
Rumah >pangkalan data >tutorial mysql >Analisis titik pengetahuan indeks MySQL
Analisis titik pengetahuan indeks MySQL

- PHPzke hadapan
- 2023-05-27 20:38:351571semak imbas
1 Konsep indeks
1.1 Definisi
Dalam pangkalan data hubungan, indeks ialah pasangan pangkalan data fizikal yang berasingan A storan struktur yang mengisih satu atau lebih nilai lajur dalam jadual Ia adalah koleksi satu atau lebih nilai lajur dalam jadual, dan senarai penunjuk logik ke halaman data dalam jadual yang mengenal pasti nilai ini secara fizikal.
Indeks adalah bersamaan dengan jadual kandungan buku Anda boleh mencari kandungan yang anda perlukan dengan cepat berdasarkan nombor halaman utama jadual kandungan Pangkalan data menggunakan indeks untuk mencari nilai tertentu, dan kemudian mengikuti penunjuk untuk mencari baris yang mengandungi nilai, yang boleh sepadan dengan jadual penyata SQL dilaksanakan dengan lebih pantas dan menyediakan akses pantas kepada maklumat tertentu dalam jadual pangkalan data.
1.2 Jenis
InnoDB merangkumi tiga jenis indeks, iaitu indeks biasa, indeks unik (indeks kunci utama ialah indeks unik bukan kosong khas) dan indeks teks penuh.
ditulis semula sebagai: Indeks biasa juga dipanggil indeks bukan unik, tanpa sebarang sekatan. Unik: Indeks unik memerlukan nilai kunci tidak boleh diulang (boleh kosong Indeks kunci utama sebenarnya adalah indeks unik khas, tetapi ia juga mempunyai sekatan tambahan, yang memerlukan nilai kunci tidak boleh kosong. Indeks kunci utama dicipta dengan kunci utama. Teks penuh: Untuk data yang agak besar, seperti artikel, teks, e-mel, dsb., satu medan mungkin memerlukan beberapa kb Jika anda ingin menyelesaikan masalah kecekapan rendah pertanyaan seperti dalam padanan teks penuh, anda boleh mencipta teks Penuh indeks. Hanya medan jenis char, varchar dan teks boleh membuat indeks teks penuh. Kedua-dua MyISAM dan InnoDB menyokong pengindeksan teks penuh.
1.3 Fungsi
Ringkasan satu ayat:
Indeks boleh meningkatkan kecekapan pengambilan data dan mengurangkan kos IO pangkalan data.
Tanya soalan: Kami menukar ruang untuk masa, tetapi bagaimana pula dengan struktur datanya, kos IO pertanyaan dan cara menyimpan data?
2 data terindeks Evolusi proses struktur pokok B+
Mari kita lihat proses evolusi pokok B+ kita dari perspektif Page.
Halaman ialah unit asas untuk InnoDB untuk mengurus ruang storan dalam pangkalan data dalam unit storan asas halaman juga merupakan unit asas interaksi antara memori dan cakera pangkalan data bermula dari cakera Baca beberapa halaman data ke dalam memori, dan muat semula beberapa halaman data dalam memori ke cakera.
Saiz memori satu halaman ialah 16KB.
Andaikan kami ingin melaksanakan SQL ini dan mendapatkan 10 rekod:
SELECT * FROM INNODB_USER LIMIT 0 , 10;
Jika saiz data rekod ialah 4K, maka salah satu halaman Halaman kami boleh Berapa keping data yang disimpan?
16K bahagi dengan 4K dapat 4 rekod, betul.
Setiap data dalam Halaman mempunyai atribut utama yang dipanggil record_type
0 Rekod pengguna biasa 1 Rekod indeks direktori 2 Minimum 3 Maksimum
Lukiskan gambar untuk menunjukkan cara data diletakkan pada halaman:

Ini adalah Halaman kami, dan setiap Halaman akan menyimpan data, Simpan data dengan cara yang teratur mengikut kunci utama
Kami tahu bahawa penyimpanan data adalah IO berurutan, yang mudah untuk penyimpanan Walau bagaimanapun, jika storan mudah, ia akan menyusahkan jika anda ingin menyemak yang terakhir, adakah anda perlu melintasinya Keseluruhan halaman data?
2.1 Soalan
Bagaimana jika kita ingin menyemak sekeping data Bagaimana kita boleh mencari data dengan cepat?
Jika data dalam Halaman kami disambungkan, fikirkan tentang struktur data yang telah kami pelajari, struktur manakah yang paling pantas ditanya?
Jika data dalam Halaman kami mempunyai kaedah sambungan, ia boleh diselesaikan! Betul, ia adalah senarai terpaut
Cara data dalam halaman Halaman disambungkan (data berada dalam halaman yang sama):
MySQL menghubungkan data dalam halaman melalui senarai terpaut sehala Jika pertanyaan berdasarkan kunci utama, kaedah penentududukan binari akan menjadi sangat pantas pertanyaan adalah berdasarkan indeks kunci bukan utama, hanya Boleh merentasi senarai terpaut sehala bermula dari yang terkecil.
Cara mewujudkan sambungan antara berbilang Halaman (data berada dalam halaman berbeza):
MySQL melepasi halaman berbeza melalui dua hala senarai terpaut Wujudkan pautan supaya kami dapat mencari halaman seterusnya melalui halaman sebelumnya dan satu halaman melalui halaman seterusnya Memandangkan kami tidak dapat mencari halaman di mana data berada , kami hanya boleh bermula dari yang pertama. halaman Cari sehingga ke bawah senarai pautan berganda, dan kemudian cari rekod yang ditentukan dalam setiap halaman seperti pada halaman yang sama Ini juga merupakan imbasan jadual penuh.

2.2 Masalah
Apabila semakin banyak halaman Halaman, apakah masalah yang akan berlaku dalam pertanyaan, cara menyelesaikan dan mengoptimumkan? 🎜> Kerumitan masa pertanyaan 0 (N) Terlalu banyak kali IO untuk membaca dan menulis cakera Jom fikirkan tentangnya Apabila kita biasanya membaca buku, kita ingin mencari maklumat pada halaman tertentu. Cari direktori di Baidu dan siarkan gambar: Kami mendapati terdapat dua dalam direktori ini Sangat maklumat penting: Pengenalan kandungan (tajuk bab) Nombor halaman di mana Kami menggunakan idea merujuk kepada katalog buku untuk mencapai matlamat kami menanya data dengan cepat: Tambah katalog pada data dan semak data . Kami mula-mula menggunakan Katalog Halaman mencari di mana data berada di halaman mana, meningkatkan prestasi pertanyaan . Walau bagaimanapun, Adakah anda perlu kerap membuat direktori? Sebagai contoh, direktori kamus ditubuhkan mengikut susunan abjad Apakah yang anda fikirkan? Betul, kunci utama Kunci utama yang ditambah secara automatik dalam Mysql hanya memenuhi keperluan kami, mempunyai kandungan yang kurang dan tidak boleh diulang kunci setiap halaman mengikut peraturan , tambahkan penunjuk yang menunjuk ke lokasi data, secara langsung berdasarkan saiz kunci utama semasa pertanyaan, gunakan kaedah dikotomi untuk mencari direktori dengan cepat, dan kemudian cari data. Pokok ini disimpan mengikut kunci utama , jadi kami memanggilnya pokok indeks kunci utama , kerana Kunci utama pokok indeks menyimpan semua data dalam jadual kami, jadi dalam MySQL indeks ialah data dan data ialah indeks atas sebab yang sama. Ini ialah struktur data pepohon indeks kunci utama MysqlB+. Adakah ia lebih mengagumkan daripada pengetahuan yang anda dapat dengan menghafalnya secara terus Kami telah menemui cara untuk meningkatkan prestasi pertanyaan Jadi, apakah masalah yang akan kami hadapi apabila Halaman ditambah, diubah suai atau dipadamkan? Jika ia Buka halaman baharu dan cari lokasi data. Alihkan data lama ke halaman baharu dan letakkan data baharu dalam kedudukan tersusun. Data nod daun terus beralih. Mencetuskan pemisahan dan penggabungan Halaman data nod daun dan mencetuskan pemisahan dan penggabungan nod daun atas dan nod akar semula. Apakah ini dipanggil, "satu langkah menjejaskan seluruh badan", juga dipanggil pemisahan halaman! ! Ringkasan: Masalah yang dihadapi semasa menambah, mengubah suai dan memadam halaman Halaman: Kita boleh mengatakan bahawa apabila gangguan meningkat Semasa kemas kini operasi seperti mengemas kini ID kunci utama dan memadam halaman indeks, akan terdapat sejumlah besar pelarasan nod pokok, yang akan mencetuskan kelui dan penggabungan halaman halaman nod daun anak dan halaman nod daun atas dan nod akar, menghasilkan sejumlah besar pemecahan cakera dan kehilangan kapasiti pangkalan data menerangkan sebab kami tidak seharusnya membina indeks pada lajur yang kerap dikemas kini dan diubah suai, atau mengapa kami tidak perlu mengemas kini kunci utama . Mari kita ringkaskan: Indeks Berkelompok (Indeks Berkelompok): Pokok indeks kunci utama juga Ia dipanggil indeks berkelompok atau indeks berkelompok Dalam InnoDB, jadual hanya mempunyai satu pepohon indeks berkelompok Jika jadual mencipta indeks kunci utama, maka indeks kunci utama ini adalah indeks berkelompok pokok indeks berkelompok Dalam susunan storan fizikal baris, indeks berkelompok kami akan mengisih dan menyimpan semua lajur dalam jadual, dan data ialah indeks, yang merujuk kepada pokok indeks kunci utama kami. Mengapakah yang terbaik untuk ID kunci utama mempunyai arah aliran yang semakin meningkat? 你刚刚看完啊,不会没记住吧,有序递增,下一个数据页中用户记录的主键值必须大于上一个页中用户的主键值,假如我是趋势递增,存入的数据肯定是在最末尾链表或者新增一个链表,就不会触发页的分裂与合并,导致添加的速度变慢。 三层B+数能存多少数据? 考察点:Page页的大小,B+树的定义 答: mysql 大字段为什么要拆分? 一个Page页可存放16K的数据,大字段占用大量的存储空间,意味着一个Page页可存储的数据条数变少,那么就需要更多的页来存储,需要更多的Page,意味着树的深度会变高。那么磁盘IO的次数会增加,性能下降,查询更慢。大字段不管是否被使用都会存放在索引上,占据大量内存空间压缩Page数据条数。 为什么用B+树? B+树的底层是多路平衡查找树,对于每一次的查询的都是从根节点触发,到子叶结点才存放数据,根节点和非叶子结点都是存放的索引指针,查找叶子结点互,可以根据键值数据查询。具备更强的扫库、扫表能力、排序能力以及查询效率和性能的稳定性,存储能力也更强,仅使用三层B+树就能存储千万级别的数据。 刚才看的是根据主键得来的索引,我们如果不查主键,或者说表里压根就没有主键,怎么办?我们还可以根据几个字段来创建联合索引(组合索引聚合索引。。哎呀名字而已怎么叫都行)。 根据主键得到的索引树叫主键索引树,根据别的字段得到的索引树叫二级索引树。 通过下面的SQL 可以建立一个组合索引 其实,看似建立了1个索引,但是你使用 age 查询 age,user_name 查询 age,user_name,phone 都能生效 首先需要知道参与排序的字段类型是否有有序? 如果是有序字段,就按照有序字段排序比如(int) 1 2 3 4。 我现在有一个组合索引(A-B-C)他会按照你建立字段的顺序来进行排序: 我们的Page会根据组合索引的字段建立顺序来存储数据,年龄 用户名 手机号。 还是上面那个索引,年龄用户名手机号,age,username,phone 只使用了user_name 能使用到索引吗? 最左其实就是因为我们是按照组合索引的顺序来存储的。大家常说的"索引桥"也是这个原因。在命中组合索引中,必须像过桥一样,先跨过第一块木板,再到第二块木板,最后到第三块木板。 二级索引树有三个重要的概念,分别是回表、覆盖索引、索引下推。. 回表就是:我们查询的数据不在二级索引树中需要拿到ID去主键索引树找的过程。 覆盖索引就是:我们需要查询的数据都在二级索引树中,直接返回这种情况就叫做覆盖索引。 为什么离散度低的列不走索引? Apakah konsep penyebaran? Lebih banyak data yang sama, lebih rendah serakan, dan semakin kurang data yang sama, semakin tinggi serakan. Bukankah lebih banyak indeks, lebih baik? Dari segi ruang: Tukar ruang dengan masa dan indeks perlu menduduki ruang cakera. Juga dipanggil indeks gabungan (indeks komposit), pokok indeks sekunder menyimpan susunan nama lajur apabila kami mencipta indeks. Ia hanya menyimpan sebahagian daripada data yang digunakan untuk mencipta nama lajur indeks sekunder Pepohon indeks sekunder dilahirkan untuk membantu kami membuat pertanyaan dan meningkatkan kecekapan pertanyaan Terdapat tiga tindakan dalam pepohon indeks sekunder: pulangan jadual, indeks penutup, dan tekan turun indeks. Antaranya, yang paling berprestasi ialah indeks penutup. Saya dapati gambar perbezaan dalam talian
Semak katalog, bukan? Apa itu direktori? Bukankah ia hanya indeks? 
2.3 soalan: Bagaimana untuk mencipta direktori? Buat jadual kandungan untuk setiap halaman?
Tetapi adakah kita perlu membuat direktori untuk setiap halaman data? Nampaknya ini masih perlu Jika anda tidak membuat data untuk setiap halaman, bagaimana anda boleh mencari data dalam halaman? Adakah imbasan halaman penuh?
Tetapi buat direktori untuk setiap halaman Memandangkan terdapat berbilang halaman direktori dan muncul, kami perlu merentasi setiap direktori dan prestasi pertanyaan juga akan menurun .
Bolehkah kita mencipta direktori untuk direktori itu?
Jadi, kami juga boleh membuat direktori untuk halaman direktori dan mengekstrak satu lapisan nod akar ke atas, yang akan memudahkan kami membuat pertanyaan. 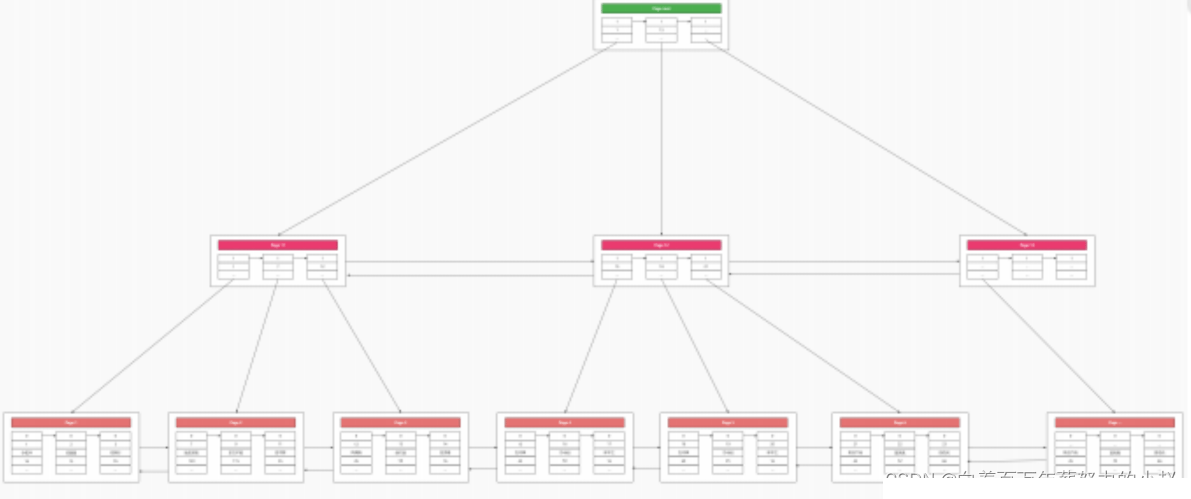
2.4 pepohon indeks, Memisahkan dan menggabungkan halaman
有序增加, apakah yang perlu saya lakukan jika saya menambah sekeping data baharu?
Halaman penuh, jadi adakah anda perlu membuka halaman baharu?
Dan data pada halaman mesti memenuhi syarat: Nilai kunci utama rekod pengguna dalam halaman data seterusnya mestilah lebih besar daripada nilai kunci utama rekod pengguna di halaman sebelumnya
Oleh kerana ia adalah peningkatan yang teratur, Kami boleh terus menambah halaman pada penghujung senarai halaman berganda.
Bagaimana jika ia 无序增加 dan sekeping data baharu ditambah?
2.5 Berdasarkan apa yang baru kami simpulkan, berikut ialah beberapa soalan temu bual
1GB = 1024 M, 1mb = 1024k,1k= 1024 bytes
已知:索引逻辑单元 16bytes 字节,16KB=16* 1024*1024,肯定比一千万多,在InnoDB中B+树的深度为3层就能满足千万级别的数据存储。3什么是二级索引树
ALTER TABLE INNODB_USER ADD INDEX
SECOND_INDEX_AGE_USERNAME_PHONE('age','user_name','phone');
您也可以认为建立了三个这样的索引:ALTER TABLE INNODB__USER ADD INDEX
SECOND_INDEX_AGE__USERNAME_PHONE('age');
ALTER TABLE INNODB_USER ADD INDEX
SECOND_INDEX_AGE_USERNAME_PHONE('age','user_name');
ALTER TABLE `INNODB_USER`ADD INDEX
SECOND_INDEX_AGE_USERNAME_PHONE('age','user_name','phone');
3.1那么二级索引树怎么排序?
如果是无序字段,按照这个列的字符集的排序规则来排序,这点不去深入,知道就好。
如果A相同按照B排序,如果B相同按照C排序,如果ABC全部相同,会按照聚集索引进行排序。
它的数据结构其实是一样的3.2索引桥的概念是什么呢(最左匹配原则)?
那么可以看到我们第一个字段是AGE,如果需要这个索引生效,是不是在查询的时候需要先使用Age查询,然后如果还需要user_name,就使用user_name。
其实是不行的,因为我是先使用age进行排序的,你必须先命中age,再命中user_name,再命中phone,这个其实
就是我们所说的最左匹配原则。3.3回表、覆盖索引、索引下推
索引下推(index condition pushdown )简称ICP:在Mysql5.6以后的版本上推出,用于优化回表查询;3.4延申几个面试题:
Mereka semua mempunyai data yang sama, bagaimana untuk mengisihnya? Tidak boleh menyusunnya?
Terdapat terlalu banyak nilai pendua dalam B+Tree Apabila pengoptimum MySQL mendapati bahawa pengindeksan hampir sama dengan menggunakan imbasan jadual penuh, ia tidak akan pergi walaupun indeks dibuat. Sama ada hendak menggunakan indeks atau tidak ditentukan oleh pengoptimum MySQL.
Masa: Tekan indeks untuk mempercepatkan kecekapan pertanyaan kami Jika ia dikemas kini dan dipadam, ia akan menyebabkan pemisahan dan penggabungan halaman, menjejaskan masa tindak balas penyisipan dan kemas kini, tetapi perlahan. prestasi menurun.
Jika ia adalah lajur yang perlu dikemas kini dengan kerap, tidak disyorkan untuk membuat indeks, kerana ia akan mencetuskan pemisahan dan penggabungan halaman dengan kerap. 3.5 Ringkasan pokok indeks sekunder
4 Perbezaan antara indeks kunci primer dan indeks sekunder
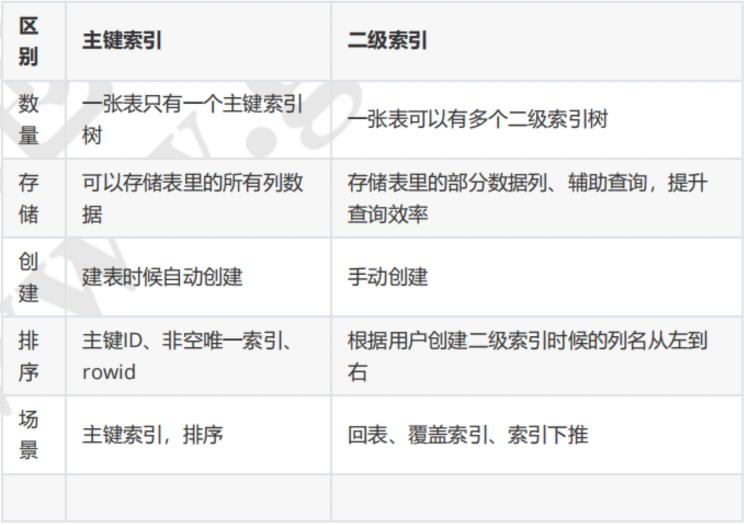
Atas ialah kandungan terperinci Analisis titik pengetahuan indeks MySQL. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!