
Rumah >Peranti teknologi >AI >Inferens LLM adalah 3 kali lebih cepat! Microsoft mengeluarkan LLM Accelerator: menggunakan teks rujukan untuk mencapai pecutan tanpa kerugian
Inferens LLM adalah 3 kali lebih cepat! Microsoft mengeluarkan LLM Accelerator: menggunakan teks rujukan untuk mencapai pecutan tanpa kerugian

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-27 10:40:061555semak imbas
Dengan perkembangan pesat teknologi kecerdasan buatan, produk dan teknologi baharu seperti ChatGPT, New Bing dan GPT-4 telah dikeluarkan satu demi satu model besar Asas akan memainkan peranan yang semakin penting dalam banyak aplikasi.
Kebanyakan model bahasa besar semasa ialah model autoregresif. Autoregression bermaksud model sering menggunakan output perkataan demi perkataan semasa mengeluarkan, iaitu apabila mengeluarkan setiap perkataan, model perlu menggunakan perkataan output sebelum ini sebagai input. Mod autoregresif ini biasanya mengehadkan penggunaan penuh pemecut selari semasa output.
Dalam banyak senario aplikasi, output model besar selalunya sangat serupa dengan beberapa teks rujukan, seperti dalam tiga senario biasa berikut:
1. Mendapatkan semula generasi dipertingkatkan
Apabila aplikasi mendapatkan semula seperti New Bing bertindak balas kepada input pengguna, mereka akan mengembalikan beberapa maklumat yang berkaitan dengan input pengguna Maklumat yang berkaitan kemudian digunakan untuk meringkaskan maklumat yang diambil menggunakan model bahasa, dan kemudian menjawab input pengguna. Dalam senario ini, output model selalunya mengandungi sejumlah besar serpihan teks daripada hasil carian.
2. Gunakan penjanaan cache
Dalam proses penggunaan model bahasa secara besar-besaran, input sejarah dan kehendak output dicache. Apabila memproses input baharu, aplikasi mendapatkan semula mencari input yang serupa dalam cache. Oleh itu, output model selalunya hampir sama dengan output yang sepadan dalam cache.
3. Penjanaan dalam perbualan berbilang pusingan
Apabila menggunakan aplikasi seperti ChatGPT, pengguna cenderung menggunakan model berdasarkan Keluaran berulang kali meminta pengubahsuaian. Dalam senario dialog berbilang pusingan ini, keluaran berbilang model selalunya hanya mempunyai sedikit perubahan dan tahap pengulangan yang tinggi.
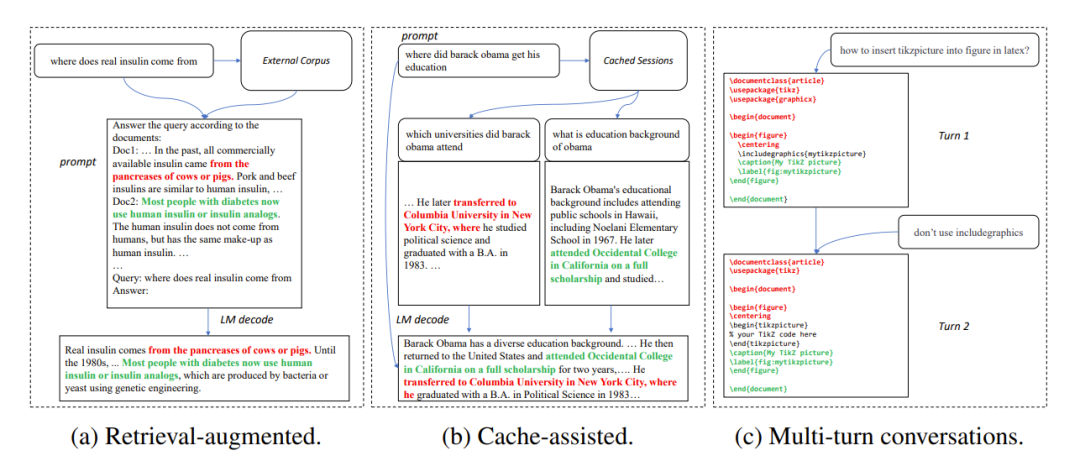
Rajah 1: Senario biasa di mana output model besar adalah serupa dengan teks rujukan
Berdasarkan pemerhatian di atas, penyelidik menggunakan kebolehulangan teks rujukan dan output model sebagai fokus untuk menembusi kesesakan autoregresif, dengan harapan dapat meningkatkan penggunaan pemecut selari, mempercepatkan inferens model bahasa yang besar, dan kemudian Kaedah LLM Accelerator dicadangkan yang menggunakan pengulangan output dan teks rujukan untuk mengeluarkan berbilang perkataan dalam satu langkah.
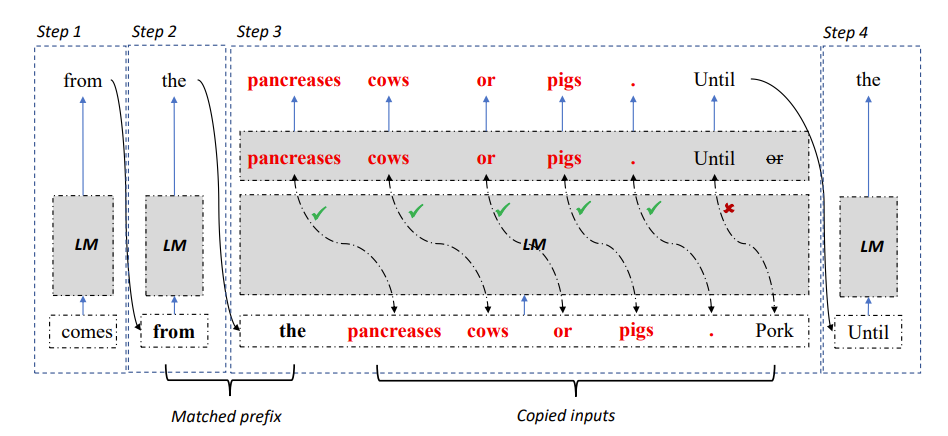
Rajah 2: Algoritma penyahkodan LLM Accelerator
Khususnya, pada setiap langkah penyahkodan, biarkan model memadankan hasil output sedia ada dengan teks rujukan jika teks rujukan didapati konsisten dengan output sedia ada, maka model mungkin akan menangguhkan teks rujukan sedia ada dan meneruskan. kepada output.
Oleh itu, penyelidik menambah perkataan seterusnya bagi teks rujukan sebagai input kepada model, supaya satu langkah penyahkodan boleh mengeluarkan berbilang perkataan.
Untuk memastikan input dan output adalah tepat, penyelidik membandingkan lagi perkataan output oleh model dengan perkataan input daripada dokumen rujukan. Jika kedua-duanya tidak konsisten, hasil input dan output yang salah akan dibuang.
Kaedah di atas boleh memastikan bahawa hasil penyahkodan adalah konsisten sepenuhnya dengan kaedah garis dasar, dan boleh meningkatkan bilangan perkataan keluaran dalam setiap langkah penyahkodan, dengan itu mencapai pecutan tanpa kehilangan inferens model besar .
LLM Accelerator tidak memerlukan model tambahan tambahan, mudah digunakan dan boleh digunakan dengan mudah dalam pelbagai senario aplikasi.
Pautan kertas: https://arxiv.org/pdf/2304.04487.pdf
Projek Pautan: https://github.com/microsoft/LMOps
Menggunakan LLM Accelerator, terdapat dua hiperparameter yang perlu dilaraskan.
Pertama, bilangan perkataan yang sepadan antara output yang diperlukan untuk mencetuskan mekanisme pemadanan dan teks rujukan: semakin lama bilangan perkataan yang sepadan, semakin tepat ia, yang dapat memastikan perkataan disalin daripada teks rujukan adalah output yang betul, mengurangkan ketidaktepatan pencetus dan pengiraan yang diperlukan;
Yang kedua ialah bilangan perkataan yang disalin setiap kali: semakin banyak perkataan yang disalin, semakin besar potensi pecutan, tetapi ia juga boleh menyebabkan lebih banyak keluaran yang salah akan dibuang, yang membazirkan sumber pengkomputeran . Penyelidik telah menemui melalui eksperimen bahawa strategi yang lebih agresif (memadankan pencetus perkataan tunggal, menyalin 15 hingga 20 perkataan pada satu masa) selalunya boleh mencapai nisbah pecutan yang lebih baik.
Untuk mengesahkan keberkesanan LLM Accelerator, penyelidik menjalankan eksperimen tentang peningkatan perolehan dan penjanaan bantuan cache, menggunakan set data perolehan perenggan MS-MARCO untuk membina sampel eksperimen.
Dalam percubaan peningkatan perolehan semula, penyelidik menggunakan model perolehan semula untuk mengembalikan 10 dokumen paling berkaitan bagi setiap pertanyaan, dan kemudian menyambungkannya ke dalam pertanyaan sebagai input model, menggunakan ini 10 dokumen sebagai teks Rujukan.
Dalam percubaan penjanaan dibantu cache, setiap pertanyaan menjana empat pertanyaan serupa, dan kemudian menggunakan model untuk mengeluarkan pertanyaan yang sepadan sebagai teks rujukan.
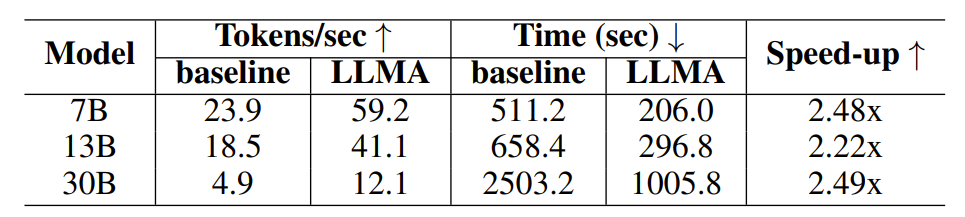
Jadual 1: Perbandingan masa di bawah pengambilan semula senario penjanaan dipertingkat
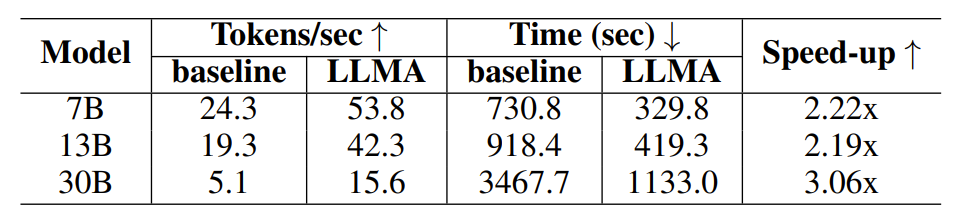
Jadual 2: Perbandingan masa dalam senario penjanaan menggunakan cache
Para penyelidik menggunakan output model Davinci-003 yang diperoleh melalui antara muka OpenAI sebagai output sasaran untuk mendapatkan output berkualiti tinggi. Selepas mendapat input, output dan teks rujukan yang diperlukan, penyelidik menjalankan eksperimen ke atas model bahasa LLaMA sumber terbuka.
Memandangkan output model LLaMA tidak konsisten dengan keluaran Davinci-003, penyelidik menggunakan kaedah penyahkodan berorientasikan matlamat untuk menguji nisbah kelajuan di bawah output ideal (Davinci-003 hasil model).
Para penyelidik menggunakan Algoritma 2 untuk mendapatkan langkah penyahkodan yang diperlukan untuk menjana output sasaran semasa penyahkodan tamak, dan memaksa model LLaMA untuk menyahkod mengikut langkah penyahkodan yang diperolehi.

Rajah 3: Menggunakan Algoritma 2 untuk mendapatkan langkah penyahkodan yang diperlukan untuk menjana output sasaran semasa penyahkodan tamak
Untuk model dengan saiz parameter 7B dan 13B, penyelidik menjalankan eksperimen pada GPU NVIDIA V100 32G tunggal untuk model dengan saiz parameter 30B, penyelidik menjalankan eksperimen pada empat GPU yang serupa Menjalankan eksperimen pada. Semua eksperimen menggunakan nombor titik terapung separuh ketepatan, penyahkodan ialah penyahkodan tamak, dan saiz kelompok ialah 1.
Hasil eksperimen menunjukkan bahawa LLM Accelerator telah mencapai dua hingga tiga kali ganda prestasi dalam saiz model yang berbeza (7B, 13B, 30B) dan senario aplikasi yang berbeza (peningkatan pengambilan semula, bantuan cache) Nisbah kelajuan .
Analisis eksperimen selanjutnya mendapati bahawa LLM Accelerator boleh mengurangkan langkah penyahkodan yang diperlukan dengan ketara, dan nisbah kelajuan dikaitkan secara positif dengan nisbah pengurangan langkah penyahkodan.
Di satu pihak, langkah penyahkodan yang lebih sedikit bermakna setiap langkah penyahkodan menjana lebih banyak perkataan keluaran, yang boleh meningkatkan kecekapan pengiraan pengiraan GPU, sebaliknya, untuk aplikasi yang memerlukan berbilang -keselarian kad Model 30B bermakna penyegerakan berbilang kad yang kurang, menghasilkan peningkatan kelajuan yang lebih pantas.
Dalam eksperimen ablasi, hasil analisis hiperparameter LLM Accelertator pada set pembangunan menunjukkan bahawa apabila memadankan satu perkataan (iaitu, mencetuskan mekanisme penyalinan), 15 hingga 20 disalin pada satu masa Nisbah kelajuan boleh mencapai maksimum apabila menggunakan perkataan (ditunjukkan dalam Rajah 4).
Dalam Rajah 5 kita dapat melihat bahawa bilangan perkataan yang sepadan ialah 1, yang boleh mencetuskan mekanisme penyalinan lebih banyak, dan apabila panjang salinan meningkat, perkataan output yang diterima oleh setiap langkah penyahkodan meningkat, dan langkah penyahkodan menurun, Dengan itu mencapai nisbah pecutan yang lebih tinggi.
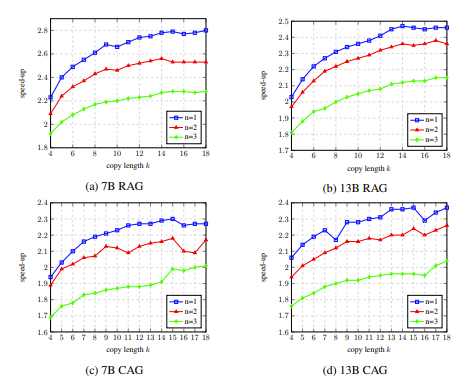
Rajah 4: Dalam eksperimen ablasi, keputusan analisis hiperparameter LLM Accelerator pada pembangunan set
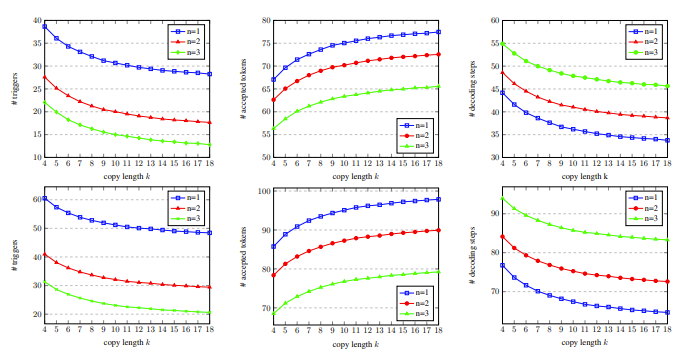
Rajah 5: Pada set pembangunan, dengan bilangan perkataan yang sepadan n dan salin perkataan Data statistik langkah penyahkodan k
LLM Accelertator ialah sebahagian daripada siri kerja Microsoft Research Asia Natural Language Computing Group pada pecutan model bahasa besar Pada masa hadapan, penyelidik akan meneruskan isu berkaitan untuk penerokaan yang lebih mendalam.
Atas ialah kandungan terperinci Inferens LLM adalah 3 kali lebih cepat! Microsoft mengeluarkan LLM Accelerator: menggunakan teks rujukan untuk mencapai pecutan tanpa kerugian. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI