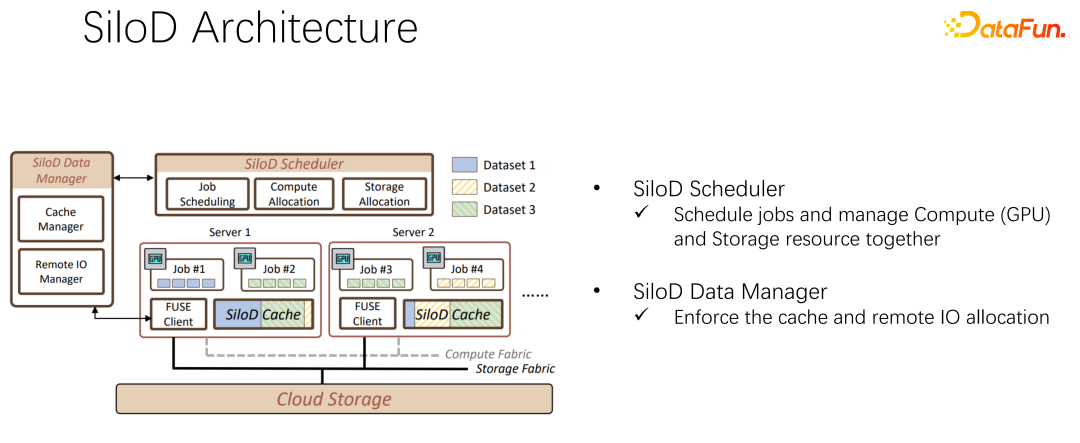
Berdasarkan pemerhatian di atas, SiloD boleh digunakan untuk cache dan peruntukan rangkaian. Selain itu, saiz cache diperuntukkan berdasarkan kelajuan setiap kerja dan saiz keseluruhan set data. Perkara yang sama berlaku untuk web. Jadi keseluruhan seni bina adalah seperti ini: sebagai tambahan kepada penjadualan kerja arus perdana seperti K8, terdapat juga pengurusan data. Di sebelah kiri angka, sebagai contoh, pengurusan cache memerlukan statistik atau pemantauan saiz cache yang diperuntukkan kepada keseluruhan kluster, saiz setiap cache kerja dan saiz IO jauh yang digunakan oleh setiap kerja. Operasi berikut sangat serupa dengan kaedah Alluxio, dan kedua-duanya boleh menggunakan API untuk latihan data. Gunakan cache pada setiap pekerja untuk menyediakan sokongan caching untuk kerja tempatan. Sudah tentu, ia juga boleh merentangi nod dalam kelompok dan juga boleh dikongsi.
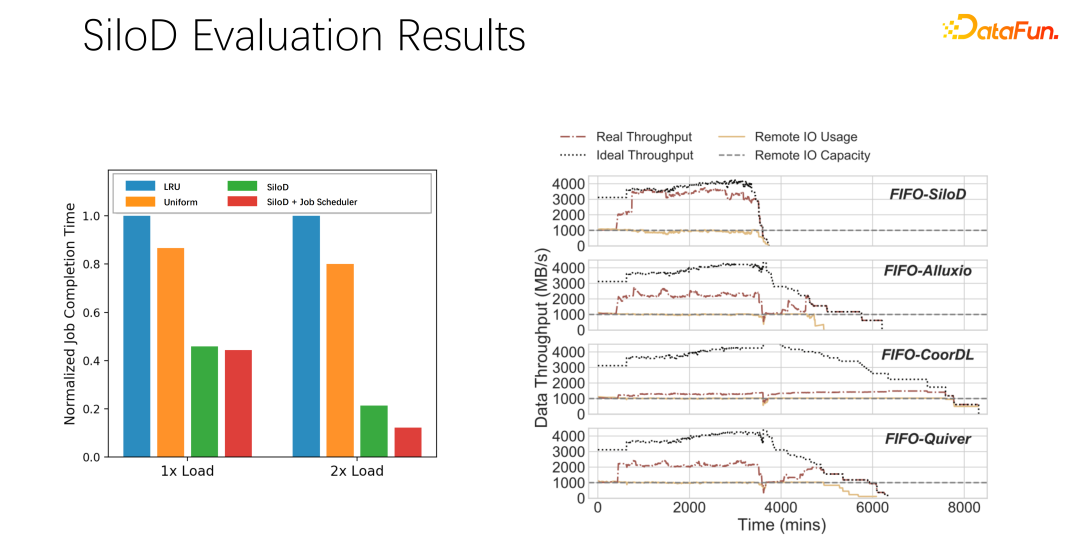
Selepas ujian dan eksperimen awal, didapati kaedah peruntukan sebegini boleh meningkatkan penggunaan dan daya pengeluaran keseluruhan kelompok. Peningkatan yang sangat jelas, sehingga 8 kali peningkatan prestasi. Ia jelas boleh mengurangkan status menunggu kerja dan kemalasan GPU.

Untuk meringkaskan pengenalan di atas:
Pertama, Dalam AI atau senario latihan pembelajaran mendalam, strategi caching tradisional seperti LRU dan LFU adalah lebih baik untuk menggunakan seragam secara langsung.
Kedua, Cache dan lebar jalur jauh ialah sepasang rakan kongsi, yang memainkan peranan besar dalam prestasi keseluruhan peranan.
Ketiga, Rangka kerja penjadualan arus perdana seperti K8 dan benang boleh diwarisi dengan mudah daripada SiloD.
Akhir sekali, Kami melakukan beberapa percubaan dalam kertas kerja Strategi penjadualan yang berbeza boleh membawa Daya tampung jelas dipertingkatkan .
3 Strategi cache dan pengurusan salinan yang diedarkan
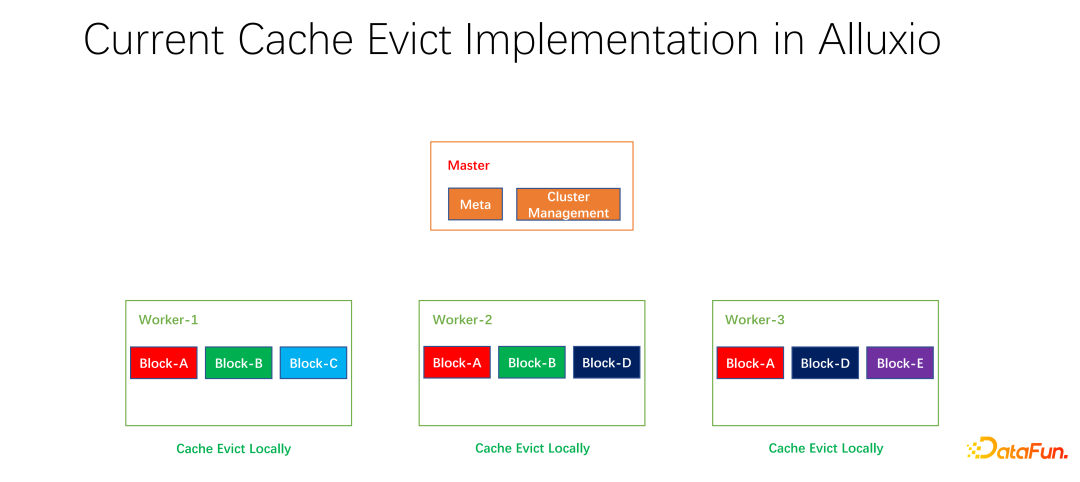
Kami juga telah melakukan beberapa kerja sumber terbuka. Kerja mengenai strategi caching teragih dan pengurusan replika ini telah diserahkan kepada komuniti dan kini dalam peringkat PR. Alluxio master bertanggungjawab terutamanya untuk pengurusan Meta dan pengurusan keseluruhan kluster pekerja. Ia adalah pekerja yang sebenarnya menyimpan data. Terdapat banyak blok dalam unit blok untuk cache data. Satu masalah ialah strategi caching semasa adalah untuk pekerja tunggal Apabila mengira sama ada untuk menghapuskan setiap data dalam pekerja, ia hanya perlu dikira pada seorang pekerja dan disetempatkan.
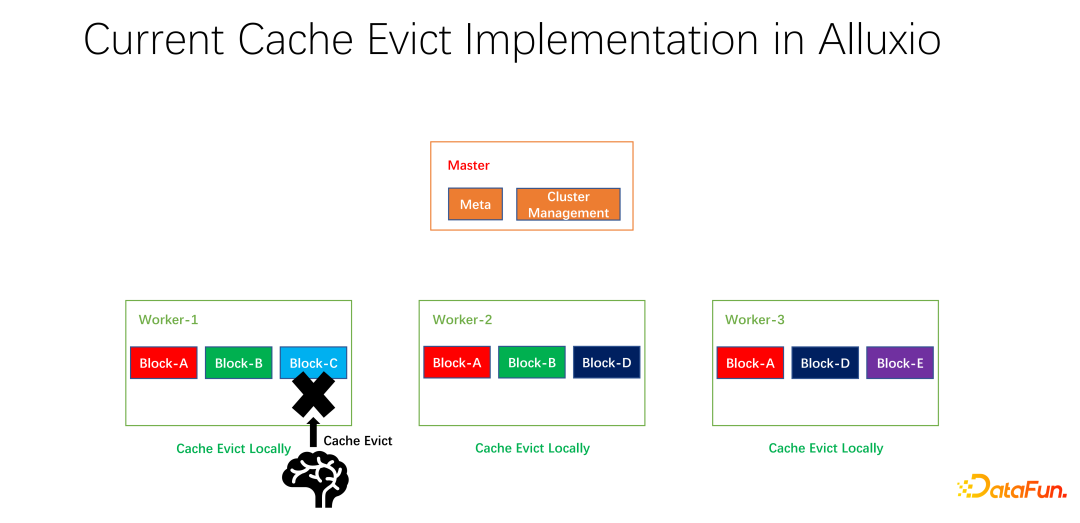
Seperti yang ditunjukkan dalam contoh di atas, jika terdapat blok A dan blok B pada pekerja 1 Dan blok C, berdasarkan pengiraan LRU, blok C akan dihapuskan jika ia tidak digunakan untuk masa yang paling lama. Jika anda melihat keadaan keseluruhan, anda akan mendapati bahawa ini tidak baik. Kerana blok C hanya mempunyai satu salinan dalam keseluruhan kluster. Selepas ia dihapuskan, jika orang lain ingin mengakses blok C, mereka hanya boleh menarik data dari hujung jauh, yang akan menyebabkan kehilangan prestasi dan kos. Kami mencadangkan strategi penyingkiran global. Dalam kes ini, blok C tidak boleh dihapuskan, tetapi blok yang mempunyai lebih banyak salinan harus dihapuskan. Dalam contoh ini, blok A harus dihapuskan kerana ia masih mempunyai dua salinan pada nod lain, yang lebih baik dari segi kos dan prestasi.
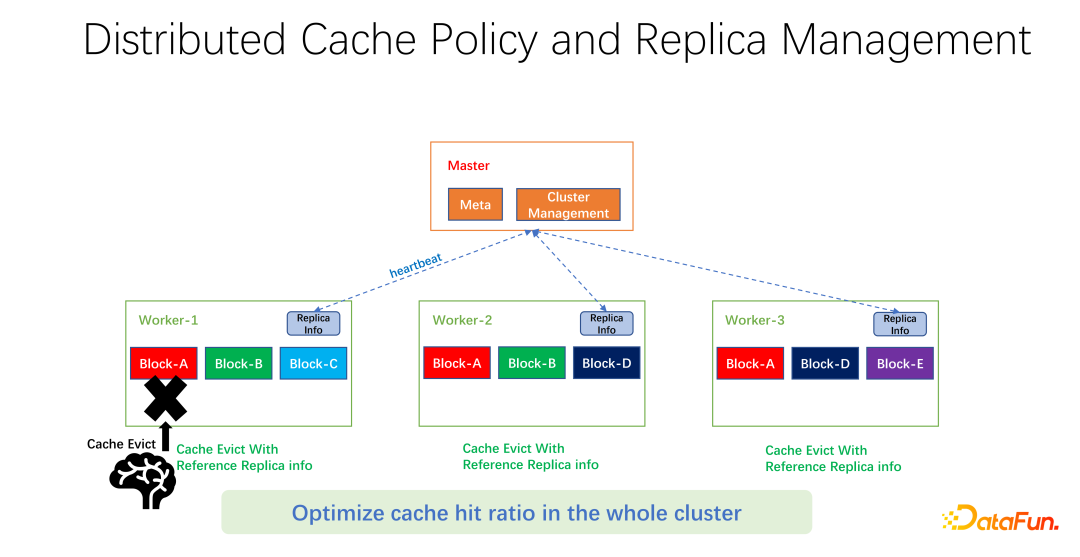
Seperti yang ditunjukkan dalam rajah di atas, apa yang kami lakukan adalah untuk mengekalkan maklumat replika pada setiap pekerja. Apabila pekerja, sebagai contoh, menambah salinan atau mengalih keluar salinan, ia akan melaporkan terlebih dahulu kepada induk dan induk akan menggunakan maklumat ini sebagai nilai pulangan degupan jantung dan mengembalikannya kepada pekerja lain yang berkaitan. Pekerja lain boleh mengetahui perubahan masa nyata bagi keseluruhan salinan global. Pada masa yang sama, maklumat salinan dikemas kini. Oleh itu, apabila menghapuskan pekerja dalaman, anda boleh mengetahui bilangan salinan setiap pekerja di seluruh dunia, dan anda boleh mereka bentuk beberapa pemberat. Sebagai contoh, LRU masih digunakan, tetapi berat bilangan replika ditambah untuk mempertimbangkan secara menyeluruh data yang hendak dihapuskan dan diganti.
Selepas ujian awal kami, ia boleh membawa peningkatan yang hebat dalam banyak bidang, sama ada data besar atau latihan AI. Jadi ia bukan hanya tentang mengoptimumkan hits cache untuk seorang pekerja pada satu mesin. Matlamat kami adalah untuk meningkatkan kadar hit cache bagi keseluruhan kluster.

Akhir sekali, mari kita ringkaskan teks penuh. Pertama sekali, dalam senario latihan AI, algoritma penyingkiran cache seragam adalah lebih baik daripada LRU dan LFU tradisional. Kedua, cache dan rangkaian jauh juga merupakan sumber yang perlu diperuntukkan dan dijadualkan. Ketiga, apabila mengoptimumkan cache, jangan hanya menghadkannya kepada satu kerja atau satu pekerja Anda harus mengambil kira keseluruhan parameter global hujung ke hujung, supaya kecekapan dan prestasi keseluruhan kluster dapat dipertingkatkan dengan lebih baik.
Atas ialah kandungan terperinci Amalan pengoptimuman cache untuk latihan pembelajaran mendalam berskala besar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI