
Rumah >Peranti teknologi >AI >Penilaian boleh diterbitkan semula, automatik, kos rendah dan tahap tinggi, PandaLM, model besar pertama yang menilai model besar secara automatik, ada di sini
Penilaian boleh diterbitkan semula, automatik, kos rendah dan tahap tinggi, PandaLM, model besar pertama yang menilai model besar secara automatik, ada di sini

- PHPzke hadapan
- 2023-05-25 19:16:321833semak imbas
Pembangunan model besar boleh dikatakan pantas, kaedah penalaan halus arahan telah muncul seperti cendawan selepas hujan, dan sejumlah besar model besar "pengganti" ChatGPT telah dikeluarkan satu selepas yang lain. Dalam latihan dan pembangunan aplikasi model besar, penilaian keupayaan sebenar pelbagai model besar seperti sumber terbuka, sumber tertutup, dan penyelidikan sendiri telah menjadi pautan penting dalam meningkatkan kecekapan dan kualiti penyelidikan dan pembangunan.
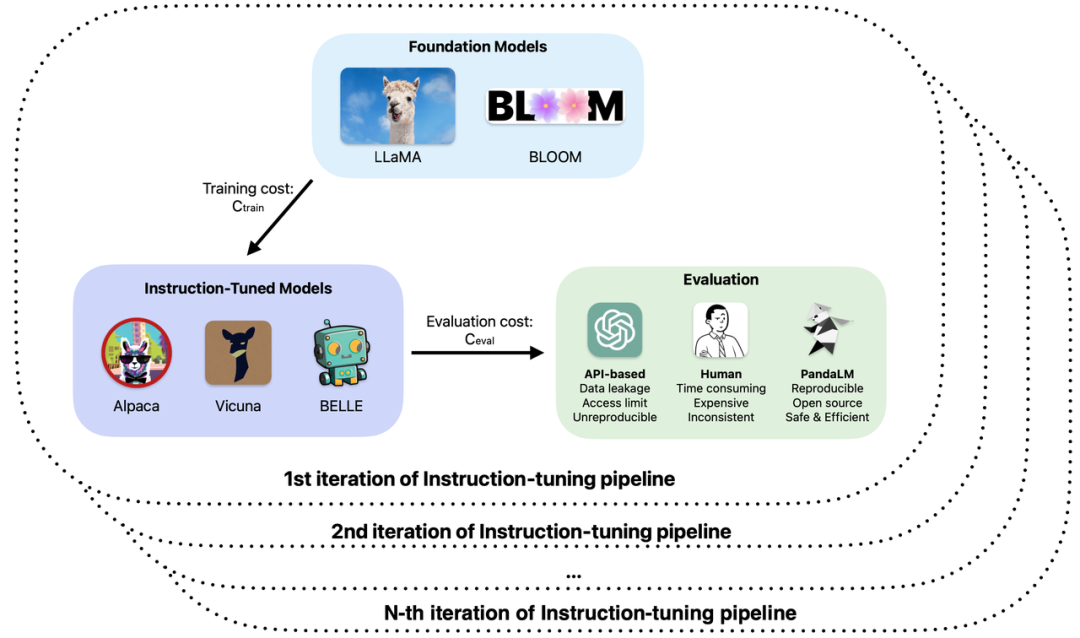
Khususnya, dalam latihan dan aplikasi model besar, anda mungkin menghadapi masalah berikut:
2 Gunakan ChatGPT untuk menilai output model, tetapi ChatGPT memperoleh hasil penilaian yang berbeza untuk input yang sama pada masa yang berbeza.
3. Memakan masa dan susah payah menggunakan anotasi manual untuk menilai hasil yang dihasilkan oleh model dan mengurangkan kos apabila belanjawan terhad dan masa ketat?
4. Apabila berurusan dengan data sulit, sama ada menggunakan ChatGPT/GPT4 atau menandai syarikat untuk penilaian model, anda akan menghadapi masalah kebocoran data.
Berdasarkan isu ini, penyelidik dari Universiti Peking, West Lake University dan institusi lain bersama-sama mencadangkan paradigma penilaian model besar baharu - PandaLM. PandaLM melaksanakan ujian automatik dan boleh dihasilkan semula serta pengesahan keupayaan model besar dengan melatih model besar khusus untuk penilaian. PandaLM, dikeluarkan di GitHub pada 30 April, ialah model besar pertama di dunia untuk penilaian. Kertas kerja berkaitan akan diterbitkan dalam masa terdekat.

PandaLM bertujuan untuk menjadikan model besar mempelajari keutamaan manusia secara keseluruhan untuk teks yang dijana oleh model besar yang berbeza melalui latihan, dan membuat penilaian relatif berdasarkan keutamaan untuk menggantikan kaedah penilaian manual atau berasaskan API dan mengurangkan kos. Tingkatkan kecekapan. Wajaran PandaLM didedahkan sepenuhnya dan boleh dijalankan pada perkakasan gred pengguna dengan ambang perkakasan yang rendah. Keputusan penilaian PandaLM boleh dipercayai, boleh dihasilkan sepenuhnya, dan boleh melindungi keselamatan data Proses penilaian boleh diselesaikan secara tempatan, menjadikannya sangat sesuai untuk digunakan dalam akademik dan unit yang memerlukan data sulit. Menggunakan PandaLM adalah sangat mudah dan hanya memerlukan tiga baris kod untuk membuat panggilan. Untuk mengesahkan keupayaan penilaian PandaLM, pasukan PandaLM menjemput tiga anotasi profesional untuk menilai secara bebas output model besar yang berbeza, dan membina set ujian pelbagai yang mengandungi 1,000 sampel dalam 50 medan. Pada set ujian ini, ketepatan PandaLM mencapai tahap 94% daripada ChatGPT, dan PandaLM menghasilkan kesimpulan yang sama tentang kelebihan dan kekurangan model seperti anotasi manual.
Pengenalan PandaLM
Pada masa ini, terdapat dua cara utama untuk menilai model besar:
(1) Dengan menghubungi antara muka API pertama syarikat pihak ketiga;
(2) Upah pakar untuk anotasi manual.
Walau bagaimanapun, pemindahan data kepada syarikat pihak ketiga boleh membawa kepada pelanggaran data yang serupa dengan kod di mana pekerja Samsung membocorkan kod [1] dan mengupah pakar untuk melabelkan sejumlah besar data adalah masa -memakan dan mahal. Masalah segera yang perlu diselesaikan ialah: bagaimana untuk mencapai penilaian model besar yang memelihara privasi, boleh dipercayai, boleh dihasilkan semula dan murah?
Untuk mengatasi batasan kedua-dua kaedah penilaian ini, kajian ini membangunkan PandaLM, model pengadil yang digunakan khusus untuk menilai prestasi model besar, dan menyediakan antara muka mudah yang membolehkan pengguna untuk PandaLM boleh dipanggil dengan hanya satu baris kod untuk mencapai penilaian model berskala besar yang memelihara privasi, boleh dipercayai, boleh berulang dan menjimatkan. Untuk butiran latihan tentang PandaLM, lihat projek sumber terbuka.
Untuk mengesahkan keupayaan PandaLM menilai model besar, pasukan penyelidik membina set ujian beranotasi manusia yang pelbagai dengan kira-kira 1,000 sampel, dengan konteks dan label yang dihasilkan oleh manusia. Pada set data ujian, PandaLM-7B mencapai ketepatan 94% daripada ChatGPT (gpt-3.5-turbo).
Bagaimana untuk menggunakan PandaLM?
Apabila dua model besar yang berbeza menghasilkan tindak balas yang berbeza kepada arahan dan konteks yang sama, matlamat PandaLM adalah untuk membandingkan kualiti respons kedua-dua model dan mengeluarkan perbandingan Keputusan, asas untuk perbandingan, dan respons untuk rujukan. Terdapat tiga hasil perbandingan: respons 1 lebih baik; respons 2 lebih baik dan respons 2 adalah sama kualiti. Apabila membandingkan prestasi berbilang model besar, hanya gunakan PandaLM untuk melakukan perbandingan berpasangan dan kemudian agregat perbandingan ini untuk menilai prestasi model atau plot susunan separa model. Ini membolehkan analisis visual perbezaan prestasi antara model yang berbeza. Oleh kerana PandaLM hanya perlu digunakan secara tempatan dan tidak memerlukan penglibatan manusia, ia boleh dinilai dengan cara memelihara privasi dan kos rendah. Untuk memberikan kebolehtafsiran yang lebih baik, PandaLM juga boleh menerangkan pilihannya dalam bahasa semula jadi dan menjana set respons rujukan tambahan.
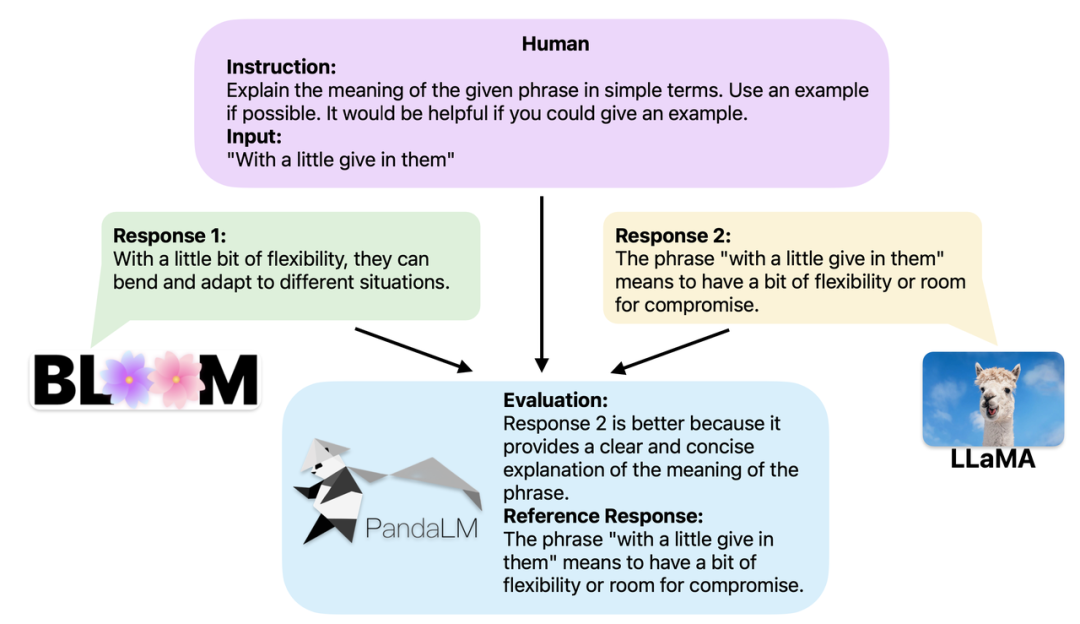
PandaLM bukan sahaja menyokong penggunaan UI Web untuk analisis kes, tetapi juga menyokong tiga baris kod untuk memanggil PandaLM untuk sebarang model dan penilaian teks yang dijana Data. Memandangkan banyak model dan rangka kerja sedia ada mungkin bukan sumber terbuka atau sukar untuk disimpulkan secara setempat, PandaLM membenarkan penjanaan teks untuk dinilai dengan menentukan berat model atau menghantar terus dalam fail .json yang mengandungi teks yang akan dinilai. Pengguna boleh memanfaatkan PandaLM untuk menilai model yang ditentukan pengguna dan data input hanya dengan menyediakan senarai nama model, ID model HuggingFace atau laluan fail .json. Berikut ialah contoh penggunaan minimalis:

Selain itu, untuk membolehkan semua orang menggunakan PandaLM secara fleksibel untuk penilaian percuma , Pasukan penyelidik telah mendedahkan berat model PandaLM di laman web HuggingFace. Anda boleh memuatkan model PandaLM-7B dengan mudah dengan arahan berikut:

Ciri PandaLM
Ciri-ciri PandaLM termasuk kebolehulangan, automasi, perlindungan privasi, kos rendah dan tahap penilaian yang tinggi.
1. Kebolehulangan: Memandangkan wajaran PandaLM adalah umum, walaupun terdapat kerawak dalam keluaran model bahasa, keputusan penilaian PandaLM akan kekal konsisten selepas menetapkan benih rawak. Kaedah penilaian yang bergantung pada API dalam talian mungkin mempunyai kemas kini yang tidak konsisten pada masa yang berbeza disebabkan oleh kemas kini legap, dan apabila model diulang, model lama dalam API mungkin tidak lagi boleh diakses, jadi penilaian berdasarkan API dalam talian selalunya tidak boleh dihasilkan semula.
2. Automasi, perlindungan privasi dan kos rendah: Pengguna hanya perlu menggunakan model PandaLM secara tempatan dan memanggil arahan siap sedia untuk menilai pelbagai model besar, tanpa perlu mengekalkan real- masa seperti mengupah pakar Berkomunikasi dan bimbang tentang pelanggaran data. Pada masa yang sama, keseluruhan proses penilaian PandaLM tidak melibatkan sebarang yuran API atau kos buruh, yang sangat murah.
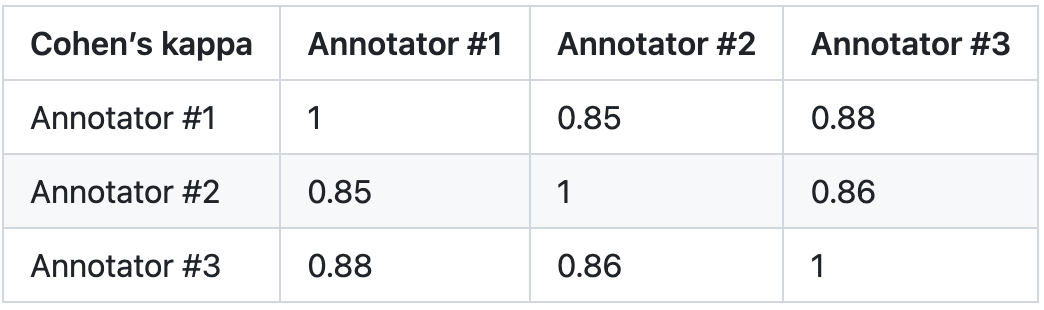
3. Tahap penilaian: Untuk mengesahkan kebolehpercayaan PandaLM, kajian ini mengupah tiga pakar untuk melengkapkan anotasi berulang secara bebas dan mencipta set ujian anotasi manual. Set ujian mengandungi 50 senario berbeza, setiap satu dengan pelbagai tugas. Set ujian ini pelbagai, boleh dipercayai dan konsisten dengan keutamaan manusia untuk teks. Setiap sampel dalam set ujian terdiri daripada arahan dan konteks, dan dua respons yang dihasilkan oleh model besar yang berbeza, dan kualiti kedua-dua respons dibandingkan oleh manusia.
Kajian ini menghapuskan sampel dengan perbezaan yang besar antara anotor untuk memastikan setiap IAA (Perjanjian Inter Annotator) pada set ujian akhir adalah hampir 0.85. Perlu diingatkan bahawa tiada pertindihan sama sekali antara set latihan PandaLM dan set ujian beranotasi manual yang dibuat dalam kajian ini.
Sampel yang ditapis ini memerlukan pengetahuan tambahan atau maklumat yang sukar diperoleh untuk membantu pertimbangan, yang menyukarkan manusia untuk Melabelkannya dengan tepat. Set ujian yang ditapis mengandungi 1000 sampel, manakala set ujian yang tidak ditapis asal mengandungi 2500 sampel. Taburan set ujian ialah {0:105, 1:422, 2:472}, dengan 0 menunjukkan bahawa kedua-dua respons mempunyai kualiti yang sama 1 menunjukkan bahawa respons 1 adalah lebih baik;
Berdasarkan set ujian manusia, perbandingan prestasi antara PandaLM dan gpt-3.5-turbo adalah seperti berikut:
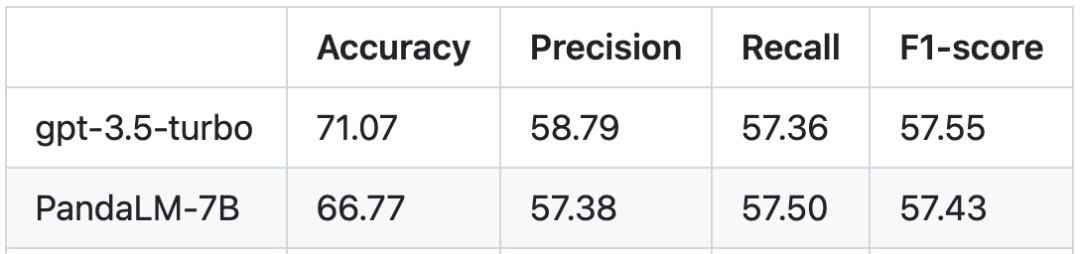
Dapat dilihat bahawa PandaLM-7B telah mencapai tahap gpt-3.5-turbo 94% dalam ketepatan, dan dari segi ketepatan, ingatan semula dan skor F1, PandaLM-7B telah melepasi gpt -3.5-turbo Tidak terlalu jauh di belakang. Boleh dikatakan PandaLM-7B sudah mempunyai keupayaan penilaian model yang besar setara dengan gpt-3.5-turbo.
Selain ketepatan, ketepatan, ingatan semula dan skor F1 pada set ujian, kajian ini juga menyediakan perbandingan antara 5 model sumber terbuka yang besar dengan hasil yang serupa. Kajian itu mula-mula menggunakan data latihan yang sama untuk memperhalusi lima model, dan kemudian menggunakan manusia, gpt-3.5-turbo, dan PandaLM untuk menjalankan perbandingan berpasangan bagi lima model. Tuple pertama (72, 28, 11) dalam baris pertama jadual di bawah menunjukkan bahawa terdapat 72 respons LLaMA-7B yang lebih baik daripada Bloom-7B, dan 28 respons LLaMA-7B yang lebih buruk daripada Bloom-7B Model tersebut mempunyai 11 respons dengan kualiti yang sama. Jadi dalam contoh ini, manusia berpendapat LLaMA-7B lebih baik daripada Bloom-7B. Keputusan dalam tiga jadual berikut menunjukkan bahawa manusia, gpt-3.5-turbo dan PandaLM-7B mempunyai pertimbangan yang konsisten sepenuhnya terhadap hubungan antara setiap model.
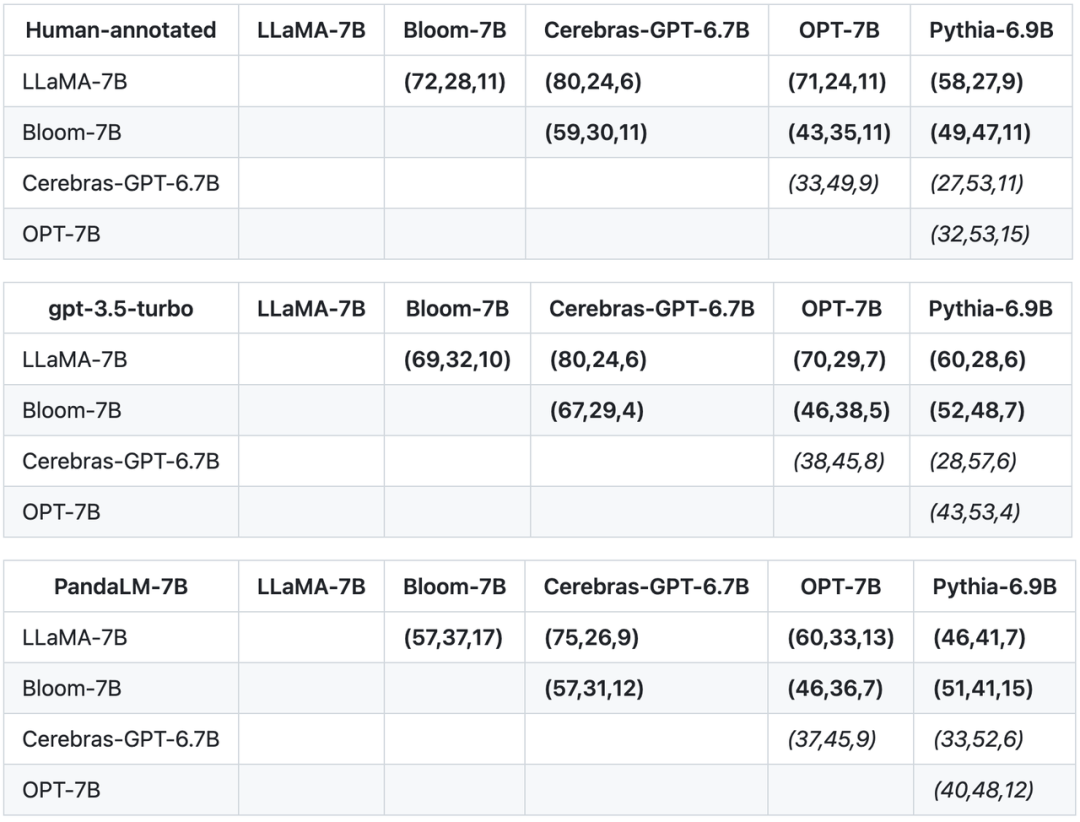
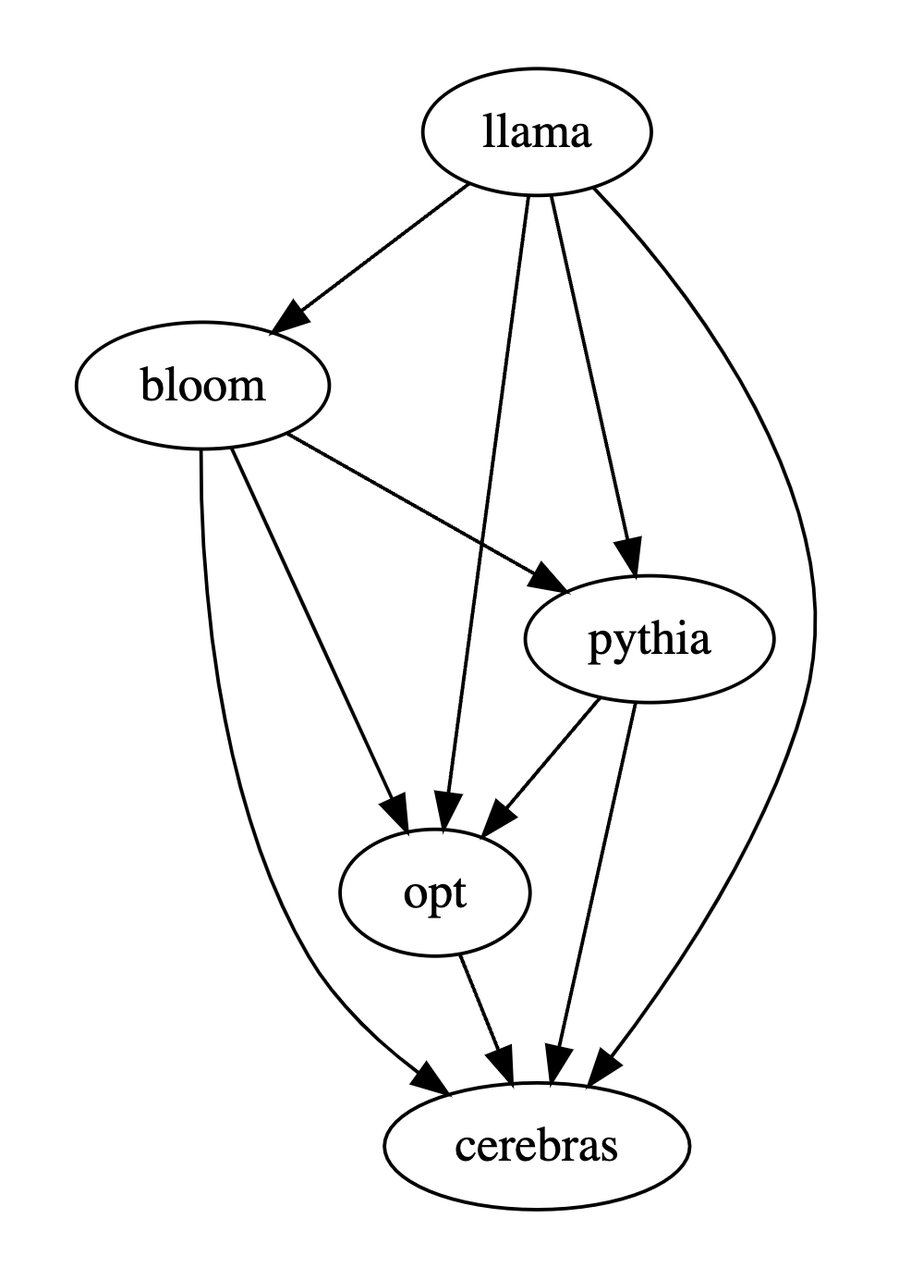
Berdasarkan tiga jadual di atas, kajian ini menghasilkan gambar rajah tertib separa tentang kelebihan dan kekurangan model. Gambar rajah pesanan separa ini terdiri daripada Perhubungan jumlah pesanan yang diperolehi, yang boleh dinyatakan sebagai: LLaMA-7B > Pythia-6.9B >
Ringkasan
Ringkasnya, PandaLM menyediakan sebagai tambahan kepada penilaian manual dan API A pihak ketiga pilihan ketiga untuk menilai model besar. Tahap penilaian PandaLM bukan sahaja tinggi, malah keputusannya boleh dihasilkan semula, proses penilaian sangat automatik, privasi dilindungi dan kosnya rendah. Pasukan penyelidik percaya bahawa PandaLM akan mempromosikan penyelidikan mengenai model berskala besar dalam akademik dan industri, dan membolehkan lebih ramai orang mendapat manfaat daripada kemajuan dalam bidang penyelidikan ini. Semua orang dialu-alukan untuk memberi perhatian kepada projek PandaLM Lebih banyak latihan, butiran ujian, artikel berkaitan dan kerja susulan akan diumumkan di laman web projek: https://github.com/WeOpenML/PandaLM
<.>Pengenalan kepada pasukan pengarang
Dalam pasukan pengarang, Wang Yidong* berasal dari Pusat Kejuruteraan Kebangsaan untuk Kejuruteraan Perisian Universiti Peking (PhD ) dan West Lake University (pembantu penyelidik), Yu Zhuohao* dan Zeng Zhengran , Jiang Chaoya, Xie Rui, Ye Wei† dan Zhang Shikun† adalah daripada Pusat Kejuruteraan Kebangsaan untuk Kejuruteraan Perisian di Universiti Peking, Yang Linyi, Wang Cunxiang dan Zhang Yue† berasal dari West Lake University, Heng Qiang dari North Carolina State University, dan Chen Hao dari Carnegie Mellon University , Jindong Wang dan Xie Xing dari Microsoft Research Asia. * menunjukkan pengarang bersama pertama, † menunjukkan pengarang sepadan bersama.
Atas ialah kandungan terperinci Penilaian boleh diterbitkan semula, automatik, kos rendah dan tahap tinggi, PandaLM, model besar pertama yang menilai model besar secara automatik, ada di sini. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI