
Rumah >Peranti teknologi >AI >Apakah klasifikasi teks?
Apakah klasifikasi teks?

- PHPzke hadapan
- 2023-05-23 21:16:041981semak imbas
Penterjemah |. Li Rui
Penilai |.
Pengkelasan teks ialah proses mengklasifikasikan teks kepada satu atau lebih kategori berbeza untuk menyusun, menstruktur dan menapis ke dalam mana-mana parameter. Contohnya, klasifikasi teks digunakan dalam dokumen undang-undang, kajian perubatan dan dokumen, atau hanya dalam ulasan produk. Data adalah lebih penting daripada sebelumnya; banyak perniagaan membelanjakan sejumlah besar wang untuk mendapatkan cerapan sebanyak mungkin.
Dengan data teks/dokumen menjadi lebih kaya daripada jenis data lain, menggunakan kaedah baharu adalah penting. Memandangkan data sememangnya tidak berstruktur dan sangat kaya, menyusunnya dengan cara yang mudah difahami untuk memahaminya boleh meningkatkan nilainya dengan ketara. Gunakan klasifikasi teks dan pembelajaran mesin untuk membina teks yang berkaitan secara automatik dengan lebih pantas dan lebih menjimatkan kos. Yang berikut akan mentakrifkan klasifikasi teks, cara ia berfungsi, beberapa algoritma yang paling terkenal dan menyediakan set data yang mungkin berguna untuk memulakan perjalanan pengelasan teks anda. Mengapa menggunakan pembelajaran mesin untuk pengelasan teks?Skala: Kemasukan data manual, analisis dan penyusunan adalah membosankan dan perlahan. Pembelajaran mesin membenarkan analisis automatik tanpa mengira saiz set data.
- Ketekalan: Kesilapan manusia berlaku disebabkan oleh keletihan dan ketidakpekaan manusia terhadap bahan dalam set data. Pembelajaran mesin meningkatkan kebolehskalaan dan meningkatkan ketepatan dengan ketara disebabkan sifat algoritma yang tidak berat sebelah dan konsisten.
- Kelajuan: Mungkin ada kalanya anda perlu mengakses dan mengatur data dengan cepat. Algoritma pembelajaran mesin boleh menghuraikan data dan menyampaikan maklumat dengan cara yang mudah difahami.
- 6 langkah umum
Sesetengah kaedah asas boleh mengklasifikasikan dokumen teks yang berbeza pada tahap tertentu, tetapi kaedah yang paling biasa digunakan ialah Pembelajaran mesin. Model pengelasan teks melalui enam langkah asas sebelum ia boleh digunakan. 
Teg perkataan: Lebih Pintar
- Teg subkata: Smart-er
- Teg aksara: S-m-a-r-t-e-r
- Mengapa tokenisasi penting? Kerana model klasifikasi teks hanya boleh memproses data pada tahap berasaskan token dan tidak dapat memahami serta memproses ayat yang lengkap. Model ini memerlukan pemprosesan lanjut set data mentah yang diberikan untuk mencerna data yang diberikan dengan mudah. Alih keluar ciri yang tidak perlu, tapis nilai nol dan tak terhingga, dan banyak lagi. Menyusun semula keseluruhan set data akan membantu mengelakkan sebarang berat sebelah semasa fasa latihan.
- Word2Vec: Ini ialah kaedah pembenaman perkataan tanpa pengawasan yang dibangunkan oleh Google. Ia menggunakan rangkaian saraf untuk belajar daripada set data teks yang besar. Seperti namanya, kaedah Word2Vec menukar setiap perkataan menjadi vektor tertentu.
- Sarung Tangan: Juga dikenali sebagai vektor global, ia ialah model pembelajaran mesin tanpa pengawasan yang digunakan untuk mendapatkan perwakilan vektor bagi perkataan. Sama seperti kaedah Word2Vec, algoritma GloVe memetakan perkataan ke dalam ruang yang bermakna, di mana jarak antara perkataan berkaitan dengan persamaan semantik.
- TF-IDF: TF-IDF ialah singkatan bagi Term Frequency-Inverse Text Frequency, iaitu algoritma pembenaman perkataan yang digunakan untuk menilai kepentingan perkataan dalam dokumen tertentu. TF-IDF memberikan setiap perkataan skor yang diberikan untuk mewakili kepentingannya dalam satu set dokumen.
Algoritma Pengelasan Teks
Berikut ialah tiga daripada algoritma pengelasan teks yang paling terkenal dan berkesan. Adalah penting untuk diingat bahawa terdapat algoritma yang ditakrifkan lebih lanjut tertanam dalam setiap kaedah.
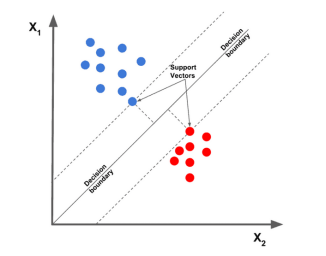
1. Mesin Vektor Sokongan Linear
Algoritma mesin vektor sokongan linear dianggap sebagai salah satu algoritma pengelasan teks terbaik pada masa ini. Ia melukis titik data yang diberikan mengikut ciri yang diberikan, dan kemudian Lukiskan garisan yang paling sesuai yang membahagi dan mengisih data ke dalam kategori.
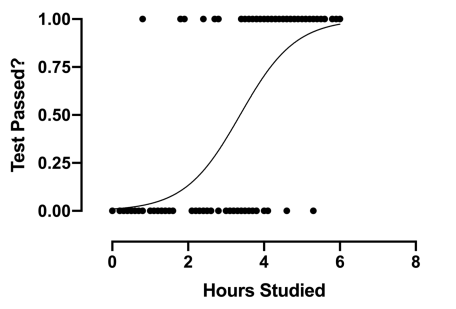
2. Regresi logistik
Regresi logistik ialah subkategori regresi, terutamanya memfokuskan pada masalah klasifikasi. Ia menggunakan sempadan keputusan, regresi, dan jarak untuk menilai dan mengklasifikasikan set data.
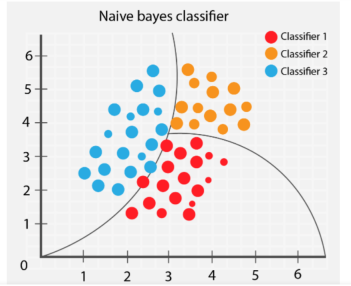
3. Naive Bayes
Algoritma Naive Bayes mengelaskan objek berbeza berdasarkan ciri yang disediakan oleh objek. Sempadan kumpulan kemudiannya dilukis untuk membuat kesimpulan klasifikasi kumpulan ini untuk penyelesaian dan pengelasan selanjutnya.
Apakah isu yang harus dielakkan semasa menyediakan klasifikasi teks
1 Data latihan yang terlalu sesak
Menyediakan data berkualiti rendah kepada algoritma akan membawa kepada ramalan masa depan yang buruk. Masalah biasa bagi pengamal pembelajaran mesin ialah model latihan diberi terlalu banyak set data dan termasuk ciri yang tidak diperlukan. Penggunaan data yang tidak berkaitan secara berlebihan akan menyebabkan penurunan prestasi model. Dan apabila ia datang untuk memilih dan mengatur set data, lebih sedikit adalah lebih.
Nisbah latihan yang salah untuk menguji data boleh menjejaskan prestasi model dan menjejaskan kocok dan penapisan data. Titik data yang tepat tidak akan diganggu oleh faktor lain yang tidak diingini, dan model terlatih akan berprestasi lebih cekap.
Apabila melatih model, pilih set data yang memenuhi keperluan model, tapis nilai yang tidak diperlukan, kocok set data dan uji ketepatan model akhir. Algoritma yang lebih mudah memerlukan lebih sedikit masa dan sumber pengkomputeran, dan model terbaik adalah yang paling mudah yang boleh menyelesaikan masalah yang kompleks.
2. Overfitting dan underfitting
Apabila latihan mencapai kemuncaknya, ketepatan model secara beransur-ansur berkurangan apabila latihan diteruskan. Ini dipanggil overfitting; kerana latihan berlangsung terlalu lama, model mula mempelajari corak yang tidak dijangka. Berhati-hati apabila mencapai ketepatan tinggi pada set latihan, kerana matlamat utamanya adalah untuk membangunkan model yang ketepatannya berakar umbi dalam set ujian (data model tidak pernah dilihat sebelum ini).
Sebaliknya, underfitting bermakna model terlatih masih mempunyai ruang untuk diperbaiki dan belum mencapai potensi maksimumnya. Model yang kurang terlatih berpunca daripada tempoh latihan atau terlalu mengatur set data. Ini menunjukkan maksud mempunyai data yang ringkas dan tepat.
Mencari titik manis adalah penting apabila melatih model. Memisahkan set data 80/20 ialah permulaan yang baik, tetapi melaraskan parameter mungkin merupakan perkara yang perlu dilakukan oleh model tertentu secara optimum.
3. Format teks yang salah
Walaupun tidak dinyatakan secara terperinci dalam artikel ini, menggunakan format teks yang betul untuk masalah pengelasan teks akan menghasilkan hasil yang lebih baik. Beberapa kaedah untuk mewakili data teks termasuk GloVe, Word2Vec dan model benam.
Menggunakan format teks yang betul akan memperbaik cara model membaca dan mentafsir set data, yang seterusnya membantu model itu memahami corak.
Aplikasi Pengelasan Teks

- Tapis spam: Dengan mencari kata kunci tertentu, e-mel boleh diklasifikasikan sebagai berguna atau spam.
- Klasifikasi Teks: Dengan menggunakan pengelasan teks, aplikasi boleh mengklasifikasikan item yang berbeza (artikel dan buku, dll.) ke dalam kategori yang berbeza dengan mengkategorikan teks yang berkaitan (seperti nama item dan huraian, dll.). Menggunakan teknik ini meningkatkan pengalaman kerana ia memudahkan pengguna menavigasi dalam pangkalan data.
- Mengenal pasti Ucapan Kebencian: Sesetengah syarikat media sosial menggunakan klasifikasi teks untuk mengesan dan melarang ulasan atau siaran yang menyinggung perasaan.
- Pemasaran dan Pengiklanan: Perniagaan boleh membuat perubahan khusus untuk memuaskan hati pelanggan mereka dengan memahami cara pengguna bertindak balas terhadap produk tertentu. Ia juga boleh mengesyorkan produk tertentu berdasarkan ulasan pengguna produk serupa. Algoritma pengelasan teks boleh digunakan bersama dengan sistem pengesyor, satu lagi algoritma pembelajaran mendalam yang digunakan oleh banyak tapak web dalam talian untuk mendapatkan perniagaan berulang.
Set data pengelasan teks popular
Dengan sejumlah besar set data berlabel dan sedia untuk digunakan, anda boleh mencari set data sempurna yang memenuhi keperluan model anda pada bila-bila masa.
Walaupun anda mungkin menghadapi beberapa masalah untuk memutuskan yang mana satu untuk digunakan, beberapa set data paling terkenal yang tersedia kepada orang ramai disyorkan di bawah.
- ImDB Dataset
- Amazon Reviews Dataset
- Yelp Reviews Dataset
- SMS Spam Collection
- Opin Rank Review Dataset
- Set Data Sentimen Syarikat Penerbangan AS Twitter
- Set Data Ucapan Kebencian dan Bahasa Menyinggung
- Set Data Clickbait
Tapak web seperti Kaggle mengandungi pelbagai set data yang merangkumi semua topik . Anda boleh cuba menjalankan model pada beberapa set data di atas untuk latihan.
Klasifikasi Teks dalam Pembelajaran Mesin
Memandangkan pembelajaran mesin telah memberi impak yang besar dalam dekad yang lalu, perusahaan sedang mencuba setiap cara yang mungkin untuk memanfaatkan pembelajaran mesin untuk mengautomasikan proses. Ulasan, catatan, artikel, jurnal dan dokumen semuanya tidak ternilai dalam teks. Dan dengan menggunakan klasifikasi teks dalam pelbagai cara kreatif untuk mengekstrak cerapan dan corak pengguna, perniagaan boleh membuat keputusan bersandarkan data, profesional boleh mengakses dan mempelajari maklumat berharga lebih cepat daripada sebelumnya.
Tajuk asal: Apakah Pengelasan Teks?, pengarang: Kevin Vu
Atas ialah kandungan terperinci Apakah klasifikasi teks?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI