
Rumah >Peranti teknologi >AI >Adakah pembenaman perkataan mewakili bahagian parameter yang terlalu besar? Kaedah MorphTE 20 kali ganda kesan mampatan tanpa kehilangan
Adakah pembenaman perkataan mewakili bahagian parameter yang terlalu besar? Kaedah MorphTE 20 kali ganda kesan mampatan tanpa kehilangan

- 王林ke hadapan
- 2023-05-17 16:01:061308semak imbas
Pengenalan
Perwakilan pembenaman perkataan ialah asas untuk pelbagai tugas pemprosesan bahasa semula jadi seperti terjemahan mesin, menjawab soalan, klasifikasi teks, dll. Ia biasanya menyumbang 20%~90% daripada jumlah parameter model. Menyimpan dan mengakses benam ini memerlukan sejumlah besar ruang, yang tidak kondusif untuk penggunaan model dan aplikasi pada peranti dengan sumber terhad. Untuk menangani masalah ini, artikel ini mencadangkan kaedah pemampatan membenamkan perkataan MorphTE . MorphTE menggabungkan keupayaan mampatan berkuasa operasi produk tensor dengan pengetahuan morfologi bahasa terdahulu untuk mencapai pemampatan tinggi parameter pembenaman perkataan (melebihi 20 kali ) sambil mengekalkan prestasi model.

- Pautan kertas: https://arxiv.org/abs/2210.15379
- Kod sumber terbuka: https://github.com/bigganbing/Fairseq_MorphTE
Model
Ini artikel mencadangkan Kaedah pemampatan membenamkan perkataan MorphTE mula-mula membahagikan perkataan kepada unit terkecil dengan makna semantik - morfem, dan melatih perwakilan vektor berdimensi rendah untuk setiap morfem, dan kemudian menggunakan hasil tensor untuk merealisasikan perwakilan matematik keadaan terjerat kuantum rendah- vektor morfem dimensi, dengan itu memperoleh perwakilan perkataan berdimensi tinggi.
01 Komposisi morfem sesuatu perkataan
Dalam linguistik, morfem ialah unit terkecil dengan fungsi semantik atau tatabahasa tertentu. Untuk bahasa seperti bahasa Inggeris, sesuatu perkataan boleh dibahagikan kepada unit morfem yang lebih kecil seperti akar dan imbuhan. Sebagai contoh, "tidak baik" boleh dibahagikan kepada "un" untuk penafian, "baik" untuk sesuatu seperti "mesra" dan "ly" untuk kata keterangan. Untuk bahasa Cina, aksara Cina juga boleh dibahagikan kepada unit yang lebih kecil seperti radikal Contohnya, "MU" boleh dibahagikan kepada "氵" dan "木" yang mewakili air.

Walaupun morfem mengandungi semantik, ia juga boleh digunakan dalam perkataan yang dikongsi antara mereka untuk menyambung perkataan yang berbeza. Selain itu, bilangan morfem yang terhad boleh digabungkan untuk membentuk bilangan perkataan yang lebih banyak.
02 Perwakilan termampat bagi benam perkataan dalam bentuk tensor terjerat
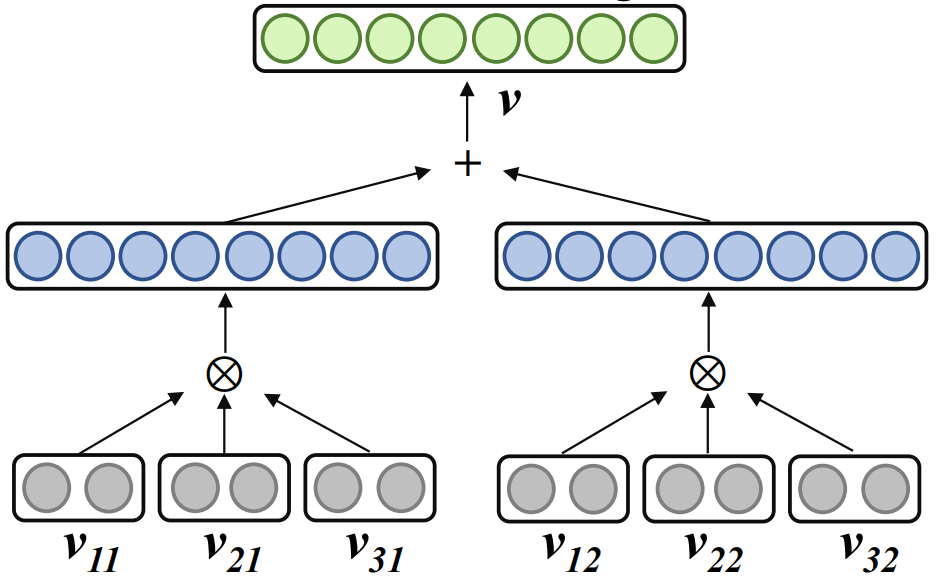
Kerja berkaitan Word2ket mewakili satu embedding perkataan sebagai The entanglement bentuk tensor beberapa vektor berdimensi rendah mempunyai formula berikut:
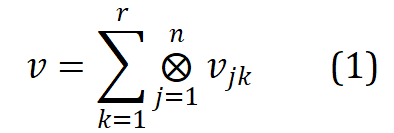
di mana , r ialah pangkat, n ialah susunan dan mewakili hasil tensor. Word2ket hanya perlu menyimpan dan menggunakan vektor dimensi rendah ini untuk membina vektor perkataan dimensi tinggi, dengan itu mencapai pengurangan parameter yang berkesan. Sebagai contoh, apabila r = 2 dan n = 3, vektor perkataan dengan dimensi 512 boleh diperolehi oleh dua kumpulan tiga tensor vektor dimensi rendah dengan dimensi 8 dalam setiap kumpulan diperlukan dikurangkan daripada 512 kepada 48 .
03 perkataan tensor dipertingkatkan morfologi membenamkan perwakilan mampatan
Melalui produk tensor, Word2ket boleh mencapai pemampatan parameter yang jelas, tetapi ia mengalami pemampatan tinggi dan terjemahan mesin Untuk lebih kompleks tugas, biasanya sukar untuk mencapai kesan sebelum pemampatan. Memandangkan vektor berdimensi rendah ialah unit asas yang membentuk tensor belitan, dan morfem ialah unit asas yang membentuk perkataan. Kajian ini mempertimbangkan pengenalan pengetahuan linguistik dan mencadangkan MorphTE, yang melatih vektor morfem berdimensi rendah dan menggunakan hasil darab tensor bagi vektor morfem yang terkandung dalam perkataan itu untuk membina perwakilan pemasukan perkataan yang sepadan.
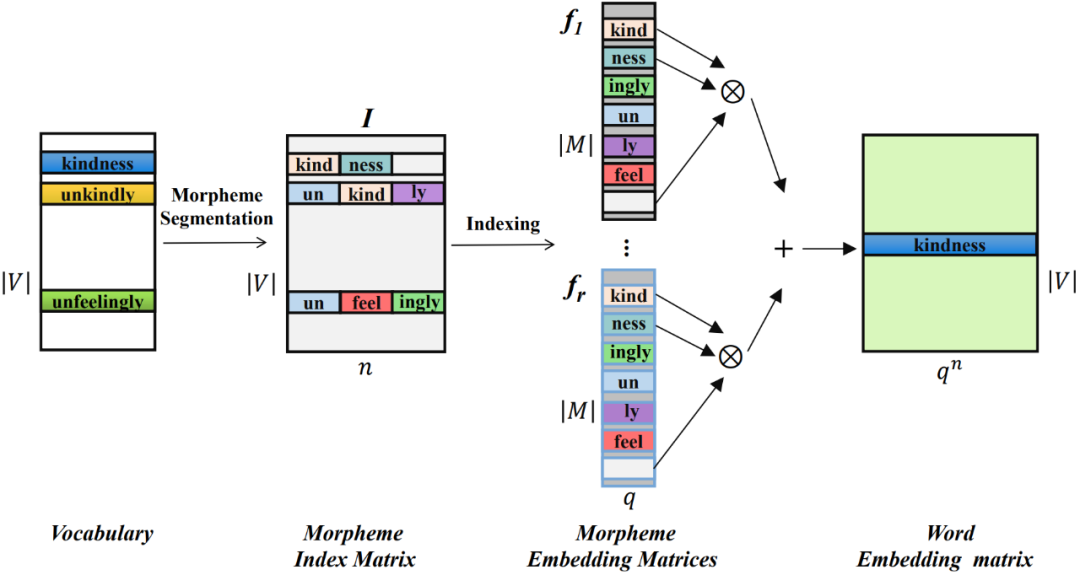
Secara khusus, mula-mula gunakan alat pembahagian morfem untuk membahagikan perkataan dalam senarai perkataan V. Morfem semua perkataan akan membentuk jadual morfem M, dan bilangan morfem akan jauh lebih rendah daripada bilangan perkataan ().
Bagi setiap perkataan, bina vektor indeks morfemnya, yang menunjukkan kedudukan morfem yang terkandung dalam setiap perkataan dalam jadual morfem. Vektor indeks morfem bagi semua perkataan membentuk matriks indeks morfem 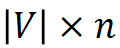 , dengan n ialah susunan MorphTE.
, dengan n ialah susunan MorphTE.
Untuk perkataan ke-j 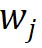 dalam perbendaharaan kata, gunakan vektor indeks morfemnya
dalam perbendaharaan kata, gunakan vektor indeks morfemnya 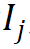 untuk meparameterkannya daripada kumpulan r Vektor morfem yang sepadan diindeks ke dalam matriks benam morfem, dan pembenaman perkataan yang sepadan diperolehi dengan perwakilan tensor terikat melalui hasil tensor Proses ini diformalkan seperti berikut:
untuk meparameterkannya daripada kumpulan r Vektor morfem yang sepadan diindeks ke dalam matriks benam morfem, dan pembenaman perkataan yang sepadan diperolehi dengan perwakilan tensor terikat melalui hasil tensor Proses ini diformalkan seperti berikut:
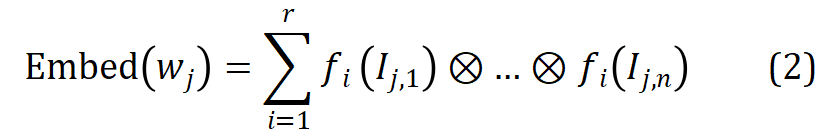
Melalui kaedah di atas, MophTE boleh menyuntik pengetahuan sedia ada linguistik berasaskan morfem ke dalam perwakilan membenamkan perkataan, dan perkongsian vektor morfem antara perkataan yang berbeza secara eksplisit boleh membina hubungan antara perkataan. Selain itu, bilangan dan dimensi vektor morfem adalah jauh lebih rendah daripada saiz dan dimensi perbendaharaan kata, dan MophTE mencapai pemampatan parameter pembenaman perkataan dari kedua-dua perspektif. Oleh itu, MophTE mampu mencapai pemampatan berkualiti tinggi bagi perwakilan pembenaman perkataan.
EksperimenArtikel ini menjalankan percubaan pada tugasan seperti terjemahan dan menjawab soalan dalam bahasa yang berbeza, dan membandingkannya dengan kaedah pemampatan pemampatan berdasarkan penguraian yang berkaitan.
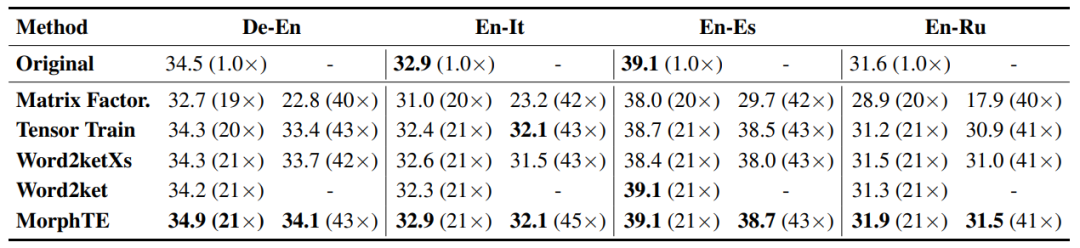
Seperti yang anda lihat daripada jadual, MorphTE boleh menyesuaikan diri dengan bahasa yang berbeza seperti bahasa Inggeris, Jerman, Itali, dsb. Pada nisbah mampatan lebih daripada 20 kali, MorphTE dapat mengekalkan kesan model asal, manakala hampir semua kaedah mampatan lain menunjukkan penurunan kesan. Selain itu, MorphTE berprestasi lebih baik daripada kaedah pemampatan lain pada set data yang berbeza pada nisbah mampatan lebih daripada 40 kali.
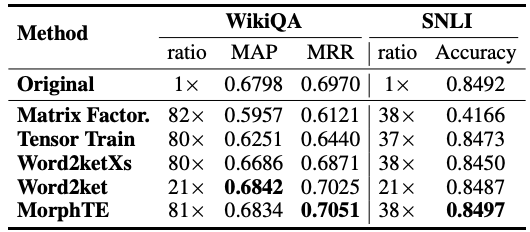
Begitu juga, MorphTE mencapai nisbah mampatan masing-masing 81 kali dan 38 kali pada tugasan soal jawab WikiQA dan tugas penaakulan bahasa semula jadi SNLI mengekalkan kesan model.
KesimpulanMorphTE menggabungkan pengetahuan bahasa morfologi priori dan keupayaan pemampatan yang berkuasa bagi produk tensor untuk mencapai pemampatan berkualiti tinggi bagi pembenaman perkataan. Eksperimen pada bahasa dan tugas yang berbeza menunjukkan bahawa MorphTE boleh mencapai 20 hingga 80 kali pemampatan parameter pembenaman perkataan tanpa merosakkan kesan model. Ini mengesahkan bahawa pengenalan pengetahuan linguistik berasaskan morfem boleh meningkatkan pembelajaran perwakilan mampat bagi benam perkataan. Walaupun pada masa ini MorphTE hanya memodelkan morfem, ia sebenarnya boleh diperluaskan kepada rangka kerja peningkatan pemampatan pemampatan umum yang secara eksplisit memodelkan lebih banyak pengetahuan linguistik priori seperti prototaip, bahagian pertuturan, penggunaan huruf besar, dsb., untuk meningkatkan lagi pemampatan pemampatan perkataan.
Atas ialah kandungan terperinci Adakah pembenaman perkataan mewakili bahagian parameter yang terlalu besar? Kaedah MorphTE 20 kali ganda kesan mampatan tanpa kehilangan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI