
Rumah >Peranti teknologi >AI >Memikirkan perspektif baharu, rangka kerja asas kod NeRF bersatu telah menjadi sumber terbuka
Memikirkan perspektif baharu, rangka kerja asas kod NeRF bersatu telah menjadi sumber terbuka

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-15 20:58:041197semak imbas
Andaikan anda melihat beberapa foto sesuatu objek, bolehkah anda bayangkan bagaimana ia kelihatan dari sudut lain? Orang ramai boleh melakukannya. Malah, model itu mempunyai cara untuk melakukan ini. Memandangkan beberapa gambar tempat kejadian, ia juga boleh memerah otak imej dari sudut yang tidak kelihatan.
Memberikan daripada perspektif baharu, yang paling menarik perhatian baru-baru ini ialah NeRF (Neural Radiance Field), sebutan yang mulia untuk kertas terbaik dalam ECCV 2020. Ia tidak memerlukan rumit sebelumnya proses pembinaan semula tiga dimensi, hanya Ia mengambil hanya beberapa foto dan kedudukan kamera apabila foto diambil untuk mensintesis imej dari perspektif baharu. Kesan menakjubkan NeRF menarik ramai penyelidik visual, dan satu siri karya cemerlang telah dihasilkan.
Tetapi kesukarannya ialah model sedemikian kompleks untuk dibina, dan pada masa ini tiada rangka kerja asas kod bersatu untuk melaksanakannya, yang sudah pasti akan menghalang penerokaan dan pembangunan lanjut dalam bidang ini. Untuk tujuan ini, platform penjanaan OpenXRLab telah membina perpustakaan algoritma XRNeRF yang sangat modular untuk membantu merealisasikan pembinaan, latihan dan inferens model seperti NeRF dengan cepat.
Alamat sumber terbuka: https://github.com/openxrlab/xrnerf
Apakah model kelas NeRF?
Tugas kelas NeRF secara amnya merujuk kepada menangkap maklumat pemandangan daripada perspektif yang diketahui, termasuk imej yang ditangkap, dan parameter dalaman dan luaran yang sepadan dengan setiap imej, dengan itu mensintesis yang baharu Imej dari perspektif. Kita boleh memahami tugas ini dengan sangat jelas dengan bantuan gambar rajah dalam kertas NeRF.
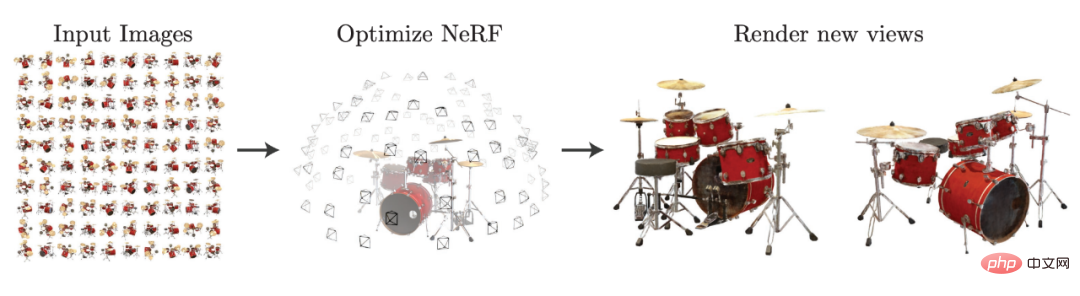
Dipilih daripada arxiv: 2003.08934.
NeRF juga akan mengumpul maklumat pemandangan 5 dimensi semasa mengumpul imej, iaitu satu imej sepadan dengan nilai koordinat tiga dimensi dan dua sudut sinaran cahaya yang lain. Pemandangan sedemikian akan dimodelkan sebagai Medan Radiance melalui perceptron berbilang lapisan, yang bermaksud bahawa perceptron berbilang lapisan akan memasukkan titik koordinat tiga dimensi dan memetakannya kepada warna Ketumpatan dan RGB bagi titik itu, dengan itu menggunakan pemaparan voxel (Volume Rendering) untuk menukar Medan Radiance dipaparkan kepada perspektif maya fotorealistik.
Seperti yang ditunjukkan dalam gambar di atas, selepas membina Medan Radiance melalui beberapa gambar, imej set dram dari perspektif baharu boleh dihasilkan. Oleh kerana NeRF tidak memerlukan pembinaan semula 3D yang eksplisit untuk mendapatkan perspektif baharu yang diingini, ia menyediakan paradigma perwakilan tersirat 3D berdasarkan pembelajaran mendalam, yang boleh melatih adegan 3D menggunakan hanya data imej pose 2D untuk mendapatkan maklumat.
Sejak NeRF, model seperti NeRF telah muncul tanpa henti: Mip-NeRF menggunakan kon dan bukannya sinar untuk mengoptimumkan penjanaan struktur halus KiloNeRF menggunakan beribu-ribu lapisan mikro Perceptron dan bukannya satu perceptron berbilang lapisan yang besar mengurangkan jumlah pengiraan dan mencapai keupayaan pemaparan masa nyata sebagai tambahan, model seperti AniNeRF dan Badan Neural mempelajari transformasi perspektif manusia daripada bingkai video pendek untuk mendapatkan sintesis perspektif yang baik dan kesan pemanduan; GN Model 'R menggunakan imej perspektif yang jarang dan prior geometri untuk mencapai pemaparan manusia yang boleh digeneralisasikan antara ID yang berbeza.

Perwakilan medan tersirat tubuh manusia yang boleh digeneralisasikan yang dicadangkan oleh GN'R merealisasikan kesan rendering badan manusia model tunggal
Meletakkan roda pada NeRF
Walaupun algoritma NeRF semasa sangat popular dalam bidang penyelidikan, ia adalah kaedah yang agak baru, jadi pelaksanaan model mestilah Sedikit lebih menyusahkan. Jika anda menggunakan rangka kerja konvensional seperti PyTorch atau TensorFlow, anda mesti mencari model NeRF yang serupa dahulu dan kemudian mengubah suainya berdasarkannya.
Melakukan ini akan membawa beberapa masalah yang jelas Pertama sekali, kita perlu memahami sepenuhnya sesuatu pelaksanaan sebelum kita boleh mengubahnya kepada apa yang kita mahukan pelaksanaan rasmi kertas yang berbeza tidak bersatu, ia akan menggunakan banyak tenaga apabila membandingkan kod sumber model NeRF yang berbeza Lagipun, tiada siapa yang tahu sama ada terdapat beberapa helah baru dalam proses latihan kertas tertentu; jika tiada Dengan set kod bersatu, sudah pasti ia akan menjadi lebih perlahan untuk mengesahkan idea baharu untuk model baharu.
Untuk menyelesaikan banyak masalah, OpenXRLab membina rangka kerja asas kod XRNeRF yang bersatu dan sangat modular untuk model kelas NeRF.

XRNeRF melaksanakan banyak model NeRF, menjadikannya lebih mudah untuk bermula dan boleh mengeluarkan semula hasil percubaan kertas yang sepadan dengan mudah. XRNeRF membahagikan model ini kepada lima modul: set data, mlp, rangkaian, embedder dan render. Kemudahan penggunaan XRNeRF terletak pada fakta bahawa modul yang berbeza boleh dipasang untuk membentuk model lengkap melalui mekanisme konfigurasi Ia sangat mudah dan mudah digunakan, dan juga meningkatkan kebolehgunaan semula.
Atas dasar memastikan kemudahan penggunaan, fleksibiliti juga diperlukan XRNeRF boleh menyesuaikan ciri khusus atau pelaksanaan modul yang berbeza melalui satu set mekanisme daftar yang lain, sekali gus menjadikan XRNeRF Terdapat lebih banyak. decoupling dan kod lebih mudah difahami.
Selain itu, semua algoritma yang dilaksanakan oleh XRNeRF menggunakan mod Pipeline pada data membaca data asal dan mendapatkan input model selepas satu siri pemprosesan model kemudian Data input diproses dan output yang sepadan diperolehi. Talian Paip sedemikian menghubungkan mekanisme konfigurasi dan mekanisme mesin pendaftaran untuk membentuk seni bina yang lengkap.
XRNeRF melaksanakan banyak model teras NeRF dan mengikatnya bersama-sama melalui tiga mekanisme di atas untuk membina rangka kerja kod yang sangat modular yang mudah digunakan dan fleksibel.
Ciri teras XRNeRF
XRNeRF ialah perpustakaan algoritma kelas NeRF berdasarkan rangka kerja Pytorch Ia telah menghasilkan semula 8 kertas klasik dalam kedua-dua arah adegan dan badan. Berbanding dengan pemodelan langsung, XRNeRF telah meningkatkan kecekapan pembinaan model dengan ketara, kos dan fleksibiliti, dan mempunyai dokumentasi penggunaan yang lengkap, contoh dan mekanisme maklum balas isu Secara ringkasnya, ciri teras XRNeRF mempunyai lima perkara berikut.
1 Melaksanakan banyak algoritma arus perdana dan teras
Sebagai contoh, kerja perintis NeRF, CVPR 2021 Best Calon Kertas (NeuralBody), ICCV 2021 Best Paper Honorable Mention (Mip-NeRF) dan Siggraph 2022 Best Paper (Instant NGP).

Atas dasar melaksanakan model ini, XRNeRF juga boleh memastikan bahawa kesan pembiakan pada asasnya konsisten dengan yang terdapat dalam kertas kerja. Seperti yang ditunjukkan dalam rajah di bawah, berdasarkan objektif PSNR dan penunjuk SSIM, ia boleh menghasilkan semula kesan kod asal dengan baik.
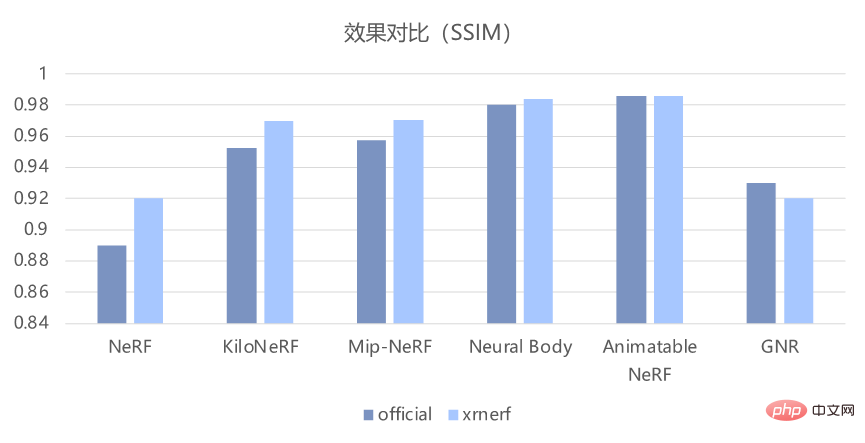
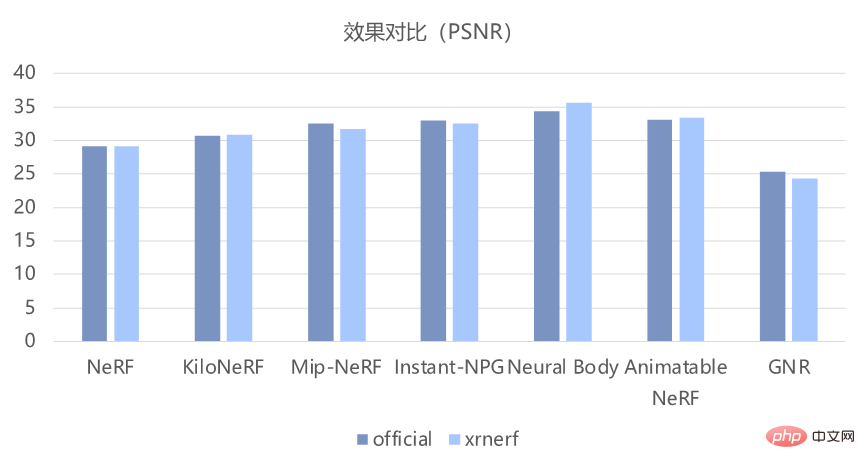
2 Reka bentuk modular
XRNeRF memodulasi keseluruhan rangka kerja kod untuk memaksimumkan kebolehgunaan semula kod dan memudahkan penyelidik membaca dan mengubah suai kod sedia ada. Dengan menganalisis kaedah model kelas NeRF sedia ada, proses modul khusus reka bentuk XRNeRF ditunjukkan dalam rajah di bawah:
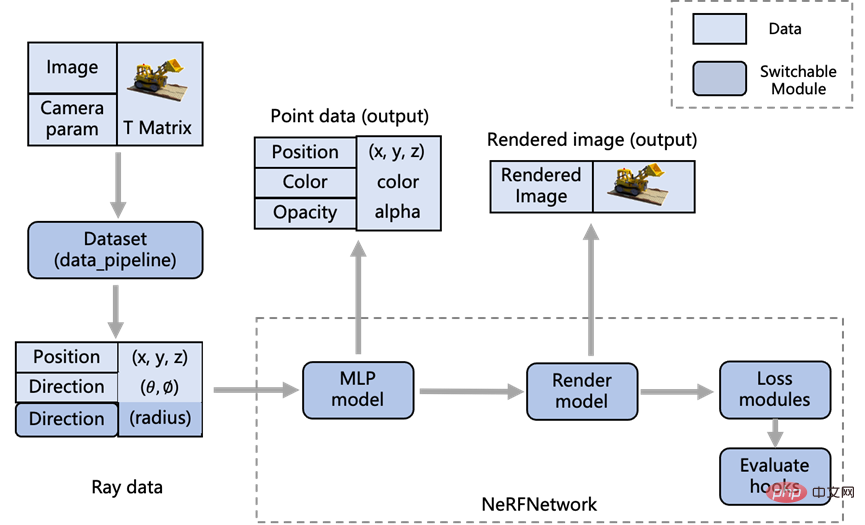
Kelebihan modulariti ialah jika kita perlu mengubah suai format data, kita hanya perlu mengubah suai logik di bawah modul Set Data Jika kita perlu mengubah suai logik rendering imej, kita hanya perlu mengubah suai modul model Render .
3. Saluran paip pemprosesan data standard
Untuk masalah prapemprosesan data yang lebih kompleks dan pelbagai untuk algoritma seperti NeRF, XRNeRF menyediakan set prosedur pemprosesan data Standard. Ia diperoleh secara bersiri daripada berbilang operasi pemprosesan data Anda hanya perlu mengubah suai bahagian saluran paip data dalam fail konfigurasi konfigurasi untuk melengkapkan pembinaan pemprosesan data yang lancar.
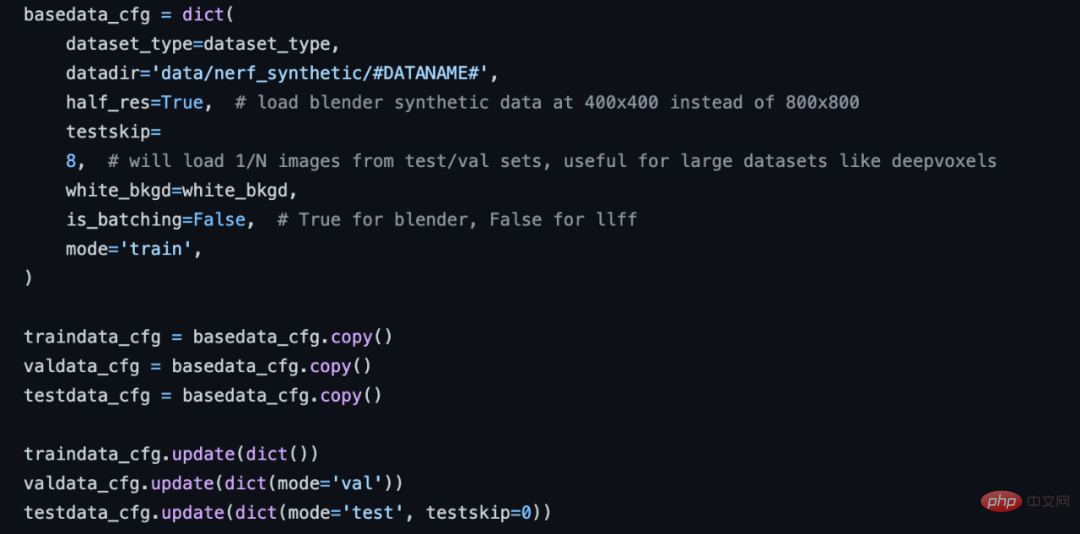
Bahagian aliran data konfigurasi NeRF.
Op pemprosesan data yang diperlukan untuk berbilang set data telah dilaksanakan dalam XRNeRF Anda hanya perlu mentakrifkan ops ini dalam konfigurasi untuk menyelesaikan proses pemprosesan data pembinaan. Jika op baharu perlu ditambah pada masa hadapan, anda hanya perlu melengkapkan pelaksanaan op baharu dalam folder yang sepadan dan satu baris kod boleh ditambahkan pada keseluruhan proses pemprosesan data.
4. Kaedah pembinaan rangkaian modular
Model dalam XRNeRF terutamanya terdiri daripada model embedder, MLP dan render Disusun dan disambungkan melalui rangkaian, ini boleh dipisahkan antara satu sama lain, sekali gus membolehkan penggantian modul berbeza antara algoritma berbeza.
Pembenam memasukkan kedudukan dan perspektif titik dan mengeluarkan data ciri yang dibenamkan sebagai input dan mengeluarkan warna Ketumpatan dan RGB bagi titik pensampelan; ; model render memasukkan output MLP Akibatnya, operasi seperti penyepaduan dilakukan di sepanjang titik pada sinar untuk mendapatkan nilai RGB piksel pada imej. Ketiga-tiga modul ini disambungkan melalui modul rangkaian standard untuk membentuk model yang lengkap.

Sesuaikan struktur kod modul rangkaian.
5. Kesan pembiakan yang baik
Menyokong rangkaian latihan dalam 60 saat terpantas, 30 Real -masa pemaparan bingkai sesaat, menyokong definisi tinggi, anti-aliasing, pemandangan berbilang skala dan pemaparan imej badan manusia. Sama ada melihat kepada penunjuk PSNR dan SSIM objektif atau kesan paparan demo subjektif, XRNeRF boleh menghasilkan semula kesan kod asal dengan baik.
Penggunaan XRNeRF
Rangka kerja XRNeRF nampaknya mempunyai ciri yang sangat baik, dan ia juga sangat mudah dan mudah digunakan. Contohnya, semasa proses pemasangan, XRNeRF bergantung pada banyak persekitaran pembangunan, seperti PyTorch, persekitaran CUDA, perpustakaan pemprosesan visual, dsb. Walau bagaimanapun, XRNeRF menyediakan persekitaran Docker, dan fail imej boleh dibina terus melalui DockerFile.
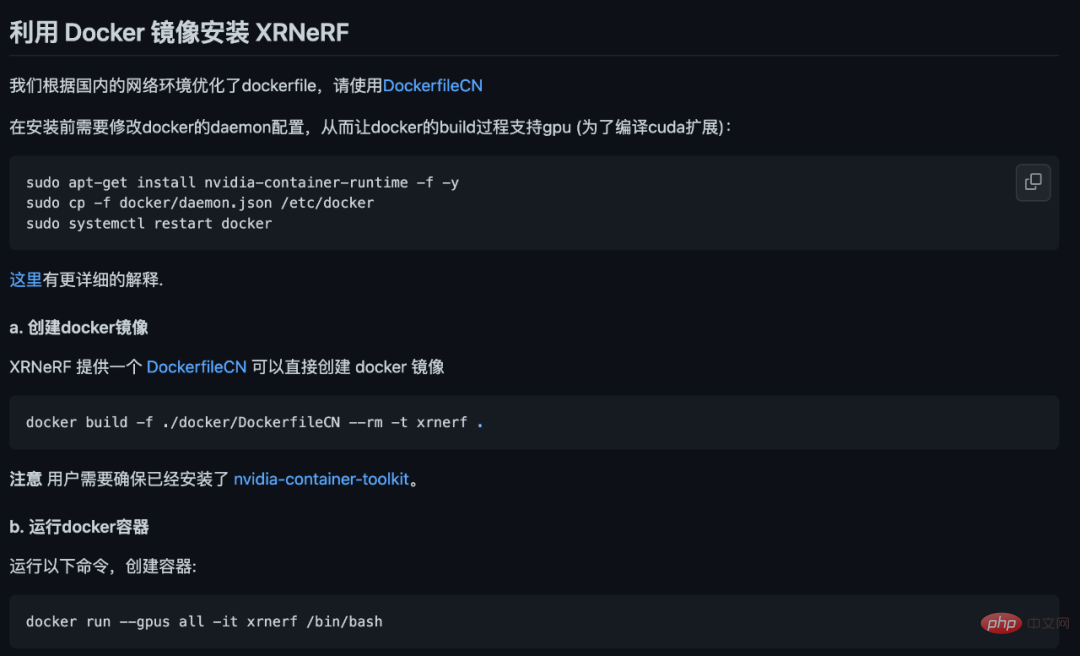
Kami mencubanya Berbanding dengan mengkonfigurasi pelbagai persekitaran operasi dan pakej langkah demi langkah, kaedah konfigurasi hanya arahan satu baris docker build adalah jelas. lebih selesa. Di samping itu, apabila membina imej Docker, alamat imej domestik dikonfigurasikan dalam DockerFile, jadi kelajuannya masih sangat pantas, dan pada dasarnya tidak perlu risau tentang masalah rangkaian.
Selepas membina imej dan memulakan bekas daripada imej, kita boleh memindahkan kod projek dan data ke bekas melalui arahan cp docker. Walau bagaimanapun, anda juga boleh terus memetakan alamat projek ke bahagian dalam bekas melalui parameter -v semasa mencipta bekas. Walau bagaimanapun, perlu diperhatikan di sini bahawa set data perlu diletakkan di lokasi tertentu (jika tidak, fail konfigurasi perlu ditukar), seperti folder data di bawah projek XRNeRF.
Secara umumnya, selepas memuat turun data, struktur folder anggaran adalah seperti yang ditunjukkan di bawah:
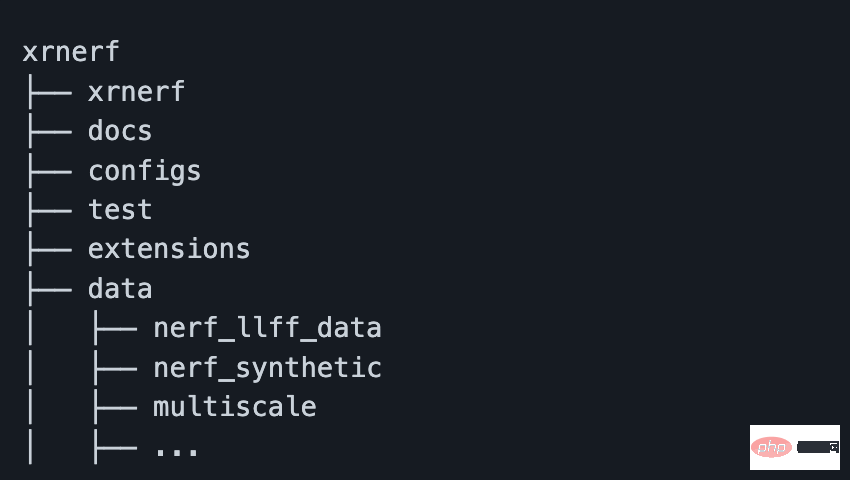
Kini, persekitaran, data dan kod sudah sedia dengan hanya satu baris kod pendek, anda boleh melakukan latihan dan pengesahan model NeFR:
python run_nerf.py --config configs/nerf/nerf_blender_base01.py --dataname lego
Di mana nama data mewakili set data khusus dalam direktori data, dan konfigurasi mewakili fail konfigurasi khusus model. Oleh kerana XRNeRF menggunakan reka bentuk yang sangat modular, konfigurasinya dibina menggunakan kamus Walaupun ia mungkin kelihatan sedikit menyusahkan pada pandangan pertama, selepas benar-benar memahami struktur reka bentuk XRNeRF, ia sangat mudah untuk dibaca.
Secara umum, fail konfigurasi konfigurasi (nerf_blender_base01.py) mengandungi semua maklumat yang diperlukan untuk melatih model, termasuk pengoptimum, strategi teragih, seni bina model, prapemprosesan dan lelaran data, dsb. , malah banyak konfigurasi berkaitan pemprosesan imej disertakan. Ringkasnya, sebagai tambahan kepada pelaksanaan kod khusus, fail konfigurasi konfigurasi menerangkan keseluruhan proses latihan dan inferens.
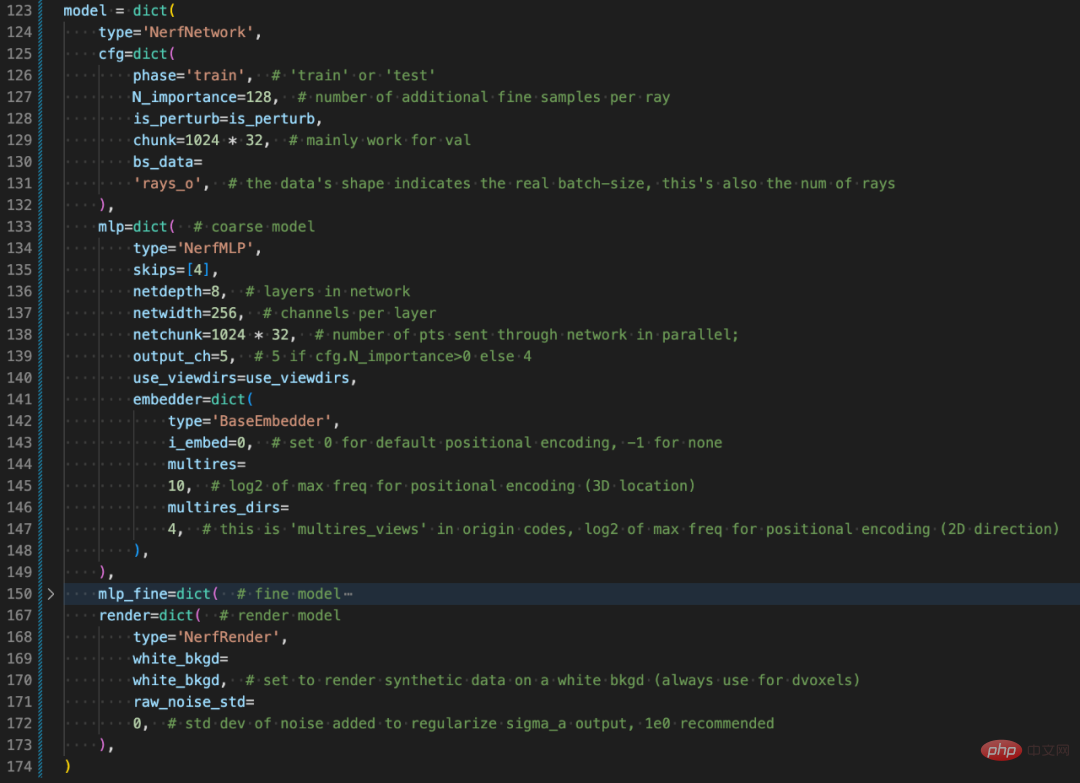
Menerangkan konfigurasi Config bahagian struktur model.
Secara amnya, XRNeRF agak lancar daripada menyediakan persekitaran operasi asas kepada pelaksanaan akhir tugasan latihan. Selain itu, dengan mengkonfigurasi fail konfigurasi atau melaksanakan OP tertentu, anda juga boleh mendapatkan fleksibiliti pemodelan yang sangat tinggi. Berbanding dengan secara langsung menggunakan pemodelan rangka kerja pembelajaran mendalam, XRNeRF sudah pasti akan mengurangkan banyak kerja pembangunan, dan penyelidik atau jurutera algoritma juga boleh menghabiskan lebih banyak masa pada model atau inovasi tugas.
Model kelas NeRF masih menjadi tumpuan penyelidikan dalam bidang penglihatan komputer Pangkalan kod bersatu seperti XRNeRF, seperti perpustakaan Transformer HuggingFace, boleh mengumpulkan lebih banyak penyelidikan yang lebih baik. kerja. Mengumpul lebih banyak kod baharu dan idea baharu. Seterusnya, XRNeRF juga akan mempercepatkan penerokaan penyelidik terhadap model jenis NeRF, menjadikannya lebih mudah untuk menggunakan medan baharu ini pada senario dan tugas baharu, dan potensi NeRF juga akan dipercepatkan.
Atas ialah kandungan terperinci Memikirkan perspektif baharu, rangka kerja asas kod NeRF bersatu telah menjadi sumber terbuka. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI