
Rumah >Peranti teknologi >AI >Ringkasan kertas CVPR 2023! Bidang CV yang paling hangat dianugerahkan kepada model berbilang modal dan resapan
Ringkasan kertas CVPR 2023! Bidang CV yang paling hangat dianugerahkan kepada model berbilang modal dan resapan

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-25 15:10:351425semak imbas
CVPR tahunan akan dibuka secara rasmi di Vancouver, Kanada dari 18 hingga 22 Jun.
Setiap tahun, beribu-ribu penyelidik dan jurutera CV dari seluruh dunia berkumpul bersama untuk Sidang Kemuncak. Persidangan berprestij ini bermula pada tahun 1983 dan mewakili kemuncak pembangunan penglihatan komputer.
Pada masa ini, indeks h5 CVPR menduduki tempat keempat dalam kalangan semua persidangan atau penerbitan, kedua selepas Alam Semula Jadi, Sains dan New England Journal of Medicine.

Beberapa ketika dahulu, CVPR mengumumkan keputusan penerimaan kertas. Mengikut statistik di laman web rasmi, sejumlah 9,155 kertas diterima, 2,359 diterima, dan kadar penerimaan ialah 25.8%.
Selain itu, 12 kertas calon pemenang anugerah turut diumumkan.

Jadi, apakah kemuncak CVPR tahun ini? Apakah trend yang boleh kita lihat dalam bidang CV daripada kertas yang diterima?
akan diumumkan seterusnya.
Ikhtisar CVPR
Pemula Voxel51 menganalisis senarai semua kertas kerja yang diterima.
Mula-mula kita lihat rajah ringkasan tajuk kertas kerja Saiz setiap perkataan adalah berkadar dengan kekerapan kejadian dalam set data.

Penerangan ringkas
- 2359 artikel Kertas diterima (9155 kertas diserahkan)
- 1724 Arxiv kertas
- 68 kertas diserahkan ke alamat lain
Pengarang setiap kertas
- Purata pengarang kertas CVPR ialah kira-kira 5.4 orang
- Kertas yang mempunyai pengarang terbanyak ialah: "Mengapa pemenang adalah yang terbaik?"
Kategori Arxiv Utama
Antara kertas 1724 Arxiv, terdapat 1545, atau hampir 90% Kertas menyenaraikan cs.CV sebagai kategori utama.
cs.LG menduduki tempat kedua dengan 101 artikel. eess.IV (26) dan cs.RO (16) juga mendapat bahagian pai.
Kategori lain untuk kertas CVPR termasuk: cs.HC, cs.CV, cs.AR, cs.DC, cs.NE, cs.SD, cs.CL, cs.IT , cs.CR, cs.AI, cs.MM, cs.GR, eess.SP, eess.AS, math.OC, math.NT, fizik.data-an dan stat.ML.
Data "Meta"
- Dua perkataan "set data" dan "model" muncul bersama dalam Antara 567 abstrak. "Dataset" muncul bersendirian dalam 265 abstrak kertas, manakala "model" muncul sahaja 613 kali. Hanya 16.2% daripada kertas yang diterima oleh CVPR tidak mengandungi dua perkataan ini.
- Menurut abstrak kertas CVPR, set data paling popular tahun ini ialah ImageNet (105), COCO (94), KITTI (55) dan CIFAR (36).
- 28 kertas kerja mencadangkan "penanda aras" baharu.
Akronim berlimpah
Nampaknya tidak akan ada projek pembelajaran mesin tanpa akronim. Di antara 2,359 kertas, 1,487 mempunyai tajuk dengan pelbagai singkatan atau kata majmuk dalam huruf besar, menyumbang 63%.
Sesetengah daripada akronim ini mudah diingati malah boleh didengari:
- CLAMP: Pembelajaran Kontrastif berasaskan Prompt for Connecting Language and Animal PoseCLAMP
- PATS: Pengangkutan Kawasan Tampalan dengan Subbahagian untuk Padanan Ciri Setempat
- CIRCLE: Tangkap Dalam Persekitaran Kontekstual Kaya
Sesetengahnya jauh lebih kompleks:
- SIEDOB: Penyuntingan Imej Semantik dengan Membongkar Objek dan Latar Belakang
- FJMP : Berbilang Bersama Berfaktor -Ramalan Gerakan Agen ke atas Graf Interaksi Acyclic Terarah TerpelajarFJMP
Sesetengah daripada mereka nampaknya telah meminjam idea daripada orang lain mengenai pembinaan akronim:
- SCOTCH dan SODA: Rangka Kerja Pengesanan Bayangan Video Transformer (Scotch & Soda jenama popular Belanda)
- EXCALIBUR: Menggalakkan dan Menilai Penerokaan Terwujud (Ex Curry sticks, lol)
Apa yang paling hangat?
Selain tajuk kertas 2023, kami merangkak semua tajuk kertas yang diterima pada 2022. Daripada dua senarai ini, kami mengira kekerapan relatif pelbagai kata kunci untuk memberi anda pemahaman yang lebih mendalam tentang apa itu aliran menaik dan apakah itu aliran menurun.
Model
Pada tahun 2023, model resapan akan mendominasi.
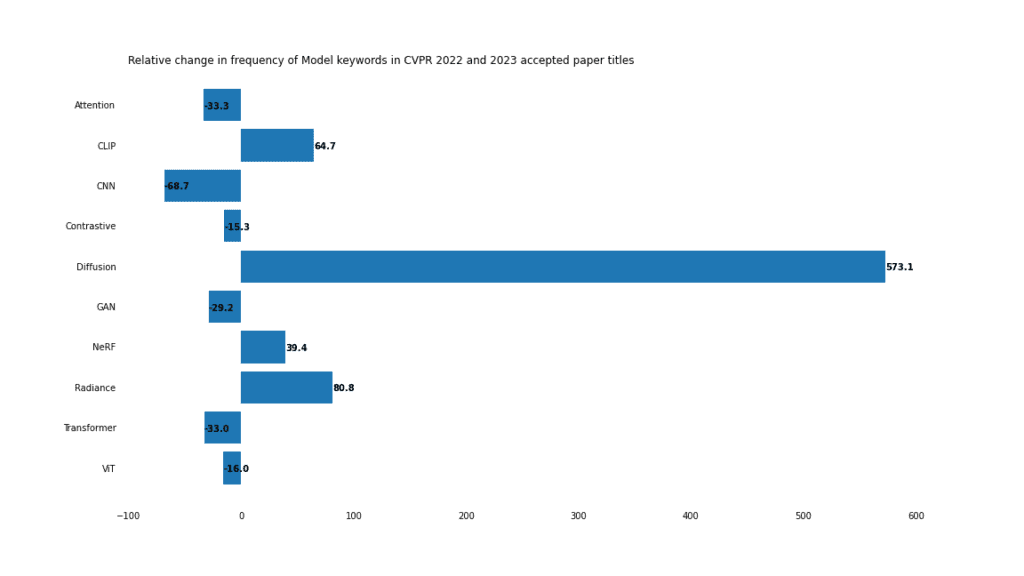
Model Resapan
Dengan Stabil Dengan populariti model penjanaan imej seperti Diffusion dan Midjourney, tidak hairanlah perkembangan model difusi menjadi trend hangat.
Model penyebaran juga mempunyai aplikasi dalam denoising, penyuntingan imej dan pemindahan gaya. Tambah semuanya, dan setakat ini ia merupakan pemenang terbesar merentas semua kategori, meningkat 573% tahun ke tahun.
Medan radiasi
Medan sinaran saraf (NERF) juga semakin popular, dan perkataan " "Radian" meningkat sebanyak 80%, dan "NERF" meningkat sebanyak 39%. NeRF telah beralih daripada pembuktian konsep kepada pengoptimuman proses pengeditan, aplikasi dan latihan.
Transformer
Penggunaan "Transformer" dan "ViT" yang semakin berkurangan tidak bermakna model Transformer adalah ketinggalan zaman, sebaliknya, ia mencerminkan dominasi model ini pada tahun 2022. Pada tahun 2021, perkataan "Transformer" hanya muncul dalam 37 kertas kerja. Pada 2022, jumlah ini akan meningkat kepada 201. Transformer tidak akan hilang dalam masa terdekat.
CNN
CNN pernah menjadi kegemaran visi komputer Menjelang 2023, nampaknya mereka telah kalah kelebihan mereka. Penggunaan menurun sebanyak 68%. Banyak tajuk utama menyebut CNN juga menyebut model lain. Sebagai contoh, makalah ini menyebut CNN dan Transformer:
- Lite-Mono: A Lightweight CNN and Transformer Architecture for Self-Supervised Monocular Depth EstimationLite-Mono
- Mempelajari Pemampatan Imej dengan Senibina Campuran Transformer-CNN
Tugas
Tugas topeng dan pemodelan imej topeng digabungkan , menduduki dominan jawatan dalam CVPR.
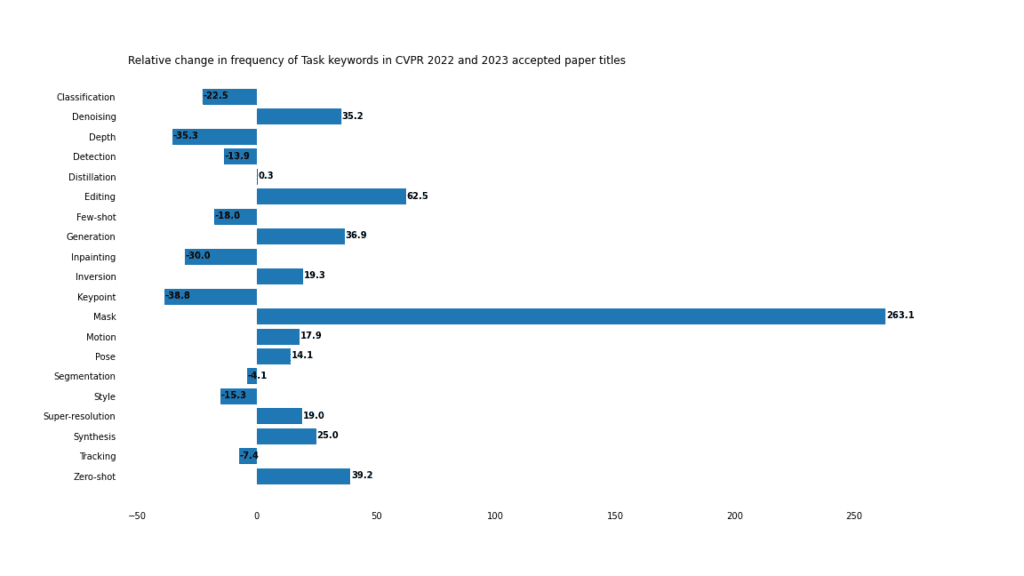
Jana
Tugas diskriminatif tradisional seperti pengesanan, pengelasan dan segmentasi tidak digemari, tetapi bahagian mereka dalam CV semakin mengecil disebabkan oleh beberapa siri kemajuan dalam aplikasi generatif, termasuk "editing", "sintesis" dan " generasi" Kebangkitan membuktikan ini.
Topeng
Kata kunci "topeng" meningkat sebanyak 263% berbanding tempoh yang sama tahun lepas dan diterima dalam 2023 muncul 92 kali dalam kertas dan kadangkala 2 kali dalam tajuk.
- SIM: Penjanaan Topeng Instance Semantik untuk Segmentasi Instance Diselia KotakSIM
- DynaMask: Pemilihan Topeng Dinamik untuk Segmentasi Instance
Tetapi majoriti (64%) sebenarnya merujuk kepada tugasan "topeng", termasuk 8 tugasan "pemodelan imej topeng" dan 15 "pengekod auto topeng". Di samping itu, "topeng" muncul dalam 8 artikel.
Perlu juga diperhatikan bahawa 3 tajuk kertas dengan perkataan "topeng" sebenarnya merujuk kepada tugas "tiada topeng".
Sampel sifar vs sampel kecil
Dengan peningkatan pembelajaran pemindahan, kaedah generatif, pembayang dan model umum, Pembelajaran "sifar pukulan" semakin menarik. Pada masa yang sama, pembelajaran "sampel kecil" telah menurun berbanding tahun lepas. Walau bagaimanapun, dari segi nombor mentah, sekurang-kurangnya buat masa ini, "sampel kecil" (45) mempunyai sedikit kelebihan berbanding "sampel sifar" (35).
Modal
Pada tahun 2023, pembangunan aplikasi multi-modal dan cross-modal akan dipercepatkan.
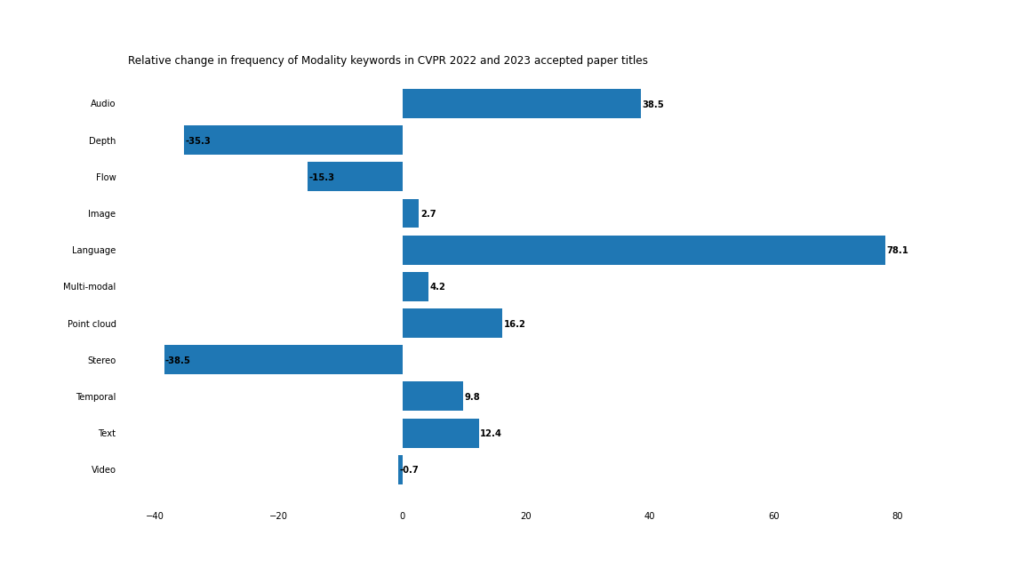
Sempadan kabur
Walaupun komputer tradisional Kekerapan kata kunci visual seperti "imej" dan "video" kekal secara relatifnya tidak berubah, tetapi "teks"/"bahasa" dan "audio" muncul lebih kerap.
Walaupun perkataan "multimodal" itu sendiri tidak muncul dalam tajuk kertas kerja, adalah sukar untuk menafikan bahawa visi komputer sedang menuju ke arah masa depan multimodal.
Ini amat jelas dalam tugas visual-verbal, seperti yang ditunjukkan oleh peningkatan mendadak dalam Terbuka, Cepat dan Perbendaharaan Kata.
Contoh paling ekstrem bagi situasi ini ialah kata majmuk "perbendaharaan kata terbuka", yang hanya muncul 3 kali pada 2022, tetapi 18 kali pada 2023.
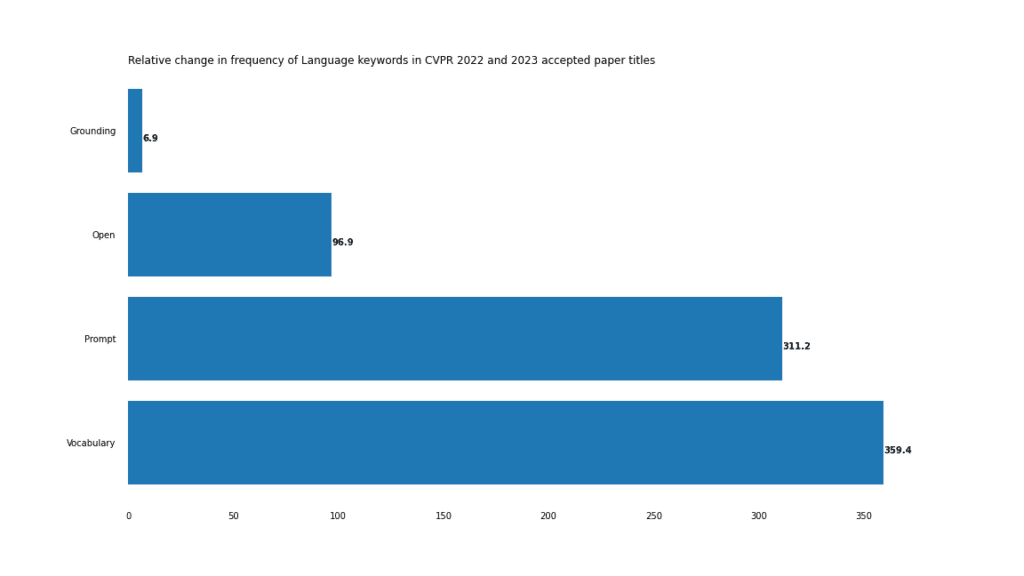
Teliti kata kunci dalam tajuk kertas CVPR 2023
Point Cloud 9
Aplikasi penglihatan komputer tiga dimensi sedang beralih daripada membuat kesimpulan maklumat 3D ("kedalaman" dan "stereoskopik") daripada imej dua dimensi kepada membuat kesimpulan terus Data awan titik 3D Sistem penglihatan komputer yang melakukan kerja.
Kreativiti dalam Tajuk CVSebarang liputan komprehensif tentang topik berkaitan pembelajaran mesin pada tahun 2023 tidak akan lengkap tanpa memasukkan ChatGPT ke dalam campuran. Kami memutuskan untuk mengekalkan perkara yang menarik dan menggunakan ChatGPT untuk mencari tajuk berita paling kreatif daripada CVPR 2023.
Untuk setiap kertas yang dimuat naik ke Arxiv, kami mengikis abstrak dan meminta ChatGPT (GPT-3.5 API) menjana tajuk untuk kertas CVPR yang sepadan.
Kemudian, kami menggabungkan tajuk yang dijana oleh ChatGPT dan tajuk kertas sebenar, menggunakan model text-embedding-ada-002 OpenAI untuk menjana vektor benam, dan mengira jumlah tajuk yang dihasilkan oleh ChatGPT Cosine persamaan antara tajuk yang dijana oleh pengarang.
Apakah perkara ini boleh memberitahu kita? Lebih dekat ChatGPT dengan tajuk kertas sebenar, lebih mudah diramal tajuk itu. Dengan kata lain, semakin "berat sebelah" ramalan ChatGPT, semakin "kreatif" pengarang dalam menamakan kertas tersebut.
Pembenaman dan persamaan kosinus memberikan kita kaedah kuantifikasi yang menarik, walaupun jauh dari sempurna.
Kami mengisih kertas mengikut metrik ini. Tanpa berlengah lagi, berikut adalah tajuk yang paling kreatif:
Tajuk sebenar: Menjejaki Setiap Benda di Alam Liar
Tajuk Ramalan : Mengurai Klasifikasi daripada Penjejakan: Memperkenalkan TETA untuk Penanda Aras Komprehensif Penjejakan Berbilang Objek Berbilang Kategori
Tajuk sebenar: Belajar Bootstrap untuk Melawan Kebisingan Label
Tajuk Ramalan : Objektif Kehilangan Boleh Dipelajari untuk Instance Bersama dan Pemberat Semula Label dalam Rangkaian Neural Dalam
Tajuk sebenar: Melihat Mawar dalam Lima Ribu Cara
Tajuk yang diramalkan : Intrinsik Objek Pembelajaran daripada Imej Internet Tunggal untuk Rendering dan Sintesis Visual Unggul
Tajuk sebenar: Mengapa pemenang adalah yang terbaik?
Tajuk yang diramalkan : Menganalisis Strategi Kemenangan dalam Pertandingan Penandaarasan Antarabangsa untuk Analisis Imej: Pandangan daripada Kajian Pelbagai Pusat IEEE ISBI dan MICCAI 2021
Atas ialah kandungan terperinci Ringkasan kertas CVPR 2023! Bidang CV yang paling hangat dianugerahkan kepada model berbilang modal dan resapan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI