
Rumah >pembangunan bahagian belakang >Tutorial Python >Apakah tiga cara untuk menyimpan dan mengakses imej Python?
Apakah tiga cara untuk menyimpan dan mengakses imej Python?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-16 21:08:301802semak imbas
Kata Pengantar
ImageNet ialah pangkalan data imej awam terkenal yang digunakan untuk melatih model bagi tugas seperti pengelasan objek, pengesanan dan pembahagian Ia mengandungi lebih daripada 14 juta imej.
Semasa memproses data imej dalam Python, contohnya, menggunakan algoritma seperti rangkaian saraf konvolusi (juga dipanggil CNN) boleh memproses sejumlah besar set data imej Di sini anda perlu belajar cara menyimpan dan membaca data cara yang paling mudah.
Perlu ada cara kuantitatif untuk membandingkan pemprosesan data imej, berapa lama masa yang diperlukan untuk membaca dan menulis fail, dan berapa banyak memori cakera akan digunakan.
Gunakan kaedah yang berbeza untuk memproses dan menyelesaikan masalah penyimpanan imej dan pengoptimuman prestasi.
Penyediaan data
Set data boleh main
Set data imej yang kita kenali, CIFAR-10, terdiri daripada 60,000 imej warna 32x32 piksel, yang dimiliki oleh objek berbeza kategori, seperti anjing, kucing, dan kapal terbang. CIFAR bukanlah set data yang sangat besar secara relatifnya, tetapi menggunakan set data TinyImages penuh memerlukan lebih kurang 400GB ruang cakera kosong.
Kod dalam artikel digunakan pada set data alamat muat turun CIFAR-10 set data.
Data ini bersiri dan disimpan dalam kelompok menggunakan cPickle. Modul acar boleh mensiri sebarang objek dalam Python tanpa memerlukan kod tambahan atau penukaran. Walau bagaimanapun, pemprosesan sejumlah besar data mungkin menimbulkan risiko keselamatan yang tidak dapat dinilai.
Muat imej ke dalam tatasusunan NumPy
import numpy as np
import pickle
from pathlib import Path
# 文件路径
data_dir = Path("data/cifar-10-batches-py/")
# 解码功能
def unpickle(file):
with open(file, "rb") as fo:
dict = pickle.load(fo, encoding="bytes")
return dict
images, labels = [], []
for batch in data_dir.glob("data_batch_*"):
batch_data = unpickle(batch)
for i, flat_im in enumerate(batch_data[b"data"]):
im_channels = []
# 每个图像都是扁平化的,通道按 R, G, B 的顺序排列
for j in range(3):
im_channels.append(
flat_im[j * 1024 : (j + 1) * 1024].reshape((32, 32))
)
# 重建原始图像
images.append(np.dstack((im_channels)))
# 保存标签
labels.append(batch_data[b"labels"][i])
print("加载 CIFAR-10 训练集:")
print(f" - np.shape(images) {np.shape(images)}")
print(f" - np.shape(labels) {np.shape(labels)}")Tetapan untuk storan imej
Pasang Bantal perpustakaan pihak ketiga untuk pemprosesan imej.
pip install Pillow
LMDB
"Pangkalan Data Pemetaan Memori Kilat" (LMDB) juga dikenali sebagai "Pangkalan Data Kilat" kerana kelajuannya dan penggunaan fail dipetakan memori. Ia adalah stor nilai kunci, bukan pangkalan data hubungan.
Pasang lmdb perpustakaan pihak ketiga untuk pemprosesan imej.
pip install lmdb
HDF5
HDF5 bermaksud Format Data Hierarki, format fail yang dipanggil HDF4 atau HDF5. Format data saintifik mudah alih dan padat ini datang daripada Pusat Nasional untuk Aplikasi Superkomputer.
Pasang h6py perpustakaan pihak ketiga untuk pemprosesan imej.
pip install h6py
Penyimpanan satu imej
3 cara berbeza untuk membaca data
from pathlib import Path
disk_dir = Path("data/disk/")
lmdb_dir = Path("data/lmdb/")
hdf5_dir = Path("data/hdf5/")Data yang dimuatkan pada masa yang sama boleh disimpan dalam folder berasingan
disk_dir.mkdir(parents=True, exist_ok=True) lmdb_dir.mkdir(parents=True, exist_ok=True) hdf5_dir.mkdir(parents=True, exist_ok=True)
Simpan ke cakera
Menggunakan Bantal Input ialah imej imej tunggal, disimpan dalam ingatan sebagai tatasusunan NumPy dan dinamakan dengan ID image_id imej yang unik.
Imej tunggal disimpan ke cakera
from PIL import Image
import csv
def store_single_disk(image, image_id, label):
""" 将单个图像作为 .png 文件存储在磁盘上。
参数:
---------------
image 图像数组, (32, 32, 3) 格式
image_id 图像的整数唯一 ID
label 图像标签
"""
Image.fromarray(image).save(disk_dir / f"{image_id}.png")
with open(disk_dir / f"{image_id}.csv", "wt") as csvfile:
writer = csv.writer(
csvfile, delimiter=" ", quotechar="|", quoting=csv.QUOTE_MINIMAL
)
writer.writerow([label])Simpan ke LMDB
LMDB ialah sistem storan nilai kunci di mana setiap entri disimpan sebagai tatasusunan bait dan kuncinya ialah pengecam unik untuk setiap imej dan nilainya ialah imej itu sendiri.
Kedua-dua kunci dan nilai mestilah rentetan. Penggunaan biasa adalah untuk mensirikan nilai kepada rentetan dan kemudian menyahsirinya apabila membacanya kembali.
Saiz imej yang digunakan untuk pembinaan semula Sesetengah set data mungkin mengandungi imej dengan saiz yang berbeza dan kaedah ini akan digunakan.
class CIFAR_Image:
def __init__(self, image, label):
self.channels = image.shape[2]
self.size = image.shape[:2]
self.image = image.tobytes()
self.label = label
def get_image(self):
""" 将图像作为 numpy 数组返回 """
image = np.frombuffer(self.image, dtype=np.uint8)
return image.reshape(*self.size, self.channels)Imej tunggal disimpan ke LMDB
import lmdb
import pickle
def store_single_lmdb(image, image_id, label):
""" 将单个图像存储到 LMDB
参数:
---------------
image 图像数组, (32, 32, 3) 格式
image_id 图像的整数唯一 ID
label 图像标签
"""
map_size = image.nbytes * 10
# Create a new LMDB environment
env = lmdb.open(str(lmdb_dir / f"single_lmdb"), map_size=map_size)
# Start a new write transaction
with env.begin(write=True) as txn:
# All key-value pairs need to be strings
value = CIFAR_Image(image, label)
key = f"{image_id:08}"
txn.put(key.encode("ascii"), pickle.dumps(value))
env.close()Storan HDF5
Fail HDF5 boleh mengandungi berbilang set data. Dua set data boleh dibuat, satu untuk imej dan satu untuk metadata.
import h6py
def store_single_hdf5(image, image_id, label):
""" 将单个图像存储到 HDF5 文件
参数:
---------------
image 图像数组, (32, 32, 3) 格式
image_id 图像的整数唯一 ID
label 图像标签
"""
# 创建一个新的 HDF5 文件
file = h6py.File(hdf5_dir / f"{image_id}.h6", "w")
# 在文件中创建数据集
dataset = file.create_dataset(
"image", np.shape(image), h6py.h6t.STD_U8BE, data=image
)
meta_set = file.create_dataset(
"meta", np.shape(label), h6py.h6t.STD_U8BE, data=label
)
file.close()Perbandingan Storan
Letakkan ketiga-tiga fungsi yang menyimpan satu imej ke dalam kamus.
_store_single_funcs = dict(
disk=store_single_disk,
lmdb=store_single_lmdb,
hdf5=store_single_hdf5
)Simpan imej pertama dalam CIFAR dan tag sepadannya dalam tiga cara berbeza.
from timeit import timeit
store_single_timings = dict()
for method in ("disk", "lmdb", "hdf5"):
t = timeit(
"_store_single_funcs[method](image, 0, label)",
setup="image=images[0]; label=labels[0]",
number=1,
globals=globals(),
)
store_single_timings[method] = t
print(f"存储方法: {method}, 使用耗时: {t}")Mari kita lihat perbandingannya.
| 存储方法 | 存储耗时 | 使用内存 |
|---|---|---|
| Disk | 2.1 ms | 8 K |
| LMDB | 1.7 ms | 32 K |
| HDF5 | 8.1 ms | 8 K |
Penyimpanan berbilang imej
Serupa dengan kaedah storan imej tunggal, ubah suai kod untuk menyimpan berbilang data imej.
Kod pelarasan imej berbilang
Menyimpan berbilang imej sebagai fail .png boleh dilihat sebagai memanggil kaedah store_single_method() beberapa kali. Pendekatan ini tidak boleh dilakukan dengan LMDB atau HDF5 kerana setiap imej wujud dalam fail pangkalan data yang berbeza.
Simpan satu set imej ke cakera
store_many_disk(images, labels):
""" 参数:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
num_images = len(images)
# 一张一张保存所有图片
for i, image in enumerate(images):
Image.fromarray(image).save(disk_dir / f"{i}.png")
# 将所有标签保存到 csv 文件
with open(disk_dir / f"{num_images}.csv", "w") as csvfile:
writer = csv.writer(
csvfile, delimiter=" ", quotechar="|", quoting=csv.QUOTE_MINIMAL
)
for label in labels:
writer.writerow([label])Simpan satu set imej ke LMDB
def store_many_lmdb(images, labels):
""" 参数:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
num_images = len(images)
map_size = num_images * images[0].nbytes * 10
# 为所有图像创建一个新的 LMDB 数据库
env = lmdb.open(str(lmdb_dir / f"{num_images}_lmdb"), map_size=map_size)
# 在一个事务中写入所有图像
with env.begin(write=True) as txn:
for i in range(num_images):
# 所有键值对都必须是字符串
value = CIFAR_Image(images[i], labels[i])
key = f"{i:08}"
txn.put(key.encode("ascii"), pickle.dumps(value))
env.close()Simpan satu set imej ke HDF5
rreeeSediakan set data perbandingan
Uji dengan 100000 imej
def store_many_hdf5(images, labels):
""" 参数:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
num_images = len(images)
# 创建一个新的 HDF5 文件
file = h6py.File(hdf5_dir / f"{num_images}_many.h6", "w")
# 在文件中创建数据集
dataset = file.create_dataset(
"images", np.shape(images), h6py.h6t.STD_U8BE, data=images
)
meta_set = file.create_dataset(
"meta", np.shape(labels), h6py.h6t.STD_U8BE, data=labels
)
file.close()Buat pengiraan untuk perbandingan
cutoffs = [10, 100, 1000, 10000, 100000] images = np.concatenate((images, images), axis=0) labels = np.concatenate((labels, labels), axis=0) # 确保有 100,000 个图像和标签 print(np.shape(images)) print(np.shape(labels))
PLOT Paparkan plot tunggal dengan berbilang set data dan legenda yang sepadan
_store_many_funcs = dict(
disk=store_many_disk, lmdb=store_many_lmdb, hdf5=store_many_hdf5
)
from timeit import timeit
store_many_timings = {"disk": [], "lmdb": [], "hdf5": []}
for cutoff in cutoffs:
for method in ("disk", "lmdb", "hdf5"):
t = timeit(
"_store_many_funcs[method](images_, labels_)",
setup="images_=images[:cutoff]; labels_=labels[:cutoff]",
number=1,
globals=globals(),
)
store_many_timings[method].append(t)
# 打印出方法、截止时间和使用时间
print(f"Method: {method}, Time usage: {t}")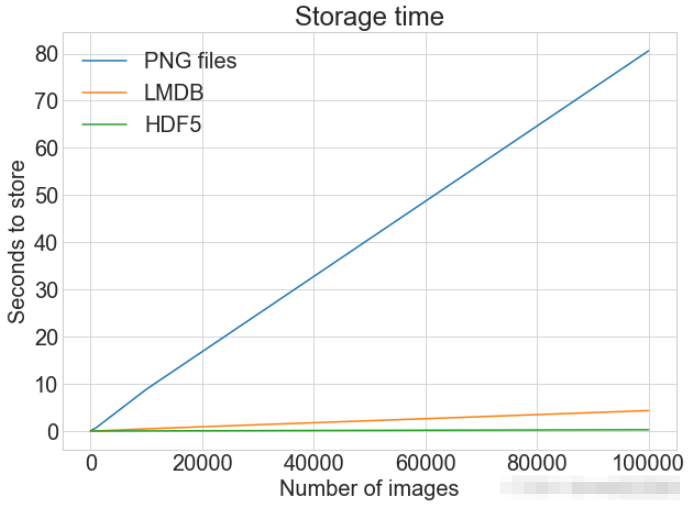
Membaca imej tunggal
Membaca dari cakera
import matplotlib.pyplot as plt
def plot_with_legend(
x_range, y_data, legend_labels, x_label, y_label, title, log=False
):
""" 参数:
--------------
x_range 包含 x 数据的列表
y_data 包含 y 值的列表
legend_labels 字符串图例标签列表
x_label x 轴标签
y_label y 轴标签
"""
plt.style.use("seaborn-whitegrid")
plt.figure(figsize=(10, 7))
if len(y_data) != len(legend_labels):
raise TypeError(
"数据集的数量与标签的数量不匹配"
)
all_plots = []
for data, label in zip(y_data, legend_labels):
if log:
temp, = plt.loglog(x_range, data, label=label)
else:
temp, = plt.plot(x_range, data, label=label)
all_plots.append(temp)
plt.title(title)
plt.xlabel(x_label)
plt.ylabel(y_label)
plt.legend(handles=all_plots)
plt.show()
# Getting the store timings data to display
disk_x = store_many_timings["disk"]
lmdb_x = store_many_timings["lmdb"]
hdf5_x = store_many_timings["hdf5"]
plot_with_legend(
cutoffs,
[disk_x, lmdb_x, hdf5_x],
["PNG files", "LMDB", "HDF5"],
"Number of images",
"Seconds to store",
"Storage time",
log=False,
)
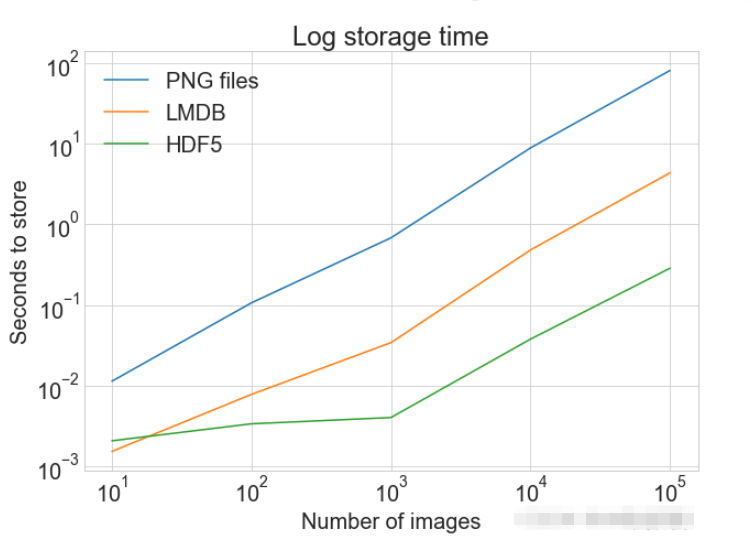
plot_with_legend(
cutoffs,
[disk_x, lmdb_x, hdf5_x],
["PNG files", "LMDB", "HDF5"],
"Number of images",
"Seconds to store",
"Log storage time",
log=True,
)Membaca dari LMDB Ambil
def read_single_disk(image_id):
""" 参数:
---------------
image_id 图像的整数唯一 ID
返回结果:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
image = np.array(Image.open(disk_dir / f"{image_id}.png"))
with open(disk_dir / f"{image_id}.csv", "r") as csvfile:
reader = csv.reader(
csvfile, delimiter=" ", quotechar="|", quoting=csv.QUOTE_MINIMAL
)
label = int(next(reader)[0])
return image, labeldan baca
def read_single_lmdb(image_id):
""" 参数:
---------------
image_id 图像的整数唯一 ID
返回结果:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
# 打开 LMDB 环境
env = lmdb.open(str(lmdb_dir / f"single_lmdb"), readonly=True)
# 开始一个新的事务
with env.begin() as txn:
# 进行编码
data = txn.get(f"{image_id:08}".encode("ascii"))
# 加载的 CIFAR_Image 对象
cifar_image = pickle.loads(data)
# 检索相关位
image = cifar_image.get_image()
label = cifar_image.label
env.close()
return image, labeldari HDF5 Bandingkan kaedah bacaan
def read_single_hdf5(image_id):
""" 参数:
---------------
image_id 图像的整数唯一 ID
返回结果:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
# 打开 HDF5 文件
file = h6py.File(hdf5_dir / f"{image_id}.h6", "r+")
image = np.array(file["/image"]).astype("uint8")
label = int(np.array(file["/meta"]).astype("uint8"))
return image, label| 存储方法 | 存储耗时 |
|---|---|
| Disk | 1.7 ms |
| LMDB | 4.4 ms |
| HDF5 | 2.3 ms |
多个图像的读取
可以将多个图像保存为.png文件,这等价于多次调用 read_single_method()。这并不适用于 LMDB 或 HDF5,因为每个图像都储存在不同的数据库文件中。
多图像调整代码
从磁盘中读取多个都图像
def read_many_disk(num_images):
""" 参数:
---------------
num_images 要读取的图像数量
返回结果:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
images, labels = [], []
# 循环遍历所有ID,一张一张地读取每张图片
for image_id in range(num_images):
images.append(np.array(Image.open(disk_dir / f"{image_id}.png")))
with open(disk_dir / f"{num_images}.csv", "r") as csvfile:
reader = csv.reader(
csvfile, delimiter=" ", quotechar="|", quoting=csv.QUOTE_MINIMAL
)
for row in reader:
labels.append(int(row[0]))
return images, labels从LMDB中读取多个都图像
def read_many_lmdb(num_images):
""" 参数:
---------------
num_images 要读取的图像数量
返回结果:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
images, labels = [], []
env = lmdb.open(str(lmdb_dir / f"{num_images}_lmdb"), readonly=True)
# 开始一个新的事务
with env.begin() as txn:
# 在一个事务中读取,也可以拆分成多个事务分别读取
for image_id in range(num_images):
data = txn.get(f"{image_id:08}".encode("ascii"))
# CIFAR_Image 对象,作为值存储
cifar_image = pickle.loads(data)
# 检索相关位
images.append(cifar_image.get_image())
labels.append(cifar_image.label)
env.close()
return images, labels从HDF5中读取多个都图像
def read_many_hdf5(num_images):
""" 参数:
---------------
num_images 要读取的图像数量
返回结果:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
images, labels = [], []
# 打开 HDF5 文件
file = h6py.File(hdf5_dir / f"{num_images}_many.h6", "r+")
images = np.array(file["/images"]).astype("uint8")
labels = np.array(file["/meta"]).astype("uint8")
return images, labels
_read_many_funcs = dict(
disk=read_many_disk, lmdb=read_many_lmdb, hdf5=read_many_hdf5
)准备数据集对比
创建一个计算方式进行对比
from timeit import timeit
read_many_timings = {"disk": [], "lmdb": [], "hdf5": []}
for cutoff in cutoffs:
for method in ("disk", "lmdb", "hdf5"):
t = timeit(
"_read_many_funcs[method](num_images)",
setup="num_images=cutoff",
number=1,
globals=globals(),
)
read_many_timings[method].append(t)
# Print out the method, cutoff, and elapsed time
print(f"读取方法: {method}, No. images: {cutoff}, 耗时: {t}")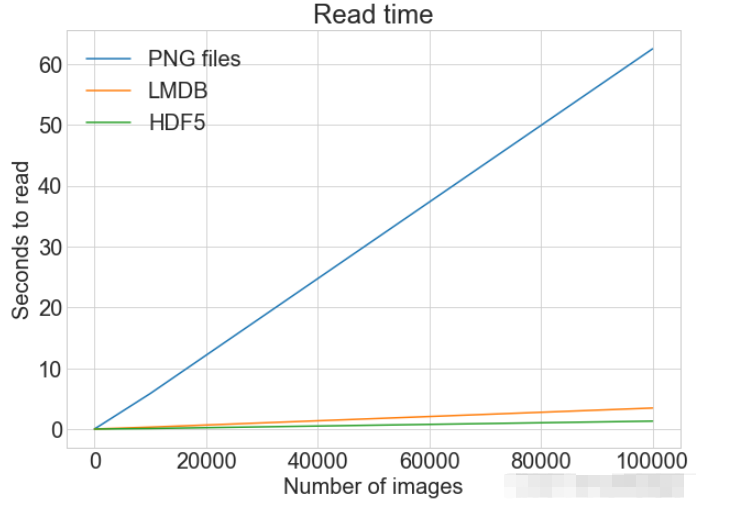
读写操作综合比较
数据对比
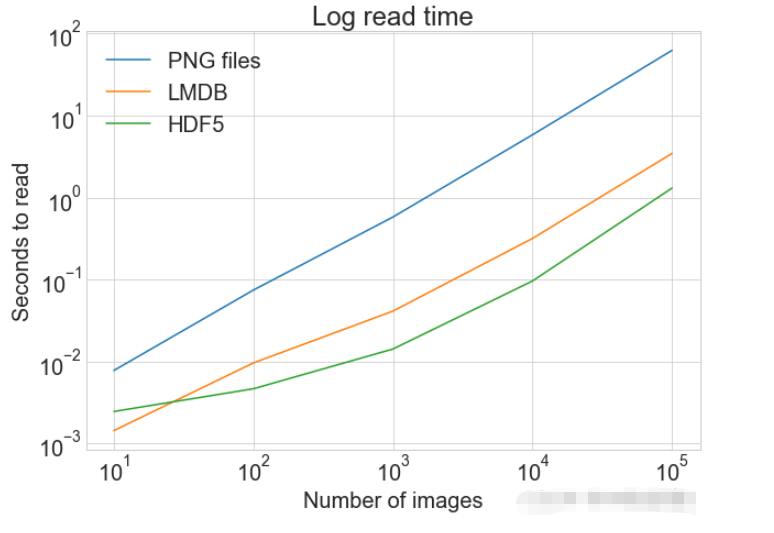
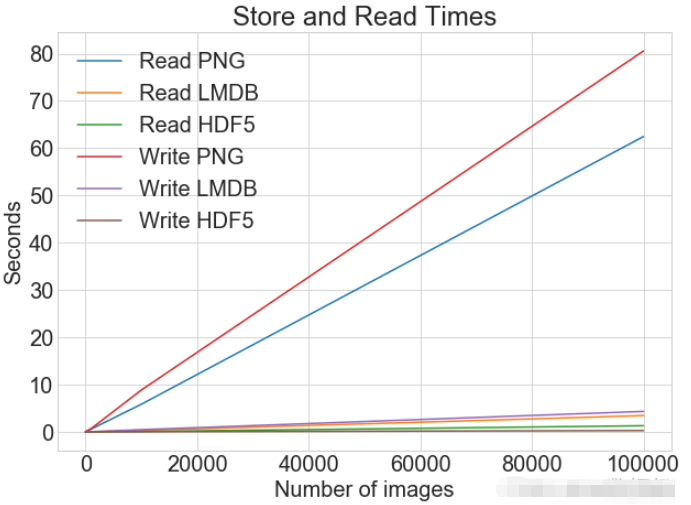
同一张图表上查看读取和写入时间
plot_with_legend(
cutoffs,
[disk_x_r, lmdb_x_r, hdf5_x_r, disk_x, lmdb_x, hdf5_x],
[
"Read PNG",
"Read LMDB",
"Read HDF5",
"Write PNG",
"Write LMDB",
"Write HDF5",
],
"Number of images",
"Seconds",
"Log Store and Read Times",
log=False,
)
各种存储方式使用磁盘空间
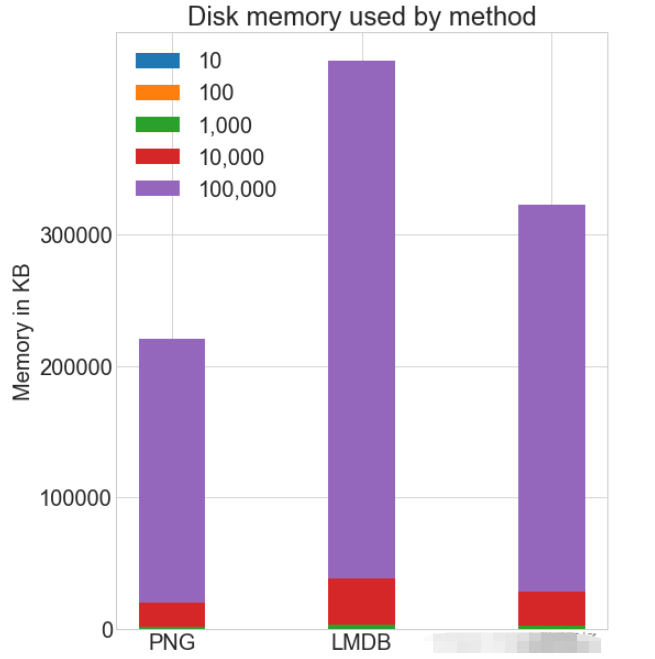
虽然 HDF5 和 LMDB 都占用更多的磁盘空间。需要注意的是 LMDB 和 HDF5 磁盘的使用和性能在很大程度上取决于各种因素,包括操作系统,更重要的是存储的数据大小。
并行操作
通常对于大的数据集,可以通过并行化来加速操作。 也就是我们经常说的并发处理。
作为.png 文件存储到磁盘实际上允许完全并发。可通过使用不同的图像名称,实现从多个线程读取多个图像,或一次性写入多个文件。
如果将所有 CIFAR 分成十组,那么可以为一组中的每个读取设置十个进程,并且相应的处理时间可以减少到原来的10%左右。
Atas ialah kandungan terperinci Apakah tiga cara untuk menyimpan dan mengakses imej Python?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!