
Rumah >Peranti teknologi >AI >Pengecaman niat pertanyaan berdasarkan peningkatan pengetahuan dan model besar yang telah dilatih sebelumnya
Pengecaman niat pertanyaan berdasarkan peningkatan pengetahuan dan model besar yang telah dilatih sebelumnya

- 王林ke hadapan
- 2023-05-19 14:01:441366semak imbas

1. Pengenalan latar belakang

Perusahaan Pendigitalan ialah topik hangat sejak beberapa tahun kebelakangan ini. Ia merujuk kepada penggunaan teknologi digital generasi baharu seperti kecerdasan buatan, data besar dan pengkomputeran awan untuk mengubah model perniagaan sesebuah perusahaan, sekali gus menggalakkan pertumbuhan baharu dalam perniagaan perusahaan. Pendigitalan perusahaan secara amnya merangkumi pendigitalan operasi perniagaan dan pendigitalan pengurusan perusahaan. Perkongsian ini terutamanya memperkenalkan pendigitalan tahap pengurusan perusahaan.
Pendigitalan maklumat, secara ringkasnya, bermaksud membaca, menulis, menyimpan dan menghantar maklumat secara digital. Daripada dokumen kertas sebelum ini kepada dokumen elektronik semasa dan dokumen kerjasama dalam talian, pendigitalan maklumat telah menjadi kebiasaan baharu di pejabat hari ini. Pada masa ini, Alibaba menggunakan Dokumen DingTalk dan Dokumen Yuque untuk kerjasama perniagaan, dan bilangan dokumen dalam talian telah mencecah lebih daripada 20 juta. Selain itu, banyak syarikat mempunyai komuniti kandungan dalaman mereka sendiri, seperti Alibaba Intranet dan Rangkaian Luaran Alibaba, dan komuniti teknikal ATA Pada masa ini, terdapat hampir 300,000 artikel teknikal dalam komuniti ATA, yang kesemuanya merupakan aset kandungan yang sangat berharga.
Pendigitalan proses merujuk kepada penggunaan teknologi digital untuk mengubah proses perkhidmatan dan meningkatkan kecekapan perkhidmatan. Akan ada banyak kerja transaksi seperti pentadbiran dalaman, IT, sumber manusia, dll. Sistem pengurusan proses BPMS boleh menyeragamkan proses kerja, merumuskan aliran kerja berdasarkan peraturan perniagaan, dan secara automatik melaksanakannya mengikut aliran kerja, yang boleh mengurangkan kos buruh dengan banyak. RPA digunakan terutamanya untuk menyelesaikan masalah pensuisan berbilang sistem dalam proses Kerana ia boleh mensimulasikan operasi input klik manual pada antara muka sistem, ia boleh menyambungkan pelbagai platform sistem. Arah pembangunan seterusnya pendigitalan proses ialah kecerdasan proses, direalisasikan melalui robot perbualan dan RPA. Pada masa kini, robot perbualan berasaskan tugas boleh membantu pengguna menyelesaikan beberapa tugas mudah dalam beberapa pusingan dialog, seperti meminta cuti, menempah tiket, dsb.
Matlamat pendigitalan perniagaan adalah untuk mewujudkan model perniagaan baharu melalui teknologi digital. Dalam perusahaan, sebenarnya terdapat beberapa pejabat pertengahan perniagaan, seperti pendigitalan perniagaan jabatan pembelian, yang merujuk kepada pendigitalan siri proses daripada carian produk, permulaan permohonan pembelian, penulisan kontrak pembelian, pembayaran, pelaksanaan pesanan, dsb. . Contoh lain ialah pendigitalan perniagaan pejabat tengah yang sah dengan mengambil pusat kontrak sebagai contoh, ia merealisasikan pendigitalan keseluruhan kitaran hayat kontrak daripada penggubalan kontrak kepada semakan kontrak, menandatangani kontrak dan prestasi kontrak.
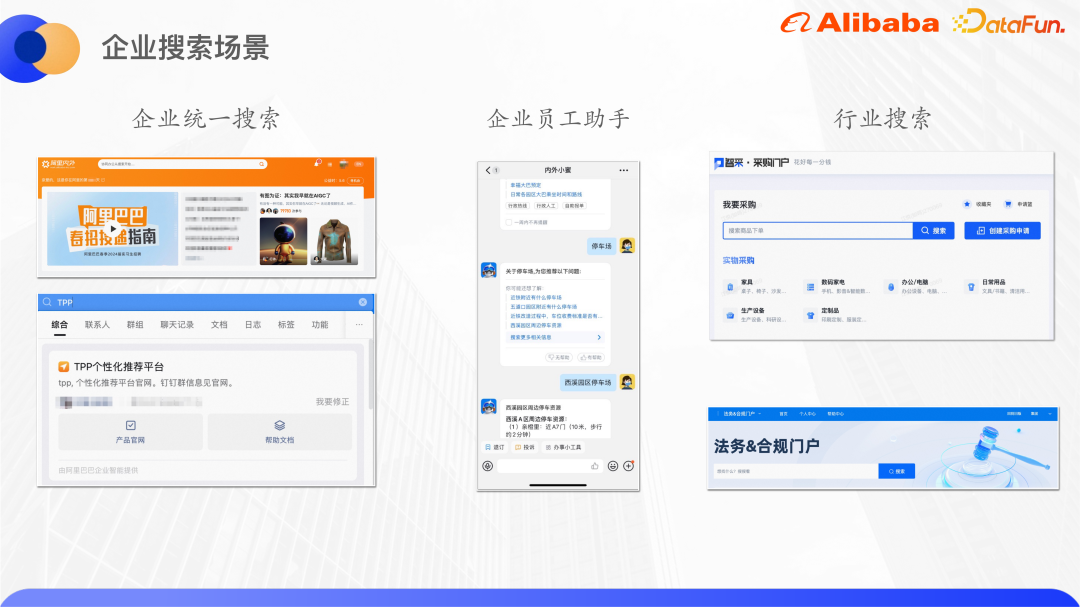
Data dan dokumen besar-besaran yang dijana melalui pendigitalan akan bertaburan dalam pelbagai sistem perniagaan, jadi adalah perlu untuk Enjin carian perusahaan pintar membantu pekerja mencari maklumat yang mereka cari dengan cepat. Mengambil Alibaba Group sebagai contoh, senario utama untuk carian perusahaan adalah seperti berikut:
(1) Carian bersatu, juga dikenali sebagai carian komprehensif, yang mengagregatkan berbilang Maklumat tentang tapak kandungan termasuk dokumen DingTalk, dokumen Yuque, ATA, dsb. Pintu masuk ke carian bersatu kini diletakkan pada Alibaba Dalaman dan Luar Alibaba dan versi DingTalk untuk pekerja sahaja. Trafik gabungan kedua-dua pintu masuk ini mencapai kira-kira 140 QPS, yang merupakan trafik yang sangat tinggi dalam senario ToB.
(2) Pembantu pekerja perusahaan merujuk kepada Xiaomi, robot perkhidmatan pintar untuk pekerja dalaman Alibaba, yang menyatukan HR, pentadbiran dan IT yang disediakannya. perkhidmatan soal jawab pengetahuan korporat dalam banyak bidang, serta saluran perkhidmatan pantas Termasuk pintu masuk DingTalk dan beberapa pintu masuk pemalam, terdapat kira-kira 250,000 orang yang membukanya, dan ia juga merupakan salah satu trafik kumpulan. jawatan.
(3) Carian industri sepadan dengan pendigitalan perniagaan yang dinyatakan dalam bab sebelumnya Sebagai contoh, perolehan mempunyai portal yang dipanggil Procurement Mall, di mana pembeli boleh mencari, memilih produk dan mengemukakan permintaan perolehan. Permohonan adalah serupa dengan laman web carian e-dagang, kecuali bahawa pengguna adalah pembeli korporat, perniagaan pematuhan undang-undang juga mempunyai portal yang sepadan, di mana pelajar undang-undang boleh mencari kontrak dan menjalankan beberapa tugas seperti penggubalan kontrak, kelulusan; , dan menandatangani .

Secara umumnya, setiap sistem perniagaan atau tapak kandungan dalam perusahaan akan mempunyai Carian sendiri sistem perniagaan perlu diasingkan antara satu sama lain, tetapi pengasingan laman kandungan akan membentuk fenomena pulau maklumat. Sebagai contoh, jika rakan sekelas teknikal menghadapi masalah teknikal, dia boleh pergi ke ATA terlebih dahulu untuk mencari artikel teknikal yang berkaitan dengan masalah tersebut. Jika dia tidak menemuinya, dia akan mencari kandungan yang serupa dalam Zhibo, Dokumen DingTalk dan Dokumen Yuque. , yang akan mengambil sebanyak empat atau lima carian ini sudah pasti sangat tidak cekap. Oleh itu, kami berharap untuk mengumpulkan kandungan ini ke dalam carian perusahaan bersatu, supaya semua maklumat yang berkaitan boleh diperolehi dengan hanya satu carian.
Selain itu, carian industri dengan atribut perniagaan secara amnya perlu diasingkan antara satu sama lain. Sebagai contoh, pengguna pusat beli-belah perolehan adalah pembeli kumpulan, dan pengguna pusat kontrak adalah hal ehwal undang-undang kumpulan Jumlah pengguna dalam dua senario carian ini adalah sangat kecil, jadi tingkah laku pengguna akan agak jarang dan bergantung. pada data tingkah laku pengguna, kesannya akan dikurangkan dengan ketara. Terdapat juga sedikit data beranotasi dalam bidang perolehan dan undang-undang, kerana ia memerlukan profesional untuk membuat anotasi dan kosnya tinggi, jadi sukar untuk mengumpul set data berkualiti tinggi.
Akhirnya, terdapat masalah padanan antara Pertanyaan dan dokumen Panjang Pertanyaan yang dicari pada dasarnya adalah dalam sedozen perkataan. Ia adalah teks pendek konteks, dan maklumat semantik tidak cukup kaya , Terdapat banyak kerja penyelidikan yang berkaitan dalam komuniti akademik untuk pemahaman teks pendek. Item yang dicari pada dasarnya adalah dokumen yang panjang, dengan bilangan aksara antara ratusan hingga ribuan Memahami dan mewakili kandungan dokumen yang panjang juga merupakan tugas yang sangat sukar.
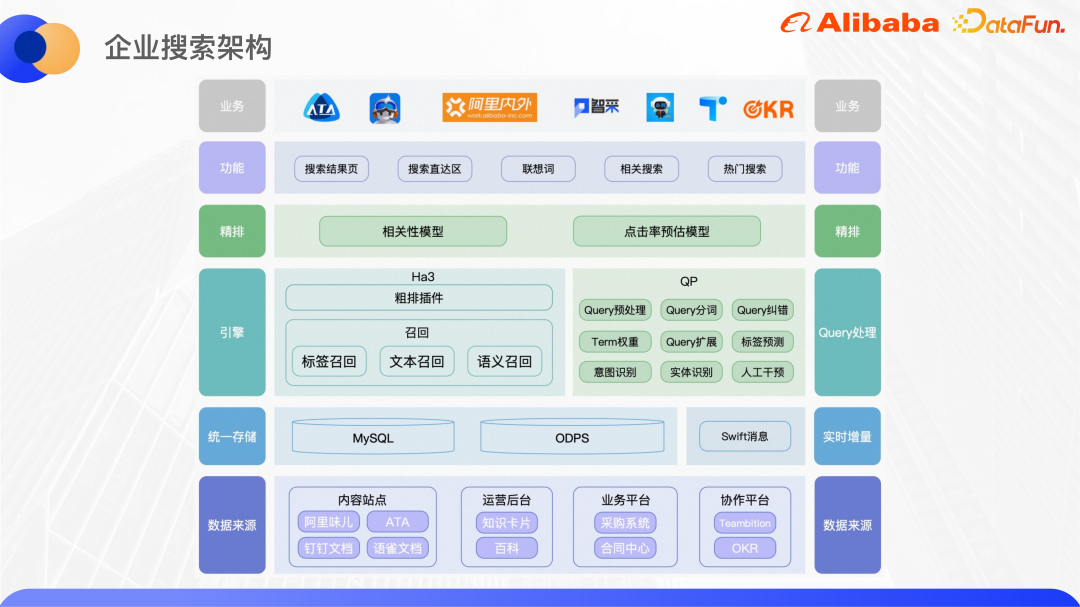
Gambar di atas menunjukkan seni bina asas carian perusahaan semasa kami. Di sini kami terutamanya memperkenalkan bahagian carian bersatu.
Pada masa ini, carian bersatu disambungkan kepada lebih daripada 40 tapak kandungan, termasuk ATA, Dokumen DingTalk dan Dokumen Yuque. Enjin Ha3 yang dibangunkan sendiri oleh Alibaba digunakan untuk memanggil semula dan pengisihan kasar Sebelum memanggil semula, perkhidmatan QP algoritma dipanggil untuk menganalisis pertanyaan pengguna dan menyediakan segmentasi pertanyaan, pembetulan ralat, berat istilah, pengembangan pertanyaan, pengecaman niat NER, dsb. Menurut keputusan QP dan logik perniagaan, rentetan pertanyaan dipasang pada bahagian enjin untuk dipanggil semula. Pemalam pengisihan kasar berdasarkan Ha3 boleh menyokong beberapa model pengisihan ringan, seperti GBDT dan sebagainya. Dalam peringkat kedudukan yang baik, model yang lebih kompleks boleh digunakan untuk pengisihan Model korelasi digunakan terutamanya untuk memastikan ketepatan carian, dan model anggaran kadar klikan secara langsung mengoptimumkan kadar klikan.
Selain pengisihan carian, ia juga mempunyai beberapa fungsi persisian carian lain, seperti kawasan carian langsung kotak lungsur carian, yang dikaitkan perkataan, carian berkaitan dan Carian popular dsb. Pada masa ini, perkhidmatan yang disokong oleh lapisan atas terutamanya adalah carian bersatu di dalam dan di luar Alibaba dan Alibaba DingTalk, carian menegak untuk pemerolehan dan hal ehwal undang-undang, dan pemahaman Pertanyaan tentang sistem ATA Teambition OKR.
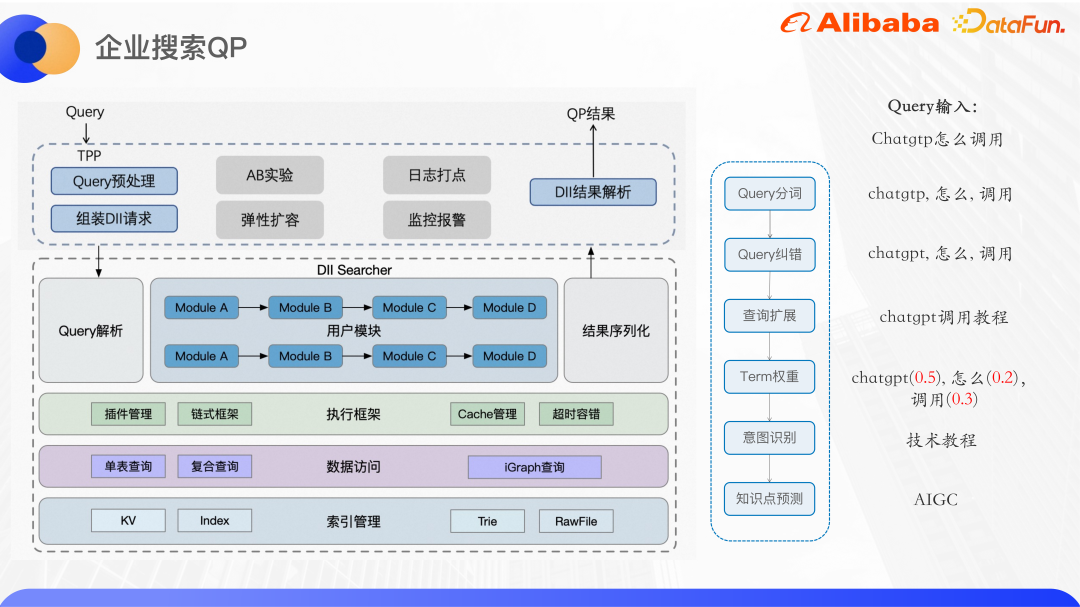
Gambar di atas ialah seni bina umum QP carian perusahaan Perkhidmatan QP digunakan pada platform perkhidmatan dalam talian algoritma yang dipanggil DII. Platform DII boleh menyokong pembinaan dan pertanyaan jadual KV dan indeks jadual indeks Ia merupakan rangka kerja rantaian secara keseluruhan, dan logik perniagaan yang kompleks perlu dibahagikan kepada modul perniagaan yang agak bebas dan padu. Sebagai contoh, perkhidmatan QP carian di dalam dan di luar Alibaba dibahagikan kepada beberapa modul berfungsi seperti pembahagian perkataan, pembetulan ralat, pengembangan pertanyaan, berat istilah dan pengecaman niat. Kelebihan rangka kerja rantaian ialah ia memudahkan pembangunan kolaboratif oleh berbilang orang Setiap orang bertanggungjawab untuk pembangunan modul mereka sendiri Selagi antara muka hulu dan hiliran dipersetujui, perkhidmatan QP yang berbeza boleh menggunakan semula modul yang sama, mengurangkan. kod pendua. Di samping itu, lapisan dibalut pada perkhidmatan algoritma asas untuk menyediakan antara muka TPP kepada dunia luar. TPP ialah platform pengesyoran algoritma matang dalam Alibaba Ia boleh menjalankan eksperimen AB dan pengembangan elastik dengan mudah. Mekanisme pengurusan dan pemantauan log juga sangat matang.
Lakukan prapemprosesan Pertanyaan pada bahagian TPP, kemudian kumpulkan permintaan DII, panggil perkhidmatan algoritma DII, huraikan hasilnya selepas memperolehnya, dan akhirnya kembalikan kepada pemanggil.
2. Perkongsian Kerja
Berikut memperkenalkan kerja pengecaman niat pertanyaan dalam dua senario perusahaan.
1 Dalaman dan luaran Xiaomi
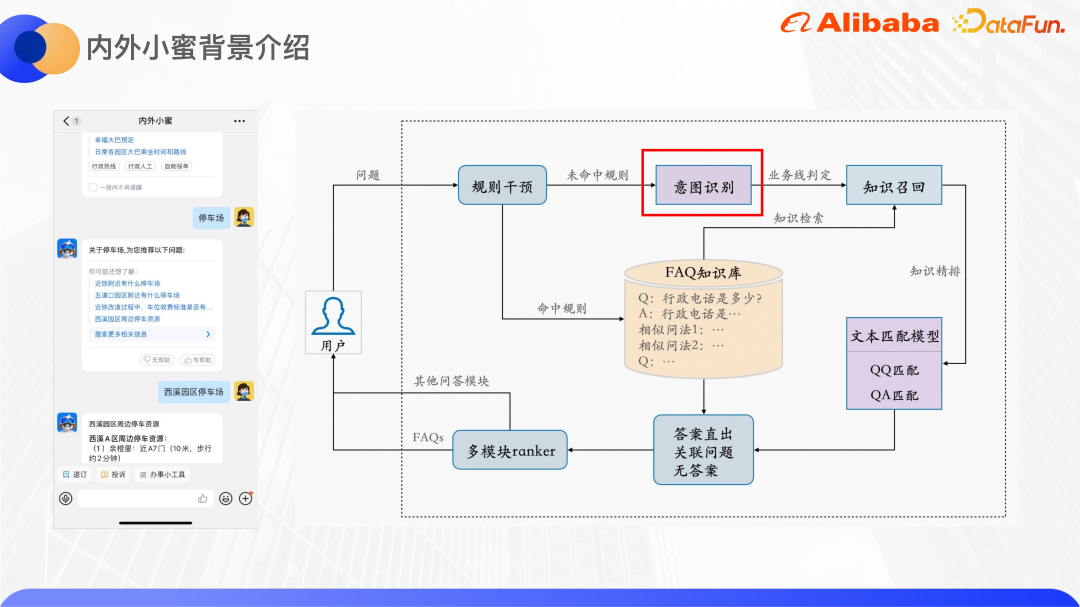
Lapisan bawah dalaman dan Xiaomi luaran adalah berdasarkan Enjin Soal Jawab Yunxiaomi yang dilancarkan oleh Akademi DAMO boleh menyokong Soal Jawab Soalan Lazim, Soal Jawab tugas pelbagai pusingan dan Soal Jawab graf pengetahuan. Bahagian kanan gambar di atas menunjukkan rangka kerja umum enjin soalan dan jawapan FAQ.
Selepas pengguna memasukkan Pertanyaan, akan ada modul campur tangan peraturan, yang membolehkan perniagaan dan operasi menetapkan beberapa peraturan jika peraturan itu dipukul. ia akan terus Kembalikan jawapan yang ditetapkan Jika tiada peraturan dipukul, algoritma akan digunakan. Modul pengecaman niat meramalkan Pertanyaan pengguna kepada baris perniagaan yang sepadan Terdapat banyak pasangan QA dalam pangkalan pengetahuan Soalan Lazim bagi setiap baris perniagaan, dan setiap soalan akan dikonfigurasikan dengan beberapa soalan yang serupa. Gunakan Pertanyaan untuk mendapatkan set calon pasangan QA dalam pangkalan pengetahuan, dan kemudian gunakan modul pemadanan teks untuk memperhalusi pasangan QA Berdasarkan skor model, ia dinilai sama ada jawapannya adalah langsung, soalan berkaitan disyorkan atau di sana tiada jawapan. Selain enjin soal jawab FAQ, akan ada juga enjin soal jawab yang lain seperti soal jawab berasaskan tugas dan soal jawab graf pengetahuan Oleh itu, penaraf berbilang modul akhirnya direka untuk memilih jawapan enjin yang mana mendedahkan kepada pengguna.
Yang berikut memfokuskan pada modul pengecaman niat.
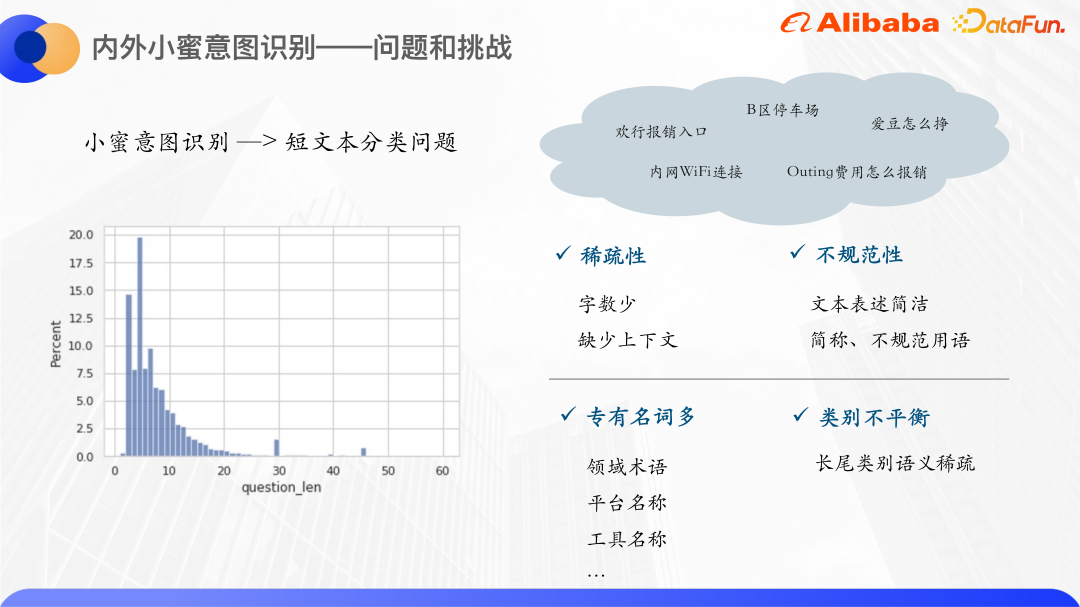
Dengan mengira pertanyaan pengguna Xiaomi di dalam dan di luar tahun lalu, kami mendapati bahawa kebanyakan pengguna Bilangan perkataan Pertanyaan tertumpu antara 0-20, dan lebih daripada 80% perkataan Pertanyaan berada dalam lingkungan 10. Oleh itu, pengecaman niat Xiaomi adalah masalah klasifikasi teks pendek Bilangan teks pendek adalah sangat kecil. jadi jika model ruang vektor tradisional digunakan Perwakilan akan menyebabkan ruang vektor menjadi jarang. Dan secara amnya, ungkapan teks pendek tidak begitu piawai, dengan banyak singkatan dan istilah yang tidak teratur, jadi terdapat lebih banyak fenomena OOV.
Satu lagi ciri Pertanyaan teks pendek Xiaomi ialah terdapat banyak kata nama khas, biasanya nama platform dan alat dalaman, seperti Huanxing, Idou dan sebagainya. Teks kata nama khas ini sendiri tidak mempunyai maklumat semantik yang berkaitan dengan kategori, jadi sukar untuk mempelajari perwakilan semantik yang berkesan, jadi kami berfikir untuk menggunakan peningkatan pengetahuan untuk menyelesaikan masalah ini.
Peningkatan pengetahuan am akan menggunakan graf pengetahuan sumber terbuka, tetapi kata nama khas dalam perusahaan tidak dapat mencari entiti yang sepadan dalam graf pengetahuan sumber terbuka, jadi kami Hanya carilah ilmu dari dalam. Kebetulan Alibaba mempunyai fungsi carian kad pengetahuan sepadan dengan produk intranet Ia sangat berkaitan dengan bidang Xiaomi di dalam dan di luar Sebagai contoh, Huanxing dan Idou boleh mencari maklumat yang berkaitan di sini kad pengetahuan digunakan sebagai sumber pengetahuan.
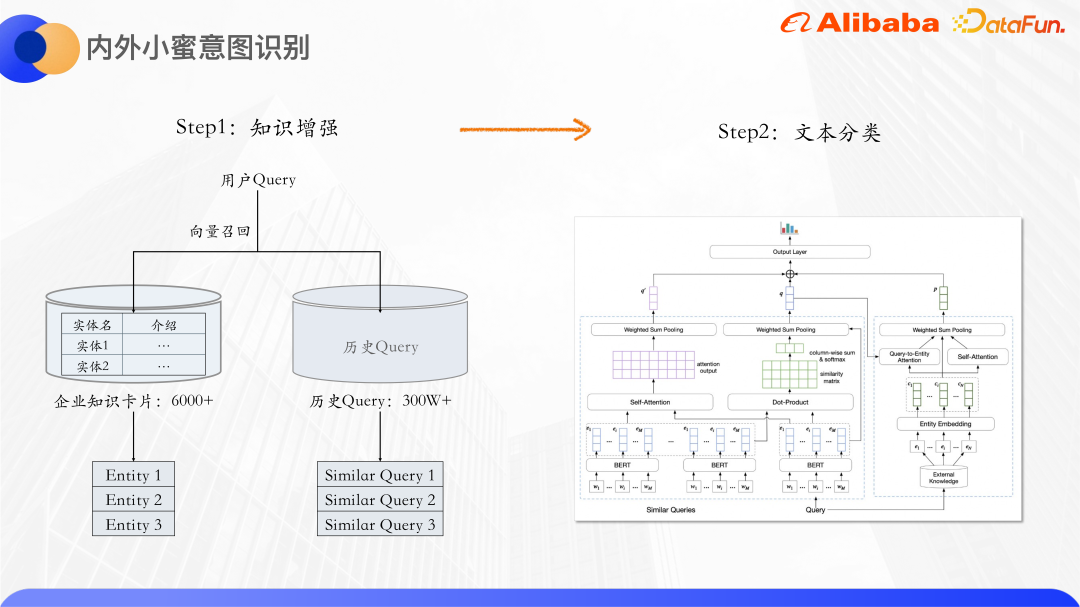
Kaedah ini terbahagi kepada dua langkah:
Pertama ialah peningkatan pengetahuan, dengan jumlah lebih daripada 6,000 Setiap kad pengetahuan mempunyai nama entiti dan pengenalan teks Menurut pertanyaan pengguna, kad pengetahuan yang berkaitan dengannya dipanggil semula, dan pertanyaan sejarah juga digunakan, kerana terdapat banyak pertanyaan yang serupa, seperti sambungan Wifi intranet, sambungan intranet Wifi, dsb. Pertanyaan serupa boleh menambah maklumat semantik satu sama lain dan seterusnya mengurangkan keterlaluan teks pendek. Selain entiti kad pengetahuan, pertanyaan serupa akan dipanggil semula dan pertanyaan asal dihantar ke model pengelasan teks untuk pengelasan.
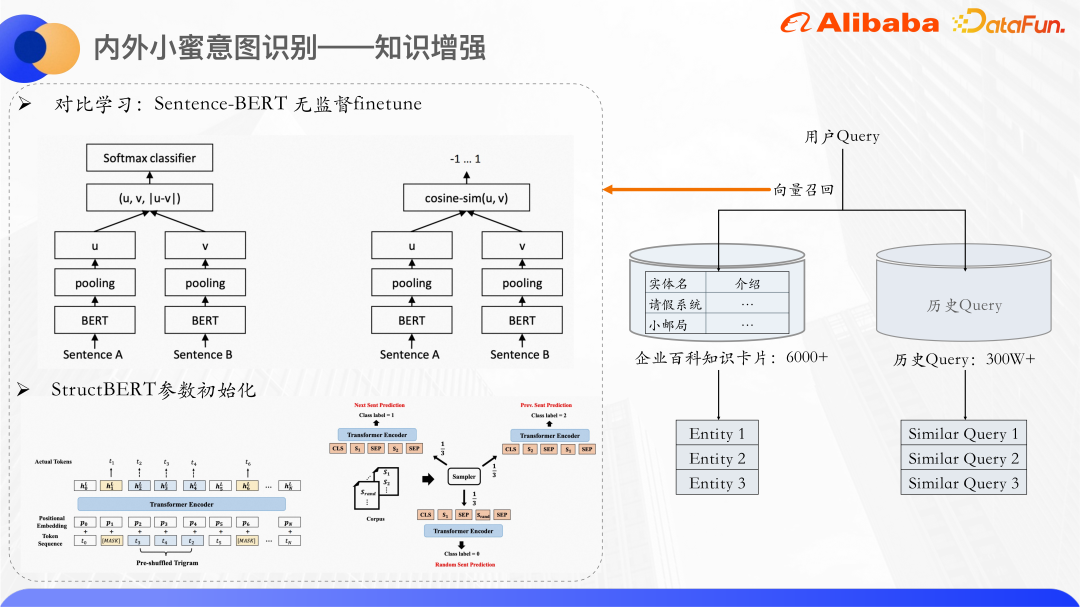
Gunakan ingatan vektor untuk memanggil balik entiti kad pengetahuan dan pertanyaan serupa. Gunakan Bert untuk mengira kuantiti konkrit bagi keterangan teks pertanyaan dan kad pengetahuan masing-masing. Secara umumnya, vektor CLS Bert tidak digunakan secara langsung sebagai representasi ayat Banyak kertas juga menyebut bahawa secara langsung menggunakan vektor CLS sebagai representasi ayat akan mempunyai hasil yang buruk kerana vektor yang dikeluarkan oleh Bert akan mengalami masalah degradasi ekspresi dan tidak sesuai untuk digunakan secara langsung melakukan pengiraan persamaan tanpa pengawasan, jadi ia menggunakan idea pembelajaran kontrastif untuk mendekatkan sampel yang serupa dan mengedarkan sampel yang berbeza sekata yang mungkin.
Secara khusus, Ayat-Bert adalah penyempurnaan pada set data, dan struktur model serta kaedah latihannya boleh menghasilkan perwakilan vektor ayat yang lebih baik. Ia adalah struktur dua menara. Model Bert pada kedua-dua belah parameter model kedua-dua dimasukkan ke dalam Bert Selepas menggabungkan output keadaan tersembunyi oleh Bert, vektor ayat kedua-dua ayat akan diperolehi. Matlamat pengoptimuman di sini ialah kehilangan pembelajaran perbandingan, infoNCE.
Contoh positif: Terus masukkan sampel ke dalam model dua kali, tetapi keciciran dua kali ini ialah adalah berbeza, jadi vektor yang diwakili juga akan berbeza sedikit.
Contoh negatif: Semua ayat lain dalam kelompok yang sama.
Dengan mengoptimumkan Kehilangan ini, kami mendapat model Sentence-Bert untuk meramalkan vektor ayat.
Kami menggunakan parameter model StructBERT untuk memulakan bahagian Bert di sini. StructBERT ialah model pra-latihan yang dicadangkan oleh DAMO Academy Struktur modelnya adalah sama dengan BERT asli Idea utamanya adalah untuk memasukkan maklumat struktur bahasa ke dalam tugas pra-latihan untuk mendapatkan vektor ayat dan kad pengetahuan pertanyaan. Melalui pengiraan Persamaan kosinus vektor mengimbas kembali k teratas kad pengetahuan yang paling serupa dan pertanyaan serupa.
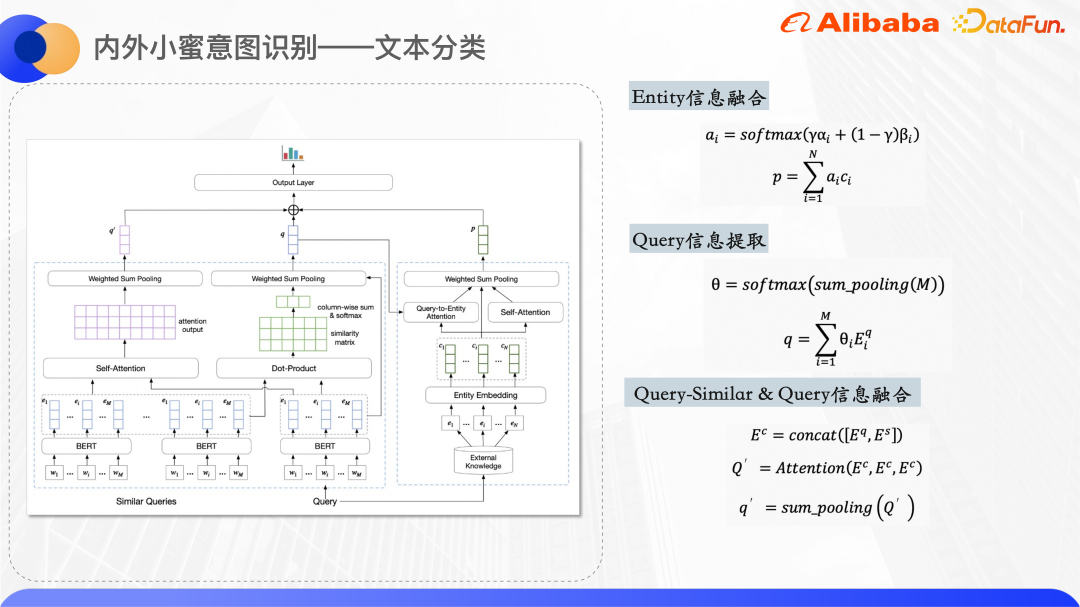
Gambar di atas ialah struktur model klasifikasi teks, menggunakan Bert dalam lapisan Pengekodan Ekstrak perwakilan pertanyaan asal dan vektor perkataan bagi pertanyaan serupa Setiap entiti kad pengetahuan mengekalkan pembenaman ID entiti dan pembenaman ID dimulakan secara rawak.
Sebelah kanan gambar rajah struktur model digunakan untuk memproses entiti yang dipanggil semula oleh pertanyaan dan mendapatkan perwakilan vektor bersatu bagi entiti tersebut. Oleh kerana teks pendek itu sendiri agak kabur, entiti kad pengetahuan yang ditarik balik juga akan mempunyai jumlah hingar tertentu Dengan menggunakan dua mekanisme perhatian, model boleh memberi lebih perhatian kepada entiti yang betul. Satu ialah Perhatian Pertanyaan-kepada-Entiti, yang bertujuan untuk menjadikan model memberi lebih perhatian kepada entiti yang berkaitan dengan pertanyaan. Yang lain ialah Perhatian kendiri entiti itu sendiri, yang boleh meningkatkan berat entiti yang serupa antara satu sama lain dan mengurangkan berat entiti yang bising. Menggabungkan dua set pemberat Perhatian, perwakilan vektor entiti akhir diperolehi.
Sebelah kiri gambar rajah struktur model adalah untuk memproses pertanyaan asal dan pertanyaan serupa Kerana diperhatikan bahawa perkataan bertindih bagi pertanyaan serupa dan pertanyaan asal boleh mencirikan perkataan pusat pertanyaan pada tahap tertentu, jadi di sini kita mengira Klik antara dua perkataan untuk mendapatkan matriks persamaan dan melakukan pengumpulan jumlah untuk mendapatkan berat setiap perkataan dalam pertanyaan asal yang agak serupa dengan pertanyaan model memberi lebih perhatian kepada perkataan pusat, dan kemudian menggabungkan vektor perkataan bagi pertanyaan yang serupa dan pertanyaan asal bersama-sama dan mengira maklumat semantik yang digabungkan.
Akhir sekali, ketiga-tiga vektor di atas disambungkan bersama, dan kebarangkalian setiap kategori diperoleh melalui ramalan lapisan padat.
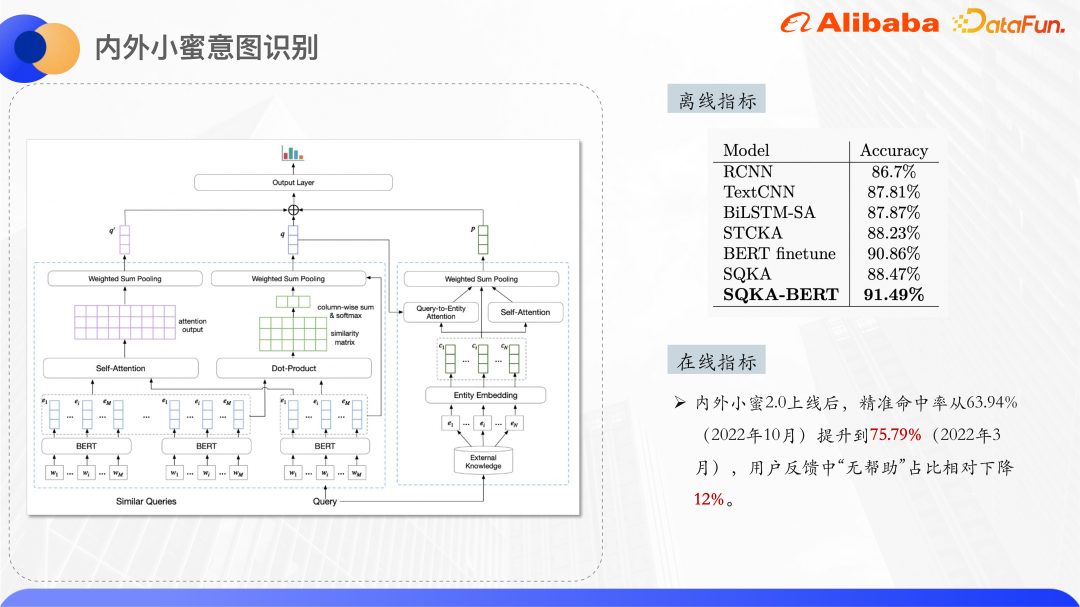
Di atas adalah keputusan percubaan, yang melebihi keputusan BERT finetune tidak digunakan dalam lapisan pengekodan , juga melebihi semua model bukan Bert.
2. Carian industri
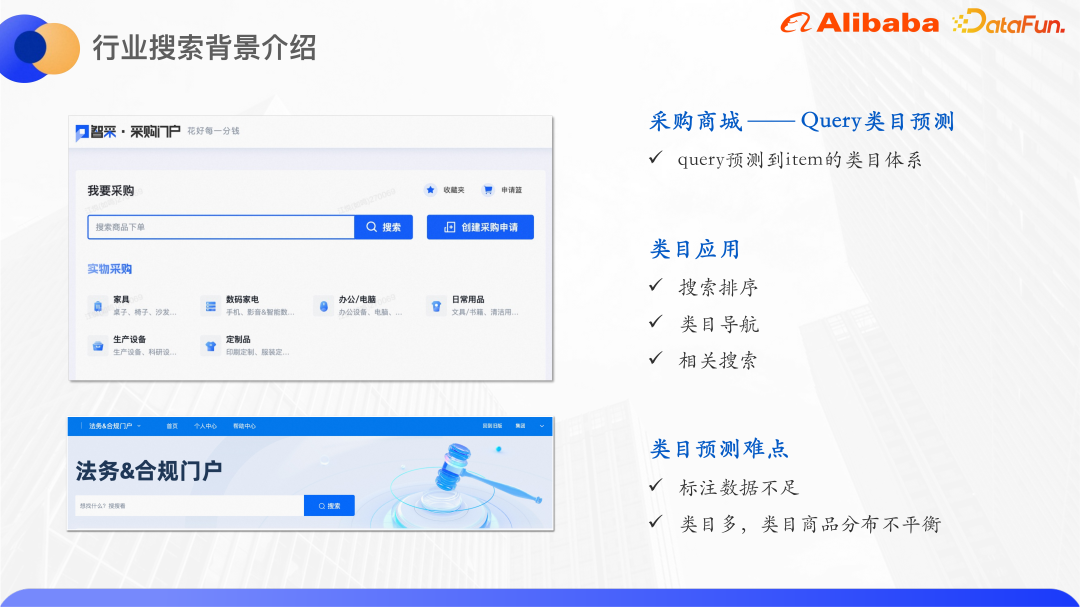
Ambil pusat beli-belah perolehan sebagai contoh . Pusat membeli-belah mempunyai sistem kategori produknya sendiri, dan setiap produk akan disenaraikan di bawah kategori produk sebelum diletakkan di rak. Untuk meningkatkan ketepatan carian pusat membeli-belah, adalah perlu untuk meramalkan pertanyaan kepada kategori tertentu, dan kemudian melaraskan hasil kedudukan carian mengikut kategori ini Anda juga boleh memaparkan navigasi sub-kategori dan carian berkaitan pada antara muka berdasarkan keputusan kategori.
Ramalan kategori memerlukan set data yang dilabel secara manual, tetapi dalam bidang perolehan, kos pelabelan agak tinggi, jadi masalah ini diselesaikan dari perspektif kecil pengelasan sampel.
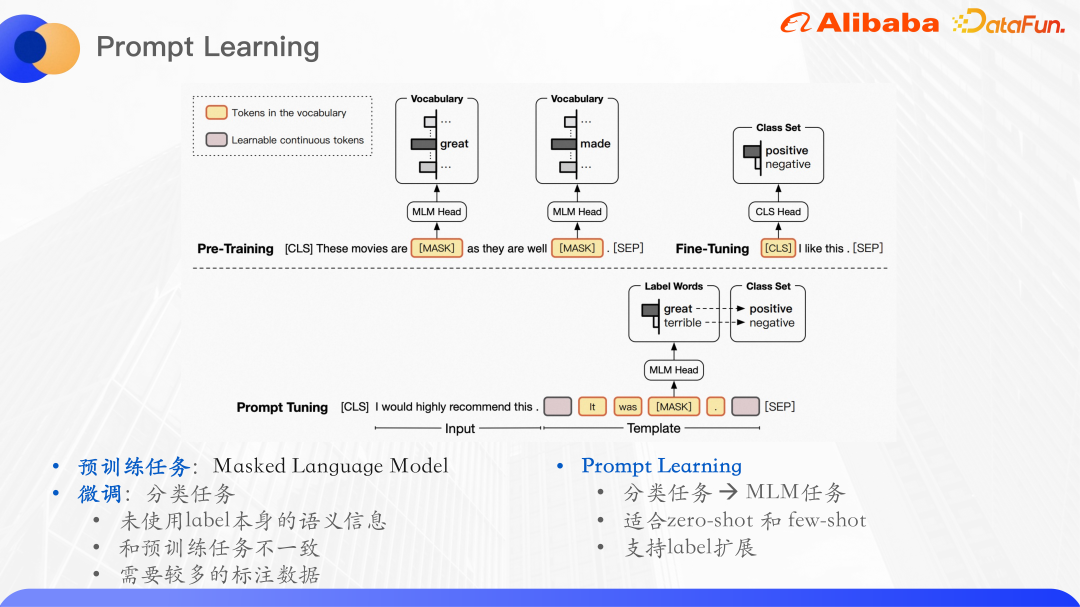
Model pra-latihan telah menunjukkan keupayaan pemahaman bahasa yang kukuh pada tugasan NLP paradigma yang digunakan adalah untuk pralatih pada set data tidak berlabel berskala besar dan kemudian memperhalusi tugas hiliran yang diselia. Sebagai contoh, tugas pra-latihan Bert adalah terutamanya model bahasa topeng, yang bermaksud menutup sebahagian daripada perkataan secara rawak dalam ayat, memasukkannya ke dalam model asal, dan kemudian meramalkan perkataan dalam bahagian topeng untuk memaksimumkan kemungkinan perkataan.
Ramalan kategori pertanyaan pada asasnya ialah tugas pengelasan teks Tugas pengelasan teks adalah untuk meramalkan input kepada ID label tertentu, dan ini tidak menggunakan label itu sendiri Maklumat semantik, tugas klasifikasi yang diperhalusi dan tugasan pra-latihan adalah tidak konsisten, dan model bahasa yang dipelajari daripada tugasan pra-latihan tidak dapat dimaksimumkan, jadi model bahasa pra-latihan baharu telah muncul.
Paradigma model bahasa pra-latihan dipanggil pembelajaran segera boleh difahami sebagai petunjuk kepada model bahasa pra-latihan untuk membantunya memahami masalah manusia dengan lebih baik. Khususnya, perenggan tambahan ditambahkan pada teks input Dalam perenggan ini, perkataan yang berkaitan dengan label akan bertopeng, dan kemudian model akan digunakan untuk meramalkan perkataan pada kedudukan topeng, sekali gus menukar tugas pengelasan kepada topeng. model bahasa. Tugas, selepas meramalkan perkataan pada kedudukan topeng, selalunya perlu untuk memetakan perkataan ke set label untuk perolehan adalah masalah klasifikasi sampel kecil yang biasa dibina untuk tugas ramalan kategori maka topeng itu dijatuhkan Bahagian itu adalah perkataan yang perlu diramalkan.
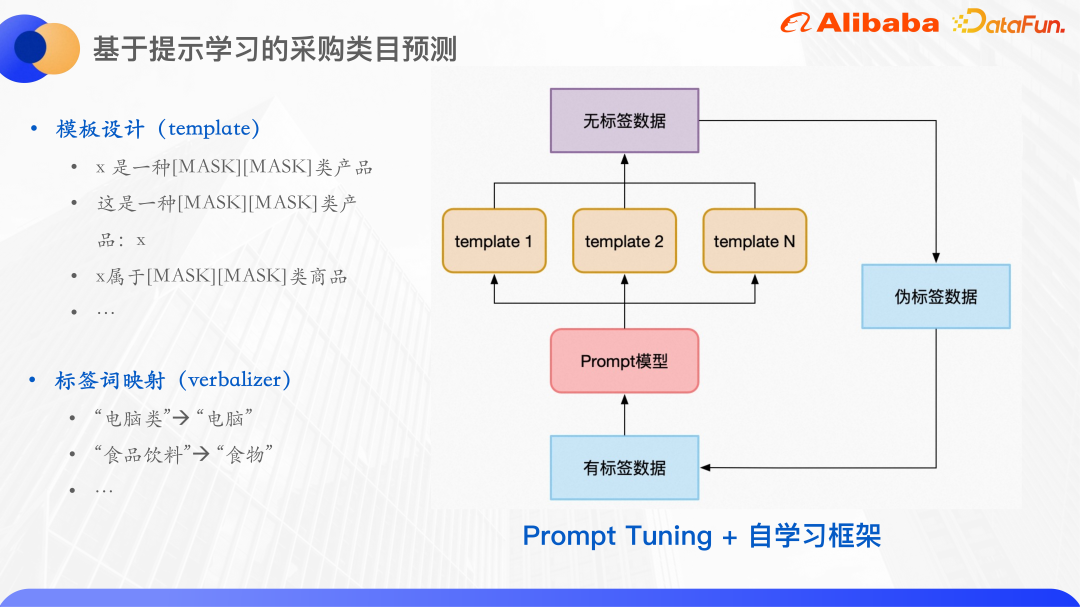
Untuk templat, pemetaan daripada perkataan ramalan kepada menandakan perkataan diwujudkan.
Pertama sekali, perkataan ramalan tidak semestinya label. Kerana untuk memudahkan latihan, bilangan watak topeng untuk setiap sampel adalah sama Kata label asal mempunyai 3 aksara, 4 aksara, dsb. Di sini, perkataan ramalan dan perkataan label dipetakan dan disatukan menjadi dua aksara.
Selain itu, berdasarkan pembelajaran segera, menggunakan rangka kerja pembelajaran kendiri, mula-mula gunakan data berlabel untuk melatih model bagi setiap templat, dan kemudian menyepadukan beberapa model untuk meramal data tidak berlabel dan melatih Dalam satu pusingan , sampel dengan keyakinan tinggi dipilih sebagai data pseudo-label dan ditambah pada set latihan, dengan itu memperoleh lebih banyak data berlabel, dan kemudian melatih satu pusingan model.
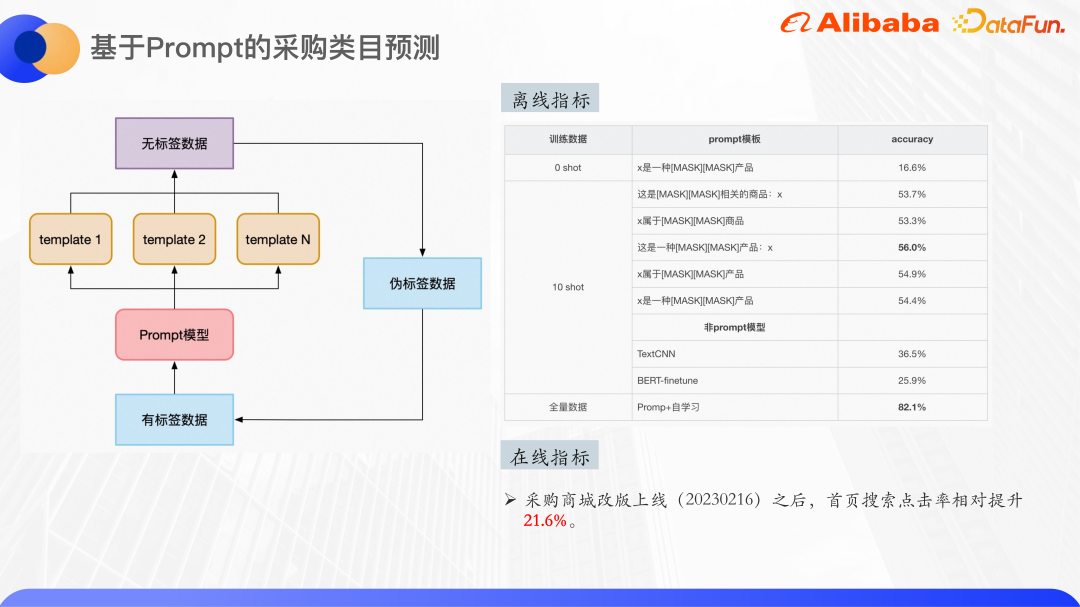
Gambar di atas adalah beberapa hasil percubaan, anda boleh melihat pengelasan dalam pukulan sifar senario Akibatnya, model pra-latihan menggunakan pangkalan Bert, dengan jumlah 30 kelas, dan pukulan sifar sudah boleh mencapai ketepatan 16%. Latihan pada set data sepuluh pukulan, beberapa templat boleh mencapai ketepatan maksimum 56%, dan penambahbaikan agak jelas Ia boleh dilihat bahawa pilihan templat juga akan memberi kesan tertentu ke atas keputusan.
Eksperimen juga dijalankan menggunakan TextCNN dan BERT-finetune pada set data sepuluh pukulan yang sama, dan kesannya jauh lebih rendah daripada kesan pembelajaran segera yang halus- penalaan, jadi Pembelajaran segera sangat berkesan dalam senario sampel kecil.
Akhir sekali, dengan menggunakan jumlah penuh data, kira-kira 4000 sampel latihan, dan pembelajaran kendiri, kesannya mencapai kira-kira 82%. Menambah beberapa pasca pemprosesan seperti ambang kad dalam talian boleh memastikan ketepatan klasifikasi melebihi 90%.
3 Ringkasan pemikiran

Enterprise Terdapat dua kesukaran utama dalam memahami Pertanyaan adegan:
(1) Kekurangan pengetahuan domain, Pendek umum pemahaman teks Graf pengetahuan akan digunakan untuk peningkatan pengetahuan, tetapi disebabkan oleh kekhususan senario perusahaan, graf pengetahuan sumber terbuka sukar untuk memenuhi keperluan, jadi data separa berstruktur dalam perusahaan digunakan untuk peningkatan pengetahuan.
(2) Terdapat sangat sedikit data berlabel dalam beberapa bidang profesional dalam perusahaan, 0 sampel dan sampel kecil Terdapat banyak senario Dalam kes ini, adalah wajar untuk memikirkan menggunakan model pra-latihan untuk menambah pembelajaran pembayang Walau bagaimanapun, keputusan eksperimen 0 sampel tidak begitu baik, kerana korpus yang digunakan dalam pra-latihan sedia ada. model latihan sebenarnya tidak meliputi pengetahuan Domain tentang senario perusahaan.
Jadi adakah mungkin untuk melatih model besar pra-latihan peringkat perusahaan, menggunakan data daripada medan menegak dalaman perusahaan berdasarkan korpus am, seperti ATA Alibaba? Data artikel, data kontrak, data kod, dll. dilatih untuk mendapatkan model pra-terlatih yang besar, dan kemudian pembelajaran segera atau Pembelajaran Konteks digunakan untuk menyatukan pelbagai tugas seperti klasifikasi teks, NER dan pemadanan teks ke dalam satu tugas model bahasa.
Selain itu, untuk tugasan fakta seperti soal jawab QA dan carian, bagaimana untuk memastikan ketepatan jawapan berdasarkan hasil model bahasa generatif juga perkara yang perlu difikirkan.
4 Sesi Soal Jawab
S1: Adakah terdapat sebarang kertas atau kod yang berkaitan untuk keseluruhan model pengecaman niat yang disediakan oleh Alibaba?
A1: Model ini dibangunkan sendiri dan belum ada kertas dan kod lagi.
S2: Pada masa ini, pertanyaan dan pertanyaan serupa menggunakan input peringkat token Mengapakah maklumat kad pengetahuan yang diambil tidak menggunakan kuantiti konkritnya dalam model pengelasan, tetapi hanya mempertimbangkan pembenaman ID?
A2: pertanyaan dan pertanyaan serupa menggunakan input tahap dimensi token, dan kad pengetahuan hanya menggunakan pembenaman ID, kerana mengambil kira nama kad pengetahuan itu sendiri, terdapat beberapa dalaman nama produk tidak begitu bermakna dari segi semantik teks. Jika kad pengetahuan ini diterangkan dalam teks, ia hanyalah teks yang agak panjang, yang mungkin menimbulkan terlalu banyak hingar, jadi penerangan teksnya tidak digunakan, hanya pembenaman ID kad pengetahuan ini digunakan.
S3: Berkenaan isu berkaitan promosi, pada masa ini dalam kes sampel kecil, ketepatan hanya 16%, dan sepuluh pendek hanya 50. Dalam kes ini, ia akan digunakan dalam aplikasi perusahaan Bagaimana untuk mempertimbangkannya? Atau adakah anda mempunyai sebarang idea tentang ini?
A3: sepuluh pendek sememangnya hanya kira-kira 50%, kerana model pra-latihan tidak meliputi beberapa korpora yang jarang berlaku dalam bidang perolehan, dan menggunakan parameter Model BERT- asas mempunyai jumlah yang agak kecil, jadi kesan sepuluh pukulan tidak begitu baik Namun, jika jumlah penuh data digunakan, ketepatan boleh dicapai melebihi 80%.
S4: Adakah mudah untuk mengembangkan ketepatan jawapan kepada model besar pra-latihan perusahaan yang disebut kali terakhir?
A4: Kawasan ini sedang diterokai. Idea utama ialah menggunakan beberapa idea yang serupa dengan pembelajaran pengukuhan dan menambah beberapa maklum balas buatan untuk melaraskan output sebelum model bahasa dijana.
Tambahkan beberapa prapemprosesan selepas input, iaitu selepas keluaran model besar Semasa prapemprosesan, anda boleh menambah graf pengetahuan atau pengetahuan lain ketepatan jawapan anda.
Atas ialah kandungan terperinci Pengecaman niat pertanyaan berdasarkan peningkatan pengetahuan dan model besar yang telah dilatih sebelumnya. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI