
Rumah >pangkalan data >tutorial mysql >Apakah perbezaan antara count(*), count(1), dan count(col) dalam MySQL?
Apakah perbezaan antara count(*), count(1), dan count(col) dalam MySQL?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-26 13:37:081877semak imbas
Fungsi kiraan
COUNT(ungkapan): Mengembalikan jumlah bilangan rekod yang ditanya Parameter ungkapan ialah medan atau tanda *.
Ujian
Versi MySQL: 5.7.29
Buat jadual pengguna dan masukkan satu juta keping data, yang mana setengah juta baris dalam medan jantina adalah nol Nilai daripada
CREATE TABLE `users` ( `Id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id', `name` varchar(32) DEFAULT NULL COMMENT '名称', `gender` varchar(20) DEFAULT NULL COMMENT '性别', `create_date` datetime DEFAULT NULL COMMENT '创建时间', PRIMARY KEY (`Id`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC COMMENT='用户表';
count(*)
Sebelum MySQL 5.7.18, InnoDB memproses kenyataan dengan mengimbas indeks berkelompok. SELECT COUNT(*) Bermula dalam MySQL 5.7.18, InnoDB mengendalikan penyataan SELECT COUNT(*) dengan merentasi indeks sekunder terkecil yang tersedia, melainkan petunjuk indeks atau pengoptimum mengarahkan pengoptimum untuk menggunakan indeks yang berbeza. Jika indeks sekunder tidak wujud, indeks berkelompok akan diimbas.
Maksud umum ialah jika terdapat indeks sekunder, gunakan indeks sekunder Jika terdapat beberapa indeks sekunder, indeks sekunder terkecil akan diutamakan untuk mengurangkan kos jika tiada indeks sekunder, gunakan indeks berkelompok.
Ujian berikut digunakan untuk mengesahkan pandangan ini.
Mula-mula, tanya pelan pelaksanaan apabila hanya terdapat indeks kunci utama Id

Anda boleh melihat bahawa jenisnya ialah indeks, yang bermaksud bahawa. indeks digunakan. Kuncinya adalah PRIMARY, yang bermaksud indeks kunci utama digunakan, key_len=8.
Seterusnya, tambahkan indeks pada medan nama dan gunakan pelan pelaksanaan sekali lagi untuk melihat

Anda boleh melihat bahawa indeks juga digunakan, tetapi indeks menggunakan nama Indeks medan, key_len=99.
Kemudian tambahkan indeks pada medan create_date sambil mengekalkan indeks medan nama, dan semak pelan pelaksanaan sekali lagi

Anda boleh melihat bahawa kali ini The medan create_date diindeks, key_len=6.
Tidak kira indeks yang digunakan di atas, jumlah baris yang ditanya ialah satu juta, tidak kira sama ada ia mengandungi nilai NULL.
count(1)
count(1) mempunyai hasil pertanyaan yang sama seperti count(*), dan akhirnya mengembalikan satu juta keping data, tidak kira sama ada ia mengandungi nilai NULL.
count(col)
count(col) mengira nilai lajur tertentu, yang dibahagikan kepada tiga situasi:
count(id): counts id
Hasil pertanyaan adalah sama seperti count(*), dan akhirnya satu juta keping data dikembalikan
count(index col): Kira medan terindeks
dengan count(. nama) Untuk pertanyaan, pelan pelaksanaan adalah seperti berikut:

Anda boleh melihat bahawa medan indeks digunakan untuk statistik, dan indeks juga dipukul.
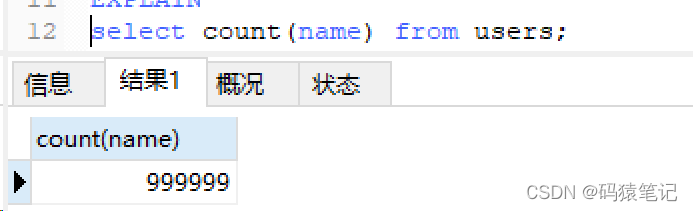
Tetapkan medan nama dalam lajur kepada NULL, dan kemudian lakukan pertanyaan kiraan Hasilnya mengembalikan 999999
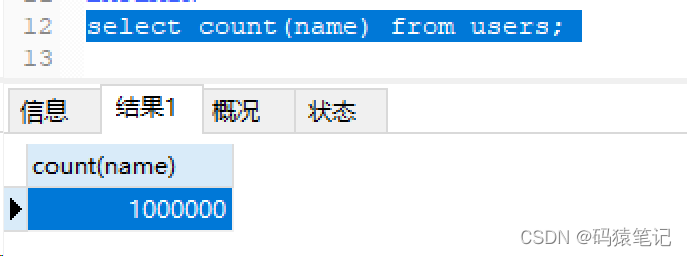
Kemudian tetapkan nilai NULL lajur ini kepada kosong. rentetan, dan kemudian Lakukan pertanyaan kiraan, dan hasilnya mengembalikan 1000000
Oleh itu, hanya menggunakan medan indeks untuk mengira bilangan baris boleh mencapai indeks, dan hanya kira bilangan baris yang bukan nilai NULL.
count (col normal): Kira medan tanpa indeks
Jika anda mengira medan tanpa indeks, indeks tidak akan digunakan dan hanya bilangan baris yang bukan nilai NULL akan dikira.

Pertukaran yang manakah antara kiraan(1) dan kiraan(*)
Saya tidak tahu di mana saya melihat atau mendengar tentangnya sebelum ini, kira (1) adalah lebih baik daripada count(*) count(*) adalah sangat cekap, yang merupakan persepsi yang salah Terdapat pepatah di laman web rasmi, InnoDB mengendalikan operasi SELECT COUNT(*) dan SELECT COUNT(1) dalam operasi yang sama. cara. Tiada perbezaan prestasi.
Terjemahan Intinya ialah InnoDB mengendalikan operasi SELECT COUNT(*) dan SELECT COUNT(1) dengan cara yang sama, tanpa perbezaan prestasi.
Untuk jadual MyISAM, COUNT(*) dioptimumkan untuk kembali dengan cepat jika mengambil semula daripada jadual, tiada lajur lain diambil dan tiada klausa, pengoptimuman ini hanya terpakai pada jadual MyISAM kerana untuk ini Enjin storan menyimpan bilangan baris yang tepat dan boleh diakses dengan cepat. COUNT(1) melakukan pengoptimuman yang sama hanya jika lajur pertama ditakrifkan sebagai NOT NULL. ----Dari tapak web rasmi MySQL
Pengoptimuman ini adalah berdasarkan premis bahawa tiada tempat dan kumpulan mengikut.
Spesifikasi pembangunan Alibaba juga menyebut

, jadi jika anda boleh menggunakan count(*) dalam pembangunan, gunakan count(*).
Atas ialah kandungan terperinci Apakah perbezaan antara count(*), count(1), dan count(col) dalam MySQL?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!