
Rumah >Peranti teknologi >AI >Penerokaan dan amalan teknologi perkaitan carian Dianping
Penerokaan dan amalan teknologi perkaitan carian Dianping

- 王林ke hadapan
- 2023-05-19 19:04:04957semak imbas
Pengarang: Xiaoya Shen Yuan, Zhu Di et al
1 Latar Belakang
Pencarian Dianping ialah teras Dianping. App Salah satu pintu masuk membolehkan pengguna mencari untuk memenuhi keperluan pencarian kedai mereka untuk peniaga perkhidmatan gaya hidup dalam senario yang berbeza. Matlamat jangka panjang carian adalah untuk terus mengoptimumkan pengalaman carian dan meningkatkan kepuasan carian pengguna. Ini memerlukan kami memahami hasrat carian pengguna, mengukur dengan tepat korelasi antara istilah carian dan pedagang, memaparkan pedagang yang berkaitan sebanyak mungkin dan memberi kedudukan lebih. peniaga yang berkaitan berdasarkan hadapan. Oleh itu, pengiraan korelasi antara istilah carian dan pedagang adalah bahagian penting dalam carian ulasan.
Masalah perkaitan yang dihadapi oleh senario carian Dianping adalah rumit dan pelbagai Istilah carian pengguna agak pelbagai, seperti mencari nama perniagaan, hidangan, alamat, kategori dan pelbagai kerumitan antara. Pada masa yang sama, peniaga juga mempunyai pelbagai jenis maklumat, termasuk nama pedagang, maklumat alamat, maklumat pesanan kumpulan, maklumat hidangan, dan pelbagai maklumat kemudahan dan label lain, dsb., menghasilkan corak padanan yang sangat kompleks antara Pertanyaan dan peniaga, yang dengan mudah membiak pelbagai isu korelasi tersebut. Secara khusus, ia boleh dibahagikan kepada jenis berikut:
- Ketidakpadanan teks: Apabila mencari, untuk memastikan lebih ramai pedagang diambil dan didedahkan , Pertanyaan mungkin dibahagikan kepada perkataan yang lebih halus untuk mendapatkan semula, yang akan menyebabkan masalah ketidakpadanan Pertanyaan dengan medan pedagang yang berbeza Seperti yang ditunjukkan dalam Rajah 1(a), pengguna yang mencari "hotpot tiram" harus mencari asas sup. Periuk panas mengandungi tiram, dan "tiram" dan "periuk panas" masing-masing dipadankan dengan dua hidangan berbeza peniaga.
- Imbang semantik: Pertanyaan benar-benar sepadan dengan pedagang, tetapi pedagang secara semantik tidak berkaitan dengan niat utama Pertanyaan, seperti "teh susu" - "gula perang teh susu mutiara" Pakej", seperti yang ditunjukkan dalam Rajah 1(b).
- Kategori mengimbangi: Pertanyaan benar-benar sepadan dengan pedagang dan berkaitan secara semantik, tetapi kategori utama tidak sepadan dengan keperluan pengguna Contohnya, apabila pengguna mencari Peniaga KTV "buah" yang menyediakan "pinggan buah" jelas tidak relevan dengan keperluan pengguna.
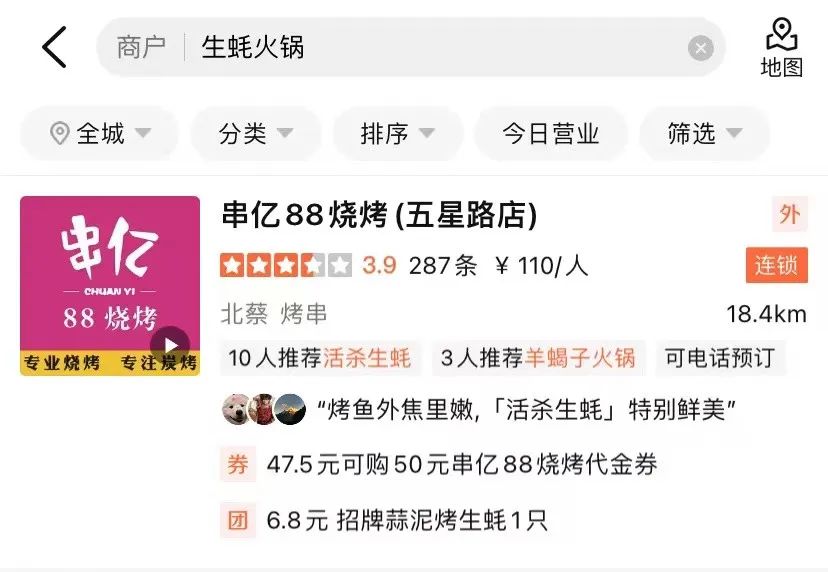
(a) Contoh teks yang tidak padan
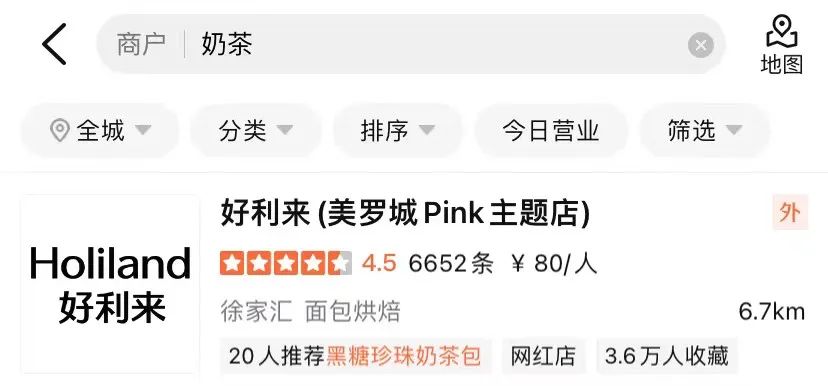
(b) Contoh anjakan semantik
Rajah 1 Contoh masalah perkaitan carian semakan
Berdasarkan literal The kaedah korelasi pemadanan tidak dapat menangani masalah di atas dengan berkesan Untuk menyelesaikan pelbagai masalah yang tidak berkaitan dalam senarai carian yang tidak memenuhi niat pengguna, adalah perlu untuk mencirikan korelasi semantik yang mendalam antara istilah carian dan pedagang. Berdasarkan model pra-latihan MT-BERT yang dilatih pada korpus perniagaan besar Meituan, artikel ini mengoptimumkan semantik mendalam Query dan pedagang (POI, sepadan dengan Doc dalam enjin carian umum) dalam senario carian Dianping model, dan gunakan maklumat korelasi antara Pertanyaan dan POI dalam setiap pautan pautan carian.
Artikel ini akan memperkenalkan teknologi perkaitan carian semakan daripada empat aspek: semakan teknologi perkaitan carian sedia ada, semakan skim pengiraan perkaitan carian, amalan aplikasi, ringkasan dan pandangan. Bab pengiraan perkaitan carian Dianping akan memperkenalkan cara kami menyelesaikan tiga cabaran utama pembinaan maklumat input pedagang, menyesuaikan model kepada pengiraan perkaitan carian Dianping, dan pengoptimuman prestasi model dalam talian Bab aplikasi praktikal akan memperkenalkan pembangunan luar talian Model perkaitan carian Dianping dan kesan dalam talian.
2 Cari perkaitan teknologi sedia ada
Kaitan carian bertujuan untuk mengira korelasi antara Pertanyaan dan Dokumen yang dikembalikan, iaitu, untuk menentukan sama ada kandungan dalam Doc Meet keperluan Pertanyaan pengguna dan sepadan dengan tugas pemadanan semantik dalam NLP (Pemadanan Semantik). Dalam senario carian Dianping, perkaitan carian adalah untuk mengira korelasi antara Pertanyaan pengguna dan POI pedagang.
Kaedah pemadanan teks: Tugas pemadanan teks awal hanya mempertimbangkan tahap pemadanan literal antara Pertanyaan dan Dokumen, melalui ciri pemadanan berasaskan Istilah seperti TF-IDF dan BM25 . untuk mengira korelasi. Kecekapan pengiraan dalam talian bagi korelasi padanan perkataan adalah tinggi, tetapi prestasi generalisasi padanan kata kunci berasaskan istilah adalah lemah, kekurangan maklumat semantik dan susunan perkataan, dan tidak dapat menangani masalah berbilang makna bagi satu perkataan atau berbilang perkataan dengan satu makna, jadi padanan hilang dan salah faham Fenomena padanan adalah serius.
Model padanan semantik tradisional: Untuk mengimbangi kekurangan padanan literal, model padanan semantik dicadangkan untuk lebih memahami korelasi semantik antara Pertanyaan dan Dokumen. Model padanan semantik tradisional terutamanya termasuk padanan berdasarkan ruang tersirat: memetakan kedua-dua Pertanyaan dan Dokumen kepada vektor dalam ruang yang sama, dan kemudian menggunakan jarak atau persamaan vektor sebagai skor padanan, seperti Separa Segiempat Terkecil (PLS )[1]; dan padanan berdasarkan model terjemahan: padankan Dokumen selepas memetakannya ke ruang Pertanyaan atau kira kebarangkalian Dokumen diterjemahkan ke dalam Pertanyaan[2].
Dengan pembangunan model pembelajaran mendalam dan pra-latihan, model padanan semantik mendalam juga digunakan secara meluas dalam industri. Model padanan semantik mendalam dibahagikan kepada kaedah berasaskan perwakilan (Berasaskan perwakilan) dan berasaskan interaksi (Berasaskan interaksi) dari segi kaedah pelaksanaan. Sebagai kaedah yang berkesan dalam bidang pemprosesan bahasa semula jadi, model pra-latihan juga digunakan secara meluas dalam tugasan padanan semantik.
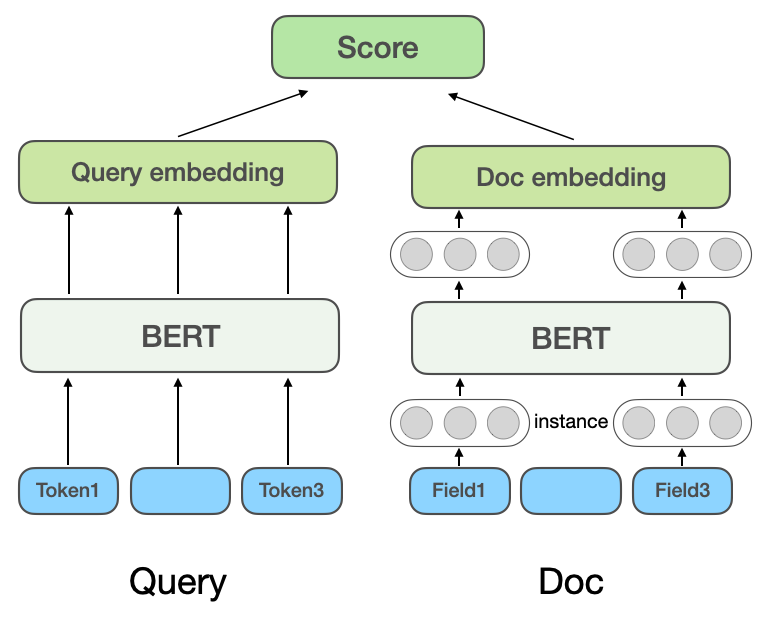
(a) Model korelasi berbilang domain berasaskan perwakilan
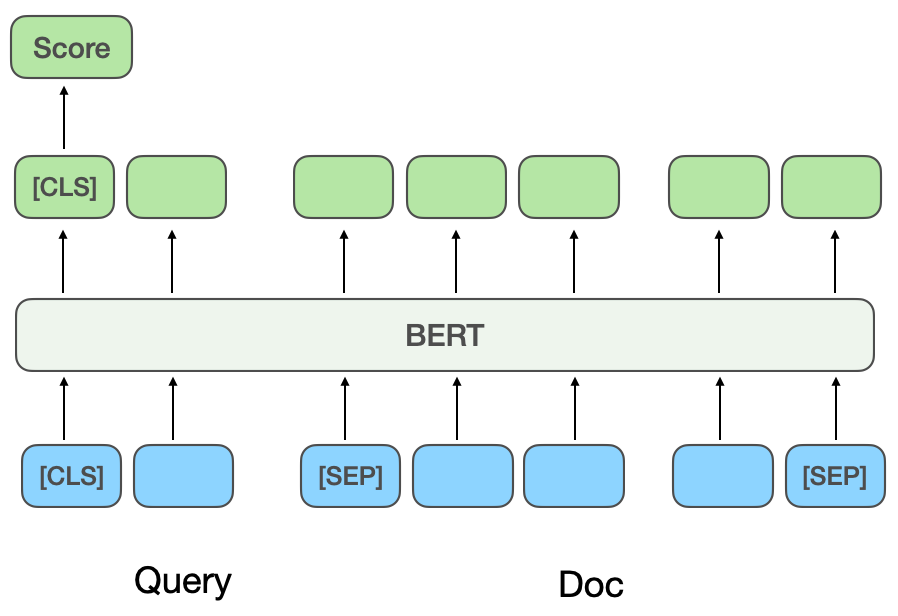
(b) Model korelasi berasaskan interaksi
Rajah 2 Model korelasi pemadanan semantik mendalam
Model padanan semantik dalam berasaskan perwakilan: Kaedah berasaskan perwakilan mempelajari perwakilan vektor semantik Pertanyaan dan Dokumen masing-masing, kemudian mengira persamaan berdasarkan dua vektor. Model DSSM Microsoft [3] mencadangkan model pemadanan teks struktur menara berkembar klasik, yang menggunakan dua rangkaian bebas untuk membina perwakilan vektor Query dan Doc, dan menggunakan persamaan kosinus untuk mengukur dua darjah korelasi . NRM Microsoft Bing Search[4]Mensasarkan masalah perwakilan Dokumen Selain tajuk dan kandungan Dokumen asas, maklumat berbilang sumber lain juga dipertimbangkan (Setiap jenis maklumat dipanggil. medan Medan ), seperti pautan luaran, pertanyaan yang diklik oleh pengguna, dsb. Pertimbangkan bahawa terdapat berbilang Medan dalam Dokumen dan terdapat berbilang tika dalam setiap Medan (Instance sepadan kepada teks, seperti Kata pertanyaan. Model pertama mempelajari vektor Contoh, mengagregat semua vektor perwakilan Contoh untuk mendapatkan vektor perwakilan Medan dan mengagregatkan berbilang vektor perwakilan Medan untuk mendapatkan vektor Dokumen akhir. SentenceBERT[5]Perkenalkan model BERT pra-latihan kepada lapisan pengekodan Pertanyaan dan Dokumen Menara Berkembar, gunakan kaedah Pengumpulan yang berbeza untuk mendapatkan vektor ayat Menara Berkembar dan gunakan pendaraban titik, penyambungan, dsb. . untuk bertanya dan Doc untuk berinteraksi.
Model awal perkaitan carian Dianping menggunakan idea NRM dan SentenceBERT, dan menerima pakai struktur model perkaitan berbilang domain berasaskan perwakilan yang ditunjukkan dalam Rajah 2(a). boleh mengira vektor POI terlebih dahulu dan menyimpannya dalam cache Hanya bahagian interaktif antara vektor Pertanyaan dan vektor POI dikira dalam talian, jadi kelajuan pengiraan lebih cepat apabila digunakan dalam talian.
Model padanan semantik dalam berasaskan interaksi: Kaedah berasaskan interaksi tidak secara langsung mempelajari vektor perwakilan semantik Pertanyaan dan Dokumen, tetapi membenarkan Pertanyaan digunakan dalam peringkat input asas. Berinteraksi dengan Dokumen untuk mewujudkan beberapa isyarat padanan asas, dan kemudian gabungkan isyarat padanan asas ke dalam skor padanan. ESIM[6] ialah model klasik yang digunakan secara meluas dalam industri sebelum pengenalan model pra-latihan Pertama, Pertanyaan dan Dokumen dikodkan untuk mendapatkan vektor awal, dan kemudian mekanisme Perhatian digunakan untuk interaktif pemberat dan kemudian disambung dengan vektor awal Akhirnya, Pengelasan menghasilkan skor perkaitan.
Apabila memperkenalkan BERT model pra-latihan untuk pengiraan interaktif, Pertanyaan dan Dokumen biasanya disambungkan sebagai input tugas perhubungan antara ayat BERT, dan skor korelasi akhir ialah diperolehi melalui rangkaian MLP [ 7], seperti yang ditunjukkan dalam Rajah 2(b). CEDR[8]Selepas mendapatkan vektor Pertanyaan dan Dokumen dalam tugas perhubungan antara ayat BERT, vektor Pertanyaan dan Dokumen dipisahkan dan matriks persamaan kosinus Pertanyaan dan Dokumen dikira selanjutnya. Pasukan carian Meituan [9] memperkenalkan kaedah berasaskan interaksi ke dalam model korelasi carian Meituan, memperkenalkan maklumat kategori pedagang untuk pra-latihan dan memperkenalkan tugas pengecaman entiti untuk pembelajaran berbilang tugas. Pasukan pengiklanan carian dalam gedung Meituan [10] mencadangkan kaedah penyulingan model berasaskan interaksi menjadi model berasaskan perwakilan untuk mencapai interaksi maya model menara berkembar, sambil memastikan prestasi sambil menambah Pertanyaan dan interaksi POI.
3. Semak pengiraan korelasi carian
Model berasaskan perwakilan memfokuskan pada mewakili ciri global POI dan tidak mempunyai maklumat padanan antara Pertanyaan dalam talian dan Berdasarkan POI pada interaksi Kaedah ini boleh mengimbangi kelemahan kaedah berasaskan perwakilan, meningkatkan interaksi antara Pertanyaan dan POI, dan meningkatkan keupayaan ekspresi model Pada masa yang sama, memandangkan prestasi kukuh pra-terlatih model dalam tugas pemadanan semantik teks, pengiraan korelasi carian semakan menentukan model pra-latihan berdasarkan skema Interaktif Meituan MT-BERT[11]. Apabila menggunakan BERT interaktif berdasarkan model pra-latihan kepada tugas perkaitan senario carian semakan, masih terdapat banyak cabaran:
- Cara membina model Sisi POI dengan lebih baik maklumat input : Pembinaan maklumat input model sisi Doc ialah pautan penting dalam model korelasi. Dalam enjin carian web umum, tajuk halaman web Doc sangat penting untuk menentukan perkaitan Walau bagaimanapun, dalam senario carian semakan, maklumat POI mempunyai ciri-ciri banyak medan dan maklumat yang kompleks. tajuk halaman web". , setiap pedagang dinyatakan melalui pelbagai maklumat berstruktur seperti nama pedagang, kategori, alamat, pesanan kumpulan, tag pedagang, dsb. Apabila mengira skor perkaitan, sejumlah besar maklumat pedagang berbilang sumber tidak boleh dimasukkan ke dalam model, dan hanya menggunakan maklumat asas seperti nama dan kategori pedagang tidak dapat mencapai hasil yang memuaskan kerana kekurangan maklumat Oleh itu, bagaimana untuk membina a struktur dengan maklumat yang kaya? Input model sampingan POI ialah masalah utama yang ingin kami selesaikan.
- Cara mengoptimumkan model agar lebih sesuai untuk menyemak pengiraan perkaitan carian : Maklumat teks dalam senario carian Dianping dan umum Terdapat perbezaan tertentu dalam maklumat korpus model pra-latihan Contohnya, "gembira" dan "gembira" adalah sinonim dalam senario semantik umum, tetapi dalam senario carian semakan, "barbeku gembira" dan "barbeku gembira" adalah dua jenama yang sama sekali berbeza. Pada masa yang sama, logik penentuan korelasi Pertanyaan dan POI tidak betul-betul sama dengan tugas pemadanan semantik senario NLP umum Mod padanan Pertanyaan dan POI adalah sangat kompleks Apabila Pertanyaan sepadan dengan medan POI yang berbeza, penentuan korelasi keputusan juga berbeza. Contohnya, apabila Pertanyaan "Buah" sepadan dengan kategori pedagang "Kedai Buah", korelasi adalah tinggi, tetapi apabila ia mencecah teg "Fruit Platter" KTV, korelasinya lemah. Oleh itu, berbanding dengan tugas pemadanan semantik hubungan antara ayat BERT berasaskan interaksi umum, pengiraan korelasi juga perlu memberi perhatian kepada padanan khusus antara bahagian Pertanyaan dan POI. Bagaimana untuk mengoptimumkan model untuk menyesuaikan diri dengan senario carian semakan, mengendalikan logik penghakiman yang kompleks dan pelbagai perkaitan, dan menyelesaikan pelbagai masalah yang tidak berkaitan sebanyak mungkin adalah cabaran utama yang kami hadapi.
- Cara menyelesaikan kesesakan prestasi dalam talian model korelasi pra-latihan: Walaupun model berasaskan perwakilan mempunyai kelajuan pengiraan yang lebih pantas tetapi keupayaan ekspresi terhad, interaksi model berasaskan boleh dipertingkatkan Interaksi antara Pertanyaan dan POI meningkatkan kesan model, tetapi terdapat kesesakan prestasi yang besar apabila digunakan dalam talian. Oleh itu, apabila menggunakan model berasaskan interaksi BERT 12 lapisan dalam talian, cara memastikan kesan pengiraan model sambil memastikan prestasi keseluruhan pautan pengkomputeran supaya ia boleh berjalan dengan stabil dan cekap dalam talian adalah halangan terakhir untuk aplikasi dalam talian pengiraan korelasi.
Selepas penerokaan dan percubaan berterusan, kami membina ringkasan teks POI yang disesuaikan dengan senario carian semakan untuk maklumat berbilang sumber yang kompleks di bahagian POI; model lebih sesuai Dengan pengiraan korelasi carian Dianping, kaedah latihan dua peringkat telah diterima pakai, dan struktur model telah diubah mengikut ciri-ciri pengiraan korelasi akhirnya, dengan mengoptimumkan proses pengiraan, memperkenalkan caching dan langkah-langkah lain, masa nyata; pengiraan dan pautan aplikasi keseluruhan model berjaya dikurangkan memakan masa, memenuhi keperluan prestasi pengiraan masa nyata dalam talian bagi BERT.
3.1 Cara membina maklumat input model sisi POI dengan lebih baik
Apabila menentukan korelasi antara Pertanyaan dan POI, terdapat lebih daripada sedozen medan di bahagian POI yang mengambil bahagian dalam pengiraan. Terdapat banyak kandungan di bawah medan tertentu (Sebagai contoh, seorang pedagang mungkin mempunyai ratusan hidangan yang disyorkan), jadi perlu mencari cara yang sesuai untuk mengekstrak dan menyusun maklumat sampingan POI dan masukkannya ke dalam model korelasi. Enjin carian am ( seperti Baidu ), atau enjin carian menegak biasa ( seperti Taobao ), yang tajuk halaman Doc atau tajuk produknya kaya dengan maklumat, biasanya digunakan dalam proses menentukan perkaitan Kandungan utama input model sisi Doc.
Seperti yang ditunjukkan dalam Rajah 3(a), dalam enjin carian umum, maklumat utama tapak web yang sepadan dan sama ada ia berkaitan dengan Pertanyaan boleh dilihat sepintas lalu melalui tajuk hasil carian, manakala dalam Rajah 3(b) Dianping Dalam hasil carian App, maklumat pedagang yang mencukupi tidak boleh diperoleh hanya melalui medan nama pedagang Ia perlu digabungkan dengan kategori peniaga (Jus Teh Susu) dan. hidangan disyorkan pengguna (Olioli Milk Tea) , tag (Internet Celebrity Store), alamat (Wulin Plaza) pelbagai medan untuk menentukan kaitan peniaga dengan Pertanyaan "Teh Susu Selebriti Internet Wulin Plaza".
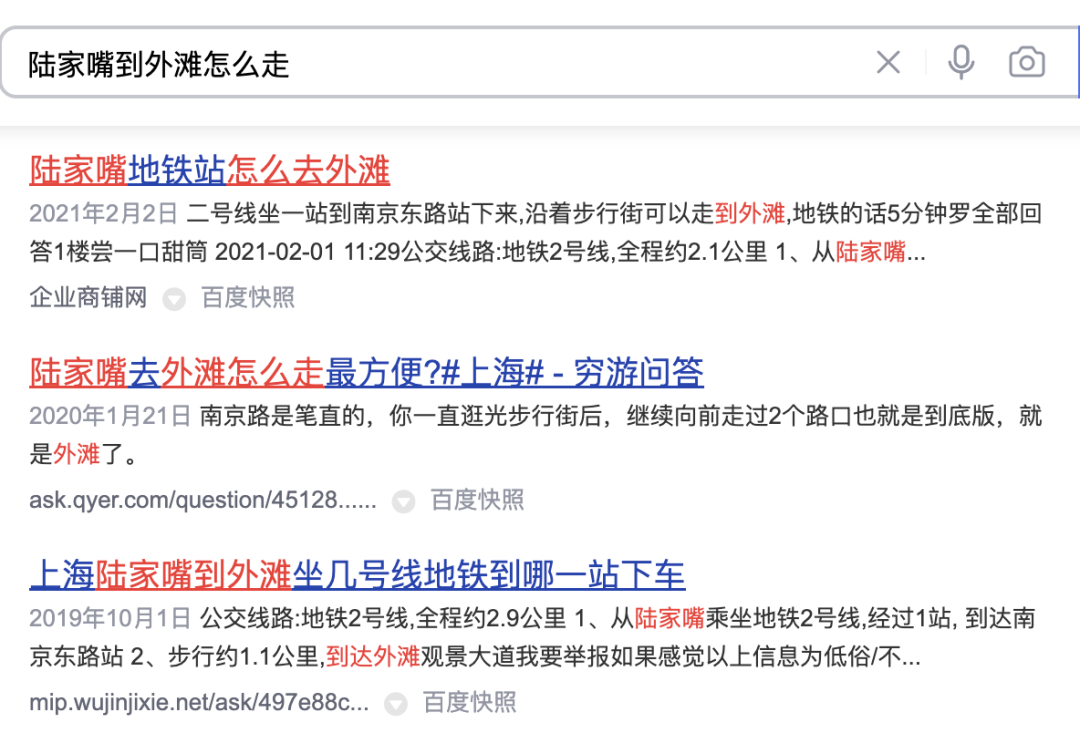
(a) Contoh hasil carian enjin carian umum
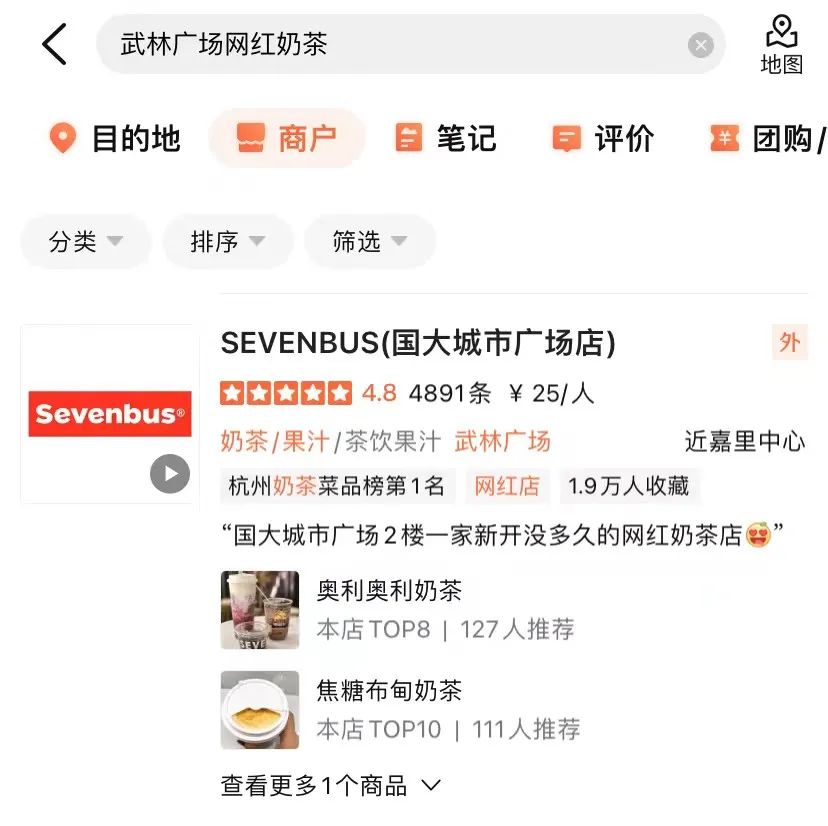
(b) Contoh hasil carian Apl Dianping
Rajah 3 Perbandingan enjin carian umum dan hasil carian Dianping
Pengeluaran teg ialah cara yang agak biasa untuk mengekstrak maklumat topik dalam industri, jadi kami mula-mula cuba membina kaedah input model sisi POI melalui teg pedagang dan mencari perkataan klik berdasarkan ulasan pedagang, maklumat asas, hidangan dan pengepala sepadan pedagang, dsb. Ekstrak kata kunci pedagang wakil sebagai teg pedagang. Apabila digunakan dalam talian, teg pedagang yang diekstrak, nama pedagang dan maklumat asas kategori digunakan sebagai maklumat input pada bahagian POI model dan pengiraan interaktif dilakukan dengan Pertanyaan. Walau bagaimanapun, liputan maklumat pedagang mengikut tag pedagang masih tidak cukup menyeluruh Contohnya, apabila pengguna mencari hidangan "kustard telur", restoran Korea yang berdekatan dengan pengguna menjual kastard telur, tetapi hidangan tandatangan kedai, klik kepala. perkataan tidak berkaitan dengan "kustard telur", menyebabkan perkataan tag yang diekstrak oleh kedai juga mempunyai korelasi yang rendah dengan "kustard telur", jadi model akan menilai kedai sebagai tidak relevan, sekali gus menyebabkan kemudaratan kepada pengalaman pengguna.
Untuk mendapatkan perwakilan POI yang paling komprehensif, satu penyelesaian adalah untuk menyambung terus semua medan pedagang ke dalam input model tanpa mengekstrak kata kunci Walau bagaimanapun, kaedah ini akan menyebabkan masalah kepada panjang input model Jika terlalu panjang, ia akan menjejaskan prestasi dalam talian secara serius, dan sejumlah besar maklumat berlebihan juga akan menjejaskan prestasi model.
Untuk membina maklumat sampingan POI yang lebih bermaklumat sebagai input model, kami mencadangkan kaedah pengekstrakan ringkasan medan pemadanan POI , iaitu digabungkan dengan padanan Pertanyaan dalam talian teks medan sepadan POI diekstrak dalam masa nyata dan ringkasan medan sepadan dibina sebagai maklumat input model sisi POI. Proses pengekstrakan ringkasan medan padanan POI ditunjukkan dalam Rajah 4. Berdasarkan beberapa ciri persamaan teks, kami mengekstrak medan teks yang paling relevan dan bermaklumat kepada Pertanyaan, dan menyepadukan maklumat jenis medan untuk membina ringkasan medan sepadan. Apabila digunakan dalam talian, ringkasan medan padanan POI yang diekstrak, nama pedagang dan maklumat asas kategori dimasukkan sebagai model sisi POI.
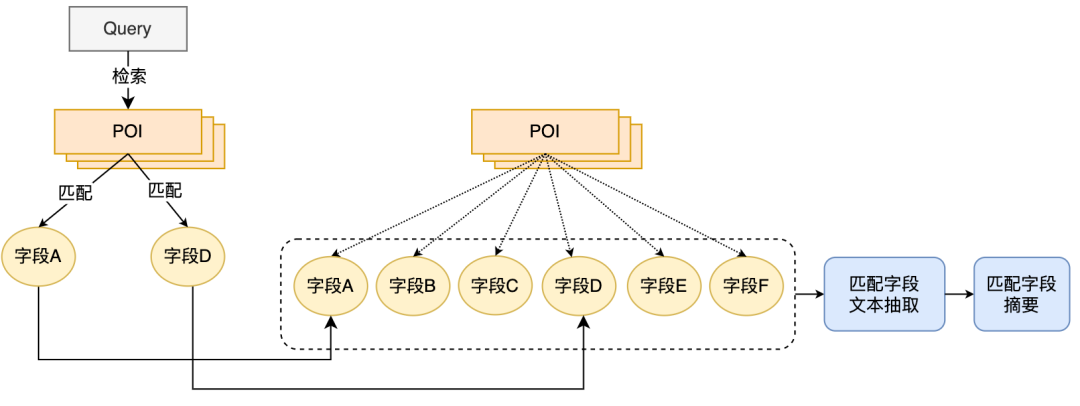
Rajah 4 Proses pengekstrakan ringkasan medan pemadanan POI Selepas menentukan maklumat input model sisi POI, kami menggunakan antara ayat BERT Tugas perhubungan, mula-mula gunakan MT-BERT untuk mengekod maklumat ringkasan medan sepadan pada bahagian Pertanyaan dan bahagian POI, kemudian gunakan vektor ayat terkumpul untuk mengira skor korelasi. Selepas menggunakan skema ringkasan medan padanan POI untuk membina model sisi POI dan memasukkan maklumat, dan bekerja dengan lelaran sampel, kesan model telah bertambah baik berbanding kaedah berasaskan label.
3.2 Cara mengoptimumkan model agar lebih sesuai dengan pengiraan perkaitan carian ulasan
Biarkan model menyesuaikan diri dengan tugas pengiraan perkaitan carian ulasan yang lebih baik mengandungi dua peringkat makna : Terdapat perbezaan tertentu dalam pengedaran antara maklumat teks dalam senario carian Dianping dan korpus yang digunakan oleh model pra-latihan MT-BERT tugas hubungan antara ayat model pra-latihan juga berbeza sedikit daripada tugasan korelasi Query dan POI, yang memerlukan Ubah suai struktur model. Selepas penerokaan berterusan, kami mengguna pakai skema latihan dua peringkat berdasarkan data domain, digabungkan dengan pembinaan sampel latihan, untuk menjadikan model pra-latihan lebih sesuai untuk tugas perkaitan senario carian semakan dan mencadangkan a berasaskan pelbagai persamaan Model korelasi interaktif mendalam matriks mengukuhkan interaksi antara Pertanyaan dan POI, meningkatkan keupayaan model untuk menyatakan maklumat Pertanyaan dan POI yang kompleks, serta mengoptimumkan kesan pengiraan korelasi.
3.2.1 Latihan dua peringkat berdasarkan data domain
Untuk menggunakan data klik pengguna dengan berkesan dan menjadikan model MT-BERT pra-latihan lebih sesuai untuk tugasan perkaitan carian semakan, kami ambil pengajaran daripada carian Baidu Berdasarkan idea korelasi[12], kaedah latihan pelbagai peringkat diperkenalkan, menggunakan klik pengguna dan data pensampelan negatif untuk menjalankan pra-latihan peringkat pertama domain penyesuaian (Pralatihan Penyesuaian Domain Berterusan), menggunakan data berlabel manual untuk peringkat kedua latihan (Tala Halus), struktur model ditunjukkan dalam Rajah 5 di bawah:
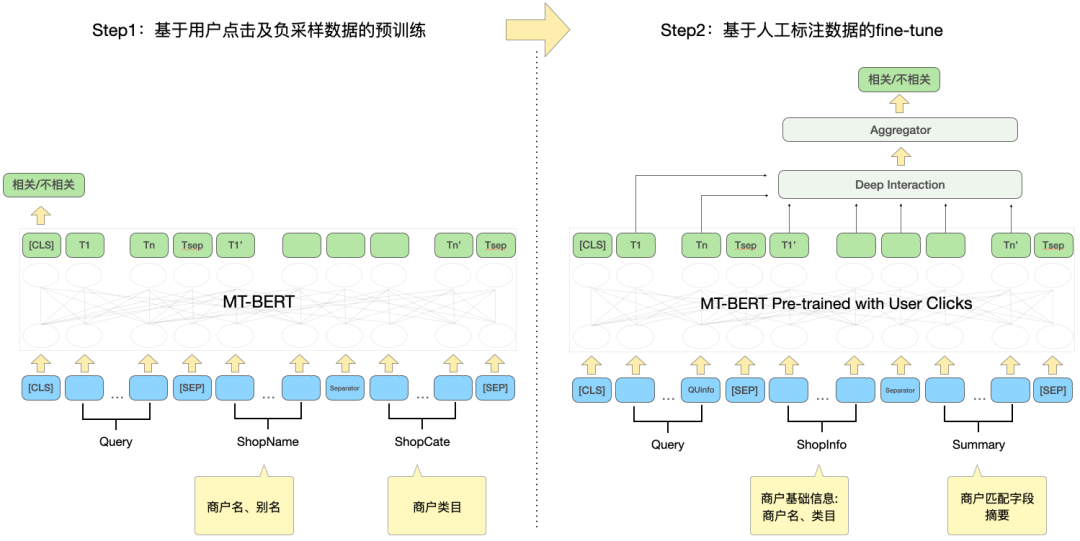
Rajah 5 Struktur model latihan dua peringkat berdasarkan klik dan data anotasi manual
Latihan peringkat pertama berdasarkan data klik
Sebab langsung untuk memperkenalkan data klik sebagai tugas latihan peringkat pertama ialah terdapat beberapa masalah unik dalam senario carian semakan Untuk contoh, perkataan "gembira" dan "gembira" hampir sinonim sepenuhnya dalam senario biasa, tetapi dalam senario carian semakan, "Selamat BBQ" dan "Selamat BBQ" ialah dua peniaga jenama yang berbeza, jadi pengenalan data klik. boleh membantu model mempelajari beberapa pengetahuan unik dalam senario carian. Walau bagaimanapun, akan terdapat banyak kebisingan dalam menggunakan sampel klik secara langsung untuk pertimbangan korelasi, kerana pengguna mungkin tersilap mengklik pada pedagang kerana kedudukan yang lebih tinggi, dan pengguna mungkin tidak mengklik pada pedagang hanya kerana pedagang berada jauh. . Ia bukan kerana masalah korelasi, jadi kami memperkenalkan pelbagai ciri dan peraturan untuk meningkatkan ketepatan anotasi automatik sampel latihan.
Apabila membina sampel, sampel calon disaring dengan mengira sama ada klik diklik, kedudukan klik, jarak antara pedagang klik terbesar dan pengguna, dsb., dan Pertanyaan- POI yang kadar kliknya lebih besar daripada ambang tertentu terdedah Gunakannya sebagai contoh positif dan laraskan ambang yang berbeza untuk jenis pedagang yang berbeza berdasarkan ciri perniagaan. Dari segi struktur contoh negatif, strategi persampelan Langkau Atas menggunakan pedagang yang terletak sebelum pedagang yang diklik dan yang kadar kliknya kurang daripada ambang sebagai sampel negatif. Selain itu, persampelan negatif rawak boleh menambah contoh negatif mudah untuk sampel latihan, tetapi apabila mempertimbangkan persampelan negatif rawak, beberapa data hingar juga akan diperkenalkan Oleh itu, kami menggunakan peraturan yang direka bentuk secara buatan untuk menafikan data latihan: Apabila niat kategori Pertanyaan adalah berbeza daripada Apabila sistem kategori POI agak konsisten atau sangat sepadan dengan nama POI, ia akan disingkirkan daripada sampel negatif.
Fasa kedua latihan berdasarkan data anotasi manual
Selepas fasa pertama latihan, memandangkan ia tidak boleh sepenuhnya Untuk mengeluarkan bunyi dalam data klik dan ciri-ciri tugas korelasi, adalah perlu untuk memperkenalkan latihan peringkat kedua berdasarkan sampel yang dilabel secara manual untuk membetulkan model. Selain daripada mengambil sampel secara rawak sebahagian daripada data dan menyerahkannya kepada anotasi manual, untuk meningkatkan keupayaan model sebanyak mungkin, kami menghasilkan sejumlah besar sampel bernilai tinggi melalui contoh perlombongan yang sukar dan peningkatan sampel perbandingan dan tangan. mereka ke anotasi manual. Butirannya adalah seperti berikut:
1)Contoh perlombongan yang sukar
- Jenis khusus perlombongan sampel: Dengan mereka bentuk kaedah untuk mencirikan jenis BadCase berdasarkan ciri Query dan POI dan padanan kedua-duanya, ia secara automatik memilih sampel jenis BadCase tertentu daripada set data calon untuk penyerahan.
- Pengguna telah mengklik tetapi model dalam talian lama dinilai sebagai tidak relevan: Kaedah ini boleh mencungkil ralat ramalan model dalam talian semasa dan Sukar untuk pengguna yang mempunyai semantik yang sama untuk membezakan antara mereka.
- Pensampelan tepi : Melombong sampel dengan ketidakpastian yang lebih tinggi melalui pensampelan tepi, seperti mengekstrak skor ramalan model berhampiran sampel ambang.
- Sampel yang sukar dikenal pasti oleh model atau secara manual : Gunakan model semasa untuk meramal set latihan, dan bandingkan keputusan ramalan model dengan sampel yang tidak konsisten dengan label berlabel dan sampel yang bercanggah dengan label berlabel manual Jenis sampel diserahkan semula.
2) Peningkatan sampel kontras: Gunakan idea pembelajaran kontrastif, hasilkan sampel kontras untuk beberapa sampel yang sangat sepadan untuk peningkatan data, dan lakukan anotasi manual Pastikan ketepatan label sampel. Dengan membandingkan perbezaan antara sampel, model boleh menumpukan pada maklumat yang benar-benar berguna dan meningkatkan keupayaan generalisasinya untuk sinonim, dengan itu mencapai hasil yang lebih baik.
- Mensasarkan masalah korelasi padanan silang hidangan yang mudah berlaku dengan perkataan hidangan (Sebagai contoh, mencari "foie gras burger" akan sepadan dengan jualan "burger daging lembu" dan "angsa" Peniaga "Sushi Hati" ) menggunakan setiap sub-komponen hidangan untuk memadankan medan hidangan yang disyorkan untuk menghasilkan sejumlah besar sampel perbandingan dan mengukuhkan keupayaan model untuk mengenal pasti isu padanan silang hidangan.
- Memandangkan masalah perkataan hidangan mencecah awalan hidangan yang disyorkan, keadaan telah diubah suai agar sepadan sepenuhnya dengan hidangan yang disyorkan ( Mencari "kek durian" sepadan dengan peniaga yang menjual "kek durian"), hanya mengekalkan awalan dalam istilah carian dan membina sampel perbandingan yang sepadan dengan awalan hidangan yang disyorkan (cari "durian" dan peniaga yang menjual "kek durian" ), supaya model boleh membezakan padanan Situasi dengan lebih baik apabila mengesyorkan awalan hidangan.
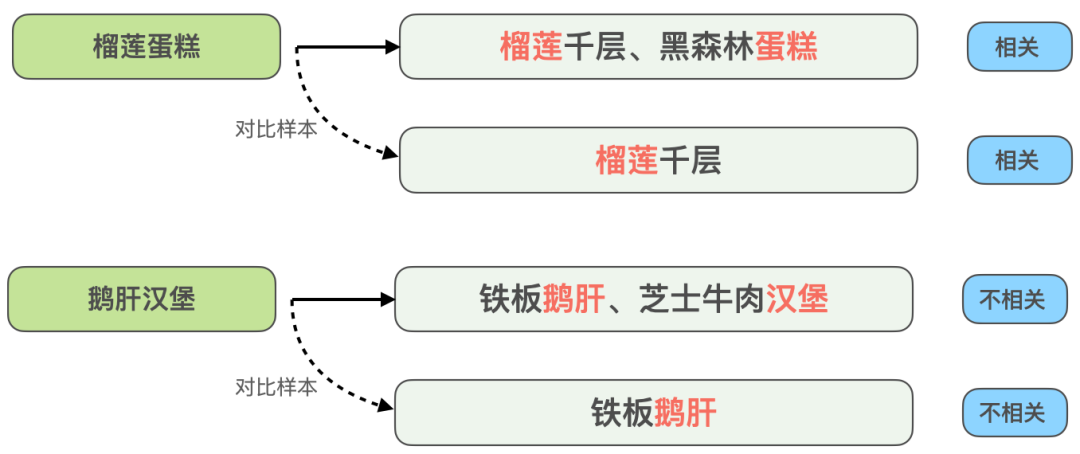
Rajah 6 Contoh perbandingan sampel peningkatan
untuk menyelesaikan masalah korelasi silang- padanan hidangan Contohnya, seperti yang ditunjukkan dalam Rajah 6 di atas, ia juga berlaku bahawa Query dipecah dan dipadankan dengan berbilang medan hidangan yang disyorkan oleh peniaga. Pertanyaan "Kek Durian" adalah berkaitan dengan hidangan yang disyorkan "Durian Seribu Krep, Black Forest Kek", tetapi Pertanyaan "Foie gras burger" dan "Sizzling foie gras, burger daging lembu keju" tidak berkaitan. Untuk meningkatkan keupayaan model untuk mengenal pasti kes yang sangat sepadan dengan hasil yang bertentangan, kami membina "kek durian" dan "durian". mille-feuille" ", "Foie Gras Burger" dan "Sizzling Foie Gras" ialah dua set sampel perbandingan Maklumat yang sepadan dengan teks Pertanyaan tetapi tidak membantu untuk pertimbangan model dialih keluar, membenarkan model mempelajari maklumat utama. yang benar-benar menentukan sama ada ia relevan Pada masa yang sama Meningkatkan keupayaan generalisasi model untuk sinonim seperti "kek" dan "seribu-lapisan". Begitu juga, jenis contoh sukar lain juga boleh menggunakan kaedah peningkatan sampel ini untuk meningkatkan kesannya.
3.2.2 Model interaksi mendalam berdasarkan pelbagai matriks kesamaan
PERhubungan antara ayat BERT ialah tugas NLP umum, digunakan untuk menentukan hubungan antara dua ayat, dan Tugas korelasi adalah untuk mengira korelasi antara Pertanyaan dan POI. Semasa proses pengiraan, tugas perhubungan antara ayat bukan sahaja mengira interaksi antara Pertanyaan dan POI, tetapi juga mengira interaksi dalam Pertanyaan dan dalam POI, manakala pengiraan korelasi memberi lebih perhatian kepada interaksi antara Pertanyaan dan POI. Di samping itu, semasa proses lelaran model, kami mendapati bahawa beberapa jenis kesukaran BadCase mempunyai keperluan yang lebih tinggi pada keupayaan ekspresif model, seperti jenis yang teksnya sangat dipadankan tetapi tidak relevan. Oleh itu, untuk meningkatkan lagi kesan pengiraan model pada tugasan Kolerasi Pertanyaan dan POI yang kompleks, kami mengubah tugasan perhubungan antara ayat BERT dalam latihan peringkat kedua dan mencadangkan model interaksi mendalam berdasarkan pelbagai matriks persamaan Dengan memperkenalkan Pelbagai persamaan matriks digunakan untuk berinteraksi secara mendalam antara Query dan POI, dan matriks penunjuk diperkenalkan untuk menyelesaikan masalah BadCase yang sukar Struktur model ditunjukkan dalam Rajah 7 di bawah:
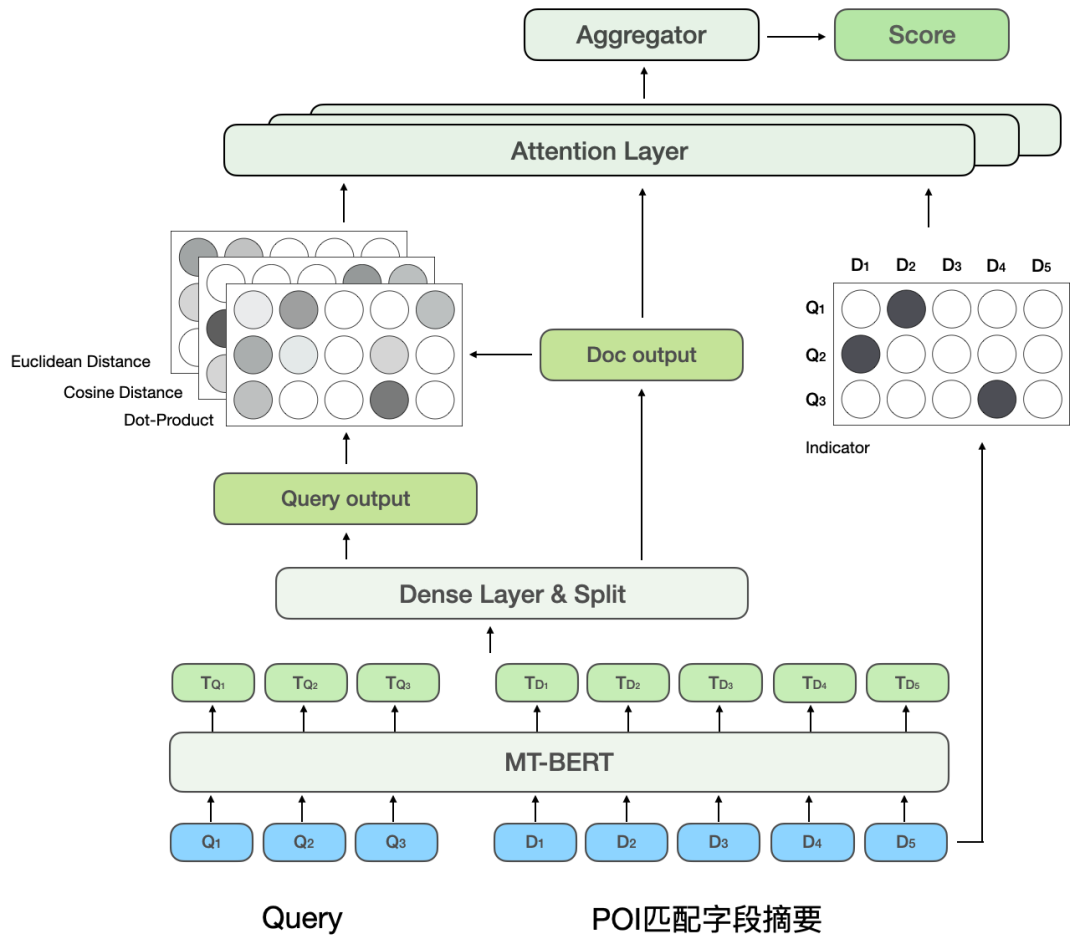 <.>
<.>
Rajah 7 Model korelasi silang dalam berdasarkan pelbagai matriks persamaan
Diinspirasikan oleh CEDR[8], kami akan mengekod MT -Vektor Pertanyaan BERT dan POI dipisahkan untuk mengira secara eksplisit hubungan interaksi yang mendalam antara dua bahagian dan POI dipecahkan dan berinteraksi secara mendalam Sebaliknya, peningkatan bilangan parameter boleh meningkatkan keupayaan pemasangan model.
Rujuk kepada model MatchPyramid[13] Model korelasi silang dalam mengira empat matriks persamaan Pertanyaan-Dokumen yang berbeza dan menggabungkannya, termasuk Penunjuk, Titik-. produk, jarak kosinus dan jarak Euclidean, dan berwajaran Perhatian dengan keluaran bahagian POI. Matriks Penunjuk digunakan untuk menerangkan sama ada Token Pertanyaan dan POI adalah konsisten Kaedah pengiraan adalah seperti berikut:
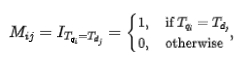
, yang mewakili. elemen yang sepadan dengan baris dan lajur matriks padanan, Token mewakili Pertanyaan dan Token mewakili POI. Memandangkan matriks Penunjuk ialah matriks yang menunjukkan sama ada Query dan POI benar-benar sepadan, format input bagi tiga matriks padanan semantik yang lain adalah berbeza. dan kemudian keputusan yang diperoleh digabungkan dengan matriks Penunjuk Matriks dicantumkan lagi sebelum mengira skor korelasi akhir.
Matriks penunjuk boleh menerangkan dengan lebih baik hubungan padanan antara Pertanyaan dan POI Pengenalan matriks ini terutamanya mengambil kira kesukaran dalam menentukan korelasi antara Pertanyaan dan POI: kadangkala walaupun teks sangat sepadan, kedua-duanya. tidak relevan. Struktur model BERT berasaskan interaksi memudahkan untuk menentukan Query dan POI dengan tahap pemadanan teks yang tinggi adalah berkaitan Walau bagaimanapun, dalam senario carian semakan, ini mungkin tidak berlaku dalam beberapa kes yang sukar. Sebagai contoh, walaupun "jus kacang" dan "jus kacang hijau" sangat dipadankan, ia tidak berkaitan. Walaupun "Maokong" dan "Cat's Sky Castle" adalah padanan yang berasingan, ia berkaitan kerana yang pertama adalah singkatan dari yang terakhir. Oleh itu, situasi padanan teks yang berbeza dimasukkan terus kepada model melalui matriks Penunjuk, membolehkan model menerima situasi padanan teks secara eksplisit seperti "mengandungi" dan "padanan berpecah", yang bukan sahaja membantu model meningkatkan keupayaannya untuk membezakan kes yang sukar. , tetapi juga Ia akan menjejaskan prestasi kebanyakan Kes biasa.
Model korelasi interaktif mendalam berdasarkan pelbagai matriks persamaan memisahkan Query dan POI dan kemudian mengira matriks persamaan, yang bersamaan dengan membenarkan model berinteraksi secara eksplisit dengan Query dan POI, menjadikan model lebih sesuai Tugasan berkaitan padanan. Matriks kesamaan berbilang meningkatkan keupayaan perwakilan model dalam mengira korelasi antara Pertanyaan dan POI, manakala matriks Penunjuk direka khas untuk situasi pemadanan teks yang kompleks dalam tugas korelasi, menjadikan pertimbangan model terhadap hasil yang tidak berkaitan lebih tepat.
3.3 Bagaimana untuk menyelesaikan kesesakan prestasi dalam talian bagi model korelasi pra-latihan
Apabila menggunakan pengiraan korelasi dalam talian, penyelesaian sedia ada biasanya menggunakan menara berkembar Struktur penyulingan pengetahuan [10,14] untuk memastikan kecekapan pengiraan dalam talian, tetapi kaedah pemprosesan ini lebih kurang memudaratkan kesan model. Semak pengiraan korelasi carian Untuk memastikan kesan model, model korelasi pra-latihan BERT 12 lapisan berdasarkan interaksi digunakan dalam talian, yang memerlukan ratusan POI di bawah setiap Pertanyaan untuk diramalkan oleh model BERT 12 lapisan. Untuk memastikan kecekapan pengkomputeran dalam talian, kami bermula dari dua perspektif proses pengkomputeran masa nyata model dan pautan aplikasi, dan dioptimumkan dengan memperkenalkan mekanisme caching, pecutan ramalan model, memperkenalkan lapisan peraturan pra-emas, menyelaraskan pengiraan korelasi dan pengisihan teras, dll. Kesesakan prestasi model korelasi apabila digunakan dalam talian membolehkan model korelasi BERT berasaskan interaksi 12 lapisan berjalan dengan stabil dan cekap dalam talian, memastikan ia boleh menyokong pengiraan korelasi antara ratusan pedagang dan Pertanyaan.
3.3.1 Pengoptimuman prestasi proses pengiraan model korelasi
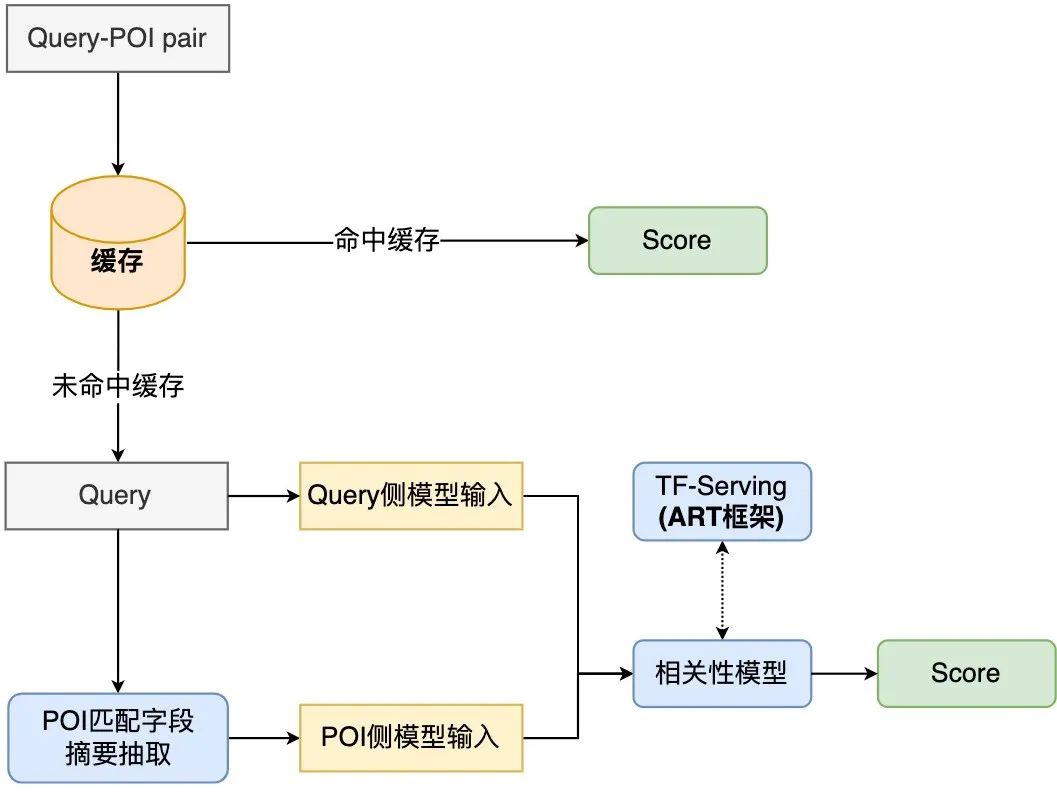
Rajah 8 Carta aliran pengiraan dalam talian model korelasi
Proses pengiraan dalam talian model korelasi carian semakan ditunjukkan dalam Rajah 8. Mekanisme caching dan pecutan ramalan model TF-Serving digunakan untuk mengoptimumkan prestasi pengiraan masa nyata model.
Untuk menggunakan sumber pengkomputeran dengan berkesan, penggunaan dalam talian model memperkenalkan mekanisme caching untuk menulis skor korelasi pertanyaan frekuensi tinggi ke dalam cache. Dalam panggilan berikutnya, cache akan dibaca terlebih dahulu Jika cache dipukul, skor akan dikeluarkan secara langsung. Mekanisme caching sangat menjimatkan sumber pengkomputeran dan dengan berkesan mengurangkan tekanan prestasi pengkomputeran dalam talian.
Untuk Pertanyaan yang terlepas cache, proseskannya sebagai input model sisi pertanyaan, dapatkan ringkasan medan sepadan bagi setiap POI melalui proses yang diterangkan dalam Rajah 4 dan proseskannya sebagai POI -model sisi Masukkan format, dan kemudian panggil model korelasi dalam talian untuk mengeluarkan skor korelasi. Model korelasi digunakan pada TF-Serving Semasa ramalan model, rangka kerja ART alat pengoptimuman model platform pembelajaran mesin Meituan digunakan (berdasarkan Faster-Transformer[15]diperbaiki ). Pecutan sangat meningkatkan kelajuan ramalan model sambil memastikan ketepatan.
3.3.2 Pengoptimuman prestasi pautan aplikasi
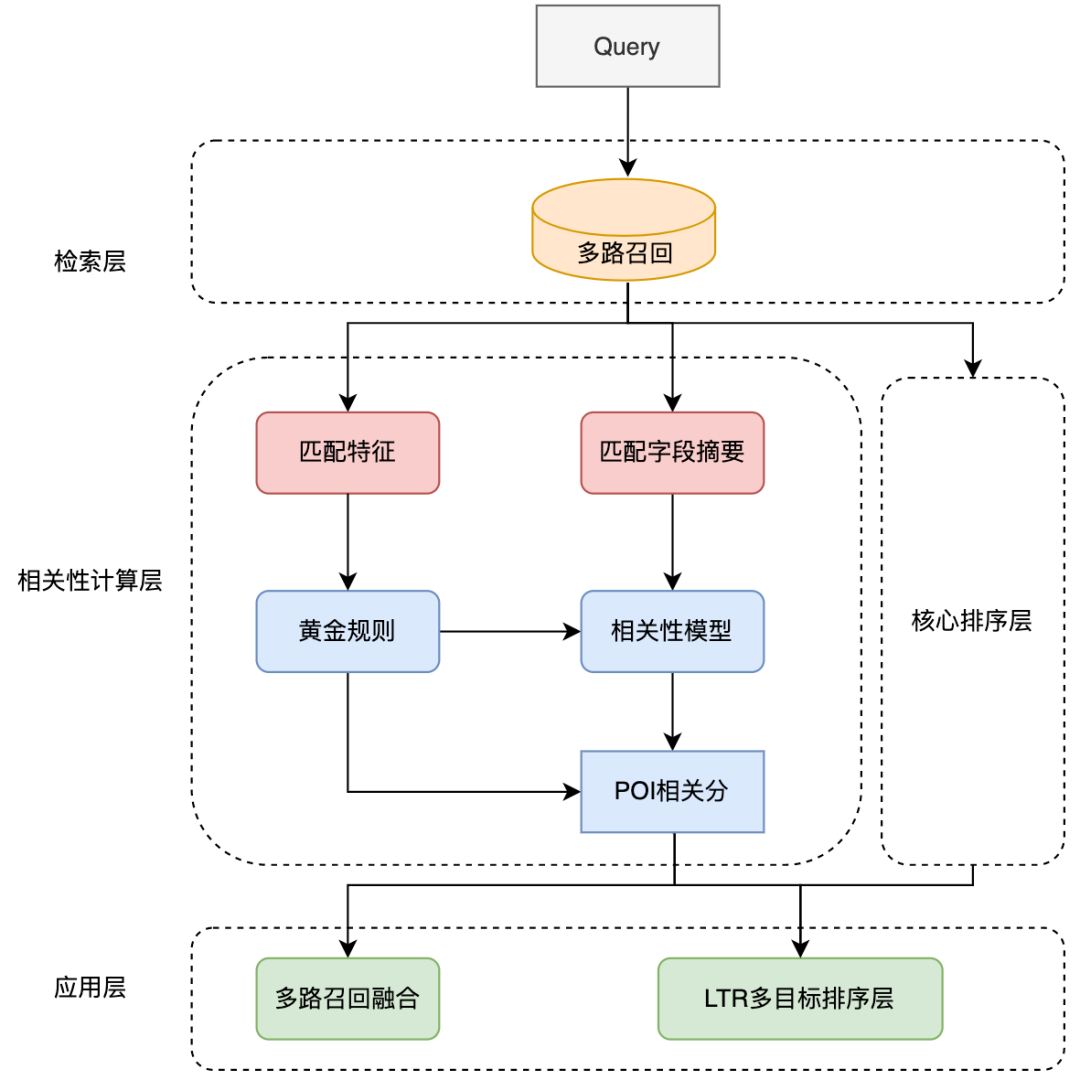
Rajah 9 Aplikasi model korelasi dalam pautan carian semakan
Aplikasi model korelasi dalam pautan carian ditunjukkan dalam Rajah 9 di atas dengan memperkenalkan peraturan pra-keemasan dan menyelaraskan pengiraan korelasi dengan lapisan pengisihan teras, prestasi keseluruhan carian dioptimumkan.
Untuk mempercepatkan lagi pautan panggilan korelasi, kami memperkenalkan peraturan pra-emas untuk mengalihkan Pertanyaan dan secara langsung mengeluarkan skor korelasi melalui peraturan untuk beberapa Pertanyaan, dengan itu memudahkan pengiraan model tekanan. Dalam lapisan peraturan emas, ciri padanan teks digunakan untuk menilai Pertanyaan dan POI Contohnya, jika istilah carian adalah betul-betul sama dengan nama pedagang, pertimbangan "berkaitan" dikeluarkan secara langsung melalui lapisan peraturan emas tanpa mengira korelasi. skor melalui model korelasi.
Dalam pautan pengiraan keseluruhan, proses pengiraan korelasi dan lapisan pengisihan teras dikendalikan serentak untuk memastikan pengiraan korelasi pada dasarnya tidak memberi kesan ke atas keseluruhan memakan masa pautan carian. Pada lapisan aplikasi, pengiraan korelasi digunakan dalam banyak aspek seperti mengingat semula dan menyusun pautan carian. Untuk mengurangkan perkadaran pedagang yang tidak berkaitan pada skrin pertama senarai carian, kami memperkenalkan skor perkaitan ke dalam pengisihan gabungan berbilang objektif LTR untuk mengisih halaman senarai, dan menggunakan strategi gabungan ingat berbilang hala Menggunakan keputusan daripada model korelasi, hanya laluan penarikan semula tambahan Pedagang berkaitan dalam digabungkan ke dalam senarai.
4. Aplikasi praktikal
4.1 Kesan luar talian
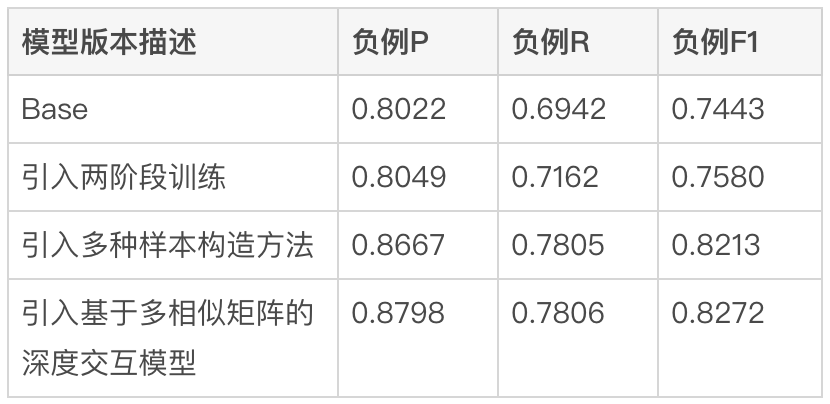
Untuk menggambarkan dengan tepat kesan luar talian lelaran model, kami membina model melalui berbilang pusingan anotasi manual. Penanda Aras Kelompok, memandangkan matlamat utama dalam penggunaan sebenar dalam talian semasa adalah untuk mengurangkan penunjuk BadCase, iaitu, untuk mengenal pasti pedagang yang tidak berkaitan dengan tepat, kami menggunakan ketepatan, kadar ingatan semula dan nilai F1 bagi contoh negatif sebagai penunjuk pengukuran. Faedah yang dibawa oleh latihan dua peringkat, pembinaan sampel dan lelaran model ditunjukkan dalam Jadual 1 di bawah:
Jadual 1 Semak lelaran model korelasi carian di luar talian Penunjuk
kaedah awal (Asas) menggunakan Pertanyaan untuk menyambung maklumat ringkasan medan padanan POI untuk tugas pengelasan pasangan ayat BERT Input model sisi Pertanyaan menggunakan asal Input pertanyaan oleh pengguna Bahagian POI menggunakan kaedah penyambungan teks nama pedagang, kategori pedagang dan ringkasan medan yang sepadan. Selepas pengenalan latihan dua peringkat berdasarkan data klik, indeks F1 contoh negatif meningkat sebanyak 1.84% berbanding kaedah Asas Dengan memperkenalkan sampel perbandingan dan sampel contoh yang sukar untuk meneruskan sampel latihan dan bekerjasama dengan struktur input model peringkat kedua. , contoh negatif indeks F1 berbanding dengan kaedah Asas Peningkatan ketara sebanyak 10.35%. Selepas pengenalan kaedah interaksi mendalam berdasarkan pelbagai matriks persamaan, contoh negatif F1 meningkat sebanyak 11.14% berbanding dengan Asas. Penunjuk keseluruhan model pada Penanda Aras juga mencapai nilai tinggi AUC sebanyak 0.96 dan F1 sebanyak 0.97.
4.2 Kesan Dalam Talian
Untuk mengukur kepuasan carian pengguna dengan berkesan, Carian Dianping sampel trafik dalam talian sebenar setiap hari dan melabelkannya secara manual, menggunakan BadCase pada halaman utama kadar halaman senarai sebagai penunjuk teras untuk menilai keberkesanan model korelasi. Selepas model korelasi dilancarkan, purata bulanan penunjuk kadar BadCase carian Dianping menurun dengan ketara sebanyak 2.9pp (Mata Peratusan, peratusan mata mutlak ) berbanding sebelum pelancaran dan penunjuk kadar BadCase stabil pada tahap rendah titik pada minggu-minggu berikutnya, pada masa yang sama, penunjuk NDCG halaman senarai carian telah meningkat secara berterusan sebanyak 2pp. Ia boleh dilihat bahawa model korelasi dapat mengenal pasti peniaga yang tidak berkaitan dengan berkesan dan mengurangkan kadar masalah yang tidak berkaitan dengan ketara pada skrin pertama carian, sekali gus meningkatkan pengalaman carian pengguna.
Rajah 10 di bawah menyenaraikan beberapa contoh penyelesaian BadCase dalam talian. Sari kata ialah Pertanyaan yang sepadan dengan contoh ialah kumpulan kawalan. Dalam Rajah 10(a), apabila istilah carian ialah "Pei Jie", model korelasi menentukan bahawa pedagang "Produk Terkenal Pei Jie" yang perkataan terasnya mengandungi "Pei Jie" adalah berkaitan dan memilih item mewah yang pengguna mungkin ingin mencari tetapi memasukkan secara salah Pedagang sasaran kualiti "Pei Jie Lao Hotpot" juga dinilai relevan Pada masa yang sama, dengan memperkenalkan pengecam medan alamat, pedagang di sebelah "Pei Jie" dalam alamat itu. dinilai tidak relevan Dalam Rajah 10(b), pengguna melepasi Pertanyaan "Youzi Ri "Makanan Layan Diri" ingin mencari kedai layan diri makanan Jepun bernama "Yuzu". Model korelasi akan memadankan perkataan berpecah kepada Kedai layan diri makanan Jepun "Tewako Tuna" yang menjual produk berkaitan Yuzu dan menilai dengan betul sebagai tidak relevan dan menetapkannya dengan sewajarnya. keperluan.
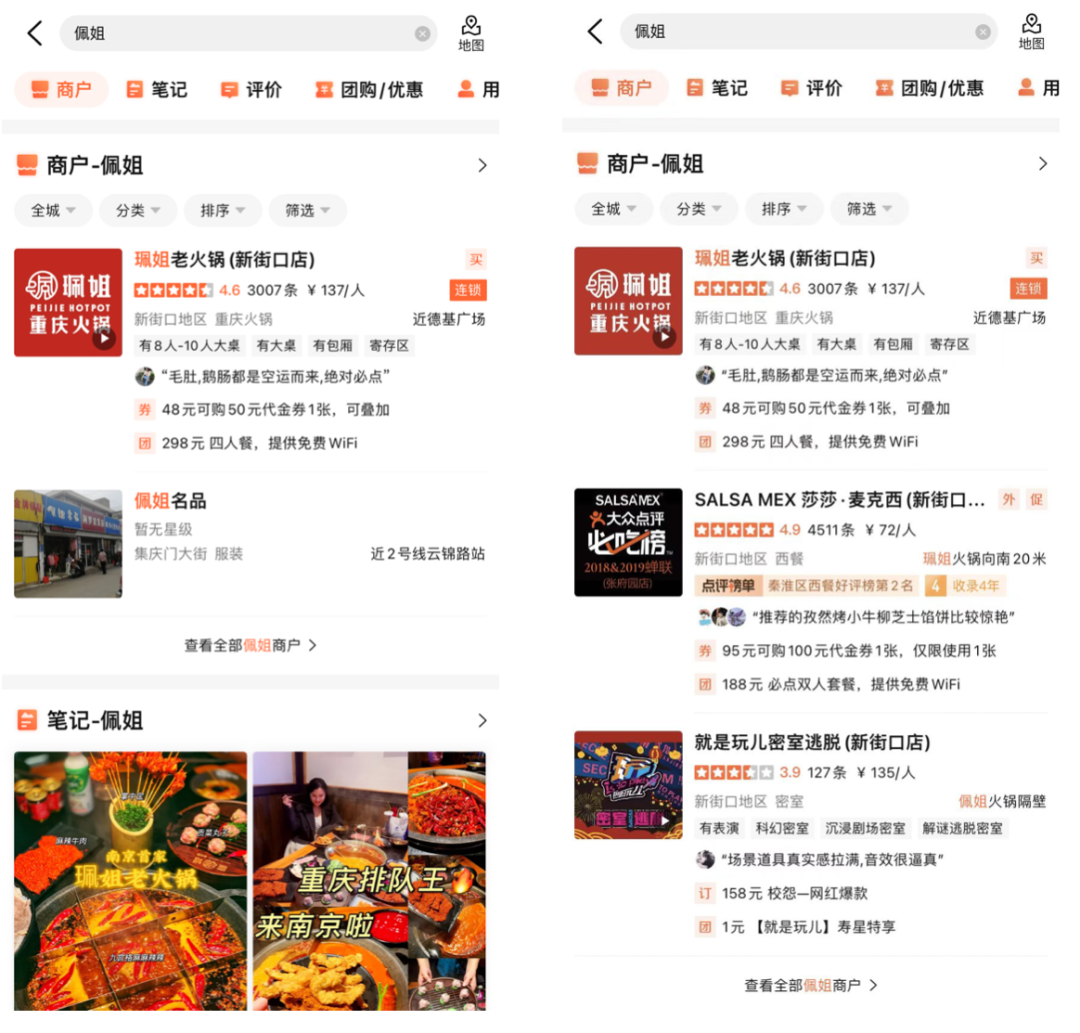
(a) Sister Pei
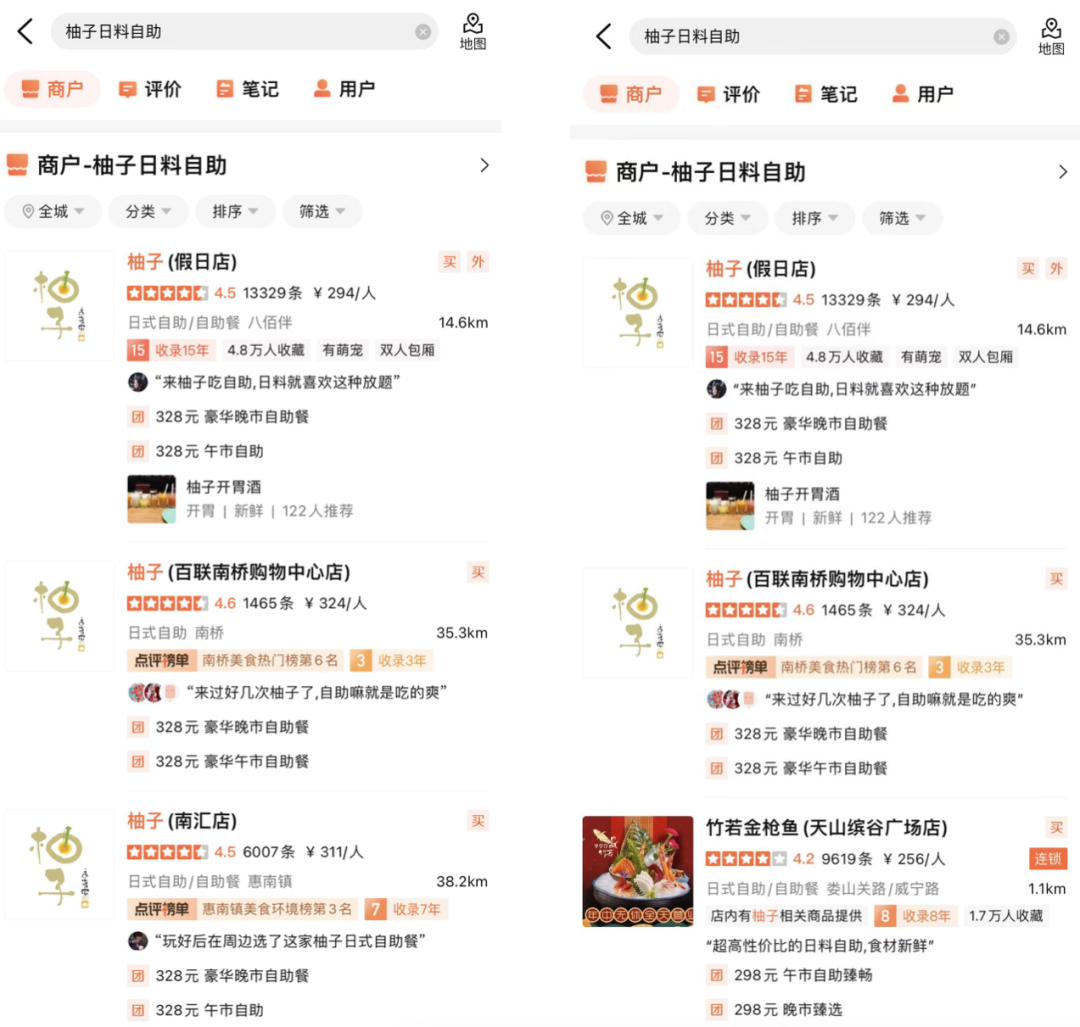 (b) Bufet Makanan Jepun PomeloRajah 10 Contoh penyelesaian BadCase Dalam Talian
(b) Bufet Makanan Jepun PomeloRajah 10 Contoh penyelesaian BadCase Dalam Talian
5. Ringkasan dan Tinjauan
Artikel ini memperkenalkan penyelesaian teknikal dan aplikasi praktikal model perkaitan carian Dianping. Untuk membina maklumat input model sisi pedagang dengan lebih baik, kami memperkenalkan kaedah mengekstrak teks ringkasan medan pemadanan pedagang dalam masa nyata untuk membina perwakilan pedagang sebagai input model untuk mengoptimumkan model untuk menyesuaikan diri dengan lebih baik untuk menyemak pengiraan korelasi carian, proses dua peringkat telah digunakan Kaedah latihan menggunakan skim latihan dua peringkat berdasarkan klik dan data anotasi manual untuk menggunakan data klik pengguna Dianping dengan berkesan Mengikut ciri-ciri pengiraan korelasi, struktur interaksi yang mendalam berdasarkan pelbagai persamaan matriks dicadangkan untuk menambah baik lagi model korelasi Untuk mengurangkan tekanan pengkomputeran dalam talian model korelasi, mekanisme caching dan pecutan ramalan TF-Serving diperkenalkan semasa penggunaan dalam talian, lapisan peraturan emas diperkenalkan untuk memunggah Query, dan pengiraan korelasi adalah selari dengan lapisan pengisihan teras, sekali gus memenuhi keperluan dalam talian untuk pengiraan masa nyata BERT. Dengan menggunakan model korelasi pada setiap pautan pautan carian, perkadaran soalan yang tidak berkaitan dikurangkan dengan ketara dan pengalaman carian pengguna dipertingkatkan dengan berkesan.
Pada masa ini, model korelasi carian semakan masih mempunyai ruang untuk penambahbaikan dalam prestasi model dan aplikasi dalam talian Dari segi struktur model, kami akan meneroka cara untuk memperkenalkan pengetahuan terdahulu dalam lebih banyak bidang contoh, pembelajaran berbilang tugas untuk mengenal pasti jenis entiti dalam Pertanyaan, input daripada model pengoptimuman pengetahuan luaran, dsb. dari segi aplikasi praktikal, ia akan diperhalusi lagi kepada lebih banyak tahap untuk memenuhi keperluan pengguna untuk carian kedai yang diperhalusi. Kami juga akan cuba menggunakan keupayaan perkaitan dengan modul bukan pedagang untuk mengoptimumkan pengalaman carian bagi keseluruhan senarai carian.
6. Pengenalan pengarang
Xiao Ya*, Shen Yuan*, Zhu Di, Tang Biao, Zhang Gong , dsb. , semuanya dari Pusat Teknologi Carian Bahagian Meituan/Dianping. * ialah pengarang bersama artikel ini.
Atas ialah kandungan terperinci Penerokaan dan amalan teknologi perkaitan carian Dianping. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI