
Rumah >pembangunan bahagian belakang >Tutorial Python >Apakah Python multithreading dan cara menggunakannya
Apakah Python multithreading dan cara menggunakannya

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-13 11:55:141021semak imbas
Apakah benang? Kenapa awak mahukannya?
Pada dasarnya, Python ialah bahasa linear, tetapi modul penjalinan amat berguna apabila anda memerlukan lebih banyak kuasa pemprosesan. Walaupun benang dalam Python tidak boleh digunakan untuk pengkomputeran CPU selari, ia sangat sesuai untuk operasi I/O seperti mengikis web kerana pemproses melahu, menunggu data.
Benang sedang mengubah permainan kerana banyak skrip berkaitan I/O rangkaian/data menghabiskan sebahagian besar masa mereka menunggu data daripada sumber jauh. Memandangkan muat turun mungkin dinyahpautkan (iaitu merangkak tapak web berasingan), pemproses boleh memuat turun daripada sumber data yang berbeza secara selari dan menggabungkan hasilnya pada penghujungnya. Untuk proses intensif CPU, terdapat sedikit faedah untuk menggunakan modul benang.
Mujurlah, urutan disertakan dalam pustaka standard:
import threading from queue import Queue import time
Anda boleh menggunakan target sebagai boleh panggil dan args untuk menghantar hujah Lulus ke fungsi dan start mulakan utas.
def testThread(num): print num if __name__ == '__main__': for i in range(5): t = threading.Thread(target=testThread, arg=(i,)) t.start()
Jika anda tidak pernah melihat if __name__ == '__main__': sebelum ini, ini pada asasnya adalah cara untuk memastikan kod yang bersarang di dalamnya hanya berjalan apabila skrip dijalankan secara langsung (berbanding dengan diimport).
Kunci
Benang proses sistem pengendalian yang sama mengedarkan beban kerja pengkomputeran merentas berbilang teras, seperti yang dilihat dalam bahasa pengaturcaraan seperti C++ dan Java. Biasanya, python hanya menggunakan satu proses, dari mana benang utama dihasilkan untuk melaksanakan runtime. Ia kekal pada teras tunggal tanpa mengira berapa banyak teras yang ada pada komputer atau berapa banyak utas baharu yang dihasilkan disebabkan oleh mekanisme penguncian yang dipanggil kunci penterjemah global Untuk mengelakkan apa yang dipanggil keadaan perlumbaan.
 Apabila bercakap tentang persaingan, saya memikirkan NASCAR dan Formula Satu. Mari kita gunakan analogi ini dan bayangkan semua pemandu Formula 1 cuba berlumba dalam satu kereta pada masa yang sama. Kedengaran tidak masuk akal, bukan? , yang hanya boleh dilakukan jika setiap pemandu mempunyai akses kepada keretanya sendiri, atau lebih baik lagi, berlari satu pusingan pada satu masa, menyerahkan kereta itu kepada pemandu seterusnya setiap kali.
Apabila bercakap tentang persaingan, saya memikirkan NASCAR dan Formula Satu. Mari kita gunakan analogi ini dan bayangkan semua pemandu Formula 1 cuba berlumba dalam satu kereta pada masa yang sama. Kedengaran tidak masuk akal, bukan? , yang hanya boleh dilakukan jika setiap pemandu mempunyai akses kepada keretanya sendiri, atau lebih baik lagi, berlari satu pusingan pada satu masa, menyerahkan kereta itu kepada pemandu seterusnya setiap kali.
Ini sangat serupa dengan apa yang berlaku dalam urutan. Benang "bercabang" daripada benang "utama", dan setiap utas berikutnya ialah salinan benang sebelumnya. Utas ini semuanya wujud dalam "konteks" proses yang sama (acara atau perlumbaan), jadi semua sumber (seperti ingatan) yang diperuntukkan kepada proses dikongsi. Contohnya, dalam sesi penterjemah python biasa:
>>> a = 8
Di sini,
menggunakan sangat sedikit memori (RAM) dengan menahan nilai 8 buat sementara waktu di beberapa lokasi sewenang-wenangnya dalam ingatan.aSetakat ini, mari kita mulakan beberapa utas dan amati gelagat mereka apabila menambah dua nombor
: x
import time
import threading
from threading import Thread
a = 8
def threaded_add(x, y):
# simulation of a more complex task by asking
# python to sleep, since adding happens so quick!
for i in range(2):
global a
print("computing task in a different thread!")
time.sleep(1)
#this is not okay! but python will force sync, more on that later!
a = 10
print(a)
# the current thread will be a subset fork!
if __name__ != "__main__":
current_thread = threading.current_thread()
# here we tell python from the main
# thread of execution make others
if __name__ == "__main__":
thread = Thread(target = threaded_add, args = (1, 2))
thread.start()
thread.join()
print(a)
print("main thread finished...exiting")
>>> computing task in a different thread! >>> 10 >>> computing task in a different thread! >>> 10 >>> 10 >>> main thread finished...exiting
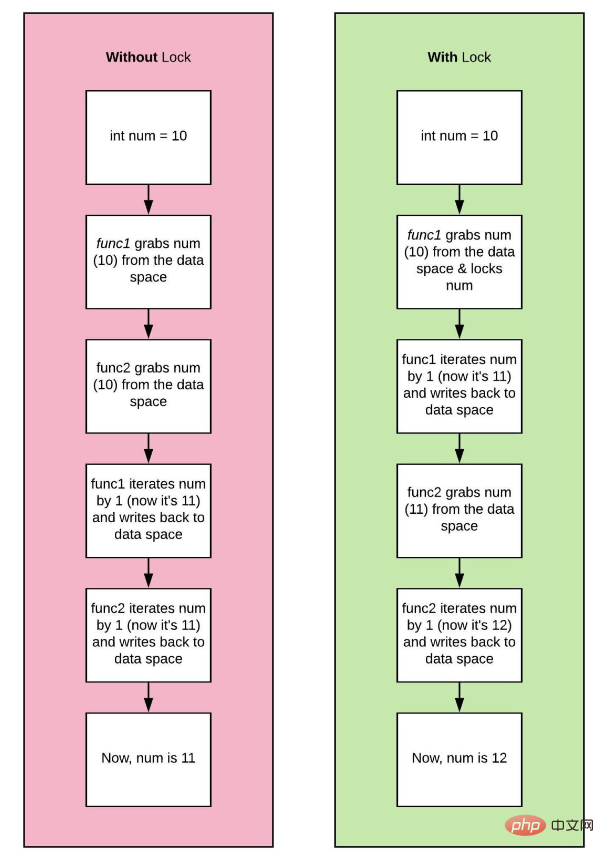
y Kedua-dua utas sedang berjalan. Mari kita panggil mereka dan . Jika thread_one mahu mengubah suai thread_two dengan nilai 10, dan thread_one pada masa yang sama cuba mengemas kini pembolehubah yang sama, kami menghadapi masalah! Situasi yang dipanggil perlumbaan data akan berlaku dan nilai a yang terhasil akan menjadi tidak konsisten. thread_twoaAcara perlumbaan yang anda tidak tonton, tetapi mendengar dua keputusan bercanggah daripada dua rakan anda!
menyangkal perkara ini! Berikut ialah coretan pseudokod untuk menggambarkan: thread_one
a = 8 # spawns two different threads 1 and 2 # thread_one updates the value of a to 10 if (a == 10): # a check #thread_two updates the value of a to 15 a = 15 b = a * 2 # if thread_one finished first the result will be 20 # if thread_two finished first the result will be 30 # who is right?
thread twoApa yang sedang berlaku? Python ialah bahasa yang ditafsirkan, yang bermaksud ia disertakan dengan penterjemah - program yang menghuraikan kod sumbernya daripada bahasa lain! Beberapa jurubahasa dalam python termasuk cpython, pypypy, Jpython dan IronPython, antaranya, cpython ialah pelaksanaan asal python.
CPython ialah penterjemah yang menyediakan antara muka fungsi luaran dengan C dan bahasa pengaturcaraan lain Ia menyusun kod sumber python ke dalam kod bait perantaraan, yang ditafsirkan oleh mesin maya CPython. Perbincangan setakat ini dan pada masa hadapan adalah mengenai CPython dan memahami tingkah laku dalam persekitaran.
内存模型和锁定机制
编程语言使用程序中的对象来执行操作。这些对象由基本数据类型组成,如string、integer或boolean。它们还包括更复杂的数据结构,如list或classes/objects。程序对象的值存储在内存中,以便快速访问。在程序中使用变量时,进程将从内存中读取值并对其进行操作。在早期的编程语言中,大多数开发人员负责他们程序中的所有内存管理。这意味着在创建列表或对象之前,首先必须为变量分配内存。在这样做时,你可以继续释放以“释放”内存。
在python中,对象通过引用存储在内存中。引用是对象的一种标签,因此一个对象可以有许多名称,比如你如何拥有给定的名称和昵称。引用是对象的精确内存位置。引用计数器用于python中的垃圾收集,这是一种自动内存管理过程。
在引用计数器的帮助下,python通过在创建或引用对象时递增引用计数器和在取消引用对象时递减来跟踪每个对象。当引用计数为0时,对象的内存将被释放。
import sys import gc hello = "world" #reference to 'world' is 2 print (sys.getrefcount(hello)) bye = "world" other_bye = bye print(sys.getrefcount(bye)) print(gc.get_referrers(other_bye))
>>> 4
>>> 6
>>> [['sys', 'gc', 'hello', 'world', 'print', 'sys', 'getrefcount', 'hello', 'bye', 'world', 'other_bye', 'bye', 'print', 'sys', 'getrefcount', 'bye', 'print', 'gc', 'get_referrers', 'other_bye'], (0, None, 'world'), {'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.sourcefileloader>, '__spec__': None, '__annotations__': {}, '__builtins__': <module>, '__file__': 'test.py', '__cached__': None, 'sys': <module>, 'gc': <module>, 'hello': 'world', 'bye': 'world', 'other_bye': 'world'}]</module></module></module></_frozen_importlib_external.sourcefileloader>
需要保护这些参考计数器变量,防止竞争条件或内存泄漏。以保护这些变量;可以将锁添加到跨线程共享的所有数据结构中。
CPython 的 GIL 通过一次允许一个线程控制解释器来控制 Python 解释器。它为单线程程序提供了性能提升,因为只需要管理一个锁,但代价是它阻止了多线程 CPython 程序在某些情况下充分利用多处理器系统。
当用户编写python程序时,性能受CPU限制的程序和受I/O限制的程序之间存在差异。CPU通过同时执行许多操作将程序推到极限,而I/O程序必须花费时间等待I/O。
因此,只有多线程程序在GIL中花费大量时间来解释CPython字节码;GIL成为瓶颈。即使没有严格必要,GIL也会降低性能。例如,一个用python编写的同时处理IO和CPU任务的程序:
import time, os
from threading import Thread, current_thread
from multiprocessing import current_process
COUNT = 200000000
SLEEP = 10
def io_bound(sec):
pid = os.getpid()
threadName = current_thread().name
processName = current_process().name
print(f"{pid} * {processName} * {threadName} \
---> Start sleeping...")
time.sleep(sec)
print(f"{pid} * {processName} * {threadName} \
---> Finished sleeping...")
def cpu_bound(n):
pid = os.getpid()
threadName = current_thread().name
processName = current_process().name
print(f"{pid} * {processName} * {threadName} \
---> Start counting...")
while n>0:
n -= 1
print(f"{pid} * {processName} * {threadName} \
---> Finished counting...")
def timeit(function,args,threaded=False):
start = time.time()
if threaded:
t1 = Thread(target = function, args =(args, ))
t2 = Thread(target = function, args =(args, ))
t1.start()
t2.start()
t1.join()
t2.join()
else:
function(args)
end = time.time()
print('Time taken in seconds for running {} on Argument {} is {}s -{}'.format(function,args,end - start,"Threaded" if threaded else "None Threaded"))
if __name__=="__main__":
#Running io_bound task
print("IO BOUND TASK NON THREADED")
timeit(io_bound,SLEEP)
print("IO BOUND TASK THREADED")
#Running io_bound task in Thread
timeit(io_bound,SLEEP,threaded=True)
print("CPU BOUND TASK NON THREADED")
#Running cpu_bound task
timeit(cpu_bound,COUNT)
print("CPU BOUND TASK THREADED")
#Running cpu_bound task in Thread
timeit(cpu_bound,COUNT,threaded=True)
>>> IO BOUND TASK NON THREADED >>> 17244 * MainProcess * MainThread ---> Start sleeping... >>> 17244 * MainProcess * MainThread ---> Finished sleeping... >>> 17244 * MainProcess * MainThread ---> Start sleeping... >>> 17244 * MainProcess * MainThread ---> Finished sleeping... >>> Time taken in seconds for running <function> on Argument 10 is 20.036664724349976s -None Threaded >>> IO BOUND TASK THREADED >>> 10180 * MainProcess * Thread-1 ---> Start sleeping... >>> 10180 * MainProcess * Thread-2 ---> Start sleeping... >>> 10180 * MainProcess * Thread-1 ---> Finished sleeping... >>> 10180 * MainProcess * Thread-2 ---> Finished sleeping... >>> Time taken in seconds for running <function> on Argument 10 is 10.01464056968689s -Threaded >>> CPU BOUND TASK NON THREADED >>> 14172 * MainProcess * MainThread ---> Start counting... >>> 14172 * MainProcess * MainThread ---> Finished counting... >>> 14172 * MainProcess * MainThread ---> Start counting... >>> 14172 * MainProcess * MainThread ---> Finished counting... >>> Time taken in seconds for running <function> on Argument 200000000 is 44.90199875831604s -None Threaded >>> CPU BOUND TASK THEADED >>> 15616 * MainProcess * Thread-1 ---> Start counting... >>> 15616 * MainProcess * Thread-2 ---> Start counting... >>> 15616 * MainProcess * Thread-1 ---> Finished counting... >>> 15616 * MainProcess * Thread-2 ---> Finished counting... >>> Time taken in seconds for running <function> on Argument 200000000 is 106.09711360931396s -Threaded</function></function></function></function>
从结果中我们注意到,multithreading在多个IO绑定任务中表现出色,执行时间为10秒,而非线程方法执行时间为20秒。我们使用相同的方法执行CPU密集型任务。好吧,最初它确实同时启动了我们的线程,但最后,我们看到整个程序的执行需要大约106秒!然后发生了什么?这是因为当Thread-1启动时,它获取全局解释器锁(GIL),这防止Thread-2使用CPU。因此,Thread-2必须等待Thread-1完成其任务并释放锁,以便它可以获取锁并执行其任务。锁的获取和释放增加了总执行时间的开销。因此,可以肯定地说,线程不是依赖CPU执行任务的理想解决方案。
这种特性使并发编程变得困难。如果GIL在并发性方面阻碍了我们,我们是不是应该摆脱它,还是能够关闭它?。嗯,这并不容易。其他功能、库和包都依赖于GIL,因此必须有一些东西来取代它,否则整个生态系统将崩溃。这是一个很难解决的问题。
多进程
我们已经证实,CPython使用锁来保护数据不受竞速的影响,尽管这种锁存在,但程序员已经找到了一种显式实现并发的方法。当涉及到GIL时,我们可以使用multiprocessing库来绕过全局锁。多处理实现了真正意义上的并发,因为它在不同CPU核上跨不同进程执行代码。它创建了一个新的Python解释器实例,在每个内核上运行。不同的进程位于不同的内存位置,因此它们之间的对象共享并不容易。在这个实现中,python为每个要运行的进程提供了不同的解释器;因此在这种情况下,为多处理中的每个进程提供单个线程。
import os
import time
from multiprocessing import Process, current_process
SLEEP = 10
COUNT = 200000000
def count_down(cnt):
pid = os.getpid()
processName = current_process().name
print(f"{pid} * {processName} \
---> Start counting...")
while cnt > 0:
cnt -= 1
def io_bound(sec):
pid = os.getpid()
threadName = current_thread().name
processName = current_process().name
print(f"{pid} * {processName} * {threadName} \
---> Start sleeping...")
time.sleep(sec)
print(f"{pid} * {processName} * {threadName} \
---> Finished sleeping...")
if __name__ == '__main__':
# creating processes
start = time.time()
#CPU BOUND
p1 = Process(target=count_down, args=(COUNT, ))
p2 = Process(target=count_down, args=(COUNT, ))
#IO BOUND
#p1 = Process(target=, args=(SLEEP, ))
#p2 = Process(target=count_down, args=(SLEEP, ))
# starting process_thread
p1.start()
p2.start()
# wait until finished
p1.join()
p2.join()
stop = time.time()
elapsed = stop - start
print ("The time taken in seconds is :", elapsed)
>>> 1660 * Process-2 ---> Start counting... >>> 10184 * Process-1 ---> Start counting... >>> The time taken in seconds is : 12.815475225448608
可以看出,对于cpu和io绑定任务,multiprocessing性能异常出色。MainProcess启动了两个子进程,Process-1和Process-2,它们具有不同的PIDs,每个都执行将COUNT减少到零的任务。每个进程并行运行,使用单独的CPU内核和自己的Python解释器实例,因此整个程序执行只需12秒。
请注意,输出可能以无序的方式打印,因为过程彼此独立。这是因为每个进程都在自己的默认主线程中执行函数。
我们还可以使用asyncio库(上一节我已经讲过了,没看的可以返回到上一节去学习)绕过GIL锁。asyncio的基本概念是,一个称为事件循环的python对象控制每个任务的运行方式和时间。事件循环知道每个任务及其状态。就绪状态表示任务已准备好运行,等待阶段表示任务正在等待某个外部任务完成。在异步IO中,任务永远不会放弃控制,也不会在执行过程中被中断,因此对象共享是线程安全的。
import time
import asyncio
COUNT = 200000000
# asynchronous function defination
async def func_name(cnt):
while cnt > 0:
cnt -= 1
#asynchronous main function defination
async def main ():
# Creating 2 tasks.....You could create as many tasks (n tasks)
task1 = loop.create_task(func_name(COUNT))
task2 = loop.create_task(func_name(COUNT))
# await each task to execute before handing control back to the program
await asyncio.wait([task1, task2])
if __name__ =='__main__':
# get the event loop
start_time = time.time()
loop = asyncio.get_event_loop()
# run all tasks in the event loop until completion
loop.run_until_complete(main())
loop.close()
print("--- %s seconds ---" % (time.time() - start_time))
>>> --- 41.74118399620056 seconds ---
我们可以看到,asyncio需要41秒来完成倒计时,这比multithreading的106秒要好,但对于cpu受限的任务,不如multiprocessing的12秒。Asyncio创建一个eventloop和两个任务task1和task2,然后将这些任务放在eventloop上。然后,程序await任务的执行,因为事件循环执行所有任务直至完成。
为了充分利用python中并发的全部功能,我们还可以使用不同的解释器。JPython和IronPython没有GIL,这意味着用户可以充分利用多处理器系统。
与线程一样,多进程仍然存在缺点:
数据在进程之间混洗会产生 I/O 开销
整个内存被复制到每个子进程中,这对于更重要的程序来说可能是很多开销
Atas ialah kandungan terperinci Apakah Python multithreading dan cara menggunakannya. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!