
Rumah > Artikel > pangkalan data > Apakah kekangan MySQL?
Apakah kekangan MySQL?

- 王林ke hadapan
- 2023-05-26 19:14:101551semak imbas
1. Gambaran Keseluruhan
Konsep: Kekangan ialah peraturan yang bertindak pada medan dalam jadual untuk mengehadkan apa yang disimpan dalam jadual data.
Tujuan: Memastikan ketepatan, kesahihan dan integriti data dalam pangkalan data.
Kategori:

Nota: kekangan digunakan pada medan dalam jadual dan boleh dibuat Jadual/Tambah kekangan semasa mengubah suai jadual.
2. Demonstrasi Kekangan
Di atas kita telah memperkenalkan kekangan biasa dalam pangkalan data dan kata kunci yang terlibat dalam kekangan Jadi bagaimana kita menentukan kekangan ini apabila membuat dan mengubah suai jadual? kami akan menunjukkannya melalui kes.
Keperluan kes: Lengkapkan penciptaan struktur meja mengikut keperluan. Keperluan adalah seperti berikut:
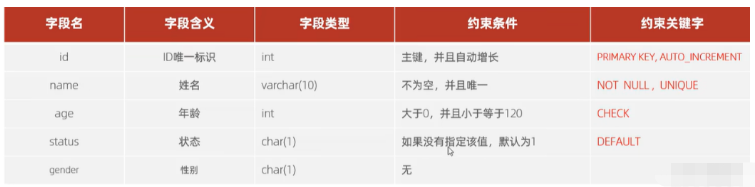
Pernyataan penciptaan jadual yang sepadan ialah:
CREATE TABLE tb_user ( id INT AUTO_INCREMENT PRIMARY KEY COMMENT 'ID唯一标识', NAME VARCHAR ( 10 ) NOT NULL UNIQUE COMMENT '姓名', age INT CHECK ( age > 0 && age <= 120 ) COMMENT '年龄', STATUS CHAR ( 1 ) DEFAULT '1' COMMENT '状态', gender CHAR ( 1 ) COMMENT '性别' );
Apabila menambah kekangan pada medan, kami hanya Tambah sahaja kata kunci kekangan selepas medan, dan anda perlu memberi perhatian kepada sintaksnya.
Kami melaksanakan SQL di atas untuk mencipta struktur jadual, dan kemudian mengujinya melalui set data untuk mengesahkan sama ada kekangan boleh berkuat kuasa.
(1) Mula-mula, tiga keping data telah ditambahkan
insert into tb_user(name,age,status,gender) values ('Tom1',19,'1','男'),('Tom2',25,'0','男'); insert into tb_user(name,age,status,gender) values ('Tom3',19,'1','男');
Ia mengambil masa 21 saat untuk menambah tiga keping data.
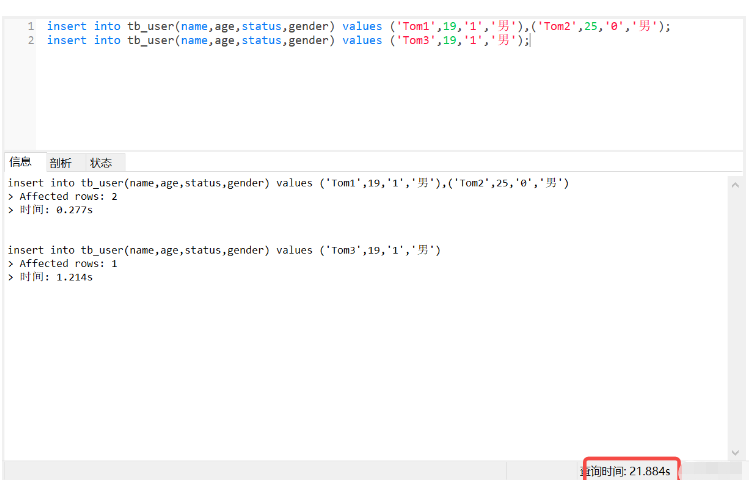
Pada asalnya, saya berpendapat bahawa penambahan kekangan ini menyebabkan kelembapan data baharu, sebenarnya tidak, kerana ini adalah pelayan Linux Alibaba, dan kemudian saya menggunakan klien dalam Linux Ia hanya mengambil masa 0.01 saat untuk menyambung ke mysql dan melaksanakan penambahan baharu, yang menunjukkan bahawa inilah masa yang diperlukan untuk navicat menyambung ke hos jauh.
Walaupun kekangan ini ditambah, data baharu akan ditambah perlahan-lahan Ini hanya boleh diperhatikan dalam kelompok dan pada dasarnya tidak dapat dilihat oleh sekeping data.
(2) Nama ujian NOT NULL
insert into tb_user(name,age,status,gender) values (null,19,'1','男');

(3) Nama ujian UNIK (sahaja)
Data yang ditambahkan di atas sudah mengandungi Tom3 Jika anda menambahkannya lagi, ralat akan dilaporkan secara langsung.
insert into tb_user(name,age,status,gender) values ('Tom3',19,'1','男');

Walaupun ralat dilaporkan, kami akan menemui fenomena apabila kami menambah sekeping data lagi pada masa ini.
insert into tb_user(name,age,status,gender) values ('Tom4',80,'1','男');
Ia adalah ID yang meningkat sendiri, tetapi tidak ada 4. Sebabnya, UNIQUE sedia untuk dimasukkan ke dalam pangkalan data selepas memohon ID meningkat secara automatik akan menyemak terlebih dahulu jika terdapat satu dalam pangkalan data Terdapat nilai dengan nama yang sama. Jika ada, penambahan baru gagal, ID kenaikan automatik telah digunakan.
Sebaliknya, apabila kami hanya menguji nama null, ia tidak memohon id, kerana ia telah menilai ia kosong pada awalnya dan belum sampai ke langkah memohon id .
Tentukan sama ada kosong -> Mohon untuk id kenaikan automatik -> Tentukan sama ada terdapat nilai sedia ada
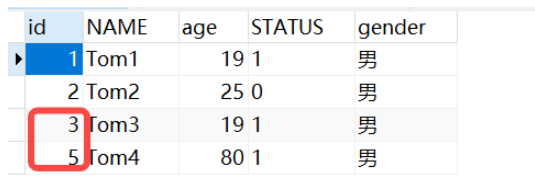
Ringkasan : Apabila baharu Apabila nama yang ditambahkan tidak kosong, tetapi sama dengan data sedia ada sebelumnya, penambahan baharu akan gagal pada masa ini, tetapi ia akan digunakan untuk id kunci utama.
(4) SEMAK Ujian
Apa yang kami tetapkan ialah umur mesti lebih daripada 0 dan kurang daripada atau sama dengan 120, jika tidak, simpanan akan gagal!
age int check (age > 0 && age <= 120) COMMENT '年龄' ,
insert into tb_user(name,age,status,gender) values ('Tom5',-1,'1','男'); insert into tb_user(name,age,status,gender) values ('Tom5',121,'1','男');
(5) Uji DEFAULT ‘1’ Nilai lalai
STATUS CHAR ( 1 ) DEFAULT '1' COMMENT '状态',
insert into tb_user(name,age,gender) values ('Tom5',120,'男');
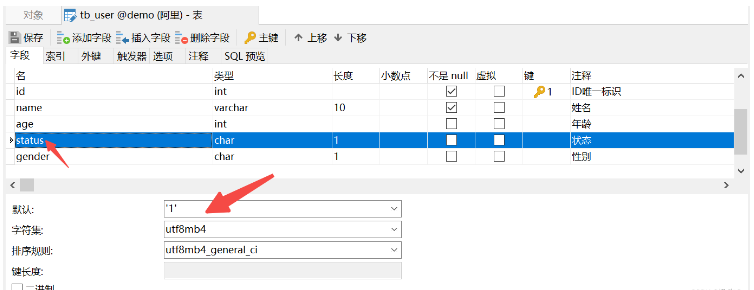
(6) Di atas, kami melengkapkan kekangan dengan menulis pernyataan SQL yang dinyatakan, apakah jika kami pelanggan Navicat?
Tambahan auto kunci utama
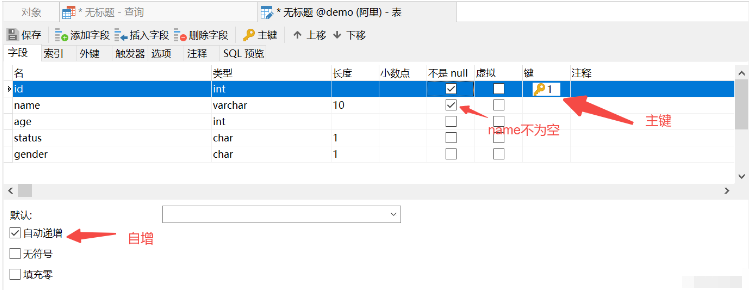
nama kekangan unik

status lalai kepada 1
3. Kekangan kunci asing
1. Apakah kekangan kunci asing? digunakan untuk Sambungan diwujudkan antara data dalam dua jadual untuk memastikan ketekalan dan integriti data.
Mari kita lihat contoh:
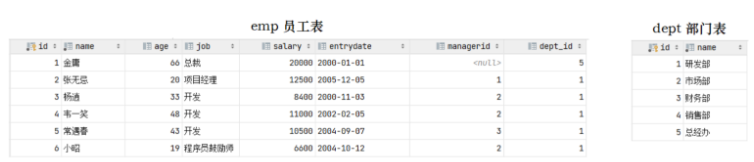
Jadual emp di sebelah kiri ialah jadual pekerja, yang menyimpan maklumat asas tentang pekerja , termasuk ID pekerja, nama, umur, jawatan, gaji, tarikh menyertai, ID penyelia atasan dan ID jabatan yang disimpan dalam maklumat pekerja ialah ID dept_id jabatan, dan ID jabatan ialah id kunci utama jadual jabatan yang berkaitan. dept. Dept_id bagi jadual emp ialah kunci asing, dan ia dikaitkan dengan kunci utama jadual lain.
2、 不使用外键有什么影响
通过上面的示例,我们分别来演示 添加外键 和不添加外键的区别,首先来看不添加 外键 对数据有什么影响:
准备数据:
CREATE TABLE dept ( id INT auto_increment COMMENT 'ID' PRIMARY KEY, NAME VARCHAR ( 50 ) NOT NULL COMMENT '部门名称' ) COMMENT '部门表'; INSERT INTO dept (id, name) VALUES (1, '研发部'), (2, '市场部'),(3, '财务部'), (4, '销售部'), (5, '总经办'); CREATE TABLE emp ( id INT auto_increment COMMENT 'ID' PRIMARY KEY, NAME VARCHAR ( 50 ) NOT NULL COMMENT '姓名', age INT COMMENT '年龄', job VARCHAR ( 20 ) COMMENT '职位', salary INT COMMENT '薪资', entrydate date COMMENT '入职时间', managerid INT COMMENT '直属领导ID', dept_id INT COMMENT '部门ID' ) COMMENT '员工表'; INSERT INTO emp (id, name, age, job,salary, entrydate, managerid, dept_id) VALUES (1, '金庸', 66, '总裁',20000, '2000-01-01', null,5), (2, '张无忌', 20, '项目经理',12500, '2005-12-05', 1,1), (3, '杨逍', 33, '开发', 8400,'2000-11-03', 2,1), (4, '韦一笑', 48, '开 发',11000, '2002-02-05', 2,1), (5, '常遇春', 43, '开发',10500, '2004-09-07', 3,1), (6, '小昭', 19, '程 序员鼓励师',6600, '2004-10-12', 2,1);
接下来,我们可以做一个测试,删除id为1的部门信息。
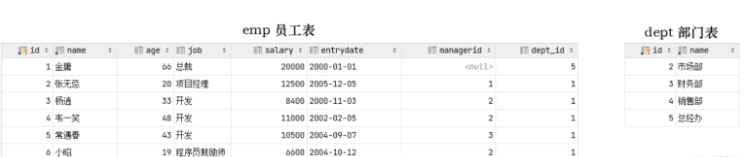
结果,我们看到删除成功,而删除成功之后,部门表不存在id为1的部门,而在emp表中还有很多的员工,关联的为id为1的部门,此时就出现了数据的不完整性。 而要想解决这个问题就得通过数据库的外键约束。
正常开发当中有时候会通过业务代码来控制数据的不完整性,例如删除部门的时候会先根据部门id去查看一下有没有对应的员工表,如果有则删除失败,没有则删除成功。
3、 添加外键的语法
可以在创建表的时候直接添加外键,也可以对现已存在的表添加外键。
(1)方式一
CREATE TABLE 表名( 字段名 数据类型, ... [CONSTRAINT] [外键名称] FOREIGN KEY (外键字段名) REFERENCES 主表 (主表列名) );
使用示例:
CREATE TABLE emp ( id INT auto_increment COMMENT 'ID' PRIMARY KEY, NAME VARCHAR ( 50 ) NOT NULL COMMENT '姓名', age INT COMMENT '年龄', job VARCHAR ( 20 ) COMMENT '职位', salary INT COMMENT '薪资', entrydate date COMMENT '入职时间', managerid INT COMMENT '直属领导ID', dept_id INT COMMENT '部门ID', CONSTRAINT fk_emp_dept_id FOREIGN KEY (dept_id) REFERENCES dept (id) ) COMMENT '员工表';
也可以省略掉CONSTRAINT fk_emp_dept_id 这样mysql就会自动给我们起外键名称。
方式二:对现存在的表添加外键
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名) REFERENCES 主表 (主表列名) ;
使用示例:
alter table emp add constraint fk_emp_dept_id FOREIGN KEY (dept_id) REFERENCES dept(id);
方式三:Navicat添加外键

删除外键:
ALTER TABLE 表名 DROP FOREIGN KEY 外键名称;
使用示例:
alter table emp drop foreign key fk_emp_dept_id;
4、 删除/更新行为
我们将在父表数据删除时发生的限制行为称为删除/更新行为,此行为是在添加外键之后发生的。具体的删除/更新行为有以下几种:

默认的MySQL 8.0.27版本中,RESTRICT是用于删除和更新行的行为!但是,不同的版本可能会有不同的行为

具体语法为:
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段) REFERENCES 主表名 (主表字段名) ON UPDATE CASCADE ON DELETE CASCADE;
就是比原先添加外键后面多了这些ON UPDATE CASCADE ON DELETE CASCADE,代表的是更新时采用CASCADE ,删除时也采用CASCADE
5、 演示删除/更新行为
(1)演示RESTRICT
在对父表中的记录进行删除或更新操作时,需要先检查该记录是否存在关联的外键,如果存在,则不允许执行删除或更新操作。 (与 NO ACTION 一致) 默认行为
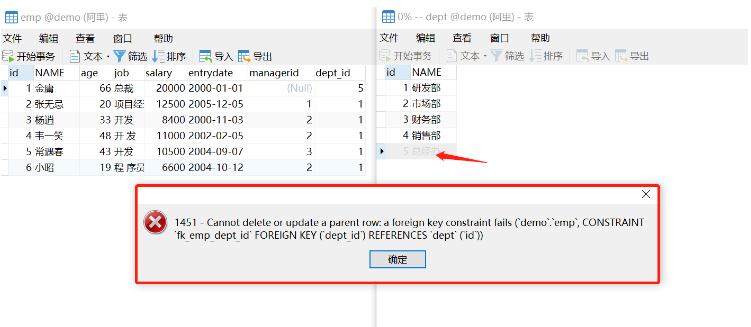
首先要添加外键,默认是RESTRICT行为!
alter table emp add constraint fk_emp_dept_id FOREIGN KEY (dept_id) REFERENCES dept(id);
删除父表中id为5的记录时,会因为emp表中的dept_id存在5而报错。假如要更新id也同样会报错的!
(2)演示CASCADE
当在父表中删除/更新对应记录时,首先检查该记录是否有对应外键,如果有,则
也删除/更新外键在子表中的记录。
删除外键的语法:
ALTER TABLE 表名 DROP FOREIGN KEY 外键约束名;
删除外键的示例:
alter table emp drop foreign key fk_emp_dept_id;
指定外键的删除更新行为为cascade
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id) on update cascade on delete cascade ;
修改父表id为1的记录,将id修改为6

我们发现,原来在子表中dept_id值为1的记录,现在也变为6了,这就是cascade级联的效果。
在一般的业务系统中,不会修改一张表的主键值。
删除父表id为6的记录

我们发现,父表的数据删除成功了,但是子表中关联的记录也被级联删除了。
(3)演示SET NULL
当在父表中删除对应记录时,首先检查该记录是否有对应外键,如果有则设置子表中该外键值为null(这就要求该外键允许取null)。
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id) on update set null on delete set null ;
在执行测试之前,我们需要先移除已创建的外键 fk_emp_dept_id。然后再通过数据脚本,将emp、dept表的数据恢复了。
接下来,我们删除id为1的数据,看看会发生什么样的现象。
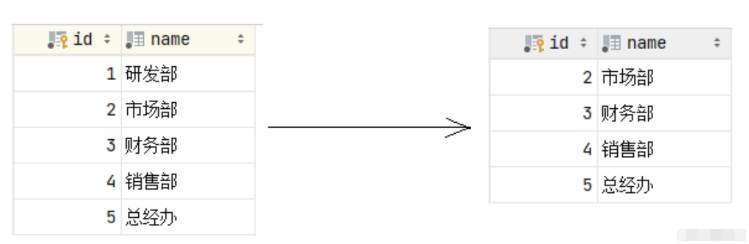
我们发现父表的记录是可以正常的删除的,父表的数据删除之后,再打开子表 emp,我们发现子表emp的dept_id字段,原来dept_id为1的数据,现在都被置为NULL了。
Ini ialah kesan daripada tingkah laku padam/kemas kini SET NULL.
4. Adakah lebih baik menggunakan auto-increment atau uuid sebagai id kunci utama
Apabila mereka bentuk jadual dalam mysql, mysql secara rasmi mengesyorkan untuk tidak menggunakan uuid atau kepingan salji tidak berterusan dan tidak berulang? id (berbentuk panjang dan (unik), tetapi disyorkan untuk terus meningkatkan id kunci utama. Pengesyoran rasmi ialah auto_increment. Jadi mengapa tidak disyorkan untuk menggunakan uuid? Apakah keburukan menggunakan uuid?
1. Uji uuid, id kenaikan automatik dan kecekapan sisipan nombor rawak
Pertama buat tiga jadual pengguna_auto_key mewakili jadual kenaikan automatik dan user_uuid mewakili Ia adalah uuid di mana id disimpan, dan random_key mewakili id jadual iaitu id kepingan salji. Kemudian keputusan ujian memasukkan data secara berkelompok dengan menyambung ke jdbc adalah seperti berikut:
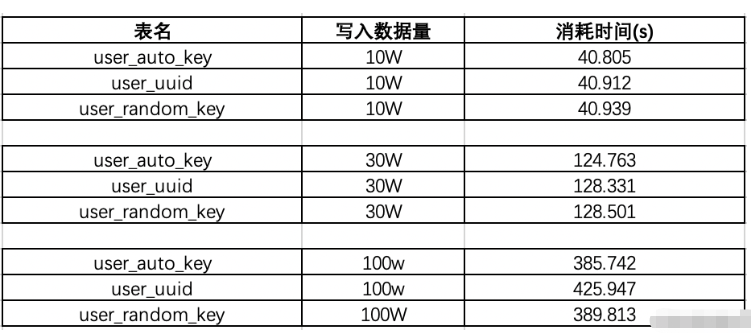
Apabila volum data sedia ada ialah 130W: Mari kita uji memasukkan data 10w sekali lagi untuk melihat apa yang berlaku. Keputusan:

Dapat dilihat apabila volum data adalah kira-kira 100W, kecekapan sisipan uuid berada di bahagian bawah, dan selepas menambah 130W data dalam jujukan, zaman uudi merudum lagi . Kedudukan kecekapan keseluruhan penggunaan masa ialah: auto_key>random_key>uuid, uuid mempunyai kecekapan terendah
2. Kelemahan menggunakan ID yang meningkat sendiri
1. Sekali orang lain merangkak Dengan mengambil pangkalan data anda, anda boleh mendapatkan maklumat pertumbuhan perniagaan anda berdasarkan ID kenaikan automatik pangkalan data, dan mudah untuk menganalisis situasi perniagaan anda
2 Untuk muatan selaras tinggi, sisipan innodb mengikut kunci utama Kadangkala ia akan menyebabkan pertikaian kunci yang jelas, dan sempadan atas kunci utama akan menjadi tempat yang hangat untuk pertikaian, kerana semua sisipan berlaku di sini, dan sisipan serentak akan menyebabkan pertikaian kunci jurang
3 Mekanisme kunci Auto_Increment akan menyebabkan automatik Rampasan kunci tambahan akan menyebabkan kehilangan prestasi tertentu
4. Auto-increment ID melibatkan pemindahan data, yang agak menyusahkan!
5 Dan apabila ia datang kepada sub-pangkalan data dan sub-jadual, agak menyusahkan untuk meningkatkan ID secara automatik!
3. Kelemahan penggunaan uuid
Oleh kerana uuid tidak mempunyai peraturan untuk id naik sendiri berjujukan, nilai baris baharu tidak semestinya lebih tinggi daripada primary sebelumnya nilai kunci adalah lebih besar, jadi InnoDB tidak boleh sentiasa memasukkan baris baharu ke penghujung indeks Sebaliknya, ia perlu mencari lokasi baharu yang sesuai untuk baris baharu untuk memperuntukkan ruang baharu. Proses ini memerlukan melakukan beberapa operasi tambahan, dan gangguan data boleh menyebabkan data bertaburan, mengakibatkan masalah berikut:
1 Halaman sasaran yang ditulis berkemungkinan telah dibuang ke cakera dan dialihkan up dari cache Selain itu, atau belum dimuatkan ke dalam cache, innodb perlu mencari dan membaca halaman sasaran dari cakera ke dalam memori sebelum memasukkan, yang akan menyebabkan banyak IO rawak
2 write adalah kemas Agar, innodb perlu melakukan operasi pemisahan halaman dengan kerap untuk memperuntukkan ruang untuk baris baharu yang membawa kepada pergerakan sejumlah besar data Sekurang-kurangnya tiga halaman perlu diubah suai untuk sisipan
3. Disebabkan oleh Pembahagian halaman yang kerap, halaman akan menjadi jarang dan diisi secara tidak teratur, yang akhirnya akan membawa kepada pemecahan data
Masalah pemisahan dan pemecahan halaman, uuid sememangnya akan menyebabkan masalah ini, tetapi Snowflake boleh menyelesaikan masalah ini, Algoritma kepingan salji secara semula jadi berurutan dan ID yang baru dimasukkan mestilah yang terbesar, jadi saya fikir menggunakan algoritma snowflake adalah pilihan yang sangat baik!
5 Gunakan kunci asing sesedikit mungkin dalam pembangunan sebenar
Kunci dan indeks utama adalah amat diperlukan bukan sahaja untuk mengoptimumkan kelajuan pengambilan data, tetapi juga menyelamatkan pembangun kerja lain.
Fokus konflik: sama ada reka bentuk pangkalan data memerlukan kunci asing. Terdapat dua soalan di sini:
Satu ialah cara memastikan integriti dan konsistensi data pangkalan data
Yang kedua ialah kesan yang pertama terhadap prestasi.
Di sini dibahagikan kepada dua sudut pandangan, pro dan kontra, untuk rujukan!
1. Sudut pandangan positif
1 Pangkalan data itu sendiri memastikan ketekalan data, integriti, dan lebih dipercayai, kerana sukar untuk program menjamin 100% integriti data. , dan sukar untuk menggunakan luaran Walaupun pelayan pangkalan data ranap atau masalah lain berlaku, kunci boleh memastikan ketekalan dan integriti data ke tahap yang paling tinggi.
2. Reka bentuk pangkalan data dengan kunci utama dan asing boleh meningkatkan kebolehbacaan rajah ER, yang sangat penting dalam reka bentuk pangkalan data.
3. Logik perniagaan yang dijelaskan oleh kunci asing pada tahap tertentu akan menjadikan reka bentuk bernas, khusus dan komprehensif.
Terdapat hubungan satu-ke-banyak antara pangkalan data dan aplikasi Aplikasi A akan mengekalkan integriti bahagian datanya Apabila sistem menjadi lebih besar, aplikasi B ditambah mungkin dibangunkan oleh syarikat yang berbeza Pasukan melakukannya. Bagaimana untuk menyelaras untuk memastikan integriti data, dan jika aplikasi C baharu ditambah selepas setahun, bagaimana untuk menanganinya?
2. Pandangan bertentangan
1. Pencetus atau aplikasi boleh digunakan untuk memastikan integriti data
2 , membawa kepada masalah seperti terlalu banyak jadual
3 Pengurusan data adalah mudah, mudah dikendalikan dan berprestasi tinggi apabila tiada kunci asing digunakan (operasi seperti import dan eksport adalah lebih pantas apabila memasukkan, mengemas kini dan. memadam data)
Jangan memikirkan kunci asing dalam pangkalan data yang besar Bayangkan, program perlu memasukkan berjuta-juta rekod setiap hari Apabila terdapat kekangan kunci asing, ia perlu mengimbas sama ada rekod itu layak, yang mana biasanya lebih daripada Medan yang mempunyai kunci asing, jadi bilangan imbasan meningkat secara eksponen! Salah satu program saya telah siap dalam 3 jam Jika kunci asing ditambahkan, ia akan mengambil masa 28 jam!
3. Kesimpulan
1 Dalam sistem besar (keperluan prestasi rendah, keperluan keselamatan tinggi), gunakan kunci asing dalam sistem besar (keperluan prestasi tinggi, keselamatan perlu dikawal sendiri) , Tiada kunci asing diperlukan untuk sistem kecil, lebih baik menggunakan kunci asing.
2. Gunakan kunci asing dengan sewajarnya dan jangan terlalu mengejarnya
Untuk memastikan ketekalan dan integriti data, anda boleh mengawalnya melalui program tanpa menggunakan kunci asing. Pada masa ini, lapisan harus ditulis untuk melaksanakan perlindungan data, dan kemudian pelbagai aplikasi pangkalan data boleh diakses melalui lapisan ini.
Perlu diambil perhatian bahawa:
MySQL membenarkan penggunaan kunci asing, tetapi untuk tujuan semakan integriti, ciri ini diabaikan dalam semua jenis jadual kecuali jenis jadual InnoDB. Ini mungkin kelihatan pelik, tetapi ia sebenarnya agak biasa: melakukan semakan integriti selepas setiap sisipan, kemas kini dan pemadaman semua kunci asing dalam pangkalan data ialah proses yang memakan masa dan sumber yang boleh memberi kesan kepada prestasi, terutamanya apabila memproses kompleks atau bilangan sambungan belitan. Oleh itu, pengguna boleh memilih yang sesuai dengan keperluan khusus mereka berdasarkan jadual.
Jadi, jika anda memerlukan prestasi yang lebih baik, dan tidak memerlukan pemeriksaan integriti, anda boleh memilih untuk menggunakan jenis jadual MyISAM, jika anda ingin membina jadual berdasarkan integriti rujukan dalam MySQL dan ingin mengekalkan prestasi yang baik atas dasar ini Untuk prestasi yang lebih baik, sebaiknya pilih struktur jadual sebagai jenis innoDB
Atas ialah kandungan terperinci Apakah kekangan MySQL?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!