
Rumah >Peranti teknologi >AI >Meniru ringkasan ilahi Jeff Dean, seorang bekas jurutera Google berkongsi 'rahsia pembangunan LLM': nombor yang perlu diketahui oleh setiap pembangun!
Meniru ringkasan ilahi Jeff Dean, seorang bekas jurutera Google berkongsi 'rahsia pembangunan LLM': nombor yang perlu diketahui oleh setiap pembangun!

- 王林ke hadapan
- 2023-05-25 22:25:291482semak imbas
Baru-baru ini, seorang netizen menyusun senarai "Nombor yang perlu diketahui oleh setiap pembangun LLM" dan menerangkan sebab nombor ini penting dan cara kita harus menggunakannya.
Semasa dia berada di Google, terdapat dokumen yang disusun oleh jurutera legenda Jeff Dean yang dipanggil "Nombor Setiap Jurutera Perlu Tahu".

Jeff Dean: "Nombor yang perlu diketahui oleh setiap jurutera"
Untuk pembangun LLM (Model Bahasa Besar), ia juga sangat berguna untuk mempunyai set nombor yang serupa untuk anggaran kasar.

Prompt
40-90%: Tambahkan "ringkas dan tepat" to the prompt Penjimatan kos seterusnya
Anda mesti tahu bahawa anda membayar mengikut token yang digunakan oleh LLM semasa mengeksport.
Ini bermakna anda boleh menjimatkan banyak wang dengan membiarkan model anda ringkas.
Pada masa yang sama, konsep ini boleh dikembangkan ke lebih banyak tempat.
Sebagai contoh, anda pada asalnya ingin menggunakan GPT-4 untuk menjana 10 alternatif, tetapi kini anda mungkin memintanya untuk menyediakan 5 dahulu, dan kemudian anda boleh menyimpan separuh lagi wang itu .
1.3: Purata bilangan token setiap perkataan
LLM beroperasi dalam unit token.
Dan token ialah perkataan atau sub-bahagian perkataan Sebagai contoh, "makan" boleh dipecahkan kepada dua token, "makan" dan "ing".
Secara umumnya, 750 perkataan Inggeris akan menjana kira-kira 1000 token.
Untuk bahasa selain bahasa Inggeris, bilangan token bagi setiap perkataan akan ditingkatkan, bergantung pada persamaannya dalam korpus benam LLM.

Harga
Memandangkan kos penggunaan LLM adalah sangat tinggi, angka yang berkaitan dengan harga telah menjadi sangat penting.
~50: Nisbah kos GPT-4 dan GPT-3.5 Turbo
Menggunakan GPT-3.5-Turbo Kira-kira 50 kali lebih murah daripada GPT-4. Saya sebut "kira-kira" kerana GPT-4 mengecaj secara berbeza untuk gesaan dan penjanaan.
Jadi dalam aplikasi sebenar, adalah lebih baik untuk mengesahkan sama ada GPT-3.5-Turbo cukup untuk memenuhi keperluan anda.
Sebagai contoh, untuk tugasan seperti generalisasi, GPT-3.5-Turbo adalah lebih daripada mencukupi.


5: Gunakan GPT- 3.5-Turbo lwn. Nisbah Kos Benamkan OpenAI untuk Penjanaan Teks
Ini bermakna mencari sesuatu dalam sistem storan vektor adalah jauh lebih murah daripada menggunakan penjanaan dengan LLM.
Khususnya, mencari dalam sistem perolehan maklumat saraf berharga kira-kira 5 kali lebih rendah daripada meminta GPT-3.5-Turbo. Berbanding dengan GPT-4, jurang kos adalah setinggi 250 kali ganda!
10: Nisbah kos pembenaman OpenAI berbanding pembenaman dihoskan sendiri
Nota: Nombor ini adalah sangat sensitif untuk memuatkan dan membenamkan saiz kelompok adalah sangat sensitif, jadi sila pertimbangkan ia sebagai anggaran.
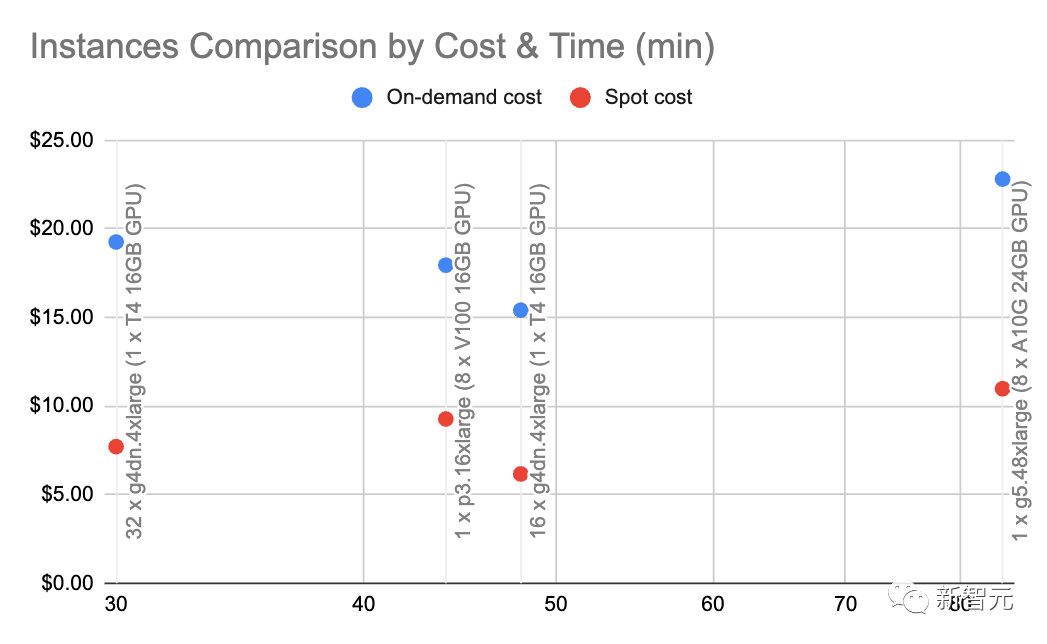
Dengan g4dn.4xlarge (harga atas permintaan: $1.20/jam) kami boleh memanfaatkan SentenceTransformers dengan HuggingFace (setanding dengan pembenaman OpenAI) pada ~9000 sesaat Kelajuan token membenamkan.
Melakukan beberapa pengiraan asas pada kelajuan dan jenis nod ini menunjukkan bahawa benaman yang dihoskan sendiri boleh menjadi 10x lebih murah.
6: Nisbah kos model asas OpenAI dan pertanyaan model yang diperhalusi
Pada OpenAI, kos model diperhalusi 6 kali ganda daripada model asas.
Ini juga bermakna bahawa ia adalah lebih menjimatkan kos untuk melaraskan gesaan model asas daripada memperhalusi model tersuai.
1: Nisbah kos model asas pengehosan sendiri berbanding pertanyaan model yang diperhalusi
Jika anda mengehos model itu sendiri, maka Kos model yang diperhalusi hampir sama dengan model asas: bilangan parameter adalah sama untuk kedua-dua model.
Latihan dan penalaan halus
~$1 juta: kos melatih model parameter 13 bilion pada 1.4 trilion token
Alamat kertas: https://arxiv.org/pdf/2302.13971.pdf
LLaMa's The kertas menyebut bahawa mereka mengambil masa 21 hari dan menggunakan 2048 A100 80GB GPU untuk melatih model LLaMa.
Dengan mengandaikan kami melatih model kami pada set latihan Piyama Merah, dengan mengandaikan semuanya berfungsi dengan baik, tanpa sebarang ranap, dan ia berjaya pada kali pertama, kami akan mendapat nombor di atas.
Selain itu, proses ini juga melibatkan penyelarasan antara 2048 GPU.
Kebanyakan syarikat tidak mempunyai syarat untuk melakukan ini.
Walau bagaimanapun, mesej yang paling kritikal ialah: adalah mungkin untuk melatih LLM kita sendiri, tetapi prosesnya tidak murah.
Dan setiap kali ia berjalan, ia mengambil masa beberapa hari.
Sebagai perbandingan, menggunakan model pra-latihan akan jauh lebih murah.
< 0.001: Kadar kos untuk penalaan halus dan latihan dari awal
Nombor ini agak umum , secara keseluruhan Secara umumnya, kos penalaan halus boleh diabaikan.
Sebagai contoh, anda boleh memperhalusi model parameter 6B untuk kira-kira $7.
Walaupun pada kadar OpenAI untuk model yang ditala halus paling mahal, Davinci, ia hanya berharga 3 setiap 1,000 token sen .
Ini bermakna jika anda ingin memperhalusi keseluruhan karya Shakespeare (kira-kira 1 juta perkataan), anda hanya perlu membelanjakan empat puluh atau lima puluh dolar.
Walau bagaimanapun, penalaan halus adalah satu perkara, latihan dari awal adalah satu lagi...
Memori GPU
Jika anda mengehos sendiri model, adalah sangat penting untuk memahami memori GPU, kerana LLM menolak memori GPU ke had.
Statistik berikut digunakan khusus untuk inferens. Jika anda ingin melakukan latihan atau penalaan halus, anda memerlukan sedikit memori video.
V100: 16GB, A10G: 24GB, A100: 40/80GB: kapasiti memori GPU
Fahami perbezaan jenis Jumlah memori video GPU anda adalah penting kerana ini akan mengehadkan jumlah parameter yang boleh dimiliki oleh LLM anda.
Secara umumnya, kami suka menggunakan A10G kerana harga atas permintaan mereka pada AWS ialah $1.5 hingga $2 sejam dan mempunyai memori GPU 24G, manakala setiap A100 Harganya lebih kurang $5/ jam.
2x Saiz Parameter: Keperluan memori GPU biasa untuk LLM
Sebagai contoh, apabila anda mempunyai 7 bilion Parametrik model memerlukan lebih kurang 14GB memori GPU.
Ini kerana kebanyakan masa, setiap hujah memerlukan apungan 16-bit (atau 2 bait).
Biasanya tidak lebih daripada 16 bit ketepatan diperlukan, tetapi kebanyakan masa resolusi mula berkurangan apabila ketepatan mencapai 8 bit (dalam beberapa kes ini boleh diterima).
Sudah tentu, terdapat beberapa projek yang telah memperbaiki keadaan ini. Sebagai contoh, llama.cpp menjalankan model parameter 13 bilion dengan mengkuantisasi kepada 4 bit pada GPU 6GB (8 bit juga tersedia), tetapi ini bukan perkara biasa.
~1GB: Keperluan memori GPU biasa untuk membenamkan model
Setiap kali anda membenamkan pernyataan (pengelompokan, semantik (yang sering dilakukan untuk tugas carian dan pengelasan), anda memerlukan model pembenaman seperti penukar ayat. OpenAI juga mempunyai model pembenaman komersialnya sendiri.
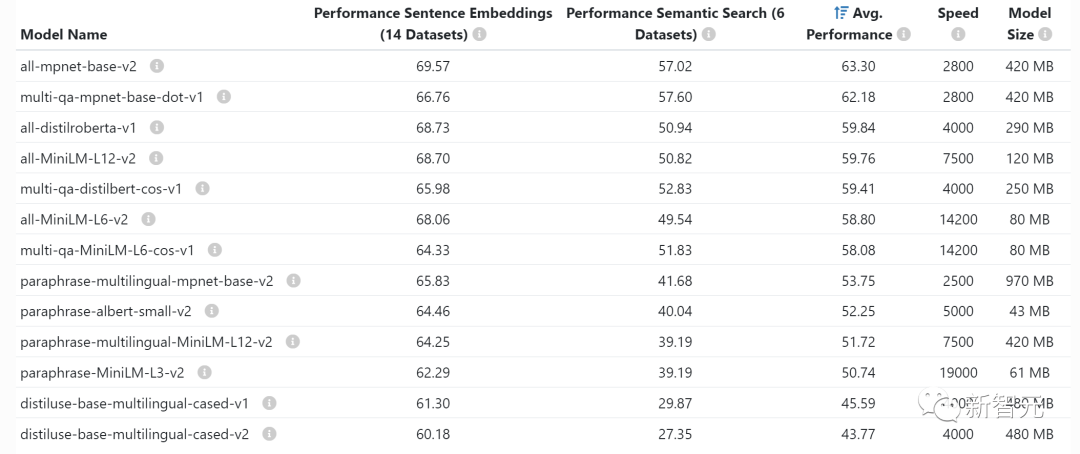
Anda biasanya tidak perlu risau tentang berapa banyak memori video yang dibenamkan pada GPU, ia cantik kecil dan anda juga boleh membenamkan LLM pada GPU yang sama.
>10x: Tingkatkan daya pengeluaran dengan menggabungkan permintaan LLM
Latensi menjalankan pertanyaan LLM melalui GPU Sangat tinggi: Pada daya pemprosesan 0.2 pertanyaan sesaat, kependaman mungkin 5 saat.
Menariknya, jika anda menjalankan dua tugasan, kependaman mungkin hanya 5.2 saat.
Ini bermakna jika anda boleh menggabungkan 25 pertanyaan bersama-sama, anda memerlukan kira-kira 10 saat kependaman, manakala daya pemprosesan telah dipertingkatkan kepada 2.5 pertanyaan sesaat.
Walau bagaimanapun, sila baca.
~1 MB: Memori GPU diperlukan untuk model parameter 13 bilion untuk mengeluarkan 1 token
Apa yang anda perlukan Jumlah memori video adalah berkadar terus dengan bilangan maksimum token yang anda ingin hasilkan.
Sebagai contoh, menjana output sehingga 512 token (kira-kira 380 perkataan) memerlukan 512MB memori video.
Anda mungkin berkata, ini bukan masalah besar - Saya mempunyai 24GB memori video, apakah itu 512MB? Walau bagaimanapun, jika anda ingin menjalankan kumpulan yang lebih besar, bilangan ini mula bertambah.
Sebagai contoh, jika anda ingin melakukan 16 kelompok, memori video akan terus meningkat kepada 8GB.
Atas ialah kandungan terperinci Meniru ringkasan ilahi Jeff Dean, seorang bekas jurutera Google berkongsi 'rahsia pembangunan LLM': nombor yang perlu diketahui oleh setiap pembangun!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI