
Rumah >Java >javaTutorial >Cara menggunakan Java untuk merangkak komik
Cara menggunakan Java untuk merangkak komik

- 王林ke hadapan
- 2023-05-13 23:10:191561semak imbas
Hasil merangkak
Kesan berjalan program
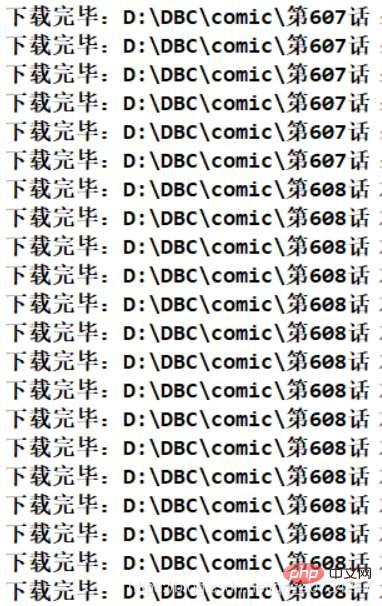
Maklumat direktori fail diperoleh
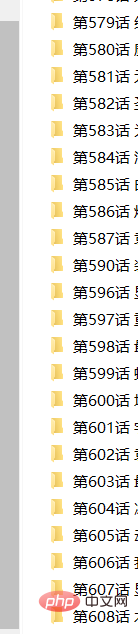
Jumlah maklumat fail

Nota : Terdapat masalah kecil di sini Beberapa fail yang diperoleh mungkin tidak mempunyai nama akhiran, tetapi ia boleh dibuka dan dilihat sebagai gambar Saya tidak tahu sebab khusus, dan kerana ia tidak menjejaskannya tidak akan mengambil berat tentangnya. (Atau gunakan kod anda sendiri untuk menamakan semula fail.)
Analisis struktur tapak web
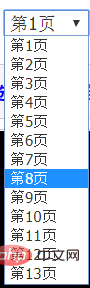
Berikut ialah komik sebagai contoh Pertama, lihat nombor di atas muka surat komik. Ini sangat penting, terdapat jadual kandungan komik di halaman ini. Kemudian klik pada bab dalam direktori satu persatu untuk melihat maklumat komik setiap bab.


Paging di sini sangat pelik, kerana bilangan muka surat dalam setiap bab tidak sama, tetapi ia memang boleh dipilih secara langsung , Ini bermakna bahawa ini harus dimuatkan terlebih dahulu atau secara tidak segerak (saya sebenarnya tidak tahu apa-apa tentang front-end, saya baru mendengarnya.) Kemudian, dengan menyemak sumbernya (Saya menemuinya dengan mata saya), saya dapati semua komik memang dimuatkan lebih awal. Ia tidak dimuatkan secara tak segerak.
Di sini saya klik pada imej komik untuk mendapatkan alamat imej, kemudian membandingkannya dengan pautan yang saya jumpa, dan kemudian saya boleh melihatnya.
Dalam halaman bab yang sepadan, gunakan sumber paparan penyemak imbas untuk mencari skrip sedemikian. Selepas analisis, maklumat dalam tatasusunan dalam skrip ialah maklumat yang sepadan bagi setiap halaman komik.

Tangkapan skrin di atas ialah maklumat struktur kasar, jadi proses pemerolehan ialah: Halaman jadual kandungan–>Halaman Bab–>Halaman komik
Untuk di sini, dapatkan skrip ini sebagai rentetan, kemudian gunakan "[" dan "]" untuk mendapatkan rentetan, dan kemudian gunakan fastjson untuk menukarnya menjadi koleksi Senarai.
// 获取的script 无法直接解析,必须先将 page url 取出来,
// 这里以 [ ] 为界限,分割字符串。
String pageUrls = script.data();
int start = pageUrls.indexOf("[");
int end = pageUrls.indexOf("]") + 1;
String urls = pageUrls.substring(start, end);
//json 转 集合,这个可以总结一下,不熟悉。
List<String> urlList = JSONArray.parseArray(urls, String.class);Saya menekankan satu perkara di sini: kaedah teks objek Elemen adalah untuk mendapatkan maklumat yang boleh dilihat, manakala kaedah data adalah untuk mendapatkan maklumat yang tidak kelihatan. Maklumat skrip tidak dapat dilihat secara langsung, jadi saya menggunakan kaedah data untuk mendapatkannya. Apa yang dipanggil kelihatan dan tidak kelihatan merujuk kepada maklumat yang boleh dipaparkan pada halaman web dan boleh diperolehi dengan melihat sumbernya. Contohnya, aksara melarikan diri menjadi aksara melarikan diri apabila diperolehi melalui samb teks.
Bahagian kod
kelas HttpClientUtil
Gunakan kumpulan sambungan HttpClient untuk menguruskan sambungan, tetapi saya tidak menggunakan berbilang benang kerana saya hanya mempunyai satu alamat IP disekat, Sangat menyusahkan. Masa thread masih boleh diterima Lagipun, komik hanya bertahan kira-kira sepuluh minit. (Ambil Bab 600 sebagai contoh)
package com.comic;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.impl.conn.PoolingHttpClientConnectionManager;
public class HttpClientUtil {
private static final int TIME_OUT = 10 * 1000;
private static PoolingHttpClientConnectionManager pcm; //HttpClient 连接池管理类
private static RequestConfig requestConfig;
static {
requestConfig = RequestConfig.custom()
.setConnectionRequestTimeout(TIME_OUT)
.setConnectTimeout(TIME_OUT)
.setSocketTimeout(TIME_OUT).build();
pcm = new PoolingHttpClientConnectionManager();
pcm.setMaxTotal(50);
pcm.setDefaultMaxPerRoute(10); //这里可能用不到这个东西。
}
public static CloseableHttpClient getHttpClient() {
return HttpClients.custom()
.setConnectionManager(pcm)
.setDefaultRequestConfig(requestConfig)
.build();
}
}Kelas ComicSpider
Kelas yang paling penting, digunakan untuk menghuraikan halaman HTML untuk mendapatkan data pautan. Nota: DIR_PATH di sini ialah laluan berkod keras, jadi jika anda ingin menguji, sila buat sendiri direktori yang berkaitan.
package com.comic;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.util.List;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.stream.Collectors;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.config.CookieSpecs;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import com.alibaba.fastjson.JSONArray;
public class ComicSpider {
private static final String DIR_PATH = "D:/DBC/comic/";
private String url;
private String root;
private CloseableHttpClient httpClient;
public ComicSpider(String url, String root) {
this.url = url;
// 这里不做非空校验,或者使用下面这个。
// Objects.requireNonNull(root);
if (root.charAt(root.length()-1) == '/') {
root = root.substring(0, root.length()-1);
}
this.root = root;
this.httpClient = HttpClients.createDefault();
}
public void start() {
try {
String html = this.getHtml(url); //获取漫画主页数据
List<Chapter> chapterList = this.mapChapters(html); //解析数据,得到各话的地址
this.download(chapterList); //依次下载各话。
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 从url中获取原始的网页数据
* @throws IOException
* @throws ClientProtocolException
* */
private String getHtml(String url) throws ClientProtocolException, IOException {
HttpGet get = new HttpGet(url);
//下面这两句,是因为总是报一个 Invalid cookie header,然后我在网上找到的解决方法。(去掉的话,不影响使用)。
RequestConfig defaultConfig = RequestConfig.custom().setCookieSpec(CookieSpecs.STANDARD).build();
get.setConfig(defaultConfig);
//因为是初学,而且我这里只是请求一次数据即可,这里就简单设置一下 UA
get.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3100.0 Safari/537.36");
HttpEntity entity = null;
String html = null;
try (CloseableHttpResponse response = httpClient.execute(get)) {
int statusCode = response.getStatusLine().getStatusCode();
if (statusCode == 200) {
entity = response.getEntity();
if (entity != null) {
html = EntityUtils.toString(entity, "UTF-8");
}
}
}
return html;
}
//获取章节名 链接地址
private List<Chapter> mapChapters(String html) {
Document doc = Jsoup.parse(html, "UTF-8");
Elements name_urls = doc.select("#chapter-list-1 > li > a");
/* 不采用直接返回map的方式,封装一下。
return name_urls.stream()
.collect(Collectors.toMap(Element::text,
name_url->root+name_url.attr("href")));
*/
return name_urls.stream()
.map(name_url->new Chapter(name_url.text(),
root+name_url.attr("href")))
.collect(Collectors.toList());
}
/**
* 依次下载对应的章节
* 我使用当线程来下载,这种网站,多线程一般容易引起一些问题。
* 方法说明:
* 使用循环迭代的方法,以 name 创建文件夹,然后依次下载漫画。
* */
public void download(List<Chapter> chapterList) {
chapterList.forEach(chapter->{
//按照章节创建文件夹,每一个章节一个文件夹存放。
File dir = new File(DIR_PATH, chapter.getName());
if (!dir.exists()) {
if (!dir.mkdir()) {
try {
throw new FileNotFoundException("无法创建指定文件夹"+dir);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
//开始按照章节下载
try {
List<ComicPage> urlList = this.getPageUrl(chapter);
urlList.forEach(page->{
SinglePictureDownloader downloader = new SinglePictureDownloader(page, dir.getAbsolutePath());
downloader.download();
});
} catch (IOException e) {
e.printStackTrace();
}
}
});
}
//获取每一个页漫画的位置
private List<ComicPage> getPageUrl(Chapter chapter) throws IOException {
String html = this.getHtml(chapter.getUrl());
Document doc = Jsoup.parse(html, "UTF-8");
Element script = doc.getElementsByTag("script").get(2); //获取第三个脚本的数据
// 获取的script 无法直接解析,必须先将 page url 取出来,
// 这里以 [ ] 为界限,分割字符串。
String pageUrls = script.data();
int start = pageUrls.indexOf("[");
int end = pageUrls.indexOf("]") + 1;
String urls = pageUrls.substring(start, end);
//json 转 集合,这个可以总结一下,不熟悉。
List<String> urlList = JSONArray.parseArray(urls, String.class);
AtomicInteger index=new AtomicInteger(0); //我无法使用索引,这是别人推荐的方式
return urlList.stream() //注意这里拼接的不是 root 路径,而是一个新的路径
.map(url->new ComicPage(index.getAndIncrement(),"https://restp.dongqiniqin.com//"+url))
.collect(Collectors.toList());
}
}Nota: Idea saya di sini ialah semua komik disimpan dalam direktori DIR_PATH. Kemudian setiap bab adalah subdirektori (dinamakan selepas nama bab), dan kemudian komik setiap bab diletakkan dalam direktori, tetapi terdapat masalah di sini. Disebabkan komik itu sebenarnya dibaca helaian demi helai, ada masalah dengan susunan komiknya (lagipun, timbunan komik yang tidak teratur kelihatan sangat payah, walaupun saya di sini bukan untuk membaca komik). Jadi saya berikan setiap muka surat komik nombor dan nomborkannya mengikut susunan dalam skrip di atas. Tetapi kerana saya menggunakan ungkapan Lambda Java8, saya tidak boleh menggunakan indeks. (Ini melibatkan isu lain). Penyelesaian di sini ialah apa yang saya lihat disyorkan oleh orang lain: anda boleh meningkatkan nilai indeks setiap kali anda memanggil kaedah getAndIncrement indeks, yang sangat mudah.
AtomicInteger index=new AtomicInteger(0); //我无法使用索引,这是别人推荐的方式 return urlList.stream() //注意这里拼接的不是 root 路径,而是一个新的路径 .map(url->new ComicPage(index.getAndIncrement(),"https://restp.dongqiniqin.com//"+url)) .collect(Collectors.toList());
kelas Bab dan ComicPage
Dua kelas entiti, kerana ia berorientasikan objek, saya mereka bentuk dua kelas entiti mudah untuk merangkum maklumat, yang menjadikan operasi lebih mudah.
Kelas Bab mewakili maklumat setiap bab dalam direktori, nama bab dan pautan ke bab. Kelas ComicPage mewakili setiap halaman maklumat komik dalam setiap bab, nombor dan alamat pautan setiap halaman.
package com.comic;
public class Chapter {
private String name; //章节名
private String url; //对应章节的链接
public Chapter(String name, String url) {
this.name = name;
this.url = url;
}
public String getName() {
return name;
}
public String getUrl() {
return url;
}
@Override
public String toString() {
return "Chapter [name=" + name + ", url=" + url + "]";
}
}package com.comic;
public class ComicPage {
private int number; //每一页的序号
private String url; //每一页的链接
public ComicPage(int number, String url) {
this.number = number;
this.url = url;
}
public int getNumber() {
return number;
}
public String getUrl() {
return url;
}
}SinglePictureDownloader 类
因为前几天使用多线程下载类爬取图片,发现速度太快了,ip 好像被封了,所以就又写了一个当线程的下载类。 它的逻辑很简单,主要是获取对应的漫画页链接,然后使用get请求,将它保存到对应的文件夹中。(它的功能大概和获取网络中的一张图片类似,既然你可以获取一张,那么成千上百也没有问题了。)
package com.comic;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.util.Random;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.util.EntityUtils;
import com.m3u8.HttpClientUtil;
public class SinglePictureDownloader {
private CloseableHttpClient httpClient;
private ComicPage page;
private String filePath;
private String[] headers = {
"Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14",
"Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Win64; x64; Trident/6.0)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11",
"Opera/9.25 (Windows NT 5.1; U; en)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12",
"Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9",
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 "
};
public SinglePictureDownloader(ComicPage page, String filePath) {
this.httpClient = HttpClientUtil.getHttpClient();
this.page = page;
this.filePath = filePath;
}
public void download() {
HttpGet get = new HttpGet(page.getUrl());
String url = page.getUrl();
//取文件的扩展名
String prefix = url.substring(url.lastIndexOf("."));
Random rand = new Random();
//设置请求头
get.setHeader("User-Agent", headers[rand.nextInt(headers.length)]);
HttpEntity entity = null;
try (CloseableHttpResponse response = httpClient.execute(get)) {
int statusCode = response.getStatusLine().getStatusCode();
if (statusCode == 200) {
entity = response.getEntity();
if (entity != null) {
File picFile = new File(filePath, page.getNumber()+prefix);
try (OutputStream out = new BufferedOutputStream(new FileOutputStream(picFile))) {
entity.writeTo(out);
System.out.println("下载完毕:" + picFile.getAbsolutePath());
}
}
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
//关闭实体,关于 httpClient 的关闭资源,有点不太了解。
EntityUtils.consume(entity);
} catch (IOException e) {
e.printStackTrace();
}
}
}
}Main 类
package com.comic;
public class Main {
public static void main(String[] args) {
String root = "https://www.manhuaniu.com/"; //网站根路径,用于拼接字符串
String url = "https://www.manhuaniu.com/manhua/5830/"; //第一张第一页的url
ComicSpider spider = new ComicSpider(url, root);
spider.start();
}
}Atas ialah kandungan terperinci Cara menggunakan Java untuk merangkak komik. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Mengapakah Operator Modulus Java Menghasilkan Keputusan Negatif untuk Nombor Negatif?
- Bagaimana untuk menetapkan margin untuk butang di dalam LinearLayout secara pemrograman?
- Mengapa dan Bagaimana Anda Harus Menyegerakkan pada Objek Rentetan di Jawa?
- Mengapa Menggunakan StringBuilder Apabila String Mempunyai Kaedah Tambah?
- Bagaimana untuk Mengakses dan Mengekstrak Nilai daripada JSONArray Bersarang di Java?