

 Peranti teknologiAIPandaLM, 'model besar pengadil' sumber terbuka dari Universiti Peking, Universiti West Lake dan lain-lain: tiga baris kod untuk menilai LLM secara automatik sepenuhnya, dengan ketepatan 94% daripada ChatGPT
Peranti teknologiAIPandaLM, 'model besar pengadil' sumber terbuka dari Universiti Peking, Universiti West Lake dan lain-lain: tiga baris kod untuk menilai LLM secara automatik sepenuhnya, dengan ketepatan 94% daripada ChatGPT
Selepas keluaran ChatGPT, ekosistem dalam bidang pemprosesan bahasa semula jadi telah berubah sepenuhnya. Banyak masalah yang tidak dapat diselesaikan sebelum ini boleh diselesaikan menggunakan ChatGPT.
Walau bagaimanapun, ia turut membawa masalah: prestasi model besar terlalu kuat, dan sukar untuk menilai perbezaan setiap model dengan mata kasar .
Sebagai contoh, jika beberapa versi model dilatih dengan model asas dan hiperparameter yang berbeza, prestasi mungkin serupa daripada contoh, dan jurang prestasi antara kedua-dua model tidak boleh sepenuhnya. kuantitatif.
Pada masa ini terdapat dua pilihan utama untuk menilai model bahasa besar:
1.
ChatGPT boleh digunakan untuk menilai kualiti keluaran dua model Walau bagaimanapun, ChatGPT telah dinaik taraf secara berulang-ulang Jawapan kepada soalan yang sama pada masa yang berbeza keputusan wujudMasalah tidak boleh dihasilkan semula.
2. Anotasi manual
Jika anda meminta anotasi manual pada platform penyumberan ramai, pasukan dengan dana yang tidak mencukupi mungkin Ia tidak mampu dimiliki, dan terdapat juga kes di mana syarikat pihak ketiga membocorkan data.
Untuk menyelesaikan "masalah penilaian model besar" sedemikian, penyelidik dari Universiti Peking, Universiti Westlake, Universiti Negeri Carolina Utara, Universiti Carnegie Mellon dan MSRA bekerjasama untuk membangunkan PandaLM, sebuah rangka kerja penilaian model bahasa baharu, komited untuk merealisasikan penyelesaian penilaian model besar yang memelihara privasi, boleh dipercayai, boleh dihasilkan semula dan murah.

Pautan projek: https://github.com/WeOpenML/PandaLM
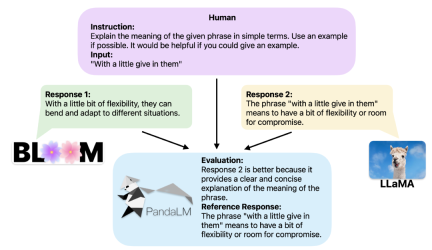
Menyediakan konteks yang sama, PandaLM boleh membandingkan output tindak balas LLM yang berbeza dan memberikan sebab tertentu.
Untuk menunjukkan kebolehpercayaan dan ketekalan alat, penyelidik mencipta set data ujian berlabel manusia yang pelbagai yang terdiri daripada kira-kira 1,000 sampel, di mana kadar tepat PandaLM-7B mencapai 94% keupayaan penilaian ChatGPT.
Tiga baris kod menggunakan PandaLM
Apabila dua model besar yang berbeza menghasilkan tindak balas yang berbeza kepada arahan dan konteks yang sama, PandaLM direka untuk membandingkan dua model besar kualiti tindak balas model, dan hasil perbandingan output, sebab perbandingan, dan respons untuk rujukan.
Terdapat tiga hasil perbandingan: respons 1 lebih baik, respons 2 lebih baik, respons 1 dan respons 2 mempunyai kualiti yang serupa.
Apabila membandingkan prestasi berbilang model besar, hanya gunakan PandaLM untuk membandingkannya secara berpasangan, kemudian ringkaskan hasil perbandingan berpasangan untuk menentukan kedudukan atau melukis prestasi berbilang model besar Model rajah hubungan pesanan separa boleh menganalisis dengan jelas dan intuitif perbezaan prestasi antara model yang berbeza.
PandaLM hanya perlu "digunakan secara tempatan" dan "tidak memerlukan penyertaan manusia", jadi penilaian PandaLM boleh melindungi privasi dan agak murah.
Untuk memberikan kebolehtafsiran yang lebih baik, PandaLM juga boleh menerangkan pilihannya dalam bahasa semula jadi dan menjana set respons rujukan tambahan.
Dalam projek itu, penyelidik bukan sahaja menyokong penggunaan PandaLM menggunakan UI Web untuk analisis kes, tetapi juga untuk memudahkan gunakan, Ia juga menyokong tiga baris kod untuk memanggil PandaLM untuk penilaian teks yang dijana oleh model dan data sewenang-wenangnya.

Memandangkan banyak model dan rangka kerja sedia ada bukan sumber terbuka atau sukar untuk menyelesaikan inferens secara setempat, PandaLM menyokong menggunakan pemberat model tertentu untuk menjana teks untuk dinilai atau menghantar terus dalam fail .json yang mengandungi teks yang akan dinilai.
Pengguna boleh menggunakan PandaLM untuk menilai model yang ditentukan pengguna dan data input hanya dengan menghantar dalam senarai yang mengandungi nama model/ID model HuggingFace atau laluan fail .json. Berikut ialah contoh penggunaan minimalis:

Untuk membolehkan semua orang menggunakan PandaLM secara fleksibel untuk penilaian percuma, penyelidik The berat model PandaLM juga telah diterbitkan di laman web huggingface Model PandaLM-7B boleh dimuatkan melalui arahan berikut:
Ciri-ciri PandaLM
Kebolehhasilan semula
Oleh kerana berat PandaLM adalah umum, malah hasil keluaran model bahasa Terdapat rawak Apabila benih rawak ditetapkan, keputusan penilaian PandaLM sentiasa boleh kekal konsisten.
Kemas kini model berdasarkan API dalam talian tidak telus, outputnya mungkin sangat tidak konsisten pada masa yang berbeza, dan versi lama model tidak lagi boleh diakses, jadi penilaian berdasarkan API dalam talian selalunya tidak boleh diakses.
Automasi, perlindungan privasi dan overhed rendah
Hanya gunakan model PandaLM secara setempat dan panggil arahan siap sedia. Anda boleh mula menilai pelbagai model besar tanpa perlu sentiasa berkomunikasi dengan pakar seperti mengupah pakar untuk anotasi. Pada masa yang sama, ia tidak melibatkan sebarang bayaran API atau kos buruh, menjadikannya sangat murah.
Tahap Penilaian
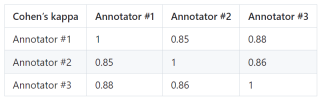
Untuk membuktikan kebolehpercayaan PandaLM, penyelidik mengupah tiga pakar untuk menjalankan anotasi berulang yang bebas , set ujian berlabel manual telah dibuat.
Set ujian mengandungi 50 senario berbeza dan setiap senario mengandungi beberapa tugasan. Set ujian ini pelbagai, boleh dipercayai dan konsisten dengan keutamaan manusia untuk teks. Setiap sampel set ujian terdiri daripada arahan dan konteks, dan dua respons yang dihasilkan oleh model besar yang berbeza, dan kualiti kedua-dua respons dibandingkan oleh manusia.
Saring keluar sampel dengan perbezaan yang besar antara anotasi untuk memastikan bahawa setiap annotator IAA (Perjanjian Inter Annotator) pada set ujian akhir adalah hampir 0.85. Perlu diingat bahawa set latihan PandaLM tidak mempunyai sebarang pertindihan dengan set ujian beranotasi manual yang dibuat.
Sampel yang ditapis ini memerlukan pengetahuan tambahan atau maklumat yang sukar diperoleh untuk membantu pertimbangan, yang menyukarkan manusia untuk Melabelkannya dengan tepat.
Set ujian yang ditapis mengandungi 1000 sampel, manakala set ujian yang tidak ditapis asal mengandungi 2500 sampel. Taburan set ujian ialah {0:105, 1:422, 2:472}, dengan 0 menunjukkan bahawa kedua-dua respons mempunyai kualiti yang sama, 1 menunjukkan bahawa respons 1 adalah lebih baik dan 2 menunjukkan bahawa respons 2 adalah lebih baik. Mengambil set ujian manusia sebagai penanda aras, perbandingan prestasi PandaLM dan gpt-3.5-turbo adalah seperti berikut:

Ia boleh dilihat bahawa PandaLM-7B berada dalam ketepatan Ia telah mencapai tahap 94% gpt-3.5-turbo, dan dari segi ketepatan, ingatan semula dan skor F1, PandaLM-7B hampir sama dengan gpt-3.5-turbo.
Oleh itu, berbanding dengan gpt-3.5-turbo, boleh dianggap bahawa PandaLM-7B sudah mempunyai keupayaan penilaian model yang besar.
Selain daripada ketepatan, ketepatan, ingatan semula dan skor F1 pada set ujian, ia juga memberikan hasil perbandingan antara 5 model sumber terbuka yang besar dengan saiz yang serupa.
Pertama, data latihan yang sama digunakan untuk memperhalusi lima model, dan kemudian manusia, gpt-3.5-turbo, dan PandaLM digunakan untuk membandingkan lima model masing-masing.
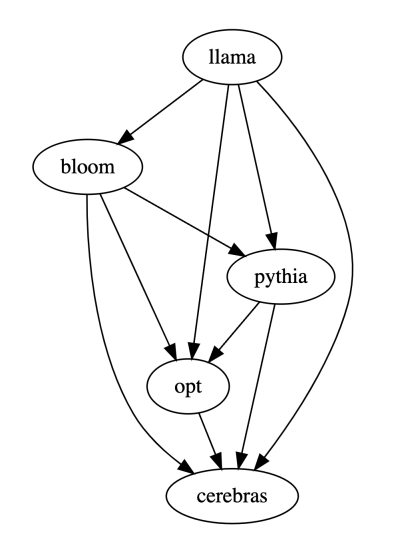
Tuple pertama (72, 28, 11) dalam baris pertama jadual di bawah menunjukkan bahawa terdapat 72 respons LLaMA-7B yang lebih baik daripada Bloom-7B, dan terdapat 28 LLaMA Sambutan -7B lebih teruk daripada Bloom-7B, dengan 11 respons kualiti yang sama antara kedua-dua model.
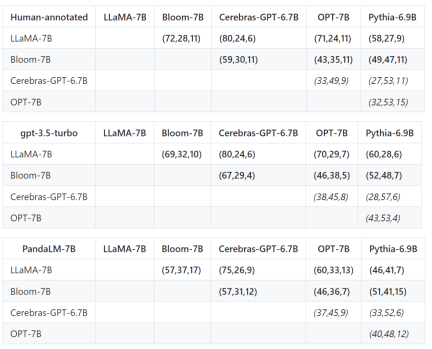
Jadi dalam contoh ini, manusia berpendapat LLaMA-7B lebih baik daripada Bloom-7B. Keputusan dalam tiga jadual berikut menunjukkan bahawa manusia, gpt-3.5-turbo dan PandaLM-7B mempunyai penilaian yang konsisten sepenuhnya mengenai hubungan antara kebaikan dan keburukan setiap model.
Ringkasan
PandaLM menyediakan kaedah ketiga sebagai tambahan kepada penilaian manusia dan penilaian OpenAI API Untuk penyelesaian untuk menilai model besar, PandaLM bukan sahaja mempunyai tahap penilaian yang tinggi, tetapi juga mempunyai hasil penilaian yang boleh dihasilkan semula, proses penilaian automatik, perlindungan privasi dan overhed yang rendah.
Pada masa hadapan, PandaLM akan mempromosikan penyelidikan tentang model besar dalam akademik dan industri, membolehkan lebih ramai orang mendapat manfaat daripada pembangunan model besar.
Atas ialah kandungan terperinci PandaLM, 'model besar pengadil' sumber terbuka dari Universiti Peking, Universiti West Lake dan lain-lain: tiga baris kod untuk menilai LLM secara automatik sepenuhnya, dengan ketepatan 94% daripada ChatGPT. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Skop Gemma: Mikroskop Google ' s untuk mengintip ke proses pemikiran AI 'Apr 17, 2025 am 11:55 AM
Skop Gemma: Mikroskop Google ' s untuk mengintip ke proses pemikiran AI 'Apr 17, 2025 am 11:55 AMMeneroka kerja -kerja dalam model bahasa dengan skop Gemma Memahami kerumitan model bahasa AI adalah satu cabaran penting. Pelepasan Google Gemma Skop, Toolkit Komprehensif, menawarkan penyelidik cara yang kuat untuk menyelidiki
 Siapa penganalisis perisikan perniagaan dan bagaimana menjadi satu?Apr 17, 2025 am 11:44 AM
Siapa penganalisis perisikan perniagaan dan bagaimana menjadi satu?Apr 17, 2025 am 11:44 AMMembuka Kejayaan Perniagaan: Panduan untuk Menjadi Penganalisis Perisikan Perniagaan Bayangkan mengubah data mentah ke dalam pandangan yang boleh dilakukan yang mendorong pertumbuhan organisasi. Ini adalah kuasa penganalisis Perniagaan Perniagaan (BI) - peranan penting dalam GU
 Bagaimana untuk menambah lajur dalam SQL? - Analytics VidhyaApr 17, 2025 am 11:43 AM
Bagaimana untuk menambah lajur dalam SQL? - Analytics VidhyaApr 17, 2025 am 11:43 AMPernyataan Jadual Alter SQL: Menambah lajur secara dinamik ke pangkalan data anda Dalam pengurusan data, kebolehsuaian SQL adalah penting. Perlu menyesuaikan struktur pangkalan data anda dengan cepat? Pernyataan Jadual ALTER adalah penyelesaian anda. Butiran panduan ini menambah colu
 Penganalisis Perniagaan vs Penganalisis DataApr 17, 2025 am 11:38 AM
Penganalisis Perniagaan vs Penganalisis DataApr 17, 2025 am 11:38 AMPengenalan Bayangkan pejabat yang sibuk di mana dua profesional bekerjasama dalam projek kritikal. Penganalisis perniagaan memberi tumpuan kepada objektif syarikat, mengenal pasti bidang penambahbaikan, dan memastikan penjajaran strategik dengan trend pasaran. Simu
 Apakah Count dan Counta dalam Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AM
Apakah Count dan Counta dalam Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AMPengiraan dan Analisis Data Excel: Penjelasan terperinci mengenai fungsi Count dan Counta Pengiraan dan analisis data yang tepat adalah kritikal dalam Excel, terutamanya apabila bekerja dengan set data yang besar. Excel menyediakan pelbagai fungsi untuk mencapai matlamat ini, dengan fungsi Count dan CountA menjadi alat utama untuk mengira bilangan sel di bawah keadaan yang berbeza. Walaupun kedua -dua fungsi digunakan untuk mengira sel, sasaran reka bentuk mereka disasarkan pada jenis data yang berbeza. Mari menggali butiran khusus fungsi Count dan Counta, menyerlahkan ciri dan perbezaan unik mereka, dan belajar cara menerapkannya dalam analisis data. Gambaran keseluruhan perkara utama Memahami kiraan dan cou
 Chrome ada di sini dengan AI: mengalami sesuatu yang baru setiap hari !!Apr 17, 2025 am 11:29 AM
Chrome ada di sini dengan AI: mengalami sesuatu yang baru setiap hari !!Apr 17, 2025 am 11:29 AMRevolusi AI Google Chrome: Pengalaman melayari yang diperibadikan dan cekap Kecerdasan Buatan (AI) dengan cepat mengubah kehidupan seharian kita, dan Google Chrome mengetuai pertuduhan di arena pelayaran web. Artikel ini meneroka exciti
 Sisi Manusia Ai ' s: Kesejahteraan dan garis bawah empat kali gandaApr 17, 2025 am 11:28 AM
Sisi Manusia Ai ' s: Kesejahteraan dan garis bawah empat kali gandaApr 17, 2025 am 11:28 AMImpak Reimagining: garis bawah empat kali ganda Selama terlalu lama, perbualan telah dikuasai oleh pandangan sempit kesan AI, terutama memberi tumpuan kepada keuntungan bawah. Walau bagaimanapun, pendekatan yang lebih holistik mengiktiraf kesalinghubungan BU
 5 Kes Pengkomputeran Kuantum Mengubah Permainan Yang Harus Anda KetahuiApr 17, 2025 am 11:24 AM
5 Kes Pengkomputeran Kuantum Mengubah Permainan Yang Harus Anda KetahuiApr 17, 2025 am 11:24 AMPerkara bergerak terus ke arah itu. Pelaburan yang dicurahkan ke dalam penyedia perkhidmatan kuantum dan permulaan menunjukkan bahawa industri memahami kepentingannya. Dan semakin banyak kes penggunaan dunia nyata muncul untuk menunjukkan nilainya


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

SecLists
SecLists ialah rakan penguji keselamatan muktamad. Ia ialah koleksi pelbagai jenis senarai yang kerap digunakan semasa penilaian keselamatan, semuanya di satu tempat. SecLists membantu menjadikan ujian keselamatan lebih cekap dan produktif dengan menyediakan semua senarai yang mungkin diperlukan oleh penguji keselamatan dengan mudah. Jenis senarai termasuk nama pengguna, kata laluan, URL, muatan kabur, corak data sensitif, cangkerang web dan banyak lagi. Penguji hanya boleh menarik repositori ini ke mesin ujian baharu dan dia akan mempunyai akses kepada setiap jenis senarai yang dia perlukan.

PhpStorm versi Mac
Alat pembangunan bersepadu PHP profesional terkini (2018.2.1).

DVWA
Damn Vulnerable Web App (DVWA) ialah aplikasi web PHP/MySQL yang sangat terdedah. Matlamat utamanya adalah untuk menjadi bantuan bagi profesional keselamatan untuk menguji kemahiran dan alatan mereka dalam persekitaran undang-undang, untuk membantu pembangun web lebih memahami proses mengamankan aplikasi web, dan untuk membantu guru/pelajar mengajar/belajar dalam persekitaran bilik darjah Aplikasi web keselamatan. Matlamat DVWA adalah untuk mempraktikkan beberapa kelemahan web yang paling biasa melalui antara muka yang mudah dan mudah, dengan pelbagai tahap kesukaran. Sila ambil perhatian bahawa perisian ini

Dreamweaver Mac版
Alat pembangunan web visual

Dreamweaver CS6
Alat pembangunan web visual

