
Rumah >Peranti teknologi >AI >Ketepatan pengaturcaraan ChatGPT menurun sebanyak 13%! Penanda aras baharu UIUC & NTU menjadikan kod AI muncul dalam bentuk sebenar
Ketepatan pengaturcaraan ChatGPT menurun sebanyak 13%! Penanda aras baharu UIUC & NTU menjadikan kod AI muncul dalam bentuk sebenar

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-17 14:58:131618semak imbas

Menulis kod menggunakan ChatGPT telah menjadi operasi rutin bagi ramai pengaturcara.
△"Sekurang-kurangnya 3~5 kali lebih pantas"
Tetapi pernahkah anda terfikir sama ada kod yang dihasilkan oleh ChatGPT mempunyai ada Bukankah ia hanya "kelihatan tepat"?
Kajian baharu dari University of Illinois di Urbana-Champaign dan Universiti Nanjing menunjukkan:
Ketepatan kod yang dijana oleh ChatGPT dan GPT-4 sekurang-kurangnya lebih tinggi daripada yang dinilai sebelum ini pengurangan 13%!

Sesetengah netizen mengeluh kerana terlalu banyak kertas ML menggunakan beberapa penanda aras yang bermasalah atau terhad untuk menilai model, yang berumur pendek. Ia mencapai "SOTA" sepenuhnya, dan hasilnya ialah bentuk asal didedahkan selepas menukar kaedah penilaian.

Beberapa netizen berkata ini juga menunjukkan bahawa kod yang dihasilkan oleh model besar masih memerlukan pengawasan manual, "Masa utama untuk menulis kod AI belum belum sampai".

Jadi, apakah jenis kaedah penilaian baharu yang dicadangkan oleh kertas kerja?
Jadikan soalan ujian kod AI lebih sukar
Kaedah baharu ini dipanggil EvalPlus, dan ia merupakan rangka kerja penilaian kod automatik.
Secara khusus, ia akan menjadikan penanda aras penilaian ini lebih teliti dengan menambah baik kepelbagaian input dan ketepatan perihalan masalah bagi set data penilaian sedia ada.
Di satu pihak ialah kepelbagaian input. EvalPlus mula-mula akan menggunakan ChatGPT untuk menjana beberapa sampel input benih berdasarkan jawapan standard (walaupun keupayaan pengaturcaraan ChatGPT perlu diuji, nampaknya tidak konsisten untuk menggunakannya untuk menjana input benih)
Kemudian, EvalPlus akan digunakan untuk menambah baik input benih ini, menjadikannya lebih sukar, lebih kompleks dan lebih rumit.
Aspek lain ialah ketepatan penerangan masalah. EvalPlus akan mengubah perihalan keperluan kod menjadi lebih tepat Walaupun mengekang keadaan input, ia akan menambah penerangan masalah bahasa semula jadi untuk meningkatkan keperluan ketepatan untuk output model.
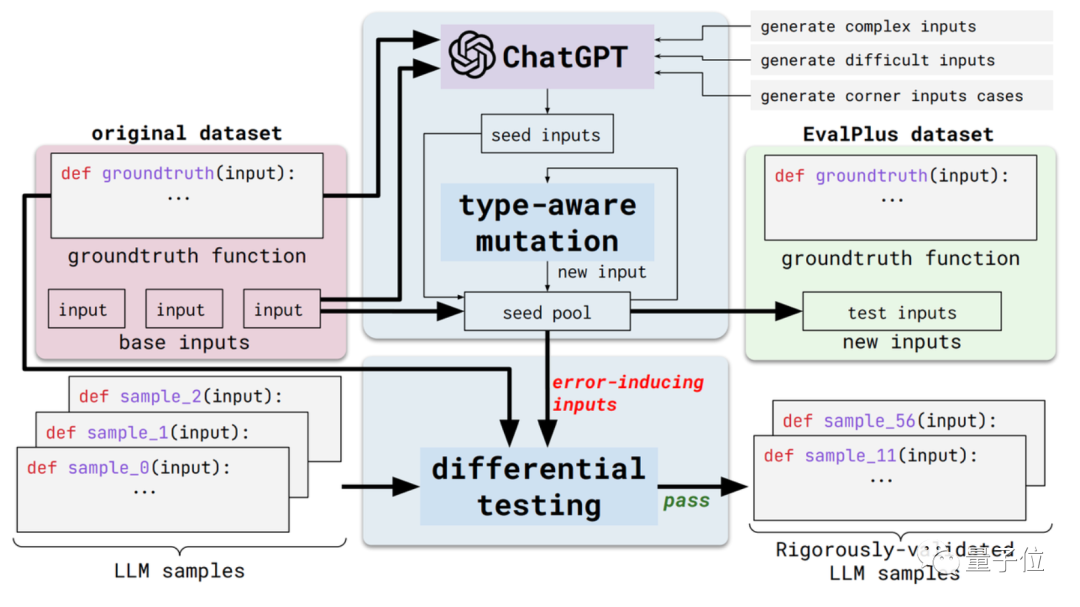
Di sini, kertas kerja memilih set data MANUSIA sebagai demonstrasi.
HUMANEVAL ialah set data kod yang dihasilkan bersama oleh OpenAI dan Anthropic AI Ia mengandungi 164 soalan pengaturcaraan asal, yang melibatkan beberapa jenis soalan dalam pemahaman bahasa, algoritma, matematik dan temu bual perisian.
EvalPlus akan menjadikan masalah pengaturcaraan kelihatan lebih jelas dengan menambah baik jenis input dan penerangan fungsi set data tersebut, sambil menjadikan input yang digunakan untuk ujian lebih "rumit" atau sukar.
Ambil salah satu soalan pengaturcaraan set kesatuan sebagai contoh AI diperlukan untuk menulis kod untuk mencari elemen biasa dalam dua senarai data dan mengisih elemen ini.
EvalPlus menggunakannya untuk menguji ketepatan kod yang ditulis oleh ChatGPT.
Selepas menjalankan ujian input mudah, kami mendapati ChatGPT dapat mengeluarkan jawapan yang tepat. Tetapi jika anda menukar input, anda akan menemui pepijat dalam versi ChatGPT kod:

Memang benar bahawa soalan ujian lebih banyak sukar untuk AI.

Berdasarkan kaedah ini, EvalPlus juga membuat versi set data HUMANEVAL+ yang dipertingkatkan sambil menambah input, ia membetulkan beberapa jawapan dalam HUMANEVAL Soalan pengaturcaraan masalah.
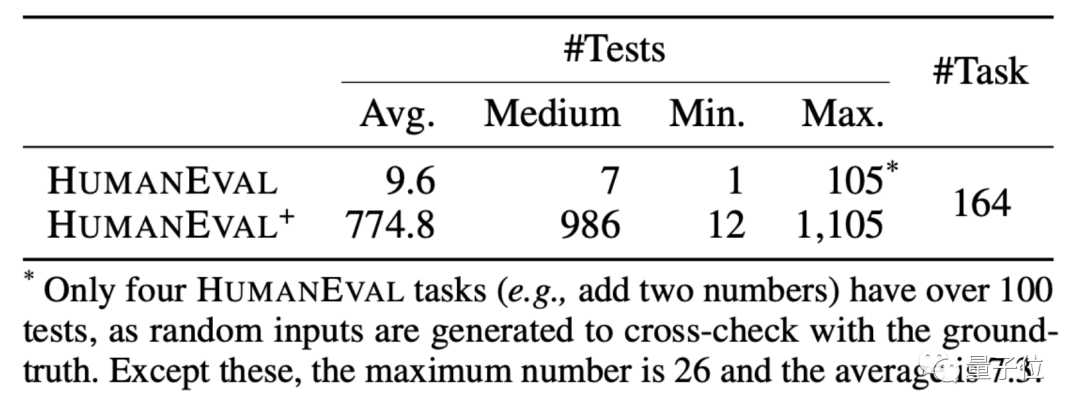
Jadi, di bawah "set soalan ujian baharu" ini, berapakah ketepatan model bahasa besar sebenarnya akan didiskaunkan?
Ketepatan kod LLM dikurangkan sebanyak 15% secara purata
Pengarang menguji 10 AI penjanaan kod yang popular pada masa ini.
GPT-4, ChatGPT, CODEGEN, VICUNA, SANTACODER, INCODER, GPT-J, GPT-NEO, PolyCoder, StableLM-α.
Berdasarkan jadual, selepas ujian yang ketat, ketepatan penjanaan kumpulan AI ini telah menurun:
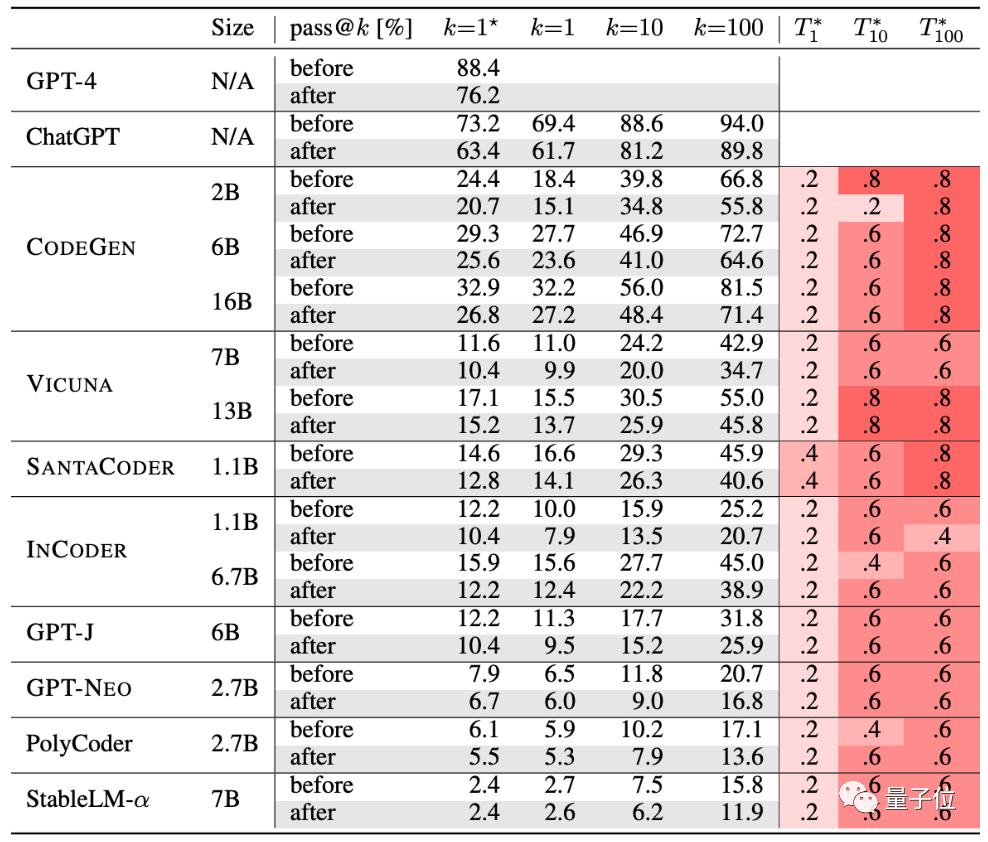
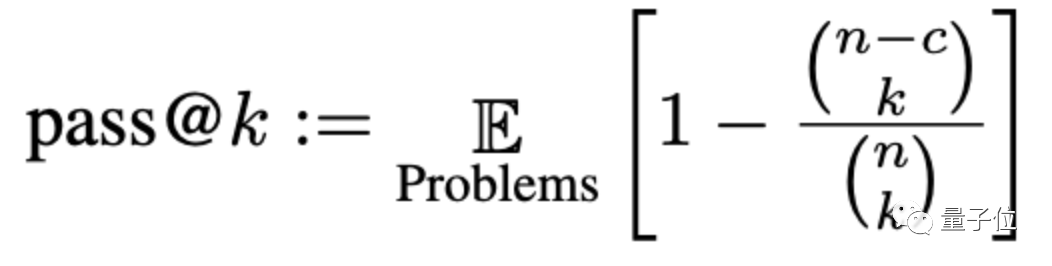
Ketepatan akan dinilai di sini melalui kaedah yang dipanggil pass@k, di mana k ialah bilangan program yang membolehkan model besar dijana untuk masalah, n ialah bilangan input yang digunakan untuk ujian, dan c ialah bilangan input yang betul :
Menurut set piawaian penilaian baharu ini, ketepatan model besar telah menurun sebanyak 15% secara purata, dan CODEGEN yang lebih banyak dikaji -16B malah telah jatuh lebih daripada 18%.
Bagi prestasi kod hasil ChatGPT dan GPT-4, ia juga menurun sekurang-kurangnya 13%.
Namun, sesetengah netizen berkata bahawa ia adalah "fakta yang diketahui umum" bahawa kod yang dihasilkan oleh model besar tidak begitu baik, dan apa yang perlu dikaji ialah "mengapa kod yang ditulis oleh model besar tidak boleh digunakan."
Atas ialah kandungan terperinci Ketepatan pengaturcaraan ChatGPT menurun sebanyak 13%! Penanda aras baharu UIUC & NTU menjadikan kod AI muncul dalam bentuk sebenar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI