
Rumah >Peranti teknologi >AI >Model besar akan menyambut 'musim sumber terbuka', mengambil stok LLM sumber terbuka dan set data pada bulan lalu
Model besar akan menyambut 'musim sumber terbuka', mengambil stok LLM sumber terbuka dan set data pada bulan lalu

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-18 16:31:131677semak imbas
Beberapa masa lalu, dokumen dalaman Google yang bocor menyatakan pandangan bahawa walaupun OpenAI dan Google kelihatan mengejar satu sama lain pada model AI yang besar, pemenang sebenar mungkin tidak muncul daripada kedua-dua ini, kerana Terdapat kuasa pihak ketiga yang secara senyap-senyap meningkat. Kuasa ini adalah "sumber terbuka".
Berkisar model sumber terbuka LLaMA Meta, seluruh komuniti dengan pantas membina model dengan keupayaan yang serupa dengan OpenAI dan model besar Google Selain itu, model sumber terbuka lebih pantas dan lebih boleh disesuaikan. Lebih privasi.
Baru-baru ini, Sebastian Raschka, bekas penolong profesor di University of Wisconsin-Madison dan ketua pegawai pendidikan AI bagi pemula Lightning AI, berkata, Untuk sumber terbuka, bulan lepas sangat Hebat .
Walau bagaimanapun, begitu banyak model bahasa besar (LLM) telah muncul satu demi satu, dan bukan mudah untuk mengekalkan pemahaman yang kukuh tentang semua model. Jadi, dalam artikel ini, Sebastian berkongsi sumber dan cerapan penyelidikan tentang LLM dan set data sumber terbuka terkini.
Kertas dan Trend
Terdapat begitu banyak kertas penyelidikan pada bulan lalu sehingga sukar untuk memilih dan memilih daripada mereka Pilih yang paling kegemaran untuk perbincangan mendalam. Sebastian lebih suka kertas kerja yang memberikan cerapan tambahan daripada sekadar menunjukkan model yang lebih berkuasa. Memandangkan perkara ini, perkara pertama yang menarik perhatiannya ialah kertas Pythia yang dikarang bersama oleh penyelidik dari Eleuther AI dan Universiti Yale serta institusi lain.

Alamat kertas: https://arxiv.org/pdf/2304.01373.pdf
Pythia: Mendapat pandangan daripada latihan berskala besar
Keluarga model besar Pythia sumber terbuka adalah yang terbaik contoh penyahkodan autoregresif lain Alternatif yang menarik kepada model gaya bekas (iaitu model seperti GPT). Makalah ini mendedahkan beberapa pandangan yang menarik tentang mekanisme latihan dan memperkenalkan model yang sepadan antara parameter 70M hingga 12B.
Seni bina model Pythia adalah serupa dengan GPT-3, tetapi termasuk beberapa penambahbaikan seperti perhatian Flash (seperti LLaMA) dan pembenaman kedudukan putaran (seperti PaLM). Pada masa yang sama, Pythia telah dilatih dengan token 300B pada set data teks pelbagai 800GB Pile (1 zaman pada Pile biasa dan 1.5 zaman pada Pile deduplikasi).
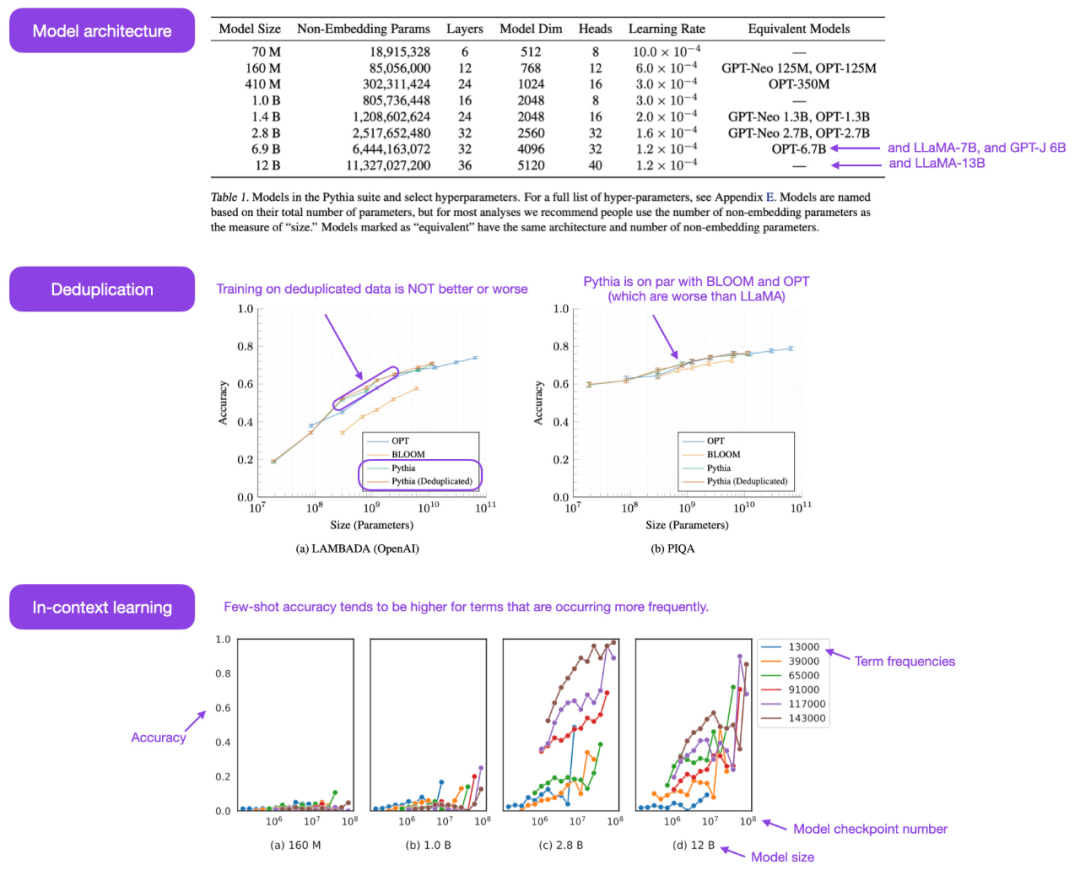
Berikut ialah beberapa pandangan dan refleksi daripada kertas Pythia:
- Dalam Wasiat terdapat sebarang kesan jika latihan pada data berulang (iaitu zaman latihan>1) akan memberi sebarang kesan? Keputusan menunjukkan bahawa penyahduplikasian data tidak meningkatkan atau menjejaskan prestasi; Malangnya, ternyata tidak. Saya minta maaf kerana jika ia berlaku, masalah ingatan verbatim yang buruk boleh dikurangkan dengan menyusun semula data latihan;
- Data Sumber Terbuka
Databricks-Dolly-15 dataset
Databricks-Dolly-15 ialah set data yang digunakan untuk LLM fine- set penalaan lebih daripada 15,000 pasangan arahan yang ditulis oleh ribuan pekerja DataBricks (serupa dengan sistem latihan seperti InstructGPT dan ChatGPT).
Set Data OASST1 Set Data OASST1 digunakan untuk memperhalusi LLM pra-latihan pada koleksi perbualan seperti pembantu ChatGPT yang dibuat dan diberi penjelasan oleh manusia , mengandungi 161,443 mesej yang ditulis dalam 35 bahasa dan 461,292 penilaian kualiti. Ini dianjurkan dalam lebih 10,000 pokok dialog beranotasi sepenuhnya. Dataset RedPajama untuk pra-latihan
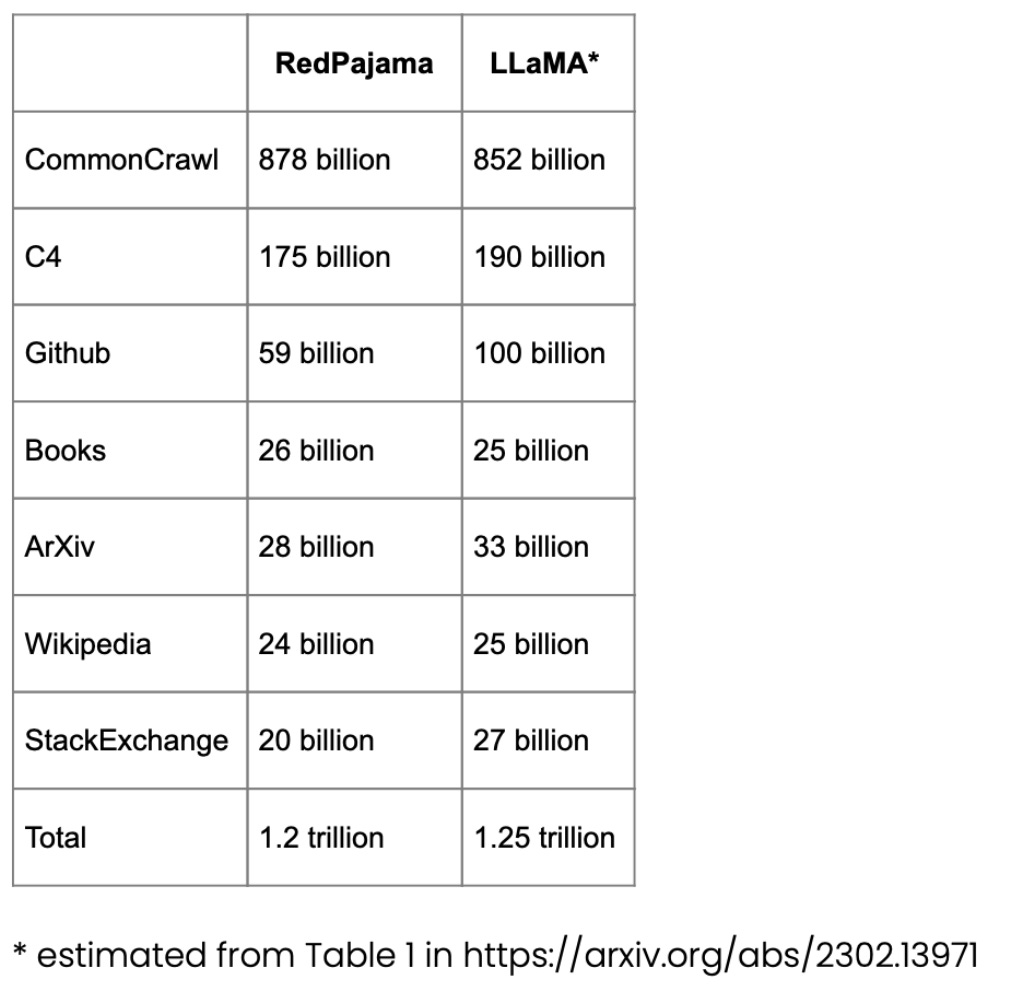
RedPajama ialah set data sumber terbuka untuk pra-latihan LLM, serupa dengan model SOTA LLaMA Meta. Set data ini bertujuan untuk mencipta pesaing sumber terbuka kepada kebanyakan LLM yang popular, yang pada masa ini sama ada model perniagaan sumber tertutup atau hanya sebahagian sumber terbuka.
Kebanyakan RedPajama terdiri daripada CommonCrawl, yang menapis tapak berbahasa Inggeris, tetapi artikel Wikipedia merangkumi 20 bahasa berbeza.
Set Data Bentuk Panjang
Kertas " The LongForm: Mengoptimumkan Penalaan Arahan untuk Penjanaan Teks Panjang dengan Pengekstrakan Korpus" memperkenalkan koleksi dokumen yang dibuat secara manual berdasarkan korpora sedia ada seperti C4 dan Wikipedia dan arahan dokumen ini, sekali gus mewujudkan set data penalaan arahan yang sesuai untuk penjanaan teks panjang.
Alamat kertas: https://arxiv.org/abs/2304.08460
Projek Alpaca Libre
Projek Alpaca Libre menyasarkan untuk mencipta semula projek Alpaca dengan menukar 100k+ demo berlesen MIT daripada repositori Anthropics HH-RLHF kepada format yang serasi dengan Alpaca.
Set data sumber terbuka lanjutan
Penalaan halus arahan ialah evolusi kami daripada pra seperti GPT-3 -model asas terlatih kepada lebih Kunci kepada model bahasa besar seperti ChatGPT yang berkuasa. Set data arahan yang dijana manusia sumber terbuka seperti Databricks-Dolly-15 membantu mencapai perkara ini. Tetapi bagaimana kita boleh meningkatkan lagi? Adakah mungkin untuk tidak mengumpul data tambahan? Satu pendekatan adalah untuk bootstrap LLM daripada lelarannya sendiri. Walaupun kaedah Arahan Kendiri telah dicadangkan 5 bulan yang lalu (dan sudah lapuk mengikut piawaian hari ini), ia masih merupakan kaedah yang sangat menarik. Perlu ditekankan bahawa adalah mungkin untuk menyelaraskan LLM yang telah dilatih dengan arahan terima kasih kepada Arahan Kendiri, kaedah yang hampir tidak memerlukan anotasi.
Bagaimana ia berfungsi? Ringkasnya, ia boleh dibahagikan kepada empat langkah berikut:
- Yang pertama ialah kumpulan tugas benih dengan set arahan bertulis manual (175 dalam kes ini) dan sampel arahan;
- Kedua, gunakan LLM pra-latihan (seperti GPT-3) untuk menentukan kategori tugasan; arahan untuk membuat LLM pra-latihan menjana respons;
- Dalam amalan, kerja berdasarkan skor ROUGE akan menjadi lebih berkesan, contohnya, Self-Instruct LLM yang ditala halus adalah lebih baik daripada LLM asas GPT-3, dan boleh bersaing dengan LLM yang dipralatih pada set arahan tulisan manusia yang besar. Pada masa yang sama, arahan kendiri juga boleh mendapat manfaat daripada LLM yang telah diperhalusi pada arahan manual.
Tetapi sudah tentu, piawaian emas untuk menilai LLM ialah meminta penilai manusia. Berdasarkan penilaian manusia, Arahan Kendiri mengatasi LLM asas, serta LLM yang dilatih mengenai set data arahan manusia dengan cara yang diawasi (seperti SuperNI, T0 Trainer). Walau bagaimanapun, menariknya, Arahan Kendiri tidak menunjukkan prestasi yang lebih baik daripada kaedah yang dilatih dengan pembelajaran pengukuhan dengan maklum balas manusia (RLHF). 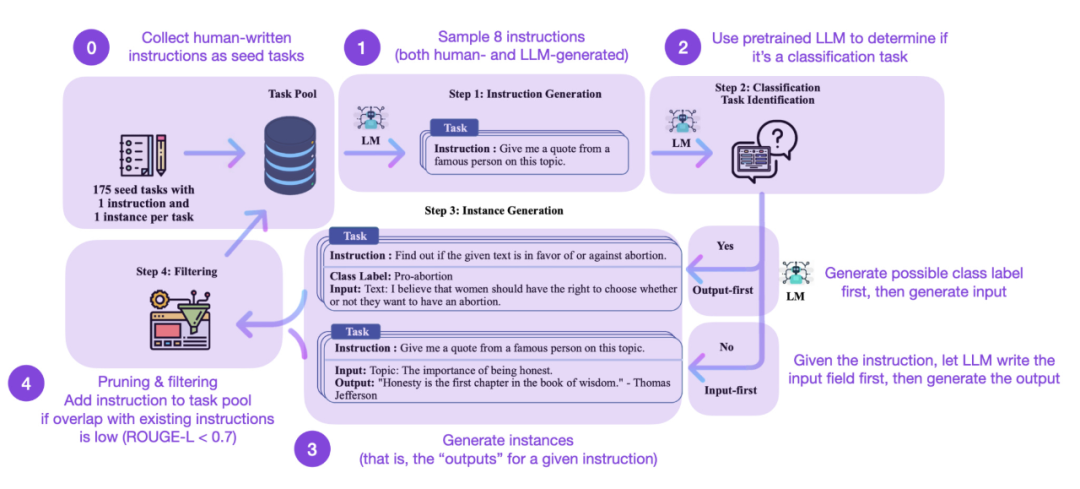
Set data latihan vs sintetik yang dijana secara buatan
Set data arahan yang dijana secara buatan atau set data arahan kendiri, yang manakah lebih menjanjikan? kain? Sebastian melihat masa depan dalam kedua-duanya. Mengapa tidak bermula dengan set data arahan yang dijana secara manual (cth. databricks-dolly-15k daripada arahan 15k) dan kemudian melanjutkannya menggunakan arahan kendiri? Makalah "Data Sintetik daripada Model Penyebaran Meningkatkan Klasifikasi ImageNet" menunjukkan bahawa menggabungkan set latihan imej sebenar dengan imej yang dijana AI boleh meningkatkan prestasi model. Adalah menarik untuk meneroka sama ada perkara yang sama berlaku untuk data teks.
Alamat kertas: https://arxiv.org/abs/2304.08466
Kertas terbaru "Bahasa yang Lebih Baik" Model Kod melalui Pembaikan Diri" adalah penyelidikan ke arah ini. Para penyelidik mendapati bahawa tugas penjanaan kod boleh dipertingkatkan jika LLM yang telah dilatih menggunakan data yang dijana sendiri.
Alamat kertas: https://arxiv.org/abs/2304.01228
Kurang lebih Kurang lebih?
Selain itu, sebagai tambahan kepada pra-latihan dan penalaan halus model pada set data yang lebih besar dan lebih besar, bagaimana untuk meningkatkan prestasi set data yang lebih kecil Bagaimana dengan kecekapan? Kertas kerja "Menyuling Langkah demi Langkah! Mengungguli Model Bahasa yang Lebih Besar dengan Kurang Data Latihan dan Saiz Model yang Lebih Kecil" mencadangkan penggunaan mekanisme penyulingan untuk mengurus model yang lebih kecil khusus tugas yang menggunakan kurang data latihan tetapi melebihi prestasi halus standard.
Alamat kertas: https://arxiv.org/abs/2305.02301
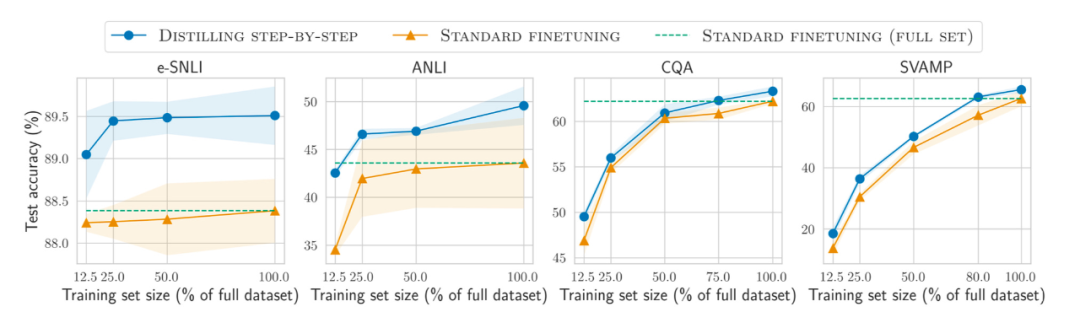
Menjejaki LLM sumber terbuka
Bilangan LLM sumber terbuka meletup Di satu pihak, ia merupakan trend pembangunan yang sangat baik (berbanding dengan mengawal model melalui API berbayar ), tetapi sebaliknya menjejaki semuanya boleh menyusahkan. Empat sumber berikut menyediakan ringkasan berbeza bagi kebanyakan model yang berkaitan, termasuk perhubungannya, set data asas dan pelbagai maklumat pelesenan.
Sumber pertama ialah tapak web graf ekosistem berdasarkan kertas "Graf Ekosistem: Jejak Sosial Model Asas", yang menyediakan jadual berikut dan graf pergantungan interaktif (tidak ditunjukkan di sini) .
Rajah ekosistem ini ialah senarai paling komprehensif yang pernah dilihat Sebastian setakat ini, tetapi boleh menjadi agak mengelirukan kerana ia termasuk banyak LLM yang kurang popular. Menyemak repositori GitHub yang sepadan menunjukkan bahawa ia telah dikemas kini selama sekurang-kurangnya sebulan. Ia juga tidak jelas sama ada ia akan menambah model yang lebih baharu.
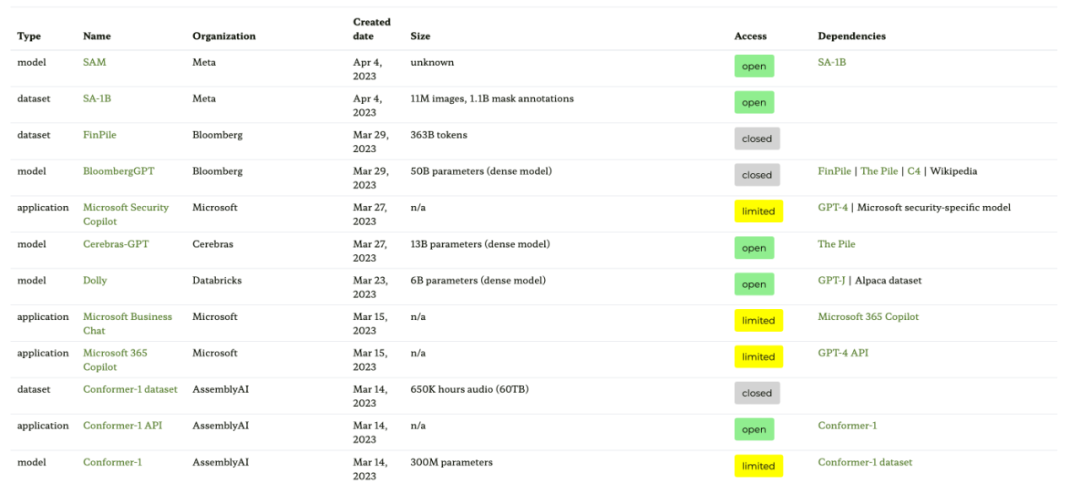
- Alamat kertas: https://arxiv.org/abs/2303.15772
- Alamat tapak web graf ekosistem: https://crfm.stanford.edu/ecosystem-graphs/index.html?mode=table
Sumber kedua ialah pokok evolusi yang dilukis dengan cantik daripada kertas baru-baru ini Memanfaatkan Kuasa LLM dalam Amalan: Tinjauan tentang ChatGPT dan Beyond, yang memfokuskan pada LLM yang paling popular dan hubungan mereka.
Walaupun pembaca melihat pokok evolusi LLM visual yang sangat cantik dan jelas, terdapat juga beberapa keraguan kecil. Tidak jelas mengapa bahagian bawah tidak bermula dari seni bina transformer asal. Label sumber terbuka juga tidak begitu tepat, contohnya LLaMA disenaraikan sebagai sumber terbuka, tetapi pemberat tidak tersedia di bawah lesen sumber terbuka (hanya kod inferens sahaja).
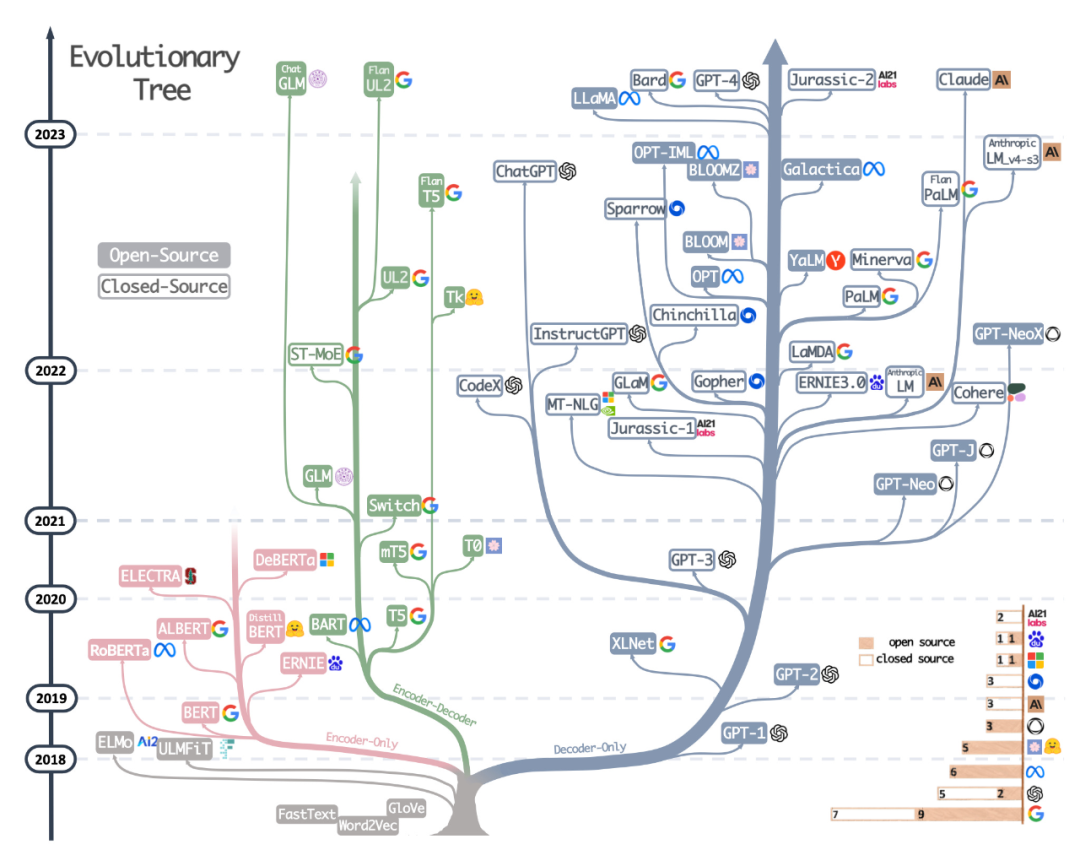
Alamat kertas: https://arxiv.org/abs/2304.13712
Sumber ketiga ialah jadual yang dilukis oleh rakan sekerja Sebastian Daniela Dapena, daripada blog "The Ultimate Battle of Language Models: Lit-LLaMA vs GPT3.5 vs Bloom vs...".
Walaupun jadual di bawah lebih kecil daripada sumber lain, ia mempunyai kelebihan untuk memasukkan dimensi model dan maklumat pelesenan. Jadual ini akan sangat berguna jika anda merancang untuk menggunakan model ini dalam mana-mana projek.
Alamat blog: https://lightning.ai/pages/community/community-discussions/the-ultimate- battle-of -language-models-lit-llama-vs-gpt3.5-vs-bloom-vs/
Sumber keempat ialah jadual gambaran keseluruhan LLaMA-Cult-and-More , yang menyediakan maklumat tambahan tentang kaedah penalaan halus dan kos perkakasan.
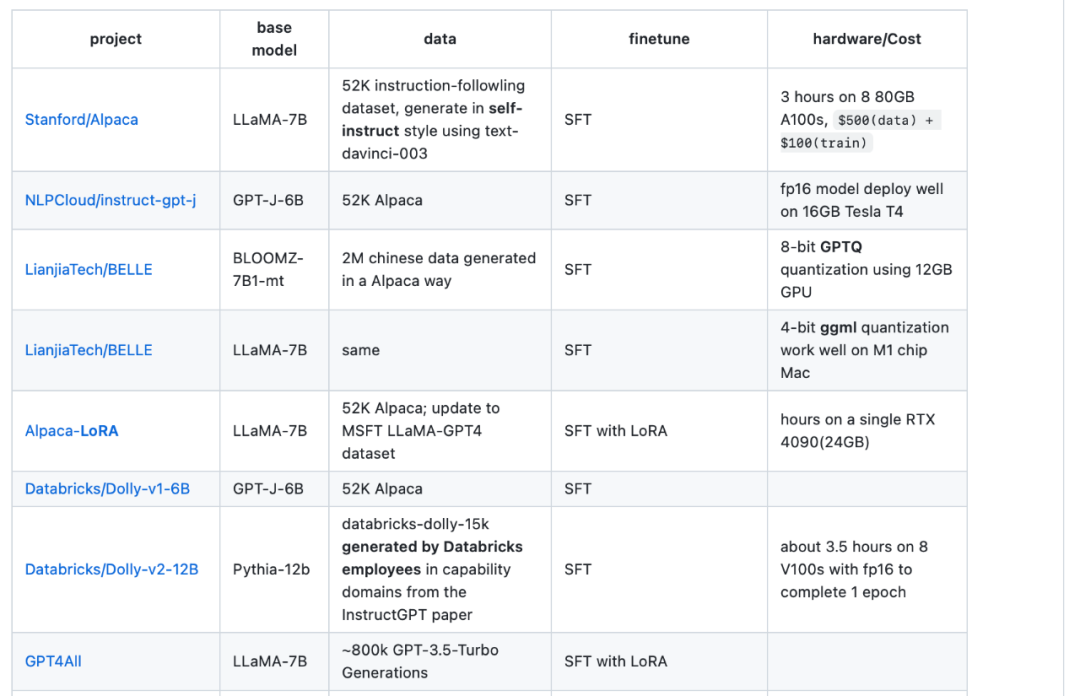
Alamat jadual gambaran keseluruhan: https://github.com/shm007g/LLaMA-Cult-and- Lagi/blob/main/chart.md
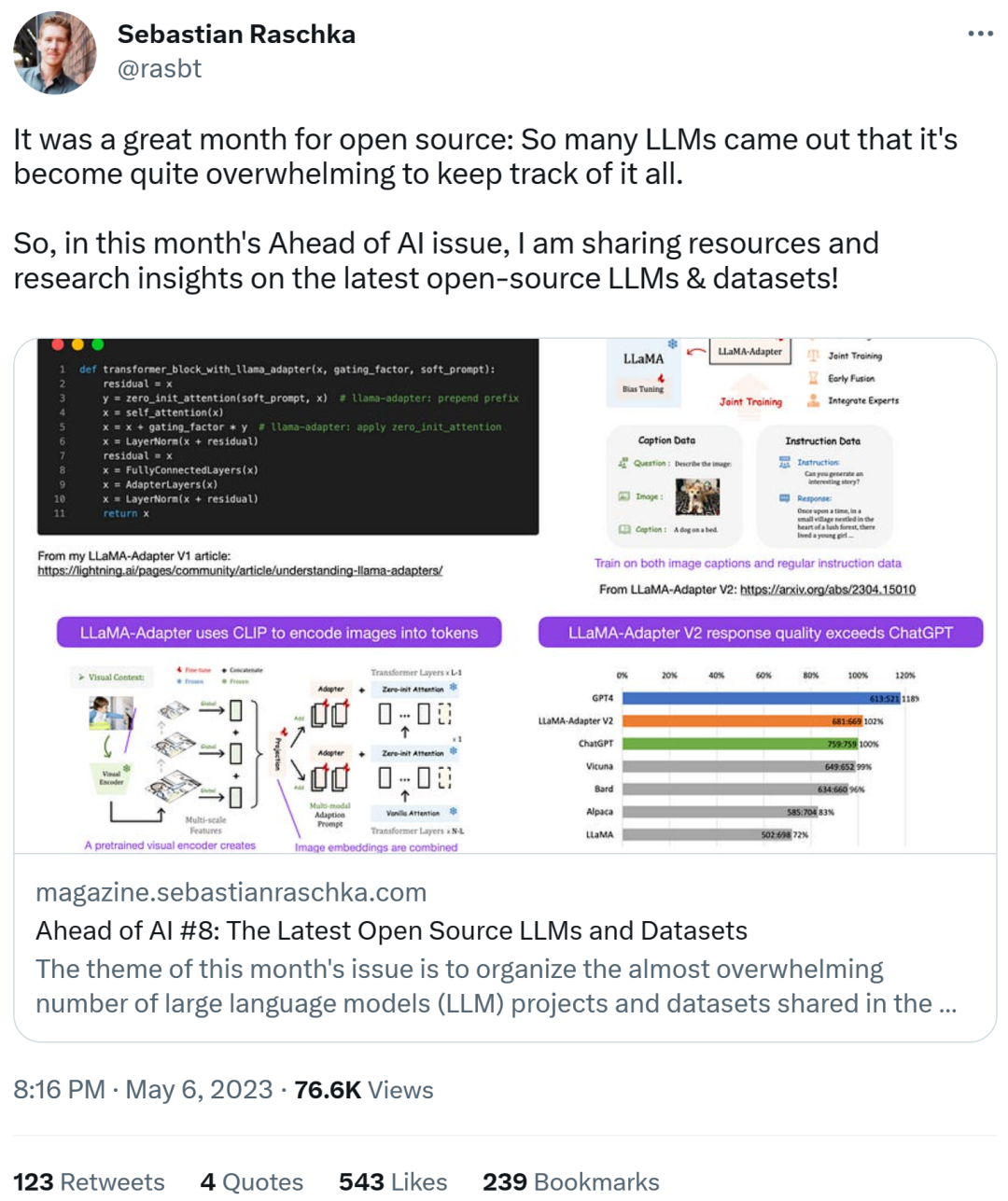
Gunakan LLaMA-Adapter V2 untuk memperhalusi LLM berbilang mod
Sebastian meramalkan bahawa kita akan melihat lebih banyak model LLM multi-modal bulan ini, jadi dia perlu bercakap mengenai kertas yang dikeluarkan baru-baru ini "LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model". Mula-mula, mari semak apakah itu LLaMA-Adapter? Ia adalah teknik penalaan halus LLM yang cekap parameter yang mengubah suai blok transformer sebelumnya dan memperkenalkan mekanisme gating untuk menstabilkan latihan.
Alamat kertas: https://arxiv.org/abs/2304.15010
Menggunakan kaedah Penyesuai LLaMA , Para penyelidik dapat memperhalusi model LLaMA parameter 7B dalam masa 1 jam sahaja (8 A100 GPU) pada pasangan arahan 52k. Walaupun hanya parameter 1.2M yang baru ditambah (lapisan penyesuai) telah diperhalusi, model 7B LLaMA masih dibekukan.
Fokus LLaMA-Adapter V2 ialah multi-modaliti, iaitu membina model arahan visual yang boleh menerima input imej. Walaupun V1 asal boleh menerima token teks dan token imej, imej tidak diterokai sepenuhnya.
Penyesuai LLaMA Dari V1 hingga V2, penyelidik menambah baik kaedah penyesuai melalui tiga teknik utama berikut.
- Penyatuan pengetahuan visual awal: daripada menggabungkan isyarat visual dan disesuaikan pada setiap lapisan yang disesuaikan, token visual disambungkan kepada token perkataan dalam blok pengubah pertama ;
- Gunakan lebih banyak parameter: nyahbeku semua lapisan normalisasi dan tambah unit pincang dan faktor penskalaan pada setiap lapisan linear dalam blok pengubah;
- Latihan bersama dengan parameter bercabang : untuk data sari kata, hanya lapisan unjuran visual dilatih untuk data diikuti dengan arahan, hanya lapisan penyesuaian (dan parameter yang baru ditambah yang dinyatakan di atas) dilatih.
LLaMA V2 (14M) mempunyai lebih banyak parameter daripada LLaMA V1 (1.2 M), tetapi ia masih ringan, menyumbang hanya 0.02% daripada jumlah parameter 65B LLaMA . Amat mengagumkan ialah dengan memperhalusi hanya 14M parameter model LLaMA 65B, LLaMA-Adapter V2 yang dihasilkan berprestasi setanding dengan ChatGPT (apabila dinilai menggunakan model GPT-4). LLaMA-Adapter V2 juga mengatasi model 13B Vicuna menggunakan kaedah penalaan halus penuh.
Malangnya, kertas LLaMA-Adapter V2 mengetepikan penanda aras prestasi pengiraan yang disertakan dalam kertas V1, tetapi kita boleh mengandaikan bahawa V2 masih jauh lebih pantas daripada pendekatan yang diperhalusi sepenuhnya.

LLM sumber terbuka lain
Model besar berkembang begitu pantas sehingga kami tidak dapat menyenaraikan kesemuanya, dan beberapa LLM dan chatbot sumber terbuka terkenal yang dilancarkan bulan ini termasuk Pembantu Terbuka, Baize, StableVicuna, ColossalChat, MPT Mosaic dan banyak lagi . Selain itu, di bawah ialah dua LLM multimodal yang sangat menarik.
OpenFlamingo
OpenFlamingo ialah salinan sumber terbuka model Flamingo yang dikeluarkan oleh Google DeepMind tahun lepas. OpenFlamingo menyasarkan untuk menyediakan keupayaan inferens imej berbilang mod untuk LLM, membolehkan orang ramai untuk menyelang input teks dan imej.
MiniGPT-4
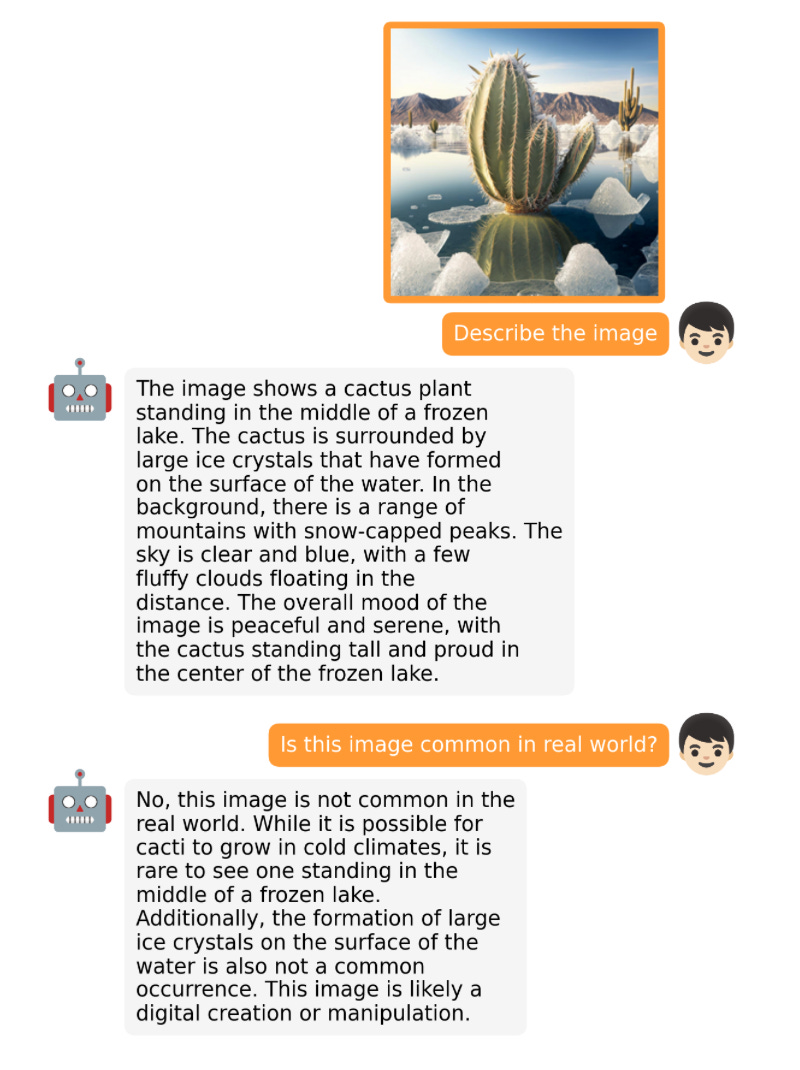
MiniGPT-4 ialah satu lagi model sumber terbuka dengan keupayaan bahasa visual. Ia berdasarkan pengekod visual beku BLIP-27 dan Vicuna LLM beku.
NeMo Guardrails
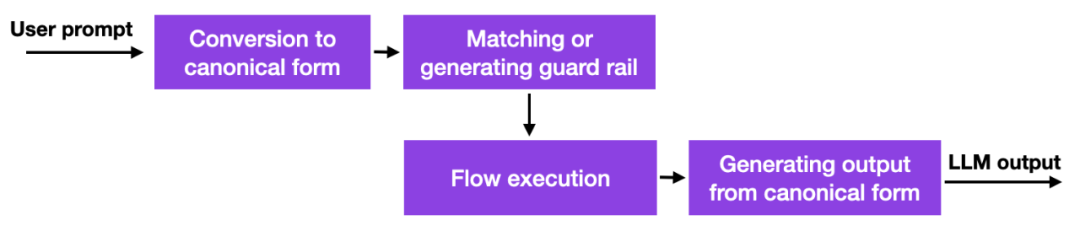
Dengan ini Dengan kemunculan model bahasa yang besar, banyak syarikat memikirkan tentang cara dan sama ada mereka harus menggunakan model tersebut, dan kebimbangan keselamatan amat menonjol. Belum ada penyelesaian yang baik, tetapi terdapat sekurang-kurangnya satu pendekatan yang lebih menjanjikan: NVIDIA telah menyediakan kit alat sumber terbuka untuk menyelesaikan masalah halusinasi LLM.
Ringkasnya, cara ia berfungsi ialah kaedah ini menggunakan pautan pangkalan data kepada gesaan berkod keras yang mesti diuruskan secara manual. Kemudian, jika pengguna memasukkan gesaan, kandungan itu akan dipadankan dahulu dengan entri yang paling serupa dalam pangkalan data itu. Pangkalan data kemudian mengembalikan gesaan berkod keras yang kemudiannya dihantar ke LLM. Jadi jika seseorang menguji dengan teliti gesaan berkod keras, seseorang boleh memastikan bahawa interaksi tidak menyimpang daripada topik yang dibenarkan dsb.
Ini adalah pendekatan yang menarik tetapi bukan terobosan kerana ia tidak menawarkan sesuatu yang lebih baik atau baharu untuk keupayaan LLM, ia hanya mengehadkan sejauh mana pengguna boleh berinteraksi dengan LLM. Namun, sehingga penyelidik mencari cara alternatif untuk mengurangkan masalah halusinasi dan tingkah laku negatif dalam LLM, ini mungkin pendekatan yang berdaya maju.
Pendekatan pagar juga boleh digabungkan dengan teknik penjajaran lain, seperti paradigma latihan pembelajaran pengukuhan maklum balas manusia yang popular yang diperkenalkan oleh pengarang dalam isu Ahead of AI sebelum ini.
Model Konsistensi
Cuba yang bagus untuk bercakap tentang model menarik selain LLM, OpenAI akhirnya bersumberkan sumber terbuka. Kod untuk model ketekalan: https://github.com/openai/consistency_models.
Model ketekalan dianggap sebagai alternatif yang berdaya maju dan cekap kepada model resapan. Anda boleh mendapatkan maklumat lanjut dalam kertas model konsistensi.
Atas ialah kandungan terperinci Model besar akan menyambut 'musim sumber terbuka', mengambil stok LLM sumber terbuka dan set data pada bulan lalu. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI