
Rumah >pangkalan data >Redis >Apakah prinsip asas redis
Apakah prinsip asas redis

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-26 22:21:131267semak imbas
Objek teras Redis
Dalam Redis terdapat "objek teras" dipanggil redisObject, yang digunakan untuk mewakili semua kunci dan nilai Struktur redisObject digunakan untuk mewakili String, Five jenis data: Hash, Senarai, Set dan ZSet.
Kod sumber redisObject adalah dalam redis.h, ditulis dalam bahasa c Jika anda berminat, anda boleh menyemaknya sendiri Saya telah melukis gambar tentang redisObject di sini, yang menunjukkan bahawa struktur redisObject adalah seperti berikut:
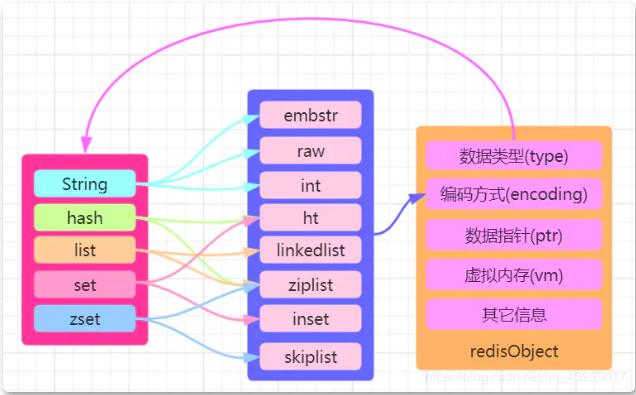
Dalam redisObject "jenis menunjukkan jenis data yang dimiliki dan pengekodan menunjukkan cara data disimpan" , iaitu , data jenis data ini dilaksanakan oleh struktur lapisan asas. Oleh itu, artikel ini secara khusus memperkenalkan bahagian pengekodan yang sepadan.
Jadi apakah maksud jenis storan dalam pengekodan? Maksud jenis data tertentu adalah seperti yang ditunjukkan dalam rajah di bawah:
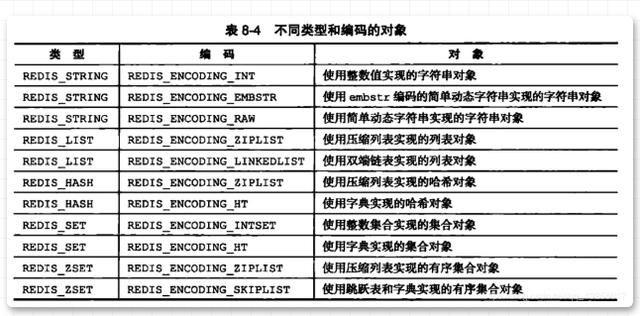
Anda mungkin masih berasa keliru selepas membaca gambar ini. Jangan panik, kami akan memberikan pengenalan terperinci kepada lima struktur data Gambar ini hanya membenarkan anda mencari jenis storan yang sepadan dengan setiap struktur data, dan mungkin mempunyai kesan dalam fikiran anda.
Untuk memberikan contoh mudah, anda tetapkan kunci rentetan 234 dalam Redis, dan kemudian semak jenis storan rentetan ini dan anda akan melihat bahawa jenis bukan integer menggunakan jenis storan embstr. Operasi khusus ditunjukkan dalam rajah di bawah:
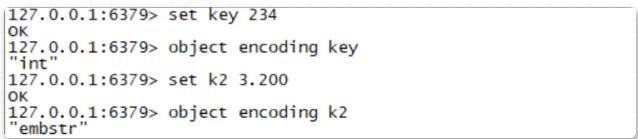
Jenis rentetan
String ialah jenis data paling asas bagi Redis menggunakan bahasa c yang dibangunkan. Walau bagaimanapun, terdapat perbezaan yang jelas antara jenis rentetan dalam Redis dan jenis rentetan dalam bahasa C.
Terdapat tiga cara untuk menyimpan struktur data jenis String: int, mentah dan embstr.. Jadi apakah perbezaan antara ketiga-tiga kaedah penyimpanan ini?
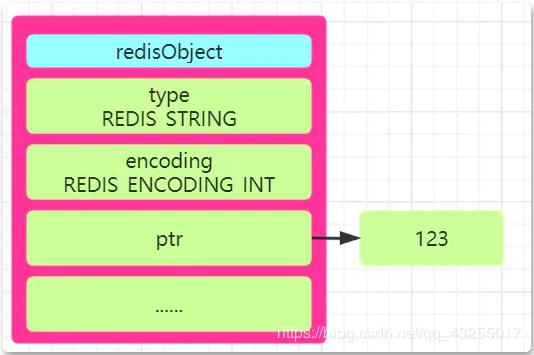
int
Redis menetapkan bahawa jika nilai yang disimpan ialah "nilai integer", seperti set nombor 123, ia akan disimpan menggunakan kaedah storan int akan disimpan dalam "ptr attribute" redisObject.
SDS
Jika "rentetan yang disimpan ialah nilai rentetan dan panjangnya lebih besar daripada 32 bait" akan digunakan Simpan dalam mod SDS (rentetan dinamik ringkas) dan pengekodan ditetapkan kepada mentah jika "Panjang rentetan kurang daripada atau sama dengan 32 bait" akan menukar pengekodan kepada embstr untuk menyimpan rentetan.
SDS dipanggil "Rentetan Dinamik Mudah" Terdapat tiga atribut yang ditakrifkan dalam SDS dalam kod sumber Redis: int len, int free, char buf[].
len menyimpan panjang rentetan, percuma mewakili bilangan bait yang tidak digunakan dalam tatasusunan buf dan tatasusunan buf menyimpan setiap elemen aksara rentetan.
Jadi apabila anda menyimpan rentetan Hello dalam Redsi, mengikut penerangan kod sumber Redis, anda boleh melukis gambar rajah struktur redisObject dalam bentuk SDS seperti yang ditunjukkan di bawah:
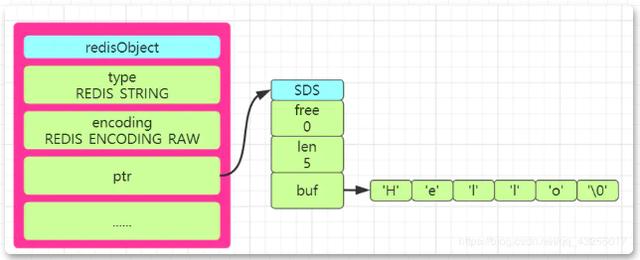
Perbandingan antara rentetan bahasa SDS dan c
Redis pasti mempunyai kelebihan tersendiri dalam menggunakan SDS sebagai jenis storan rentetan Berbanding dengan rentetan bahasa SDS dan c, SDS mempunyai pemahaman yang lebih baik rentetan bahasa c. Rentetan mempunyai reka bentuk dan pengoptimuman sendiri Kelebihan khusus adalah seperti berikut:
(1) Rentetan dalam bahasa C tidak merekodkan panjangnya sendiri, jadi "dapatkan rentetan setiap. masa Panjang akan dilalui, dan kerumitan masa ialah O(n)". Untuk mendapatkan rentetan dalam Redis, anda hanya perlu membaca nilai len dan kerumitan masa menjadi O(1).
(2) "Bahasa C" menggabungkan dua rentetan Jika ruang memori dengan panjang yang mencukupi tidak diperuntukkan, "limpahan penimbal akan berlaku" ; "SDS" terlebih dahulu akan menentukan sama ada ruang memenuhi keperluan berdasarkan atribut len Jika ruang tidak mencukupi, ruang yang sepadan akan dikembangkan, jadi "limpahan penimbal tidak akan berlaku" .
(3) SDS juga menyediakan dua strategi:"Pra-peruntukan Angkasa" dan "Pelepasan Ruang Malas" . Apabila memperuntukkan ruang untuk rentetan, peruntukkan lebih banyak ruang daripada ruang sebenar, yang boleh "mengurangkan bilangan pengagihan semula memori yang disebabkan oleh pelaksanaan berterusan pertumbuhan rentetan" .
Apabila rentetan dipendekkan, SDS tidak akan segera menuntut semula ruang yang tidak digunakan Sebaliknya, ia akan merekodkan ruang yang tidak digunakan melalui atribut bebas dan melepaskannya apabila ia digunakan kemudian. Prinsip pra-peruntukan ruang khusus ialah:"Apabila len panjang rentetan yang diubah suai kurang daripada 1MB, ruang dengan panjang yang sama dengan len akan diperuntukkan terlebih dahulu, iaitu, len=free; jika len lebih besar daripada 1MB, Ruang yang diperuntukkan secara percuma ialah 1MB".
(4) SDS adalah selamat binari Selain menyimpan rentetan, ia juga boleh menyimpan fail binari (seperti data binari gambar, audio, video, dsb.), manakala rentetan dalam bahasa C menggunakan rentetan kosong sebagai Terminator. Sesetengah imej mengandungi terminator dan oleh itu tidak selamat binari.
Untuk memudahkan pemahaman, kami membuat jadual membandingkan rentetan bahasa C dan SDS, seperti yang ditunjukkan di bawah:
Rentetan bahasa C SDS Kerumitan masa untuk mendapatkan panjang ialah O(n) Kerumitan masa untuk mendapatkan panjang ialah O(1) Ia tidak selamat binari, ia selamat binari dan hanya boleh menyimpan data binari rentetan tumbuh n kali, rentetan itu pasti akan berkembang Membawa n kali peruntukan memori n kali meningkatkan bilangan peruntukan memori rentetan , tetapi untuk menguasai teori tulen, teori masih perlu digunakan dalam amalan digunakan untuk menyimpan gambar Sekarang kita akan menggunakan penyimpanan gambar sebagai kajian kes.
(1) Pertama, anda perlu mengekod imej yang dimuat naik Berikut ialah kelas alat untuk memproses imej ke dalam pengekodan Base64 adalah seperti berikut:
/** * 将图片内容处理成Base64编码格式 * @param file * @return */ public static String encodeImg(MultipartFile file) { byte[] imgBytes = null; try { imgBytes = file.getBytes(); } catch (IOException e) { e.printStackTrace(); } BASE64Encoder encoder = new BASE64Encoder(); return imgBytes==null?null:encoder.encode(imgBytes );
Salin kod
(2) Langkah kedua ialah menyimpan format rentetan imej yang diproses ke dalam Redis Kod yang dilaksanakan adalah seperti berikut:
/** * Redis存储图片 * @param file * @return */ public void uploadImageServiceImpl(MultipartFile image) { String imgId = UUID.randomUUID().toString(); String imgStr= ImageUtils.encodeImg(image); redisUtils.set(imgId , imgStr); // 后续操作可以把imgId存进数据库对应的字段,如果需要从redis中取出,只要获取到这个字段后从redis中取出即可。 }Ini adalah cara untuk merealisasikan storan binari imej. . , sudah tentu, aplikasi struktur data jenis String juga mempunyai pengiraan konvensional: "Hitung bilangan Weibo, kira bilangan peminat" dsb.
Jenis cincangTerdapat dua cara untuk melaksanakan objek Cincang: senarai zip dan jadual cincang Kaedah storan jadual cincang adalah daripada jenis String, dan nilainya juga disimpan dalam bentuk nilai kunci.
Lapisan bawah jenis kamus dilaksanakan oleh jadual hash Memahami prinsip pelaksanaan asas kamus bermakna memahami prinsip pelaksanaan jadual hash boleh dibandingkan dengan prinsip asas HashMap.
Kamus
Kedua-dua mereka akan mengira subskrip tatasusunan melalui kunci apabila ia ditambah, kaedah pengiraan adalah berbeza HashMap, manakala jadual hash mengira Selepas cincang nilai, subskrip tatasusunan mesti diperoleh semula melalui atribut sizemask dan nilai cincang.
Kami tahu bahawa masalah terbesar dengan jadual cincang adalah konflik cincang Untuk menyelesaikan konflik cincang, jika kunci berbeza dalam jadual cincang memperoleh indeks yang sama melalui pengiraan, senarai terpaut sehala akan dibentuk (<.> "Kaedah Alamat Rantaian"
), seperti ditunjukkan dalam rajah di bawah:rehash
Dalam pelaksanaan asas kamus, objek nilai disimpan sebagai objek setiap dictEntry, Apabila pasangan nilai kunci yang disimpan dalam jadual cincang terus meningkat atau menurun, jadual cincang perlu dikembangkan atau dikurangkan. 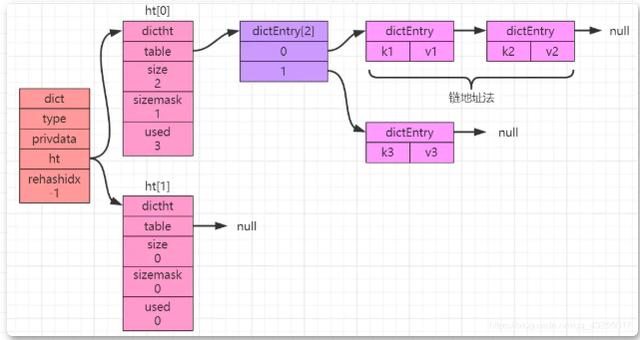
"susunan jadual cincang, cincang Saiz jadual , digunakan untuk mengira nilai indeks, sentiasa sama dengan saiz-1, bilangan nod yang sudah ada dalam jadual cincang"
. ht[0] digunakan untuk menyimpan data pada mulanya Apabila pengembangan atau pengecutan diperlukan, saiz ht[0] menentukan saiz ht[1] Semua data dalam ht[0] Kunci-. pasangan nilai akan dirombak semula menjadi ht[1].Operasi pengembangan: Saiz ht[1] yang diperluaskan ialah kuasa integer pertama 2 yang lebih besar daripada dua kali nilai ht[0] semasa. Operasi pengecutan: Kuasa integer pertama ht[0 ].digunakan Kuasa integer 2 lebih besar daripada atau sama dengan 2.
Apabila semua pasangan nilai kunci pada ht[0] dicincang semula kepada ht[1], semua nilai subskrip tatasusunan akan dikira semula dan ht[0] akan dikeluarkan apabila pemindahan data selesai. , kemudian tukar ht[1] kepada ht[0], dan cipta ht[1] baharu untuk bersedia untuk pengembangan dan pengecutan seterusnya. Rehash progresifJika jumlah data sangat besar semasa proses rehash, Redis tidak akan berjaya menyelaraskan semua data sekaligus, yang akan menyebabkan perkhidmatan luaran Redis terhenti mengendalikan situasi ini secara dalaman, Redis Dalam kes ini,"rehash progresif"
digunakan. Redis membahagikan semua operasi rehash kepada beberapa langkah sehingga semua operasi rehash selesai Pelaksanaan khusus berkaitan dengan atribut rehashindex dalam objek"Jika rehashindex dinyatakan sebagai -1, ini bermakna ada tiada operasi rehash".
Apabila operasi rehash bermula, nilai akan ditukar kepada 0. Semasa proses rehash progresif"Kemas kini, pemadaman dan pertanyaan akan dilakukan dalam kedua-dua ht[0] dan ht[1]" , sebagai contoh, untuk mengemas kini nilai, mula-mula kemas kini ht[0] dan kemudian kemas kini ht[1].
Operasi baharu ditambah terus pada jadual ht[1] dan ht[0] tidak akan menambah sebarang data Ini memastikan"ht[0] hanya berkurangan tetapi tidak meningkat, sehingga Pada saat terakhir, ia menjadi meja kosong", dan operasi rehash selesai.
Di atas ialah prinsip pelaksanaan jadual hash yang mendasari kamus Selepas bercakap tentang prinsip pelaksanaan jadual hash, mari kita lihat dua kaedah penyimpanan struktur data Hash"ziplist (senarai termampat. )"
ziplist
压缩列表(ziplist)是一组连续内存块组成的顺序的数据结构,压缩列表能够节省空间,压缩列表中使用多个节点来存储数据。
压缩列表是列表键和哈希键底层实现的原理之一,「压缩列表并不是以某种压缩算法进行压缩存储数据,而是它表示一组连续的内存空间的使用,节省空间」,压缩列表的内存结构图如下:

压缩列表中每一个节点表示的含义如下所示:
zlbytes:4个字节的大小,记录压缩列表占用内存的字节数。
zltail:4个字节大小,记录表尾节点距离起始地址的偏移量,用于快速定位到尾节点的地址。
zllen:2个字节的大小,记录压缩列表中的节点数。
entry:表示列表中的每一个节点。
zlend:表示压缩列表的特殊结束符号'0xFF'。
再压缩列表中每一个entry节点又有三部分组成,包括previous_entry_ength、encoding、content。
previous_entry_ength表示前一个节点entry的长度,可用于计算前一个节点的其实地址,因为他们的地址是连续的。
encoding:这里保存的是content的内容类型和长度。
content:content保存的是每一个节点的内容。

说到这里相信大家已经都hash这种数据结构已经非常了解,若是第一次接触Redis五种基本数据结构的底层实现的话,建议多看几遍,下面来说一说hash的应用场景。
应用场景
哈希表相对于String类型存储信息更加直观,擦欧总更加方便,经常会用来做用户数据的管理,存储用户的信息。
hash也可以用作高并发场景下使用Redis生成唯一的id。下面我们就以这两种场景用作案例编码实现。
存储用户数据
第一个场景比如我们要储存用户信息,一般使用用户的ID作为key值,保持唯一性,用户的其他信息(地址、年龄、生日、电话号码等)作为value值存储。
若是传统的实现就是将用户的信息封装成为一个对象,通过序列化存储数据,当需要获取用户信息的时候,就会通过反序列化得到用户信息。
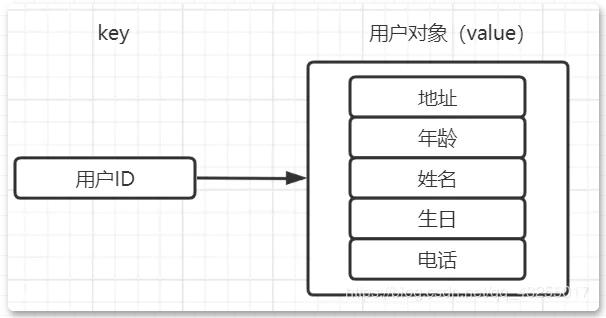
但是这样必然会造成序列化和反序列化的性能的开销,并且若是只修改其中的一个属性值,就需要把整个对象序列化出来,操作的动作太大,造成不必要的性能开销。
若是使用Redis的hash来存储用户数据,就会将原来的value值又看成了一个k v形式的存储容器,这样就不会带来序列化的性能开销的问题。
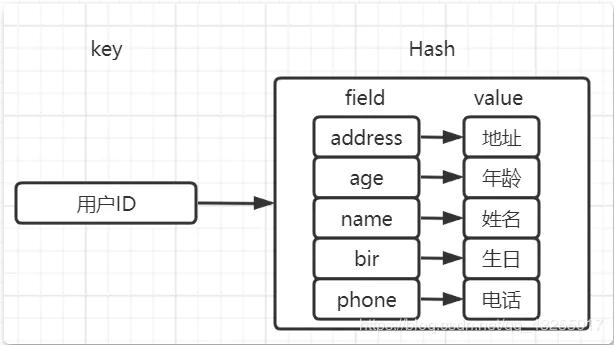
分布式生成唯一ID
第二个场景就是生成分布式的唯一ID,这个场景下就是把redis封装成了一个工具类进行实现,实现的代码如下:
// offset表示的是id的递增梯度值 public Long getId(String key,String hashKey,Long offset) throws BusinessException{ try { if (null == offset) { offset=1L; } // 生成唯一id return redisUtil.increment(key, hashKey, offset); } catch (Exception e) { //若是出现异常就是用uuid来生成唯一的id值 int randNo=UUID.randomUUID().toString().hashCode(); if (randNo <h3>List类型</h3><p>在 Redis 3.2 之前的版本,Redis 的列表是通过结合使用 ziplist 和 linkedlist 实现的。在3.2之后的版本就是引入了quicklist。</p><p>ziplist压缩列表上面已经讲过了,我们来看看linkedlist和quicklist的结构是怎么样的。</p><p>Linkedlist有双向链接,和普通的链表一样,都由指向前后节点的指针构成。时间复杂度为O(1)的操作包括插入、修改和更新,而时间复杂度为O(n)的操作是查询。</p><p>linkedlist和quicklist的底层实现是采用链表进行实现,在c语言中并没有内置的链表这种数据结构,Redis实现了自己的链表结构。</p><p><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/887/227/168511087742882.jpg" class="lazy" alt="Apakah prinsip asas redis"></p><p>Redis中链表的特性:</p><ol class=" list-paddingleft-2">
<li><p>每一个节点都有指向前一个节点和后一个节点的指针。</p></li>
<li><p>头节点和尾节点的prev和next指针指向为null,所以链表是无环的。</p></li>
<li><p>链表有自己长度的信息,获取长度的时间复杂度为O(1)。</p></li>
</ol><p>Redis中List的实现比较简单,下面我们就来看看它的应用场景。</p><h3>应用场景</h3><p>Redis中的列表可以实现<strong>「阻塞队列」</strong>,结合lpush和brpop命令就可以实现。生产者使用lupsh从列表的左侧插入元素,消费者使用brpop命令从队列的右侧获取元素进行消费。</p><p>(1)首先配置redis的配置,为了方便我就直接放在application.yml配置文件中,实际中可以把redis的配置文件放在一个redis.properties文件单独放置,具体配置如下:</p><pre class="brush:php;toolbar:false">spring redis: host: 127.0.0.1 port: 6379 password: user timeout: 0 database: 2 pool: max-active: 100 max-idle: 10 min-idle: 0 max-wait: 100000(2)第二步创建redis的配置类,叫做RedisConfig,并标注上@Configuration注解,表明他是一个配置类。
@Configuration public class RedisConfiguration { @Value("{spring.redis.port}") private int port; @Value("{spring.redis.pool.max-active}") private int maxActive; @Value("{spring.redis.pool.min-idle}") private int minIdle; @Value("{spring.redis.database}") private int database; @Value("${spring.redis.timeout}") private int timeout; @Bean public JedisPoolConfig getRedisConfiguration(){ JedisPoolConfig jedisPoolConfig= new JedisPoolConfig(); jedisPoolConfig.setMaxTotal(maxActive); jedisPoolConfig.setMaxIdle(maxIdle); jedisPoolConfig.setMinIdle(minIdle); jedisPoolConfig.setMaxWaitMillis(maxWait); return jedisPoolConfig; } @Bean public JedisConnectionFactory getConnectionFactory() { JedisConnectionFactory factory = new JedisConnectionFactory(); factory.setHostName(host); factory.setPort(port); factory.setPassword(password); factory.setDatabase(database); JedisPoolConfig jedisPoolConfig= getRedisConfiguration(); factory.setPoolConfig(jedisPoolConfig); return factory; } @Bean public RedisTemplate, ?> getRedisTemplate() { JedisConnectionFactory factory = getConnectionFactory(); RedisTemplate, ?> redisTemplate = new StringRedisTemplate(factory); return redisTemplate; } }(3)第三步就是创建Redis的工具类RedisUtil,自从学了面向对象后,就喜欢把一些通用的东西拆成工具类,好像一个一个零件,需要的时候,就把它组装起来。
@Component public class RedisUtil { @Autowired private RedisTemplate<string> redisTemplate; /** 存消息到消息队列中 @param key 键 @param value 值 @return */ public boolean lPushMessage(String key, Object value) { try { redisTemplate.opsForList().leftPush(key, value); return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** 从消息队列中弹出消息 - <rpop> @param key 键 @return */ public Object rPopMessage(String key) { try { return redisTemplate.opsForList().rightPop(key); } catch (Exception e) { e.printStackTrace(); return null; } } /** 查看消息 @param key 键 @param start 开始 @param end 结束 0 到 -1代表所有值 复制代码@return */ public List<object> getMessage(String key, long start, long end) { try { return redisTemplate.opsForList().range(key, start, end); } catch (Exception e) { e.printStackTrace(); return null; } }</object></rpop></string>这样就完成了Redis消息队列工具类的创建,在后面的代码中就可以直接使用。
Set集合
Redis中列表和集合都可以用来存储字符串,但是「Set是不可重复的集合,而List列表可以存储相同的字符串」,Set集合是无序的这个和后面讲的ZSet有序集合相对。
Set的底层实现是「ht和intset」,ht(哈希表)前面已经详细了解过,下面我们来看看inset类型的存储结构。
inset也叫做整数集合,用于保存整数值的数据结构类型,它可以保存int16_t、int32_t 或者int64_t 的整数值。
在整数集合中,有三个属性值encoding、length、contents[],分别表示编码方式、整数集合的长度、以及元素内容,length就是记录contents里面的大小。
在整数集合新增元素的时候,若是超出了原集合的长度大小,就会对集合进行升级,具体的升级过程如下:
首先扩展底层数组的大小,并且数组的类型为新元素的类型。
然后将原来的数组中的元素转为新元素的类型,并放到扩展后数组对应的位置。
整数集合升级后就不会再降级,编码会一直保持升级后的状态。
应用场景
Set集合的应用场景可以用来「去重、抽奖、共同好友、二度好友」等业务类型。接下来模拟一个添加好友的案例实现:
@RequestMapping(value = "/addFriend", method = RequestMethod.POST) public Long addFriend(User user, String friend) { String currentKey = null; // 判断是否是当前用户的好友 if (AppContext.getCurrentUser().getId().equals(user.getId)) { currentKey = user.getId.toString(); } //若是返回0则表示不是该用户好友 return currentKey==null?0l:setOperations.add(currentKey, friend); }
假如两个用户A和B都是用上上面的这个接口添加了很多的自己的好友,那么有一个需求就是要实现获取A和B的共同好友,那么可以进行如下操作:
public Set intersectFriend(User userA, User userB) { return setOperations.intersect(userA.getId.toString(), userB.getId.toString()); }举一反三,还可以实现A用户自己的好友,或者B用户自己的好友等,都可以进行实现。
ZSet集合
ZSet是有序集合,从上面的图中可以看到ZSet的底层实现是ziplist和skiplist实现的,ziplist上面已经详细讲过,这里来讲解skiplist的结构实现。
skiplist也叫做「跳跃表」,跳跃表是一种有序的数据结构,它通过每一个节点维持多个指向其它节点的指针,从而达到快速访问的目的。
skiplist由如下几个特点:
有很多层组成,由上到下节点数逐渐密集,最上层的节点最稀疏,跨度也最大。
每一层都是一个有序链表,只扫包含两个节点,头节点和尾节点。
每一层的每一个每一个节点都含有指向同一层下一个节点和下一层同一个位置节点的指针。
如果一个节点在某一层出现,那么该以下的所有链表同一个位置都会出现该节点。
具体实现的结构图如下所示:
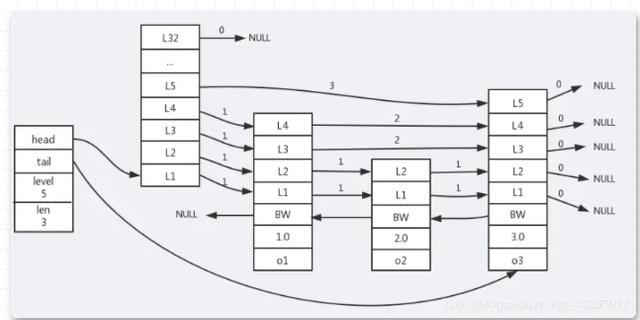
跳跃表的结构中包含指向头节点和尾节点的指针head和tail,能够快速进行定位。当在跳跃表中从尾向前遍历时,层数用 level 表示,跳跃表长度用 len 表示,同时也会使用后退指针 BW。
BW下面还有两个值分别表示分值(score)和成员对象(各个节点保存的成员对象)。
跳跃表的实现中,除了最底层的一层保存的是原始链表的完整数据,上层的节点数会越来越少,并且跨度会越来越大。
跳跃表的上面层就相当于索引层,都是为了找到最后的数据而服务的,数据量越大,条表所体现的查询的效率就越高,和平衡树的查询效率相差无几。
应用场景
因为ZSet是有序的集合,因此ZSet在实现排序类型的业务是比较常见的,比如在首页推荐10个最热门的帖子,也就是阅读量由高到低,排行榜的实现等业务。
下面就选用获取排行榜前前10名的选手作为案例实现,实现的代码如下所示:
@Autowired private RedisTemplate redisTemplate; /** * 获取前10排名 * @return */ public static List<levelvo> getZset(String key, long baseNum, LevelService levelService){ ZSetOperations<serializable> operations = redisTemplate.opsForZSet(); // 根据score分数值获取前10名的数据 Set<zsetoperations.typedtuple>> set = operations.reverseRangeWithScores(key,0,9); List<levelvo> list= new ArrayList<levelvo>(); int i=1; for (ZSetOperations.TypedTuple<object> o:set){ int uid = (int) o.getValue(); LevelCache levelCache = levelService.getLevelCache(uid); LevelVO levelVO = levelCache.getLevelVO(); long score = (o.getScore().longValue() - baseNum + levelVO .getCtime())/CommonUtil.multiplier; levelVO .setScore(score); levelVO .setRank(i); list.add( levelVO ); i++; } return list; }</object></levelvo></levelvo></zsetoperations.typedtuple></serializable></levelvo>以上的代码实现大致逻辑就是根据score分数值获取前10名的数据,然后封装成lawyerVO对象的列表进行返回。
Atas ialah kandungan terperinci Apakah prinsip asas redis. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!