
Rumah >pembangunan bahagian belakang >Tutorial Python >Cara menggunakan aliran tensor untuk membina LSTM memori jangka pendek yang panjang dalam python
Cara menggunakan aliran tensor untuk membina LSTM memori jangka pendek yang panjang dalam python

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-22 12:32:141443semak imbas
Pengenalan kepada LSTM
1. Masalah kehilangan kecerunan RNN
Pada masa lalu, kami telah mempelajari rangkaian saraf berulang RNN, dan rajah strukturnya adalah seperti berikut:
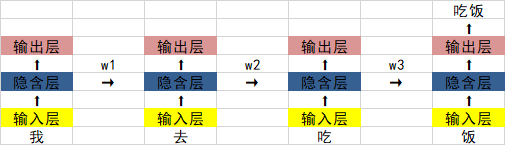
Masalah terbesar ialah apabila nilai w1, w2, dan w3 kurang daripada 0, jika ayat cukup panjang, maka apabila rangkaian saraf melakukan perambatan balik dan perambatan ke hadapan, akan ada Masalah kecerunan lenyap.
0.925=0.07 Jika ayat mempunyai 20 hingga 30 patah perkataan, maka keluaran lapisan tersembunyi bagi perkataan pertama akan menjadi 0.07 kali lebih besar daripada keluaran perkataan terakhir Impaknya sangat berkurangan.
Situasi khusus adalah seperti berikut:
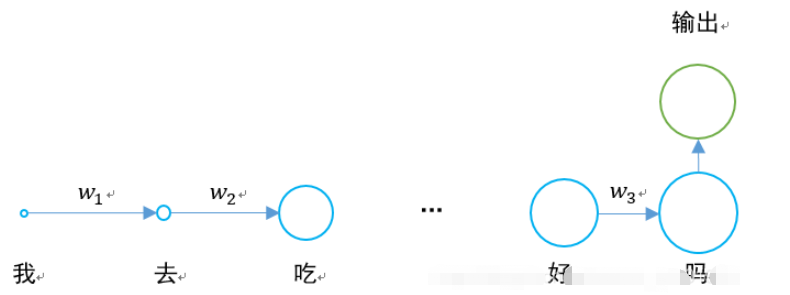
Rangkaian ingatan jangka pendek yang panjang muncul untuk menyelesaikan masalah kehilangan kecerunan.
2. Struktur LSTM
Lapisan tersembunyi RNN asal hanya mempunyai satu keadaan h, yang dihantar dari awal hingga akhir.
Jika kita menambah satu lagi keadaan c dan biarkan ia menyelamatkan keadaan jangka panjang, masalah itu boleh diselesaikan.
Untuk RNN dan LSTM, perbandingan dua unit langkah adalah seperti berikut.

Kami mengembangkan struktur LSTM mengikut dimensi masa:
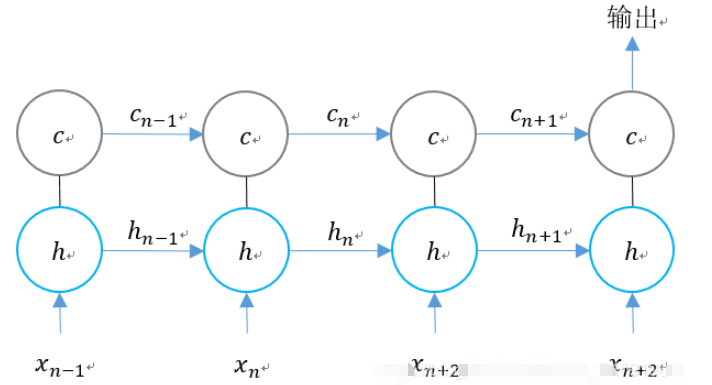
Kita dapat melihat bahawa pada n masa, LSTM Terdapat tiga input:
1 Nilai input rangkaian pada saat semasa; nilai LSTM pada saat sebelumnya ;
3. Status unit pada saat sebelumnya.
1 nilai keluaran LSTM pada saat semasa;
2. Status unit pada masa semasa.
3. Struktur get unik LSTM LSTM menggunakan dua get untuk mengawal kandungan keadaan unit cn:
1 (pintu lupa), yang menentukan berapa banyak keadaan unit cn-1 momen sebelumnya dikekalkan kepada momen semasa; , yang Ia menentukan berapa banyak input c’n rangkaian pada masa semasa disimpan ke keadaan unit.
LSTM menggunakan get untuk mengawal kandungan nilai output semasa hn:
Fungsi berkaitan LSTM dalam aliran tensortf.contrib.rnn.BasicLSTMCell
tf.contrib.rnn.BasicLSTMCell(
num_units,
forget_bias=1.0,
state_is_tuple=True,
activation=None,
reuse=None,
name=None,
dtype=None
)bilangan unit Thes: dalam RNR_unit bilangan neuron, iaitu bilangan neuron keluaran.
state_is_tuple: Jika Benar, keadaan yang diterima dan dikembalikan ialah 2-tuple bagi c_state dan m_state jika False, ia disambungkan di sepanjang paksi lajur. False akan ditamatkan.
pengaktifan: fungsi pengaktifan.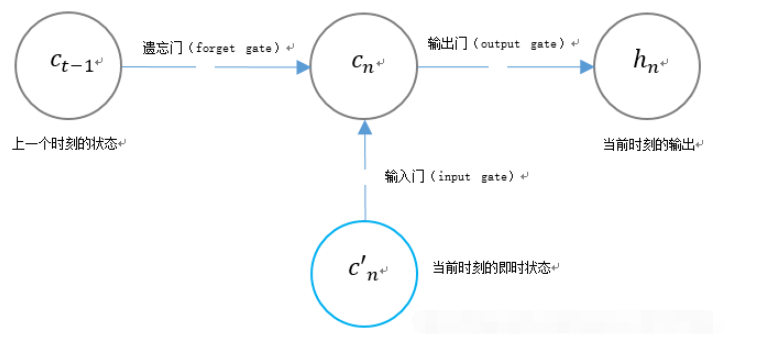 guna semula: Menerangkan sama ada hendak menggunakan semula pembolehubah dalam skop sedia ada. Jika skop sedia ada sudah mempunyai pembolehubah yang diberikan dan ia tidak Benar, ralat akan dibangkitkan.
guna semula: Menerangkan sama ada hendak menggunakan semula pembolehubah dalam skop sedia ada. Jika skop sedia ada sudah mempunyai pembolehubah yang diberikan dan ia tidak Benar, ralat akan dibangkitkan.
nama: Nama lapisan.
dtype: Jenis data lapisan ini.
Apabila digunakan, ia boleh ditakrifkan sebagai:
lstm_cell = tf.contrib.rnn.BasicLSTMCell(self.cell_size, forget_bias=1.0, state_is_tuple=True)
Selepas definisi selesai, keadaan boleh dimulakan:
self.cell_init_state = lstm_cell.zero_state(self.batch_size, dtype=tf.float32)
tf.nn.dynamic_rnn
tf.nn.dynamic_rnn(
cell,
inputs,
sequence_length=None,
initial_state=None,
dtype=None,
parallel_iterations=None,
swap_memory=False,
time_major=False,
scope=None
)
sel: lstm_cell ditakrifkan di atas.
input: input RNN. Jika time_major==false (lalai), mestilah tensor bentuk: [saiz_batch, max_time, …] atau tuple bersarang unsur tersebut. Jika time_major==benar, ia mestilah tensor bentuk: [max_time, batch_size, …] atau tuple bersarang elemen sedemikian.
Saiz vektor ditentukan oleh parameter sequence_length, iaitu jenis Int32/Int64. Digunakan untuk menyalin status dan keluaran sifar apabila panjang jujukan elemen kelompok melebihi. Jadi ia lebih kepada prestasi daripada ketepatan.
- initial_state: _init_state ditakrifkan di atas.
- dtype: jenis data.
- parallel_iterations: Bilangan lelaran berjalan selari. Operasi tersebut ialah operasi yang tidak mempunyai sebarang pergantungan masa dan boleh dijalankan secara selari. Parameter ini memperdagangkan masa untuk ruang. Nilai yang lebih besar menggunakan lebih banyak memori tetapi beroperasi lebih cepat, manakala nilai yang lebih kecil menggunakan lebih sedikit memori tetapi memerlukan masa pengiraan yang lebih lama.
time_major:输入和输出tensor的形状格式。这些张量的形状必须为[max_time, batch_size, depth],若表述正确,则它为真。这些张量的形状必须是[batch_size,max_time,depth],如果为假。time_major=true可以提高效率,因为它避免了在RNN计算的开头和结尾进行转置操作。默认情况下,此函数为False,因为大多数的 TensorFlow 数据以批处理主数据的形式存在。
scope:创建的子图的可变作用域;默认为“RNN”。
在LSTM的最后,需要用该函数得出结果。
self.cell_outputs, self.cell_final_state = tf.nn.dynamic_rnn( lstm_cell, self.l_in_y, initial_state=self.cell_init_state, time_major=False)
返回的是一个元组 (outputs, state):
outputs:LSTM的最后一层的输出,是一个tensor。如果为time_major== False,则它的shape为[batch_size,max_time,cell.output_size]。如果为time_major== True,则它的shape为[max_time,batch_size,cell.output_size]。
states:states是一个tensor。state是最终的状态,也就是序列中最后一个cell输出的状态。一般情况下states的形状为 [batch_size, cell.output_size],但当输入的cell为BasicLSTMCell时,states的形状为[2,batch_size, cell.output_size ],其中2也对应着LSTM中的cell state和hidden state。
整个LSTM的定义过程为:
def add_input_layer(self,):
#X最开始的形状为(256 batch,28 steps,28 inputs)
#转化为(256 batch*28 steps,128 hidden)
l_in_x = tf.reshape(self.xs, [-1, self.input_size], name='to_2D')
#获取Ws和Bs
Ws_in = self._weight_variable([self.input_size, self.cell_size])
bs_in = self._bias_variable([self.cell_size])
#转化为(256 batch*28 steps,256 hidden)
with tf.name_scope('Wx_plus_b'):
l_in_y = tf.matmul(l_in_x, Ws_in) + bs_in
# (batch * n_steps, cell_size) ==> (batch, n_steps, cell_size)
# (256*28,256)->(256,28,256)
self.l_in_y = tf.reshape(l_in_y, [-1, self.n_steps, self.cell_size], name='to_3D')
def add_cell(self):
#神经元个数
lstm_cell = tf.contrib.rnn.BasicLSTMCell(self.cell_size, forget_bias=1.0, state_is_tuple=True)
#每一次传入的batch的大小
with tf.name_scope('initial_state'):
self.cell_init_state = lstm_cell.zero_state(self.batch_size, dtype=tf.float32)
#不是主列
self.cell_outputs, self.cell_final_state = tf.nn.dynamic_rnn(
lstm_cell, self.l_in_y, initial_state=self.cell_init_state, time_major=False)
def add_output_layer(self):
#设置Ws,Bs
Ws_out = self._weight_variable([self.cell_size, self.output_size])
bs_out = self._bias_variable([self.output_size])
# shape = (batch,output_size)
# (256,10)
with tf.name_scope('Wx_plus_b'):
self.pred = tf.matmul(self.cell_final_state[-1], Ws_out) + bs_out全部代码
该例子为手写体识别例子,将手写体的28行分别作为每一个step的输入,输入维度均为28列。
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
mnist = input_data.read_data_sets("MNIST_data",one_hot = "true")
BATCH_SIZE = 256 # 每一个batch的数据数量
TIME_STEPS = 28 # 图像共28行,分为28个step进行传输
INPUT_SIZE = 28 # 图像共28列
OUTPUT_SIZE = 10 # 共10个输出
CELL_SIZE = 256 # RNN 的 hidden unit size,隐含层神经元的个数
LR = 1e-3 # learning rate,学习率
def get_batch(): #获取训练的batch
batch_xs,batch_ys = mnist.train.next_batch(BATCH_SIZE)
batch_xs = batch_xs.reshape([BATCH_SIZE,TIME_STEPS,INPUT_SIZE])
return [batch_xs,batch_ys]
class LSTMRNN(object): #构建LSTM的类
def __init__(self, n_steps, input_size, output_size, cell_size, batch_size):
self.n_steps = n_steps
self.input_size = input_size
self.output_size = output_size
self.cell_size = cell_size
self.batch_size = batch_size
#输入输出
with tf.name_scope('inputs'):
self.xs = tf.placeholder(tf.float32, [None, n_steps, input_size], name='xs')
self.ys = tf.placeholder(tf.float32, [None, output_size], name='ys')
#直接加层
with tf.variable_scope('in_hidden'):
self.add_input_layer()
#增加LSTM的cell
with tf.variable_scope('LSTM_cell'):
self.add_cell()
#直接加层
with tf.variable_scope('out_hidden'):
self.add_output_layer()
#计算损失值
with tf.name_scope('cost'):
self.compute_cost()
#训练
with tf.name_scope('train'):
self.train_op = tf.train.AdamOptimizer(LR).minimize(self.cost)
#正确率计算
self.correct_pre = tf.equal(tf.argmax(self.ys,1),tf.argmax(self.pred,1))
self.accuracy = tf.reduce_mean(tf.cast(self.correct_pre,tf.float32))
def add_input_layer(self,):
#X最开始的形状为(256 batch,28 steps,28 inputs)
#转化为(256 batch*28 steps,128 hidden)
l_in_x = tf.reshape(self.xs, [-1, self.input_size], name='to_2D')
#获取Ws和Bs
Ws_in = self._weight_variable([self.input_size, self.cell_size])
bs_in = self._bias_variable([self.cell_size])
#转化为(256 batch*28 steps,256 hidden)
with tf.name_scope('Wx_plus_b'):
l_in_y = tf.matmul(l_in_x, Ws_in) + bs_in
# (batch * n_steps, cell_size) ==> (batch, n_steps, cell_size)
# (256*28,256)->(256,28,256)
self.l_in_y = tf.reshape(l_in_y, [-1, self.n_steps, self.cell_size], name='to_3D')
def add_cell(self):
#神经元个数
lstm_cell = tf.contrib.rnn.BasicLSTMCell(self.cell_size, forget_bias=1.0, state_is_tuple=True)
#每一次传入的batch的大小
with tf.name_scope('initial_state'):
self.cell_init_state = lstm_cell.zero_state(self.batch_size, dtype=tf.float32)
#不是主列
self.cell_outputs, self.cell_final_state = tf.nn.dynamic_rnn(
lstm_cell, self.l_in_y, initial_state=self.cell_init_state, time_major=False)
def add_output_layer(self):
#设置Ws,Bs
Ws_out = self._weight_variable([self.cell_size, self.output_size])
bs_out = self._bias_variable([self.output_size])
# shape = (batch,output_size)
# (256,10)
with tf.name_scope('Wx_plus_b'):
self.pred = tf.matmul(self.cell_final_state[-1], Ws_out) + bs_out
def compute_cost(self):
self.cost = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits = self.pred,labels = self.ys)
)
def _weight_variable(self, shape, name='weights'):
initializer = np.random.normal(0.0,1.0 ,size=shape)
return tf.Variable(initializer, name=name,dtype = tf.float32)
def _bias_variable(self, shape, name='biases'):
initializer = np.ones(shape=shape)*0.1
return tf.Variable(initializer, name=name,dtype = tf.float32)
if __name__ == '__main__':
#搭建 LSTMRNN 模型
model = LSTMRNN(TIME_STEPS, INPUT_SIZE, OUTPUT_SIZE, CELL_SIZE, BATCH_SIZE)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
#训练10000次
for i in range(10000):
xs, ys = get_batch() #提取 batch data
if i == 0:
#初始化data
feed_dict = {
model.xs: xs,
model.ys: ys,
}
else:
feed_dict = {
model.xs: xs,
model.ys: ys,
model.cell_init_state: state #保持 state 的连续性
}
#训练
_, cost, state, pred = sess.run(
[model.train_op, model.cost, model.cell_final_state, model.pred],
feed_dict=feed_dict)
#打印精确度结果
if i % 20 == 0:
print(sess.run(model.accuracy,feed_dict = {
model.xs: xs,
model.ys: ys,
model.cell_init_state: state #保持 state 的连续性
}))Atas ialah kandungan terperinci Cara menggunakan aliran tensor untuk membina LSTM memori jangka pendek yang panjang dalam python. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!