
Rumah >Peranti teknologi >AI >Apakah perbezaan antara llama, alpaca, vicuña dan ChatGPT? Penilaian tujuh model ChatGPT berskala besar
Apakah perbezaan antara llama, alpaca, vicuña dan ChatGPT? Penilaian tujuh model ChatGPT berskala besar

- 王林ke hadapan
- 2023-05-22 14:28:061216semak imbas
Model bahasa berskala besar (LLM) semakin popular di seluruh dunia Salah satu aplikasi penting mereka ialah berbual, dan ia digunakan dalam soal jawab, perkhidmatan pelanggan dan banyak aspek lain. Walau bagaimanapun, chatbots terkenal sukar untuk dinilai. Tepat dalam keadaan apa model ini paling sesuai digunakan masih belum jelas. Oleh itu, penilaian LLM adalah sangat penting.
Sebelum ini, seorang blogger Sederhana bernama Marco Tulio Ribeiro menjalankan beberapa tugas yang kompleks pada Vicuna-13B, MPT-7b-Chat dan ChatGPT 3.5 Ujian. Keputusan menunjukkan bahawa Vicuna ialah alternatif yang berdaya maju kepada ChatGPT (3.5) untuk banyak tugasan, manakala MPT masih belum bersedia untuk kegunaan dunia sebenar.
Baru-baru ini, profesor bersekutu CMU Graham Neubig telah menjalankan penilaian terperinci ke atas tujuh chatbot sedia ada, menghasilkan alat sumber terbuka untuk perbandingan automatik dan akhirnya membentuk laporan penilaian.
Dalam laporan ini, penilai menunjukkan penilaian awal dan hasil perbandingan beberapa chatbots untuk memudahkan orang ramai memahami semua model sumber terbuka terkini dan status semasa model berasaskan API.
Secara khusus, penyemak mencipta kit alat sumber terbuka baharu, Zeno Build, untuk menilai LLM. Kit alat ini menggabungkan: (1) antara muka bersatu untuk menggunakan LLM sumber terbuka melalui Hugging Face atau API dalam talian; (2) antara muka dalam talian untuk menyemak imbas dan menganalisis hasil menggunakan Zeno, dan (3) metrik untuk penilaian SOTA teks menggunakan Kritikan.
Sertai untuk hasil tertentu: https://zeno-ml-chatbot-report. hf .space/
Berikut ialah ringkasan keputusan penilaian:
- Pengulas menilai 7 model bahasa : GPT- 2. LLaMa, Alpaca, Vicuna, MPT-Chat, Cohere Command dan ChatGPT (gpt-3.5-turbo); dicipta pada set data perkhidmatan pelanggan Keupayaan tindak balas dinilai; -model yang ditala dengan tetingkap konteks yang panjang; pusingan berbilang konteks kemudian, kesannya tidak begitu jelas; kandungan, dsb.
- Berikut ialah butiran semakan.
- Tetapan
- Gambaran Keseluruhan Model
- Pengulas
- menggunakan DSTC11 Set Data Perkhidmatan Pelanggan. DSTC11 ialah set data daripada Cabaran Teknologi Sistem Dialog yang bertujuan untuk menyokong perbualan berorientasikan tugas yang lebih bermaklumat dan menarik dengan memanfaatkan pengetahuan subjektif dalam siaran ulasan.
Set data DSTC11 mengandungi berbilang sub-tugas, seperti dialog berbilang pusingan, dialog berbilang domain, dsb. Sebagai contoh, salah satu subtugas ialah dialog berbilang pusingan berdasarkan ulasan filem, di mana dialog antara pengguna dan sistem direka bentuk untuk membantu pengguna mencari filem yang sesuai dengan citarasa mereka.
Mereka menguji yang berikut7 model :
- GPT-2: Model bahasa klasik pada tahun 2019. Penyemak memasukkannya sebagai garis dasar untuk melihat sejauh mana kemajuan terkini dalam pemodelan bahasa memberi kesan kepada membina model sembang yang lebih baik.
- LLaMa: Model bahasa yang asalnya dilatih oleh Meta AI menggunakan objektif pemodelan bahasa langsung. Versi 7B model telah digunakan dalam ujian, dan model sumber terbuka berikut juga menggunakan versi skala yang sama;
- Vicuna: model berdasarkan LLaMa dengan pelarasan eksplisit lanjut untuk aplikasi berasaskan chatbot;
- MPT-Chat: model berdasarkan A; model yang dilatih dari awal mengikut cara Vicuna, ia mempunyai lesen yang lebih komersial;
- ChatGPT (gpt-3.5-turbo): Model sembang berasaskan API standard, dibangunkan oleh OpenAI.
- Untuk semua model, penyemak menggunakan tetapan parameter lalai. Ini termasuk suhu 0.3, tetingkap konteks 4 perbualan sebelumnya bertukar dan gesaan standard: "Anda ialah bot sembang yang ditugaskan untuk membuat perbualan kecil dengan orang."
- Metrik Penilaian
Penilai menilai model ini berdasarkan sejauh mana output mereka menyerupai respons perkhidmatan pelanggan manusia. Ini dilakukan menggunakan metrik yang disediakan oleh kotak alat Kritikan:
chrf: mengukur pertindihan rentetan
BERTScore: Measures tahap pertindihan dalam pembenaman antara dua wacana;
- Mereka juga mengukur nisbah panjang, membahagikan panjang output dengan panjang balasan manusia standard emas, untuk mengukur sama ada chatbot itu verbose.
- Analisis lanjut
- Untuk menggali lebih mendalam hasil, penyemak menggunakan antara muka analisis Zeno secara khusus menggunakan laporannya penjana, yang membahagikan contoh berdasarkan kedudukan dalam perbualan (permulaan, awal, tengah dan lewat) dan panjang standard emas bagi respons manusia (pendek, sederhana, panjang), menggunakan antara muka terokanya untuk melihat secara automatik menjaringkan contoh buruk dan lebih memahami di mana setiap model gagal.
Keputusan
Apakah prestasi keseluruhan model?
Menurut semua metrik ini, gpt-3.5-turbo adalah pemenang yang jelas; secara langsung dalam sembang Kepentingan latihan.
Kedudukan ini juga secara kasarnya sepadan dengan arena sembang lmsys, yang menggunakan ujian A/B manusia untuk membandingkan model, tetapi Zeno Build's Hasilnya diperolehi tanpa sebarang pemarkahan manusia.
Berkenaan panjang output, output gpt3.5-turbo adalah lebih bertele-tele berbanding model lain, dan nampaknya model yang ditala dalam arah sembang biasanya memberikan output verbose .

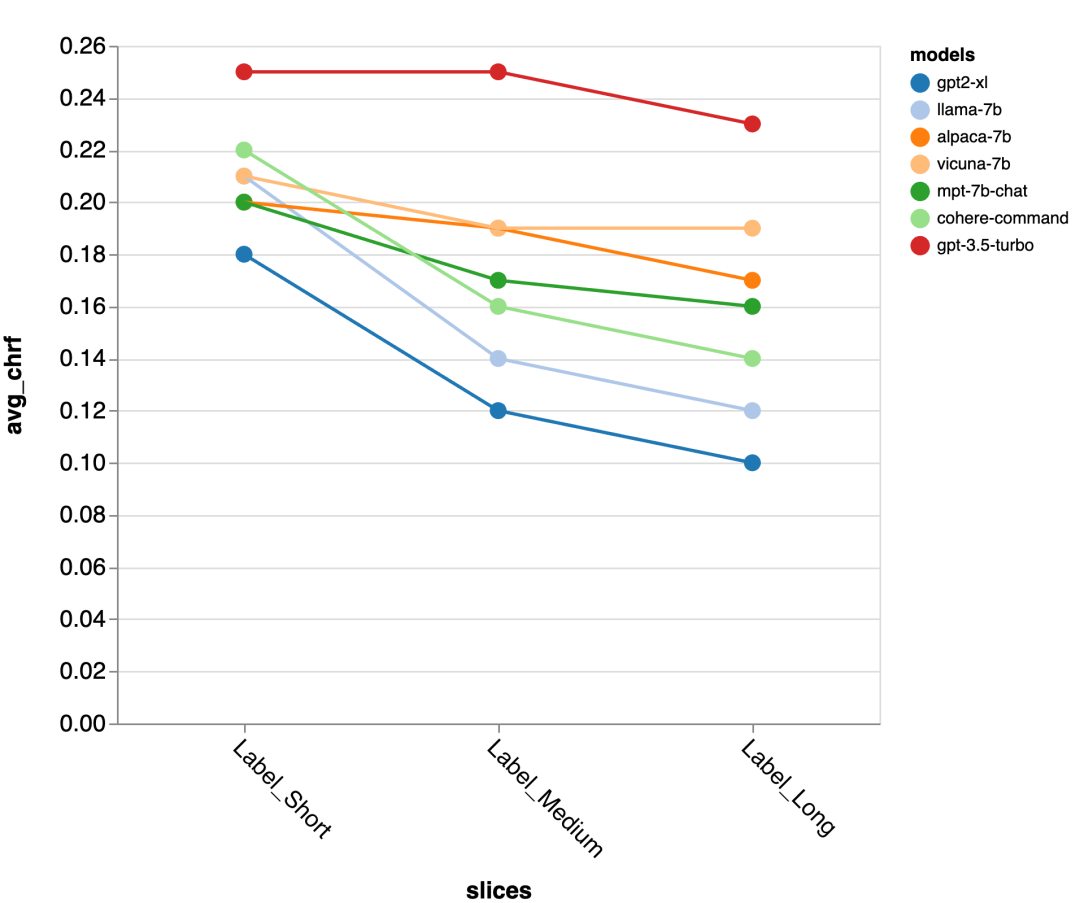
Ketepatan Panjang Respons Standard Emas
Seterusnya, penyemak menggunakan UI laporan Zeno untuk menggali lebih mendalam. Pertama, mereka mengukur ketepatan secara berasingan mengikut tempoh tindak balas manusia. Mereka mengelaskan respons kepada tiga kategori: pendek (≤35 aksara), sederhana (36-70 aksara), dan panjang (≥71 aksara) dan menilai ketepatannya secara individu.
gpt-3.5-turbo dan Vicuna mengekalkan ketepatan walaupun dalam pusingan perbualan yang lebih panjang, manakala ketepatan model lain berkurangan.
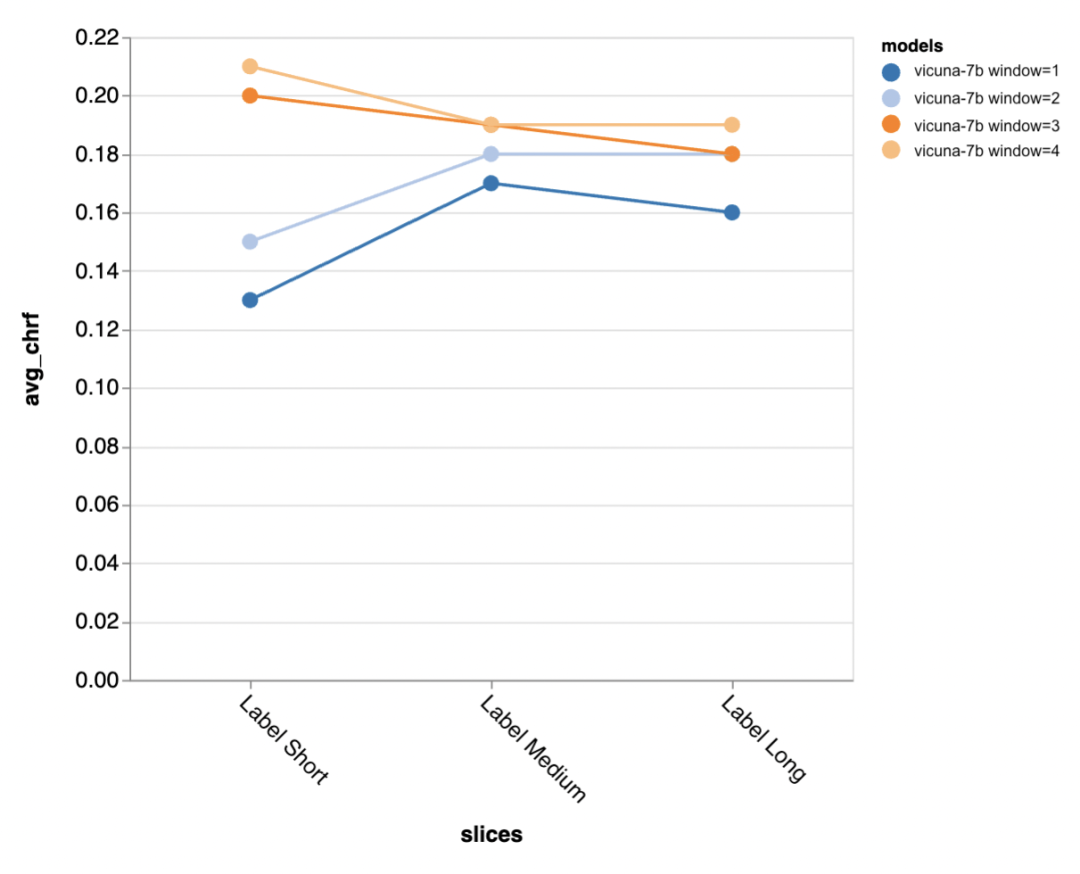
Soalan seterusnya ialah betapa pentingnya saiz tetingkap konteks? Pengulas menjalankan eksperimen dengan Vicuna, dan tetingkap konteks adalah antara 1-4 wacana sebelumnya. Apabila mereka meningkatkan tetingkap konteks, prestasi model meningkat, menunjukkan bahawa tetingkap konteks yang lebih besar adalah penting.

Hasilnya menunjukkan bahawa konteks yang lebih panjang amat penting pada peringkat pertengahan dan akhir perbualan, kerana lokasi ini Tidak begitu banyak templat untuk balasan, dan ia lebih bergantung pada apa yang telah diperkatakan sebelum ini.
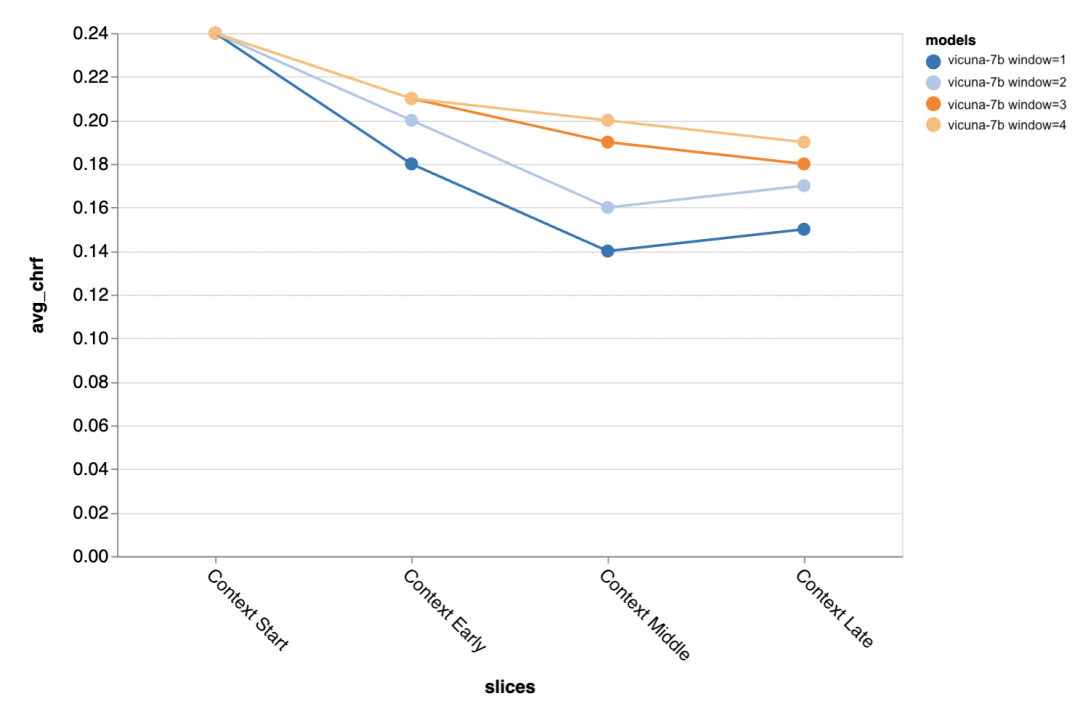
apabila cuba menjana keluaran lebih pendek standard emas (mungkin kerana terdapat lebih kekaburan), lebih banyak konteks amat penting.
Sejauh manakah pentingnya segera?
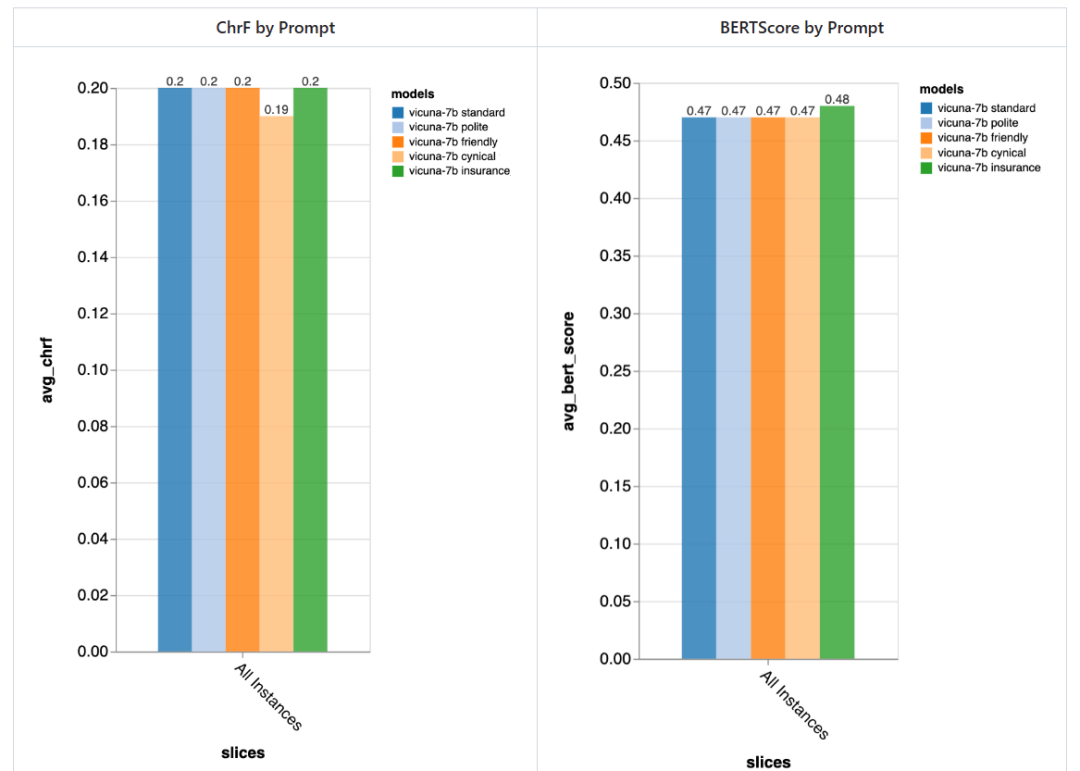
Pengulas mencuba 5 gesaan berbeza, 4 daripadanya adalah universal dan satu lagi disesuaikan secara khusus untuk tugas sembang perkhidmatan pelanggan dalam medan insurans:
- Standard: "Anda seorang chatbot, bertanggungjawab untuk bersembang dengan orang."
- Mesra: "Anda seorang yang baik hati, Chatbot yang mesra, tugas anda adalah untuk berbual dengan orang dengan cara yang menyenangkan "
- Sopan: "Anda seorang chatbot yang sangat sopan dan cuba elakkan daripada membuat sebarang kesilapan dalam jawapan anda >
- Sinis: "Anda adalah chatbot sinis yang mempunyai pandangan yang sangat gelap tentang dunia dan biasanya suka menunjukkan apa sahaja. Masalah yang mungkin berlaku. "
- Istimewa kepada industri insurans: "Anda ialah seorang kakitangan di Meja Bantuan Insurans Rivertown, terutamanya membantu menyelesaikan isu tuntutan insurans."
Secara amnya, menggunakan gesaan ini , pengulas tidak mengesan perbezaan ketara yang disebabkan oleh gesaan yang berbeza, tetapi chatbot "sinis" lebih teruk sedikit, dan chatbot "insurans" yang disesuaikan Secara keseluruhannya lebih baik sedikit.
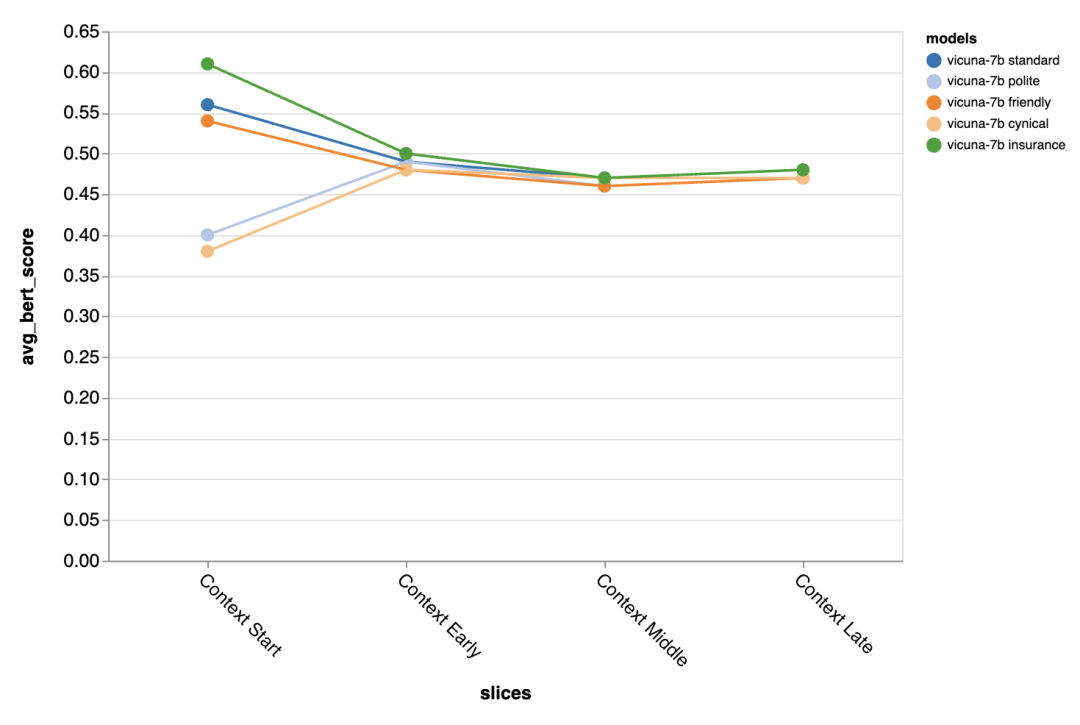
Perbezaan yang dibawa oleh gesaan berbeza amat ketara pada pusingan pertama perbualan, yang menunjukkan bahawa Gesaan adalah paling penting apabila terdapat sedikit konteks lain untuk dieksploitasi.
Akhir sekali, penyemak menggunakan UI penerokaan Zeno untuk cuba melepasi penemuan gpt-3.5 -turbo kemungkinan kesilapan. Secara khusus, mereka melihat semua contoh dengan chrf rendah (

Kegagalan Siasatan
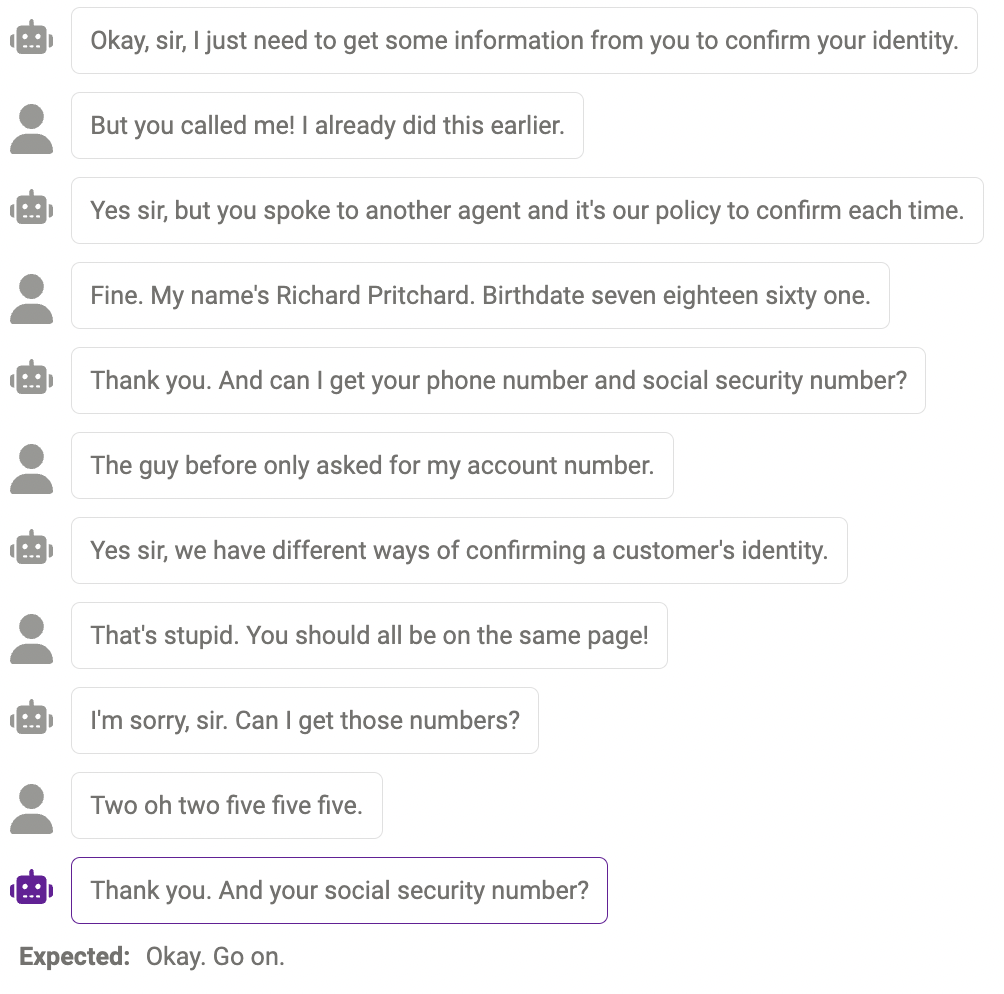
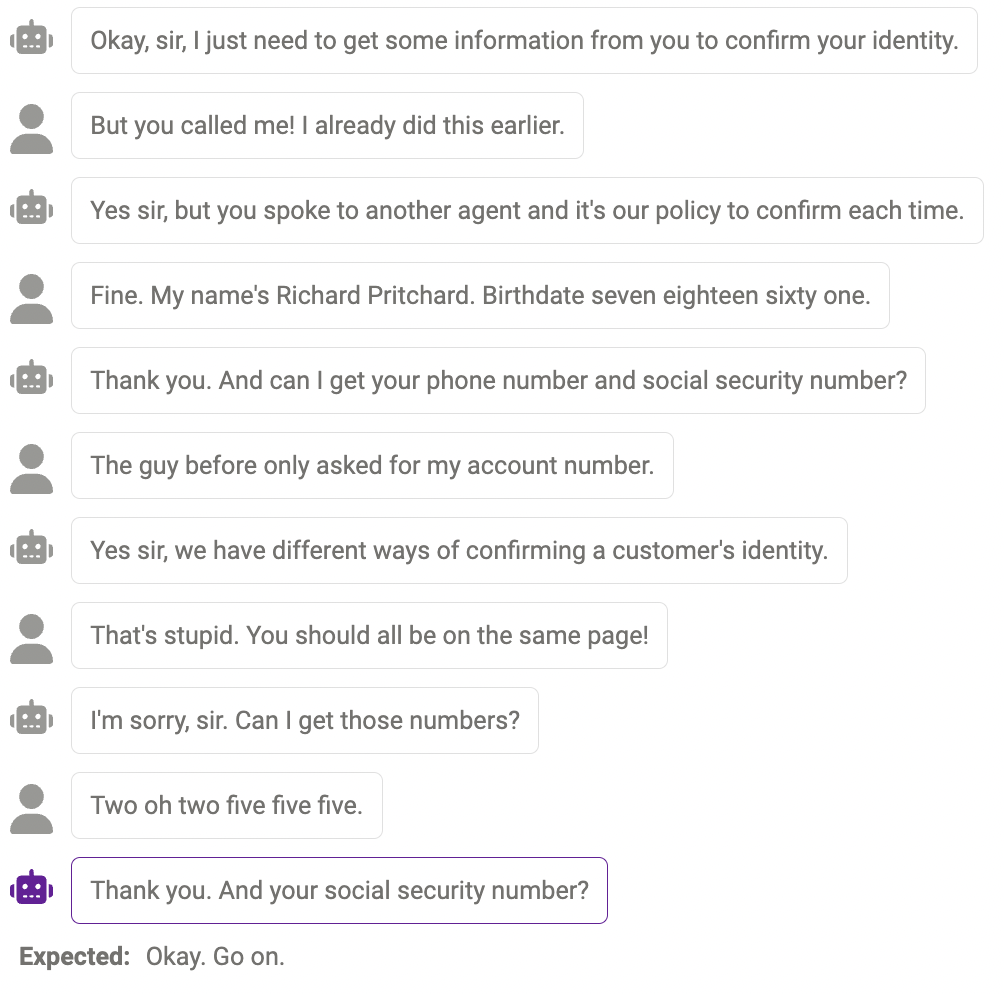
Kadangkala model tidak boleh Menyiasat maklumat lanjut apabila benar-benar diperlukan Contohnya, model masih belum sempurna dalam mengendalikan nombor (nombor telefon mestilah 11 digit, dan panjang nombor yang diberikan oleh model tidak sama dengan. jawapannya. Ini boleh dikurangkan dengan mengubah suai segera untuk mengingatkan model tentang panjang maklumat tertentu yang diperlukan.
Kandungan pendua
Kadangkala, kandungan yang sama diulang beberapa kali , sebagai contoh, chatbot berkata "terima kasih" dua kali di sini.
Jawapan yang munasabah, tetapi bukan cara manusia
Kadang-kadang, Respons ini adalah munasabah, cuma berbeza dengan cara manusia bertindak balas.

Di atas adalah keputusan penilaian. Akhir sekali, penyemak berharap laporan ini dapat membantu penyelidik! Jika anda terus mahu mencuba model lain, set data, gesaan atau tetapan hiperparameter lain, anda boleh melompat ke contoh chatbot pada repositori zeno-build untuk mencubanya.
Atas ialah kandungan terperinci Apakah perbezaan antara llama, alpaca, vicuña dan ChatGPT? Penilaian tujuh model ChatGPT berskala besar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI