
Rumah >Peranti teknologi >AI >Selesaikan sepenuhnya ChatGPT amnesia! Menembusi had input Transformer: diukur untuk menyokong 2 juta token yang sah
Selesaikan sepenuhnya ChatGPT amnesia! Menembusi had input Transformer: diukur untuk menyokong 2 juta token yang sah

- 王林ke hadapan
- 2023-05-13 14:07:062123semak imbas
ChatGPT, atau model kelas Transformer, mempunyai kecacatan yang membawa maut, iaitu ia terlalu mudah untuk dilupakan Apabila token jujukan input melebihi ambang tetingkap konteks, kandungan output seterusnya tidak akan sepadan dengan logik sebelumnya.
ChatGPT hanya boleh menyokong input 4000 token (kira-kira 3000 perkataan walaupun GPT-4 yang baru dikeluarkan hanya menyokong tetingkap token maksimum 32000. Jika panjang jujukan input terus ditingkatkan, kerumitan pengiraan). juga akan meningkat secara kuadratik.
Baru-baru ini, penyelidik dari DeepPavlov, AIRI, dan London Institute of Mathematical Sciences mengeluarkan laporan teknikal menggunakan Recurrent Memory Transformer (RMT) untuk meningkatkan panjang konteks berkesan BERT kepada "2 juta token yang belum pernah berlaku sebelum ini." ketepatan perolehan ingatan yang tinggi.
Pautan kertas: https://www.php.cn/link/459ad054a6417248a1166b30f6393301
Kaedah ini boleh menyimpan dan memproses maklumat tempatan dan global, serta menggunakan gelung untuk membenarkan maklumat disimpan dalam setiap sebahagian daripada aliran masukan antara segmen.
Bahagian eksperimen menunjukkan keberkesanan pendekatan ini, yang mempunyai potensi luar biasa untuk meningkatkan pemprosesan pergantungan jangka panjang dalam pemahaman bahasa semula jadi dan tugas penjanaan, membolehkan pemprosesan konteks berskala besar untuk aplikasi intensif memori.
Walau bagaimanapun, tiada makan tengah hari percuma di dunia Walaupun RMT tidak meningkatkan penggunaan memori dan boleh dilanjutkan kepada panjang jujukan yang hampir tidak terhad, masih terdapat masalah pereputan ingatan dalam RNN dan masa inferens yang lebih lama diperlukan. .

Tetapi sesetengah netizen telah mencadangkan penyelesaian, RMT digunakan untuk ingatan jangka panjang, konteks besar digunakan untuk ingatan jangka pendek, dan kemudian latihan model dilakukan pada waktu malam. /semasa penyelenggaraan.
Recurrent Memory Transformer
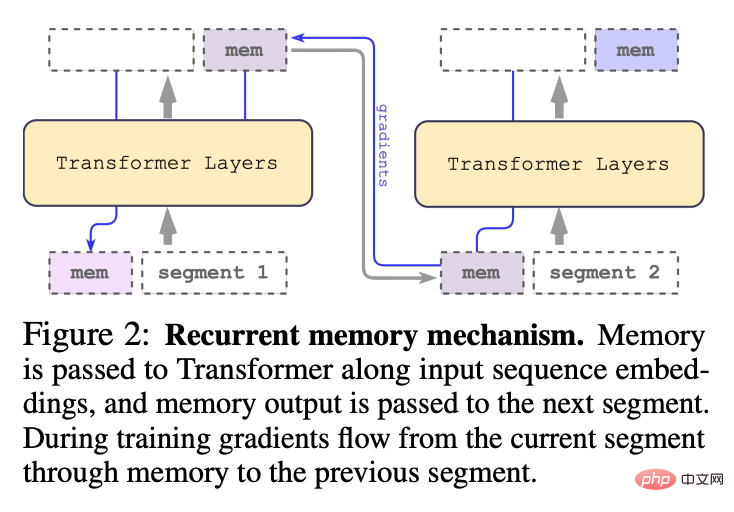
Pada tahun 2022, pasukan mencadangkan model Recurrent Memory Transformer (RMT), dengan menambahkan token memori khas pada urutan input atau output, dan kemudian melatih model untuk mengawal Operasi memori dan pemprosesan perwakilan jujukan boleh melaksanakan mekanisme ingatan baharu tanpa mengubah model Transformer asal.

Pautan kertas: https://arxiv.org/abs/2207.06881
Persidangan penerbitan: NeurIPS 2022
Dengan Transformer-XL Sebagai perbandingan, RMT memerlukan kurang memori dan boleh mengendalikan urutan tugasan yang lebih panjang.
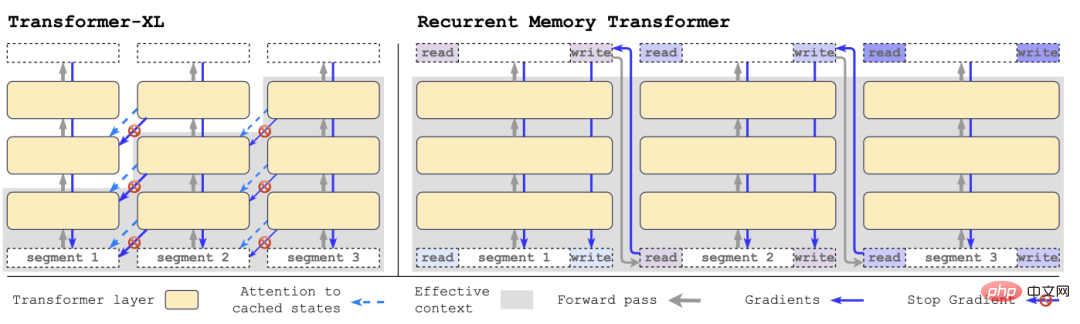
Secara khusus, RMT terdiri daripada m vektor boleh dilatih bernilai sebenar Urutan input yang terlalu panjang dibahagikan kepada beberapa segmen, dan vektor memori dipratetap kepada yang pertama pembenaman segmen dan diproses bersama-sama dengan token segmen.
Berbeza daripada model RMT asal yang dicadangkan pada tahun 2022, untuk model pengekod tulen seperti BERT, memori hanya ditambah sekali pada permulaan model penyahkodan; Ingatan terbahagi kepada dua bahagian: membaca dan menulis.
Dalam setiap langkah dan segmen masa, gelung seperti berikut, dengan N ialah bilangan lapisan Transformer, t ialah langkah masa, dan H ialah segmen
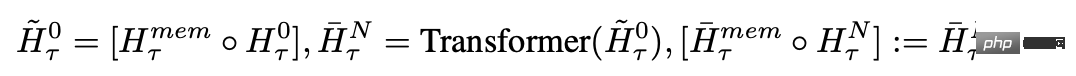
Selepas memproses segmen jujukan input mengikut tertib, untuk mencapai sambungan rekursif, penyelidik menghantar output token memori segmen semasa kepada input segmen seterusnya:
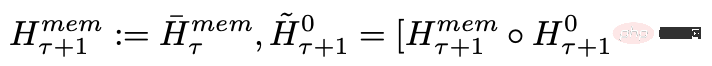
Memori dan gelung dalam RMT hanya berdasarkan token memori global, yang boleh mengekalkan model Transformer tulang belakang tidak berubah, menjadikan keupayaan peningkatan memori RMT serasi dengan mana-mana model Transformer.
Kecekapan pengiraan
Mengikut formula, FLOP yang diperlukan untuk model RMT dan Transformer dengan saiz dan panjang jujukan yang berbeza boleh dianggarkan
Dari segi saiz perbendaharaan kata, bilangan lapisan, saiz tersembunyi, perantaraan Mengenai konfigurasi parameter saiz tersembunyi dan bilangan kepala perhatian, penyelidik mengikuti konfigurasi model OPT dan mengira bilangan FLOP selepas hantaran hadapan, dengan mengambil kira kesan kitaran RMT.
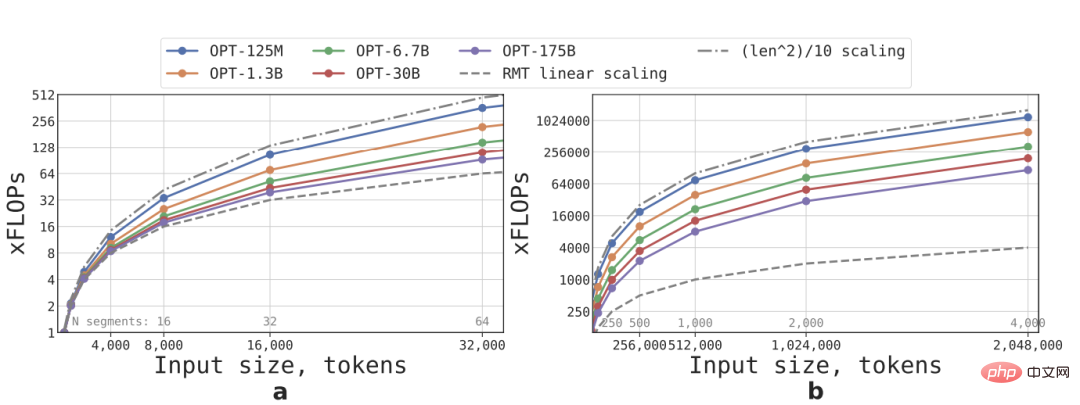
Peluasan linear dicapai dengan membahagikan jujukan input kepada beberapa segmen dan mengira keseluruhan matriks perhatian hanya dalam sempadan segmen tersebut panjang Tetap, kelajuan inferens RMT meningkat secara linear untuk sebarang saiz model.
Disebabkan jumlah pengiraan lapisan FFN yang banyak, model Transformer yang lebih besar cenderung menunjukkan kadar pertumbuhan kuadratik yang lebih perlahan berbanding dengan panjang jujukan Walau bagaimanapun, pada jujukan yang sangat panjang dengan panjang lebih daripada 32,000, FLOP kembali kepada kuadratik. keadaan pertumbuhan.
Untuk jujukan dengan lebih daripada satu segmen (lebih besar daripada 512 dalam kajian ini), RMT mempunyai FLOP yang lebih rendah daripada model asiklik, dan boleh meningkatkan kecekapan FLOP sehingga ×295 kali pada model yang lebih kecil model seperti OPT-175B, ia boleh ditingkatkan sebanyak ×29 kali.
Tugas Ingatan
Untuk menguji kebolehan ingatan, penyelidik membina set data sintetik yang memerlukan model untuk menghafal fakta mudah dan penaakulan asas.
Input tugasan terdiri daripada satu atau beberapa fakta dan soalan yang hanya boleh dijawab dengan semua fakta ini.
Untuk meningkatkan kesukaran tugasan, teks bahasa semula jadi yang tidak berkaitan dengan soalan atau jawapan juga ditambah pada tugasan ini boleh dianggap sebagai bunyi bising, jadi tugas model sebenarnya adalah untuk asingkan fakta daripada teks yang tidak berkaitan dan gunakan teks fakta untuk menjawab soalan.

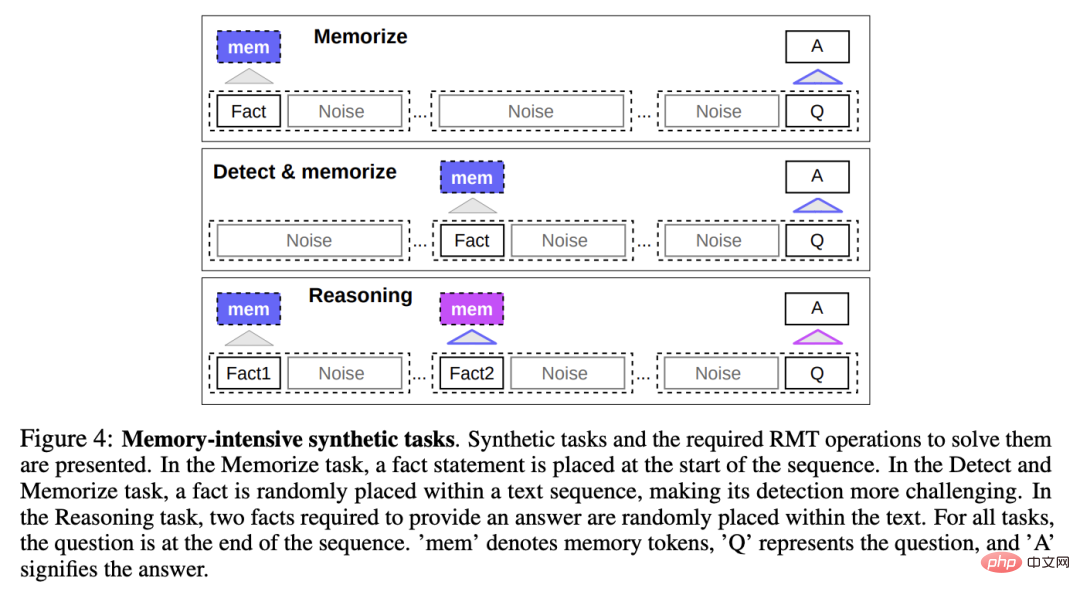
Memori Fakta
Uji penulisan RMT dan simpan maklumat dalam ingatan untuk jangka masa yang lama Kuasa masa: Dalam kes yang paling mudah, fakta berada pada permulaan input, soalan berada di penghujung input, dan secara beransur-ansur meningkatkan jumlah teks yang tidak berkaitan antara soalan dan jawapan sehingga model tidak dapat menerima semua input sekaligus .

Pengesanan fakta dan ingatan
Pengesanan fakta meningkatkan kesukaran tugasan dengan mengalihkan fakta ke kedudukan rawak dalam input, memerlukan The model mula-mula mengasingkan fakta daripada teks yang tidak berkaitan, menulisnya ke dalam ingatan, dan kemudian menjawab soalan di penghujung.
Penaakulan berdasarkan fakta yang dihafal
Satu lagi operasi ingatan yang penting ialah menggunakan fakta yang dihafal dan konteks semasa untuk menaakul.
Untuk menilai ciri ini, penyelidik memperkenalkan tugas yang lebih kompleks di mana dua fakta dijana dan diletakkan secara rawak dalam urutan input, soalan yang ditanya pada akhir urutan mesti dipilih untuk menjawab soalan dengan fakta yang betul.

Hasil eksperimen
Para penyelidik menggunakan model bersarung Bert yang telah terlatih dalam HuggingFace Transformers sebagai tulang belakang RMT dalam semua eksperimen, dan semua model adalah berdasarkan memori Dipertingkatkan dengan saiz 10.
Latih dan nilai pada 4-8 GPU NVIDIA 1080Ti untuk urutan yang lebih panjang, tukar kepada satu NVIDIA A100 40GB untuk penilaian dipercepatkan.
Pembelajaran Kurikulum
Penyelidik mendapati bahawa menggunakan penjadualan latihan boleh meningkatkan ketepatan dan kestabilan penyelesaian dengan ketara.
Mula-mula biarkan RMT melatih versi tugasan yang lebih pendek Selepas latihan bertumpu, tambah panjang tugasan dengan menambah segmen dan teruskan proses pembelajaran kursus sehingga panjang input yang ideal dicapai.
Mulakan percubaan dengan urutan yang sesuai dengan satu segmen Saiz segmen sebenar ialah 499 kerana 3 token khas BERT dan 10 ruang letak memori dikekalkan daripada input model, memberikan jumlah saiz 512.
Dapat diperhatikan bahawa selepas latihan mengenai tugasan yang lebih pendek, RMT lebih mudah untuk menyelesaikan tugasan yang lebih panjang kerana ia menumpu kepada penyelesaian yang sempurna menggunakan langkah latihan yang lebih sedikit.
Keupayaan Ekstrapolasi
Untuk memerhatikan keupayaan generalisasi RMT kepada panjang jujukan yang berbeza, para penyelidik menilai model yang dilatih pada bilangan segmen yang berbeza, untuk menyelesaikan tugasan yang lebih besar. panjang.
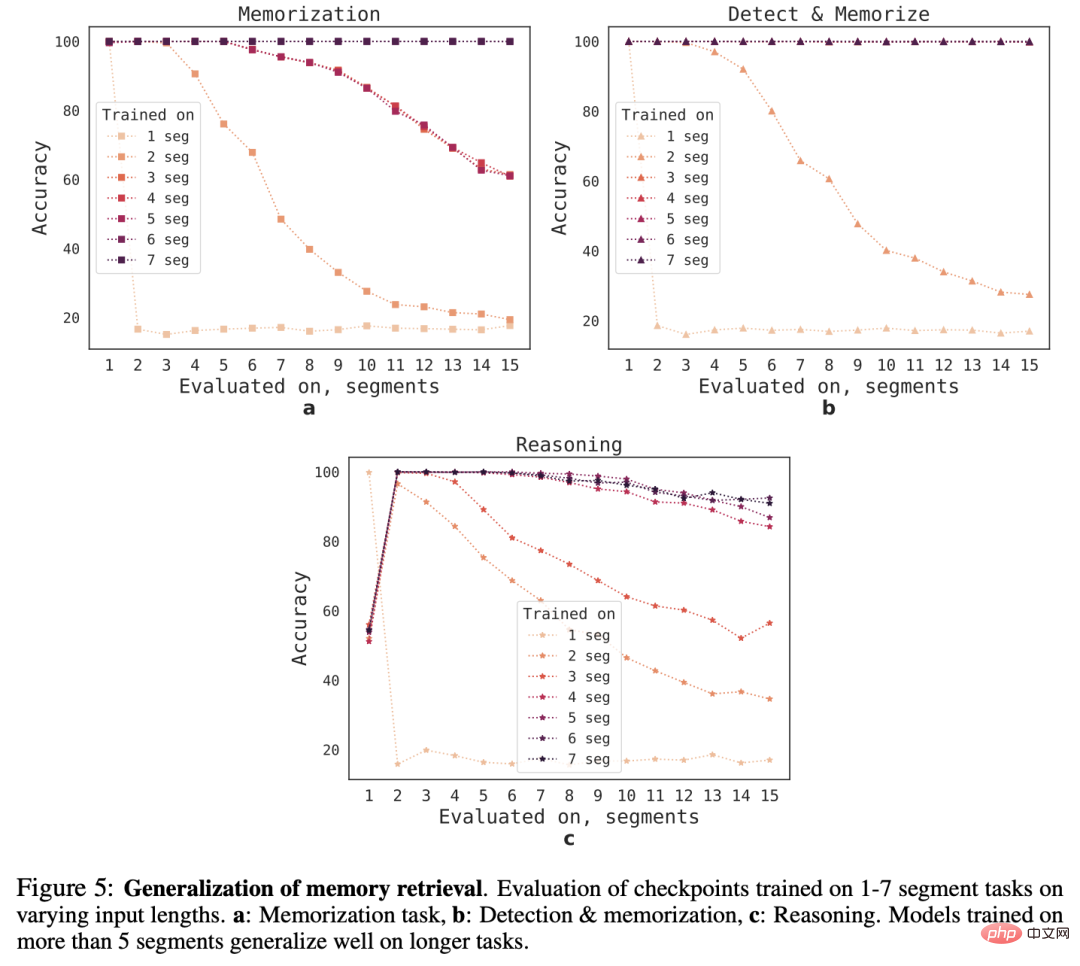
Dapat diperhatikan bahawa model sering berprestasi baik pada tugasan yang lebih pendek, tetapi selepas melatih model pada urutan yang lebih panjang, ia menjadi sukar untuk mengendalikan tugasan inferens segmen tunggal.
Penjelasan yang mungkin adalah kerana saiz tugasan melebihi satu segmen, model berhenti menjangka masalah dalam segmen pertama, mengakibatkan penurunan kualiti.
Menariknya, apabila bilangan segmen latihan meningkat, keupayaan generalisasi RMT kepada urutan yang lebih panjang juga muncul Selepas latihan pada 5 atau lebih segmen, RMT boleh melakukan latihan pada urutan dua kali lebih panjang tugasan.
Untuk menguji had generalisasi, penyelidik meningkatkan saiz tugas pengesahan kepada 4096 segmen (iaitu 2,043,904 token).
RMT mengekalkan dengan baik pada jujukan yang begitu panjang, yang mana tugas "pengesan dan ingatan" adalah yang paling mudah dan tugas inferens adalah yang paling kompleks.
Rujukan: https://www.php.cn/link/459ad054a6417248a1166b30f6393301
Atas ialah kandungan terperinci Selesaikan sepenuhnya ChatGPT amnesia! Menembusi had input Transformer: diukur untuk menyokong 2 juta token yang sah. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI