
Rumah >Peranti teknologi >AI >Model 3D penjanaan teks OpenAI telah dinaik taraf untuk melengkapkan pemodelan dalam beberapa saat, yang lebih boleh digunakan daripada Point·E
Model 3D penjanaan teks OpenAI telah dinaik taraf untuk melengkapkan pemodelan dalam beberapa saat, yang lebih boleh digunakan daripada Point·E

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-16 10:04:131598semak imbas
Model besar AI Generatif adalah tumpuan usaha OpenAI Ia telah pun melancarkan model imej terjana teks DALL-E dan DALL-E 2, serta POINT-E, yang menjana model 3D berdasarkan teks lebih awal. tahun ini.
Baru-baru ini, pasukan penyelidik OpenAI telah meningkatkan model generatif 3D dan Shap・E yang baru dilancarkan, yang merupakan model generatif bersyarat untuk mensintesis aset 3D . Pada masa ini, berat model yang berkaitan, kod inferens dan sampel telah menjadi sumber terbuka.

- Alamat Kertas : https://arxiv.org/abs/2305.02463
- Alamat projek: https://github.com/openai/shap-e
Mari kita lihat kesan generasi dahulu. Sama seperti menjana imej berdasarkan teks, model objek 3D yang dijana oleh Shap・E memfokuskan pada "tanpa kekangan". Contohnya, pesawat yang kelihatan seperti pisang:

Kerusi yang kelihatan seperti pokok:

Terdapat juga contoh klasik, seperti kerusi alpukat:

Sudah tentu, beberapa objek biasa boleh juga dihasilkan model 3D, contohnya semangkuk sayur-sayuran:

Donut:

Shap・E yang dicadangkan dalam artikel ini ialah model resapan terpendam pada ruang fungsi tersirat 3D, yang boleh dipaparkan kepada NeRF dan jerat tekstur. Memandangkan set data, seni bina model dan pengiraan latihan yang sama, Shap・E mengatasi model penjanaan eksplisit yang serupa. Para penyelidik mendapati bahawa model bersyarat teks tulen boleh menjana objek yang pelbagai dan menarik, yang juga menunjukkan potensi menjana perwakilan tersirat.

Tidak seperti kerja pada model generatif 3D yang menghasilkan perwakilan output tunggal, Shap-E boleh Menjana secara langsung parameter fungsi tersirat. Latihan Shap-E dibahagikan kepada dua peringkat: pertama melatih pengekod, yang secara deterministik memetakan aset 3D ke dalam parameter fungsi tersirat melatih model resapan bersyarat pada output pengekod. Apabila dilatih pada set data besar bagi data 3D dan teks yang berpasangan, model ini dapat menjana aset 3D yang kompleks dan pelbagai dalam beberapa saat. Berbanding dengan model penjanaan eksplisit awan titik Point・E, Shap-E memodelkan ruang keluaran berdimensi tinggi, berbilang perwakilan, menumpu lebih cepat dan mencapai kualiti sampel yang setara atau lebih baik.
Latar belakang penyelidikan
Artikel ini memfokuskan pada dua perwakilan neural tersirat (INR) untuk perwakilan 3D:
- NeRF INR yang mewakili pemandangan 3D sebagai fungsi yang memetakan koordinat dan melihat arah kepada ketumpatan dan warna RGB
- DMTet dan sambungannya GET3D Represents; jejaring 3D bertekstur yang memetakan koordinat kepada warna, jarak yang ditandatangani dan offset bucu sebagai fungsi. INR ini membolehkan jerat segi tiga 3D dibina dengan cara yang boleh dibezakan dan kemudian dijadikan pustaka rasterisasi boleh dibezakan.
Walaupun INR fleksibel dan ekspresif, adalah mahal untuk mendapatkan INR bagi setiap sampel dalam set data. Selain itu, setiap INR mungkin mempunyai banyak parameter berangka, yang boleh menyebabkan kesukaran semasa melatih model generatif hiliran. Dengan menyelesaikan masalah ini menggunakan pengekod auto dengan penyahkod tersirat, perwakilan terpendam yang lebih kecil boleh diperolehi yang dimodelkan secara langsung dengan teknik generatif sedia ada. Pendekatan alternatif ialah menggunakan meta-pembelajaran untuk mencipta set data INR yang berkongsi kebanyakan parameternya, dan kemudian melatih model resapan atau aliran normal pada parameter percuma INR ini. Ia juga telah dicadangkan bahawa meta-pembelajaran berasaskan kecerunan mungkin tidak diperlukan, dan sebaliknya pengekod Transformer harus dilatih secara langsung untuk menghasilkan parameter NeRF yang dikondisikan pada berbilang paparan objek 3D.
Para penyelidik menggabungkan dan mengembangkan kaedah di atas dan akhirnya memperoleh Shap・E, yang menjadi model penjanaan bersyarat untuk pelbagai perwakilan tersirat 3D yang kompleks. Mula-mula jana parameter INR untuk aset 3D dengan melatih pengekod berasaskan Transformer, dan kemudian melatih model resapan pada output pengekod. Tidak seperti pendekatan sebelumnya, INR dijana yang mewakili kedua-dua NeRF dan jejaring, membolehkannya dipaparkan dalam pelbagai cara atau diimport ke dalam aplikasi 3D hiliran.
Apabila dilatih pada set data berjuta-juta aset 3D, model kami dapat menghasilkan pelbagai sampel yang boleh dikenal pasti di bawah gesaan teks. Shap-E menumpu lebih cepat daripada Point·E, model generatif 3D eksplisit yang dicadangkan baru-baru ini. Ia mencapai hasil yang setanding atau lebih baik dengan seni bina model, set data dan mekanisme pelaziman yang sama.
Tinjauan Keseluruhan Kaedah
Penyelidik mula-mula melatih pengekod untuk menjana perwakilan tersirat, dan kemudian melatih model resapan pada perwakilan terpendam yang dijana oleh pengekod, yang kebanyakannya dibahagikan ke dalam dua langkah berikut Selesai:
1. Latih pengekod untuk menghasilkan parameter fungsi tersirat diberi perwakilan eksplisit padat aset 3D yang diketahui. Pengekod menghasilkan unjuran linear bagi perwakilan terpendam aset 3D untuk mendapatkan pemberat perceptron berbilang lapisan (MLP 2. Guna pengekod pada set data, dan kemudian gunakan pengekod pada data terpendam Latihan difusi sebelum); set itu. Model dikondisikan pada imej atau penerangan teks.
Kami melatih semua model pada set data besar aset 3D menggunakan pemaparan, awan titik dan kapsyen teks yang sepadan.
Pengekod 3D
Seni bina pengekod ditunjukkan dalam Rajah 2 di bawah.
Resapan Potensi
Model penjanaan menggunakan seni bina resapan Point・E berdasarkan pengubah, tetapi menggunakan vektor pendam urutan sebaliknya Awan titik. Urutan bentuk fungsi terpendam ialah 1024×1024 dan dimasukkan ke pengubah sebagai jujukan 1024 token, di mana setiap token sepadan dengan baris yang berbeza bagi matriks berat MLP. Oleh itu, model ini secara kasarnya setara dengan model Point·E asas (iaitu, mempunyai panjang dan lebar konteks yang sama). Atas dasar ini, saluran input dan output ditambah untuk menjana sampel dalam ruang dimensi yang lebih tinggi.
Hasil eksperimen
Penilaian pengekod
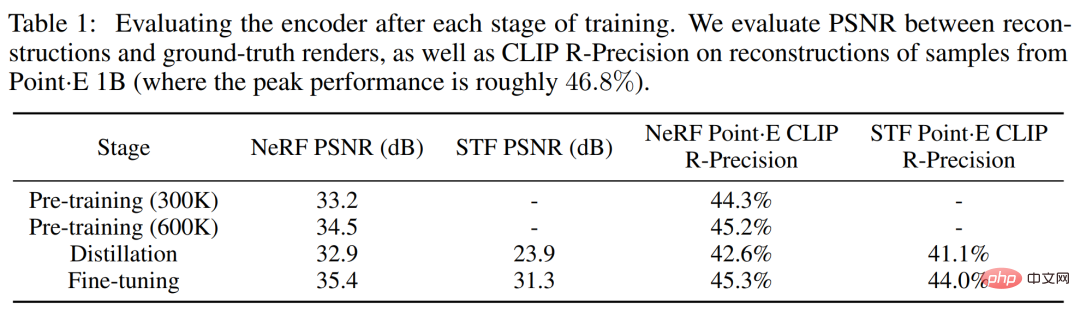
Penyelidik sepanjang keseluruhan proses latihan pengekod Menjejaki dua pemaparan -metrik berasaskan. Mula-mula nilai nisbah isyarat-kepada-bunyi puncak (PSNR) antara imej yang dibina semula dan imej yang diberikan sebenar. Selain itu, untuk mengukur keupayaan pengekod untuk menangkap butiran yang berkaitan secara semantik bagi aset 3D, CLIP R-Precision untuk pemaparan NeRF dan STF yang dibina semula telah dinilai semula dengan mengekodkan mesh yang dihasilkan oleh model Point·E terbesar.
Jadual 1 di bawah menjejaki keputusan kedua-dua metrik ini pada peringkat latihan yang berbeza. Ia boleh didapati bahawa penyulingan memudaratkan kualiti pembinaan semula NeRF, manakala penalaan halus bukan sahaja memulihkan tetapi meningkatkan sedikit kualiti NeRF sambil meningkatkan kualiti pemaparan STF dengan ketara.
Kajian Perbandingan pada Point・E
Model resapan terpendam yang dicadangkan oleh pengarang mempunyai seni bina, set data latihan dan corak bersyarat yang sama seperti Point·E. Perbandingan dengan Point·E lebih berguna dalam membezakan kesan penjanaan perwakilan saraf tersirat dan bukannya perwakilan eksplisit. Rajah 4 di bawah membandingkan kaedah ini pada metrik penilaian berasaskan sampel.
Sampel kualitatif ditunjukkan dalam Rajah 5 di bawah, dan anda boleh melihat bahawa model ini sering menghasilkan sampel kualiti yang berbeza-beza untuk gesaan teks yang sama. Sebelum tamat latihan, keadaan teks Shap·E mula menjadi lebih teruk dalam penilaian. 
Para penyelidik mendapati bahawa Shap・E dan Point・E cenderung untuk berkongsi kes kegagalan yang sama, seperti yang ditunjukkan dalam Rajah 6 (a) di bawah. Ini menunjukkan bahawa data latihan, seni bina model dan imej terkondisi mempunyai kesan yang lebih besar pada sampel yang dijana daripada ruang perwakilan yang dipilih.
Kita boleh perhatikan bahawa masih terdapat beberapa perbezaan kualitatif antara kedua-dua model keadaan imej, contohnya dalam baris pertama Rajah 6(b) di bawah, Point·E mengabaikan bangku kecil jurang, dan Shap・E cuba memodelkannya. Artikel ini membuat hipotesis bahawa percanggahan tertentu ini berlaku kerana awan titik tidak mewakili ciri nipis atau jurang dengan baik. Juga diperhatikan dalam Jadual 1 ialah pengekod 3D mengurangkan sedikit CLIP R-Precision apabila digunakan pada sampel Point·E.

Perbandingan dengan kaedah lain
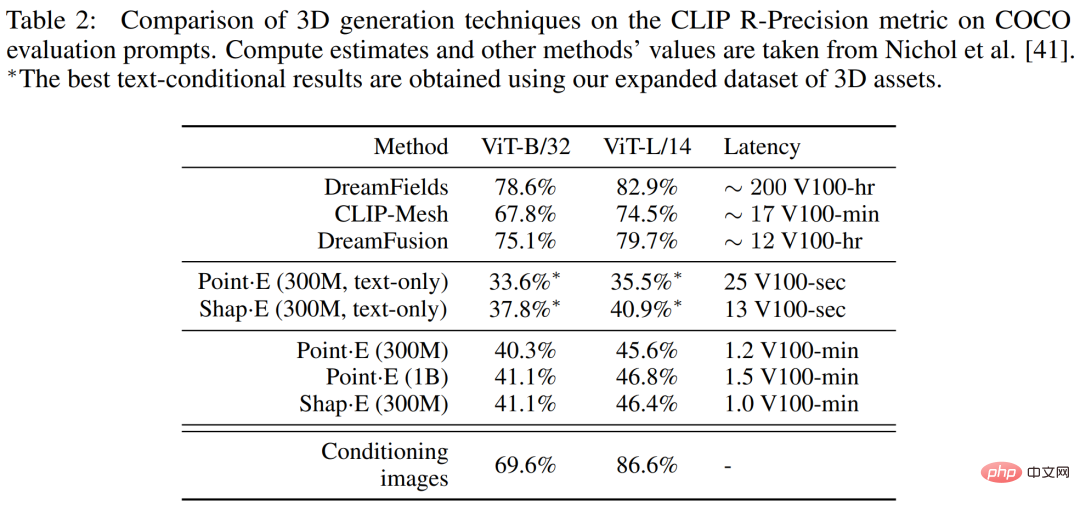
Dalam Jadual 2 di bawah, penyelidik membandingkan bentuk・E kepada julat yang lebih luas teknik penjanaan 3D pada metrik CLIP R-Precision.
Limitan dan Prospek
Walaupun Shap-E boleh memahami banyak A objek tunggal gesaan untuk sifat mudah, tetapi ia terhad dalam keupayaannya untuk menggabungkan konsep. Seperti yang anda lihat dalam Rajah 7 di bawah, model ini menyukarkan untuk mengikat berbilang sifat kepada objek yang berbeza dan tidak menjana bilangan objek yang betul dengan cekap apabila lebih daripada dua objek diminta. Ini mungkin disebabkan oleh data latihan berpasangan yang tidak mencukupi dan mungkin ditangani dengan mengumpul atau menjana set data 3D beranotasi yang lebih besar. 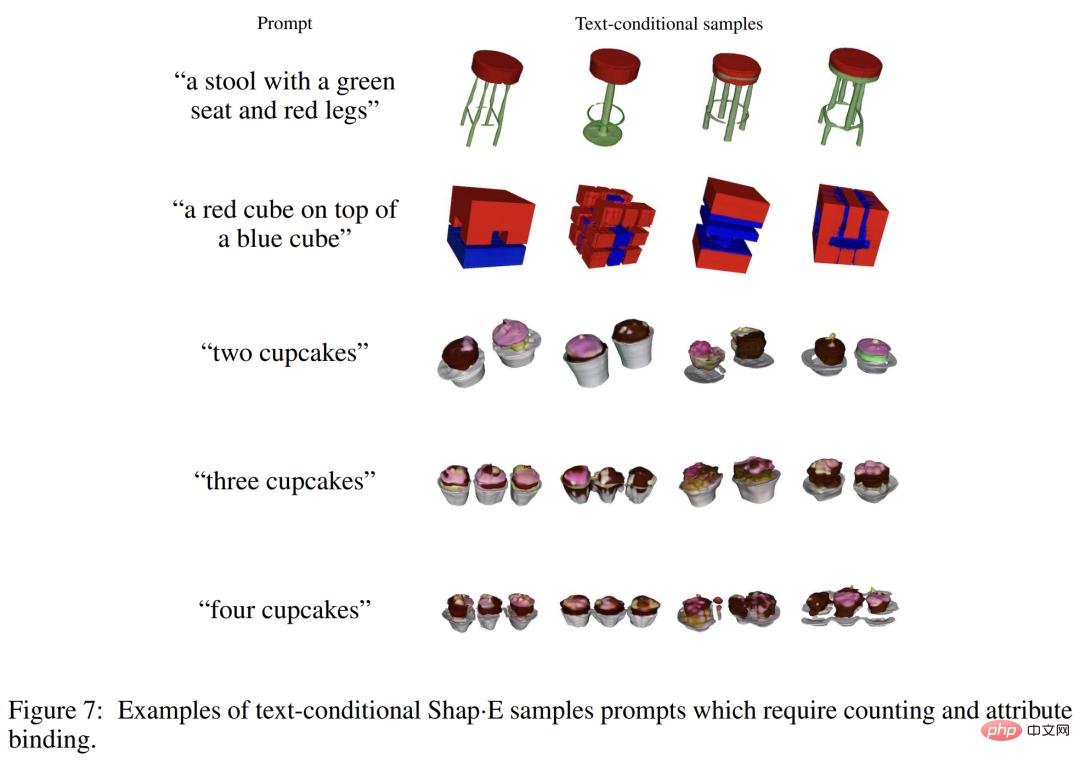
Selain itu, Shap・E menghasilkan aset 3D yang boleh dikenali, tetapi ini selalunya kelihatan kasar atau kurang terperinci. Rajah 3 di bawah menunjukkan bahawa pengekod kadangkala kehilangan tekstur terperinci (seperti jalur pada kaktus), menunjukkan bahawa pengekod yang dipertingkatkan mungkin memulihkan beberapa kualiti penjanaan yang hilang.

Sila rujuk kertas asal untuk butiran lanjut teknikal dan eksperimen.
Atas ialah kandungan terperinci Model 3D penjanaan teks OpenAI telah dinaik taraf untuk melengkapkan pemodelan dalam beberapa saat, yang lebih boleh digunakan daripada Point·E. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI