
Rumah >Peranti teknologi >AI >AI Morning Post |. Apakah pengalaman teks, imej, audio dan video, dan penjanaan 3D antara satu sama lain?
AI Morning Post |. Apakah pengalaman teks, imej, audio dan video, dan penjanaan 3D antara satu sama lain?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-26 14:29:081735semak imbas

Pada 9 Mei, waktu tempatan, Meta mengumumkan bahawa ia telah membuka model AI baharu yang dipanggil ImageBind yang boleh merangkumi 6 kaedah berbeza, termasuk penglihatan (imej dan video), suhu (imej inframerah), teks dan audio , maklumat kedalaman, bacaan gerakan (dijana oleh unit ukuran inersia atau IMU). Pada masa ini, kod sumber yang berkaitan telah dihoskan pada GitHub.
Apakah maksud menjangkau 6 mod?
ImageBind mengambil visi sebagai terasnya dan boleh memahami dan menukar antara 6 mod secara bebas. Meta menunjukkan beberapa kes, seperti mendengar anjing menyalak dan melukis anjing, dan memberikan peta kedalaman yang sepadan dan penerangan teks pada masa yang sama seperti memasukkan imej burung + bunyi ombak laut, dan mendapatkan imej seekor burung di pantai.
Berbanding dengan penjana imej seperti Midjourney, Stable Diffusion dan DALL-E 2 yang menggandingkan teks dengan imej, ImageBind lebih seperti menghantar jaring yang luas dan boleh menyambungkan teks, imej/video, audio, ukuran 3D (kedalaman), data suhu (panas) dan data gerakan (dari IMU), dan ia secara langsung meramalkan hubungan antara data tanpa latihan terlebih dahulu untuk setiap kemungkinan, sama seperti cara manusia melihat atau membayangkan alam sekitar.

Para penyelidik menyatakan bahawa ImageBind boleh dimulakan menggunakan model bahasa visual berskala besar seperti CLIP, dengan itu memanfaatkan perwakilan imej dan teks yang kaya bagi model ini. Oleh itu, ImageBind boleh disesuaikan dengan modaliti dan tugas yang berbeza dengan latihan yang sangat sedikit.
ImageBind adalah sebahagian daripada komitmen Meta untuk mencipta sistem AI berbilang modal yang belajar daripada semua jenis data yang berkaitan. Apabila bilangan modaliti meningkat, ImageBind membuka pintu air kepada penyelidik untuk cuba membangunkan sistem holistik baharu, seperti menggabungkan penderia 3D dan IMU untuk mereka bentuk atau mengalami dunia maya yang mengasyikkan. Ia juga menyediakan cara yang kaya untuk meneroka memori anda dengan menggunakan gabungan teks, video dan imej untuk mencari imej, video, fail audio atau maklumat teks.
Model ini pada masa ini hanya projek penyelidikan dan tidak mempunyai pengguna langsung atau aplikasi praktikal, tetapi ia menunjukkan bagaimana AI generatif boleh menjana kandungan yang mengasyikkan, pelbagai deria pada masa hadapan, dan juga menunjukkan bahawa Meta In cara yang berbeza daripada pesaing seperti OpenAI dan Google, ia menempa laluan ke arah model sumber terbuka yang besar.
Akhirnya, Meta percaya bahawa teknologi ImageBind akhirnya akan mengatasi enam "deria" semasa berkata di blognya, "Sementara kami meneroka enam mod dalam penyelidikan semasa kami, kami percaya dalam memperkenalkan seberapa banyak sambungan yang mungkin Modaliti deria baharu— seperti sentuhan, pertuturan, bau dan isyarat fMRI otak—akan membolehkan model AI berpusatkan manusia yang lebih kaya ”
Penggunaan ImageBind
Jika ChatGPT boleh berfungsi sebagai enjin carian dan komuniti Soal Jawab, dan Midjourney boleh digunakan sebagai alat lukisan, apakah yang boleh anda lakukan dengan ImageBind?
Menurut demo rasmi, ia boleh menjana audio terus daripada imej:
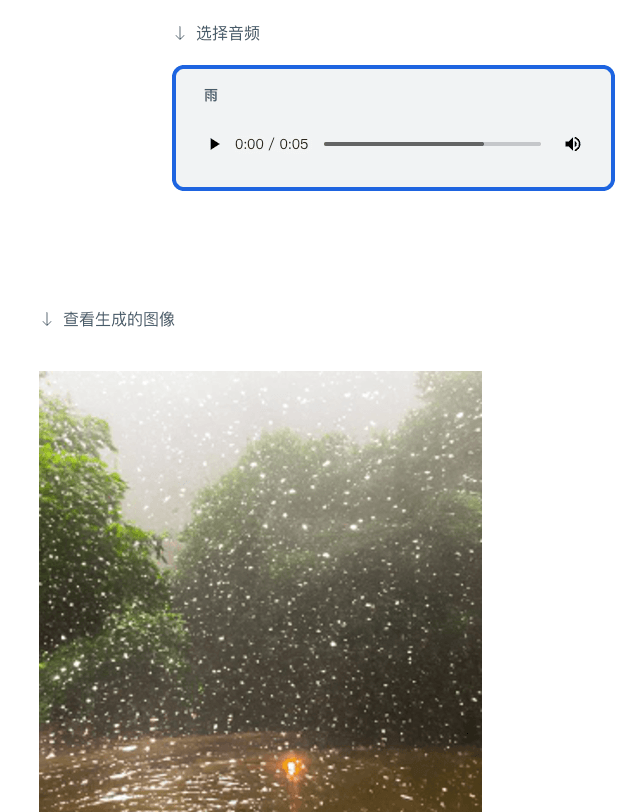
Anda juga boleh menjana gambar daripada audio:
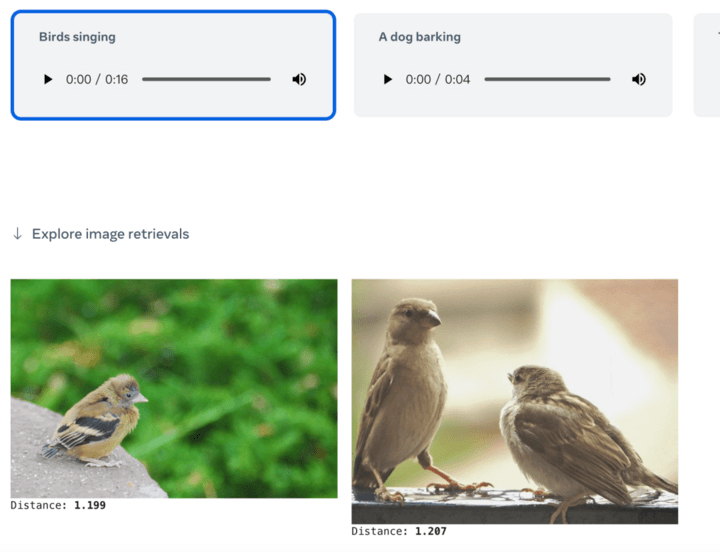
Atau hanya berikan teks untuk mendapatkan semula gambar atau kandungan audio yang berkaitan:
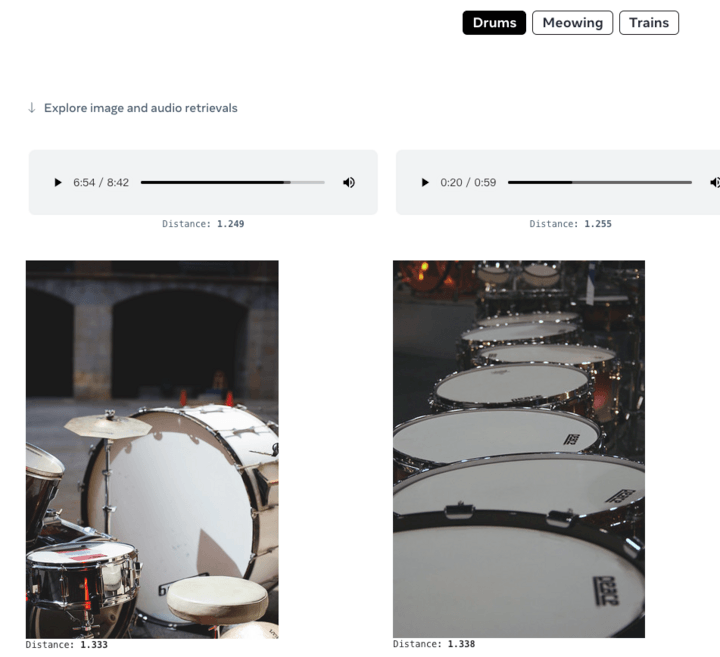
Anda juga boleh memberikan audio dan menjana imej yang sepadan:
Seperti yang dinyatakan di atas, ImageBind menyediakan cara untuk sistem AI generatif masa hadapan dipersembahkan dalam pelbagai modaliti, dan pada masa yang sama, digabungkan dengan teknologi dan senario seperti realiti maya, realiti campuran dan metaverse dalam Meta. Menggunakan alatan seperti ImageBind akan membuka pintu baharu dalam ruang yang boleh diakses, contohnya, menjana penerangan multimedia masa nyata untuk membantu orang yang mengalami masalah penglihatan atau pendengaran lebih memahami persekitaran terdekat mereka.
Masih banyak yang perlu ditemui tentang pembelajaran pelbagai mod. Pada masa ini, bidang kecerdasan buatan tidak mengukur tingkah laku penskalaan secara berkesan yang hanya muncul dalam model yang lebih besar dan memahami aplikasinya. ImageBind ialah satu langkah ke arah menilai dan menunjukkan aplikasi baharu untuk penjanaan dan pengambilan imej dengan cara yang ketat.
Pengarang: Balada
Sumber: Rangkaian Elektrik Pertama (www.d1ev.com)
Atas ialah kandungan terperinci AI Morning Post |. Apakah pengalaman teks, imej, audio dan video, dan penjanaan 3D antara satu sama lain?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI