
Rumah >pembangunan bahagian belakang >Tutorial Python >Bagaimana untuk melaksanakan panggilan berantai dalam Python
Bagaimana untuk melaksanakan panggilan berantai dalam Python

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-15 18:28:062203semak imbas
Mengapa panggilan berantai?
Panggilan berantai, atau rantaian kaedah, secara literal bermaksud kaedah kod yang menggabungkan satu siri operasi atau kaedah fungsi seperti rantai.
Saya mula-mula menyedari "keindahan" panggilan berantai, dan saya mulakan dengan menggunakan operator saluran paip bahasa R.
library(tidyverse) mtcars %>% group_by(cyl) %>% summarise(meanmeanOfdisp = mean(disp)) %>% ggplot(aes(x=as.factor(cyl), y=meanOfdisp, fill=as.factor(seq(1,3))))+ geom_bar(stat = 'identity') + guides(fill=F)
Untuk pengguna R, sekeping kod ini boleh memahami dengan cepat apakah keseluruhan langkah proses. Semuanya bermula dengan simbol %>% (pengendali paip).
Melalui operator paip, kita boleh menghantar benda kiri ke benda seterusnya. Di sini saya menghantar set data mtcars ke fungsi group_by, kemudian menghantar hasilnya kepada fungsi ringkasan, dan akhirnya menghantarnya ke fungsi ggplot untuk lukisan visual.
Sekiranya saya tidak belajar panggilan berantai, maka saya akan menulis seperti ini apabila saya mula-mula belajar bahasa R:
library(tidyverse) cyl4 <p>Jika saya tidak menggunakan operator paip, maka saya akan telah membuat tugasan yang tidak perlu, dan menulis ganti objek data asal, tetapi sebenarnya, cyl# dan data yang dijana di dalamnya sebenarnya hanya digunakan untuk menyampaikan gambar graf, jadi masalahnya ialah kod itu akan menjadi berlebihan. </p><p>Panggilan berantai bukan sahaja memudahkan kod, tetapi juga meningkatkan kebolehbacaan kod Anda boleh memahami dengan cepat apa yang dilakukan oleh setiap langkah. Kaedah ini sangat berguna untuk analisis data atau pemprosesan data Ia mengurangkan penciptaan pembolehubah yang tidak diperlukan dan membolehkan penerokaan dengan cara yang cepat dan mudah. </p><p>Anda boleh melihat panggilan berantai atau operasi saluran paip di banyak tempat Di sini saya akan memberikan dua contoh biasa selain bahasa R. </p><p>Salah satunya ialah pernyataan Shell: </p><pre class="brush:php;toolbar:false">echo "`seq 1 100`" | grep -e "^[3-4].*" | tr "3" "*"
Menggunakan operator paip "|" dalam pernyataan shell boleh melaksanakan panggilan berantai dengan cepat Di sini saya mula-mula mencetak semua integer dari 1-100, dan kemudian Lulus ia ke dalam kaedah grep, ekstrak semua bahagian bermula dengan 3 atau 4, masukkan bahagian ini ke dalam kaedah tr, dan gantikan bahagian nombor yang mengandungi 3 dengan asterisk. Hasilnya adalah seperti berikut:
Yang lain ialah bahasa Scala:
object Test { def main(args: Array[String]): Unit = { val numOfseq = (1 to 100).toList val chain = numOfseq.filter(_%2==0) .map(_*2) .take(10) } }Dalam contoh ini, mula-mula pembolehubah numOfseq mengandungi semua integer dari 1-100, dan kemudian bermula dari bahagian rantai, I pertama Kaedah penapis dipanggil berdasarkan numOfseq untuk menapis nombor genap antara nombor ini Kemudian kaedah peta dipanggil untuk mendarab nombor yang ditapis dengan 2. Akhirnya, kaedah ambil digunakan untuk mengeluarkan 10 nombor pertama daripada. nombor yang baru dibentuk, nombor ini ditugaskan bersama kepada pembolehubah rantai.
Melalui huraian di atas, saya percaya anda boleh mempunyai tanggapan awal tentang panggilan berantai, tetapi sebaik sahaja anda menguasai panggilan berantai, selain menukar gaya pengekodan anda, pemikiran pengaturcaraan anda Terdapat juga peningkatan yang berbeza.
Panggilan berantai dalam Python
Untuk melaksanakan panggilan berantai mudah dalam Python ialah membina kaedah kelas dan mengembalikan objek itu sendiri atau mengembalikan kelas yang dikaitkan (@classmethod )
class Chain: def __init__(self, name): self.name = name def introduce(self): print("hello, my name is %s" % self.name) return self def talk(self): print("Can we make a friend?") return self def greet(self): print("Hey! How are you?") return self if __name__ == '__main__': chain = Chain(name = "jobs") chain.introduce() print("-"*20) chain.introduce().talk() print("-"*20) chain.introduce().talk().greet()Di sini kita mencipta kelas Rantaian dan perlu menghantar parameter rentetan nama untuk mencipta objek contoh; terdapat tiga kaedah dalam kelas ini, iaitu memperkenalkan, bercakap dan memberi salam.
Memandangkan diri dikembalikan setiap kali, kita boleh terus memanggil kaedah dalam kelas milik objek hasilnya adalah seperti berikut:
hello, my name is jobs -------------------- hello, my name is jobs Can we make a friend? -------------------- hello, my name is jobs Can we make a friend? Hey! How are you?
Gunakan panggilan berantai dalam Pandas
Selepas begitu banyak persediaan, akhirnya kami bercakap tentang bahagian panggilan berantai dari PandasKebanyakan kaedah dalam Panda sesuai untuk operasi menggunakan kaedah rantai kerana ia diproses oleh API Apa yang dipulangkan selalunya Siri taip atau jenis DataFrame, jadi kita boleh terus memanggil kaedah yang sepadan Di sini saya mengambil data video stesen Huanong Brothers B yang saya merangkak semasa saya melakukan demonstrasi kes untuk orang lain sekitar Februari tahun ini sebagai contoh. Ia boleh didapati melalui pautan. Maklumat medan data adalah seperti berikut, terdapat 300 keping data dan 20 medan: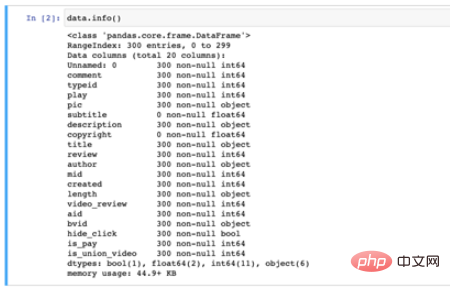
- bantuan: nombor AV yang sepadan dengan. video
- ulasan: bilangan ulasan
- main: kelantangan main
- tajuk: tajuk
- video_review: Bilangan ulasan
- dibuat: Tarikh muat naik
- panjang: Tempoh video
1. Pembersihan data
Nilai yang sepadan bagi setiap medan adalah seperti berikut: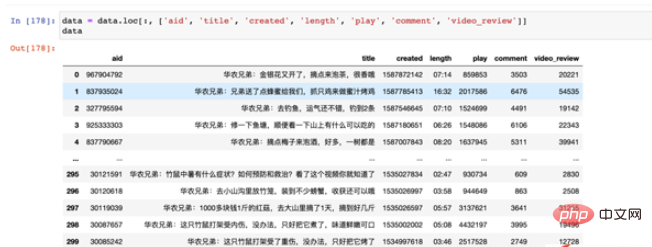
- Medan tajuk akan didahului dengan empat perkataan "Huanong Brothers". dalam tajuk dikira, ia perlu dialih keluar terlebih dahulu; masa kini. Kita perlu memprosesnya menjadi format tahun, bulan dan hari yang boleh dibaca;
length 播放量长度只显示了分秒,但是小时并未用「00」来进行补全,因此这里我们一方面需要将其补全,另一方面要将其转换成对应的时间格式
链式调用操作如下:
import re import pandas as pd # 定义字数统计函数 def word_count(text): return len(re.findall(r"[\u4e00-\u9fa5]", text)) tidy_data = ( pd.read_csv('~/Desktop/huanong.csv') .loc[:, ['aid', 'title', 'created', 'length', 'play', 'comment', 'video_review']] .assign(title = lambda df: df['title'].str.replace("华农兄弟:", ""), title_count = lambda df: df['title'].apply(word_count), created = lambda df: df['created'].pipe(pd.to_datetime, unit='s'), created_date = lambda df: df['created'].dt.date, length = lambda df: "00:" + df['length'], video_length = lambda df: df['length'].pipe(pd.to_timedelta).dt.seconds ) )
这里首先是通过loc方法挑出其中的列,然后调用assign方法来创建新的字段,新的字段其字段名如果和原来的字段相一致,那么就会进行覆盖,从assign中我们可以很清楚地看到当中字段的产生过程,同lambda 表达式进行交互:
1.title 和title_count:
原有的title字段因为属于字符串类型,可以直接很方便的调用str.* 方法来进行处理,这里我就直接调用当中的replace方法将「华农兄弟:」字符进行清洗
基于清洗好的title 字段,再对该字段使用apply方法,该方法传递我们前面实现定义好的字数统计的函数,对每一条记录的标题中,对属于\u4e00到\u9fa5这一区间内的所有 Unicode 中文字符进行提取,并进行长度计算
2.created和created_date:
对原有的created 字段调用一个pipe方法,该方法会将created 字段传递进pd.to_datetime 参数中,这里需要将unit时间单位设置成s秒才能显示出正确的时间,否则仍以 Unix 时间错的样式显示
基于处理好的created 字段,我们可以通过其属于datetime64 的性质来获取其对应的时间,这里 Pandas 给我们提供了一个很方便的 API 方法,通过dt.*来拿到当中的属性值
3.length 和video_length:
原有的length 字段我们直接让字符串00:和该字段进行直接拼接,用以做下一步转换
基于完整的length时间字符串,我们再次调用pipe方法将该字段作为参数隐式传递到pd.to_timedelta方法中转化,然后同理和create_date字段一样获取到相应的属性值,这里我取的是秒数。
2、播放量趋势图
基于前面稍作清洗后得到的tidy_data数据,我们可以快速地做一个播放量走势的探索。这里我们需要用到created这个属于datetime64的字段为 X 轴,播放量play 字段为 Y 轴做可视化展示。
# 播放量走势 %matplotlib inline %config InlineBackend.figure_format = 'retina' import matplotlib.pyplot as plt (tidy_data[['created', 'play']] .set_index('created') .resample('1M') .sum() .plot( kind='line', figsize=(16, 8), title='Video Play Prend(2018-2020)', grid=True, legend=False ) ) plt.xlabel("") plt.ylabel('The Number Of Playing')
这里我们将上传日期和播放量两个选出来后,需要先将created设定为索引,才能接着使用resample重采样的方法进行聚合操作,这里我们以月为统计颗粒度,对每个月播放量进行加总,之后再调用plot 接口实现可视化。
链式调用的一个小技巧就是,可以利用括号作用域连续的特性使整个链式调用的操作不会报错,当然如果不喜欢这种方式也可以手动在每条操作后面追加一个\符号,所以上面的整个操作就会变成这样:
tidy_data[['created', 'play']] \ .set_index('created') \ .resample('1M') .sum() .plot( \ kind='line', \ figsize=(16, 8), \ title='Video Play Prend(2018-2020)', \ grid=True, \ legend=False \ )
但是相比于追加一对括号来说,这种尾部追加\符号的方式并不推荐,也不优雅。
但是如果既没有在括号作用域或未追加\ 符号,那么在运行时 Python 解释器就会报错。
3、链式调用性能
通过前两个案例我们可以看出链式调用可以说是比较优雅且快速地能实现一套数据操作的流程,但是链式调用也会因为不同的写法而存在性能上的差异。
这里我们继续基于前面的tidy_data操作,这里我们基于created_date 来对play、comment和video_review进行求和后的数值进一步以 10 为底作对数化。最后需要得到以下结果:
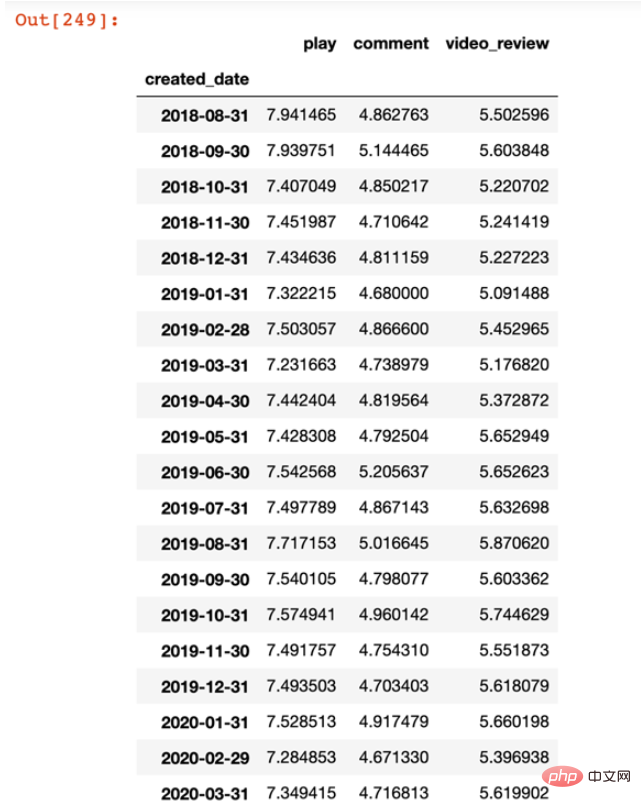
统计表格
写法一:一般写法
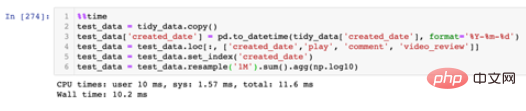
一般写法
这种写法就是基于tidy_data拷贝后进行操作,操作得到的结果会不断地覆盖原有的数据对象
写法二:链式调用写法
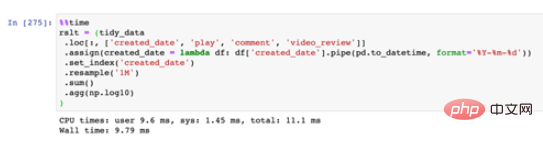
链式调用写法
可以看到,链式调用的写法相比于一般写法而言会快上一点,不过由于数据量比较小,因此二者时间的差异并不大;但链式调用由于不需要额外的中间变量已经覆盖写入步骤,在内存开销上会少一些。
结尾:链式调用的优劣
从本文的只言片语中,你能领略到链式调用使得代码在可读性上大大的增强,同时以尽肯能少的代码量去实现更多操作。
当然,链式调用并不算是完美的,它也存在着一定缺陷。比如说当链式调用的方法超过 10 步以上时,那么出错的几率就会大幅度提高,从而造成调试或 Debug 的困难。比如这样:
(data .method1(...) .method2(...) .method3(...) .method4(...) .method5(...) .method6(...) .method7(...) # Something Error .method8(...) .method9(...) .method10(...) .method11(...) )
Atas ialah kandungan terperinci Bagaimana untuk melaksanakan panggilan berantai dalam Python. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!