
Rumah >pembangunan bahagian belakang >Tutorial Python >Bagaimana Python Vaex boleh menganalisis volum data besar 100G dengan cepat
Bagaimana Python Vaex boleh menganalisis volum data besar 100G dengan cepat

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-13 08:34:051402semak imbas
Keterbatasan panda dalam memproses data besar
Kini, pertandingan sains data menyediakan jumlah data yang semakin meningkat, daripada berdozen gigabait hingga ratusan gigabait, yang menguji prestasi mesin dan keupayaan pemprosesan data .
Panda dalam Python ialah alat pemprosesan data yang biasa digunakan Ia boleh mengendalikan set data yang lebih besar (berpuluh-puluh juta baris Walau bagaimanapun, apabila volum data mencapai berbilion-bilion baris, panda agak tidak dapat melakukannya menanganinya, ia boleh dikatakan sangat perlahan.
Terdapat faktor prestasi seperti ingatan komputer, tetapi mekanisme pemprosesan data panda sendiri (bergantung pada ingatan) juga mengehadkan keupayaannya untuk memproses data besar.
Sudah tentu panda boleh membaca data dalam kelompok melalui ketulan, tetapi kelemahannya ialah pemprosesan data lebih kompleks, dan setiap langkah analisis menggunakan memori dan masa.
Yang berikut menggunakan panda untuk membaca set data 3.7G (format hdf5. Set data mempunyai 4 lajur dan 100 juta baris, dan mengira purata baris pertama). CPU komputer saya ialah i7-8550U dan memori ialah 8G Mari kita lihat berapa lama proses pemuatan dan pengiraan ini mengambil masa.
Dataset:
Gunakan panda untuk membaca dan mengira:
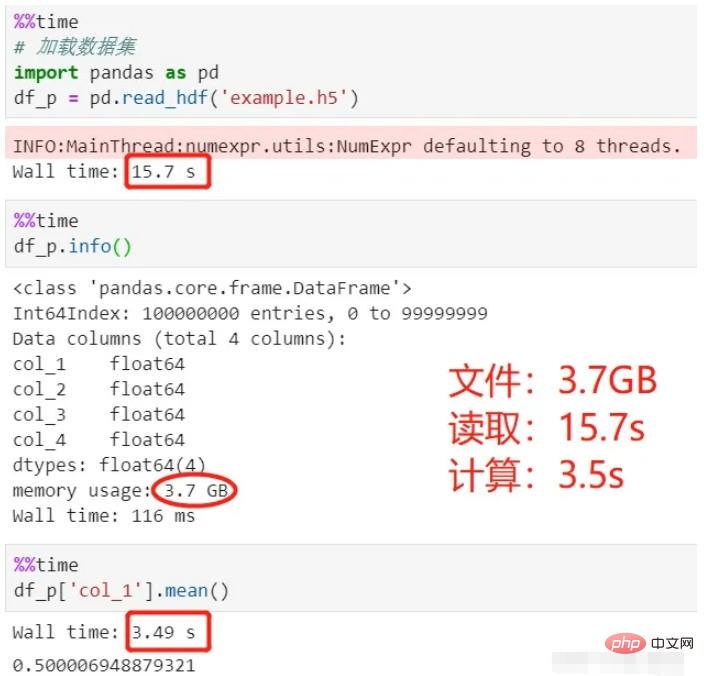
Lihat proses di atas , ia mengambil masa 15 saat untuk memuatkan data, dan 3.5 saat untuk mengira purata, untuk jumlah keseluruhan 18.5 saat.
Fail HDF5 digunakan di sini HDF5 ialah format storan fail Berbanding dengan CSV, ia lebih sesuai untuk menyimpan sejumlah besar data, mempunyai tahap pemampatan yang tinggi, dan lebih pantas untuk membaca dan menulis.
Tukar kepada vaex protagonis hari ini, baca data yang sama dan lakukan pengiraan purata yang sama Berapa lama masa yang diambil?
Gunakan vaex untuk membaca dan mengira:
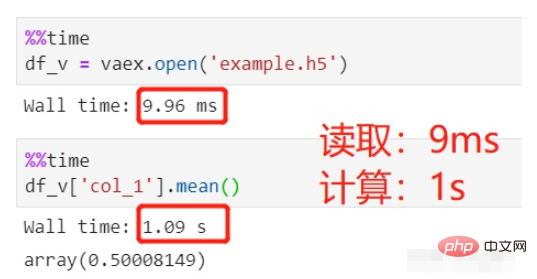
Bacaan fail mengambil masa 9ms, yang boleh diabaikan, dan pengiraan purata mengambil masa 1s, sejumlah 1s.
Set data HDFS yang sama dengan 100 juta baris dibaca Mengapa panda mengambil masa lebih daripada sepuluh saat, manakala vaex mengambil masa hampir 0?
Ini terutamanya kerana panda membaca data ke dalam ingatan dan kemudian menggunakannya untuk pemprosesan dan pengiraan. Vaex hanya akan memetakan memori dan bukannya membaca data ke dalam memori Ini sama seperti pemuatan malas percikan Ia akan dimuatkan apabila ia digunakan dan bukan apabila ia diisytiharkan.
Jadi tidak kira berapa besar data yang dimuatkan, 10GB, 100GB... ia boleh dilakukan serta-merta untuk vaex. Lalat dalam salap ialah pemuatan malas vaex hanya menyokong HDF5, Apache Arrow, Parket, FITS dan fail lain, tetapi tidak menyokong fail teks seperti csv, kerana fail teks tidak boleh dipetakan memori.
Sesetengah rakan mungkin tidak memahami pemetaan memori dengan baik. Berikut ialah penjelasan Anda perlu memikirkannya sendiri:
Pemetaan memori merujuk kepada lokasi fail pada cakera keras dan alamat logik. daripada proses tersebut. Surat-menyurat ini adalah konsep logik semata-mata dan tidak wujud secara fizikal Sebabnya ialah ruang alamat logik proses itu sendiri tidak wujud. Dalam proses pemetaan memori, tiada salinan data sebenar Fail tidak dimuatkan ke dalam memori, tetapi secara logik dimasukkan ke dalam memori Khusus kepada kod, struktur data yang berkaitan (struct address_space) ditubuhkan dan dimulakan.
Apakah itu vaex
Saya membandingkan kelajuan pemprosesan data besar antara vaex dan panda, dan vaex mempunyai kelebihan yang jelas. Walaupun kebolehannya menyerlah dan tidak begitu dikenali sebagai panda, vaex masih merupakan pendatang baru yang baru keluar dari industri.
vaex juga merupakan perpustakaan pihak ketiga untuk pemprosesan data berdasarkan Python, yang boleh dipasang menggunakan pip.
Pengenalan vaex di laman web rasmi boleh diringkaskan dalam tiga perkara:
vaex ialah alat jadual data untuk memproses dan memaparkan data, serupa dengan panda; 🎜>
- vaex menggunakan pemetaan memori dan pengiraan malas, tidak menggunakan memori, dan sesuai untuk memproses data besar
- vaex boleh melakukan tahap kedua; statistik mengenai berpuluh bilion set data Analisis dan paparan visual; baris/saat;
- Visualisasi: Mengandungi komponen visualisasi; > Interaktif: digunakan dengan buku nota Jupyter, visualisasi interaktif yang fleksibel;
- Pasang vaex
Gunakan pip atau conda untuk memasang:
- Membaca data
- Vaex menyokong pembacaan hdf5, csv, parket dan fail lain, menggunakan kaedah baca. hdf5 boleh dibaca dengan malas, manakala csv hanya boleh dibaca ke dalam ingatan.
-
fungsi membaca data VAEX:

Pemprosesan data
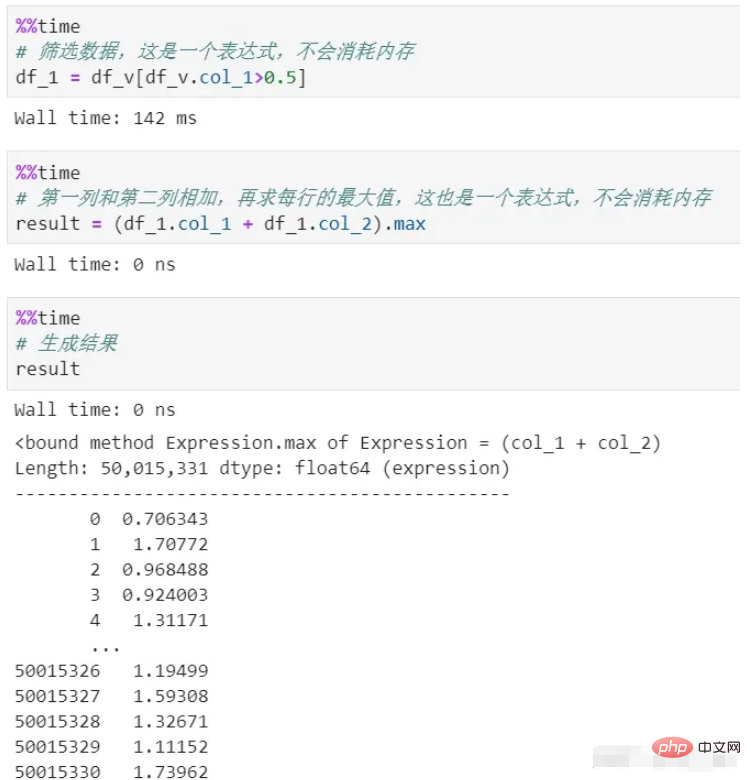
Kadangkala kita perlu melakukan pelbagai penukaran, penyaringan, pengiraan, dsb. pada data Setiap langkah pemprosesan panda akan menggunakan memori dan masa kosnya tinggi. Melainkan anda menggunakan pemprosesan rantai, prosesnya sangat tidak jelas.
vaex menggunakan memori sifar sepanjang proses. Kerana pemprosesannya hanya menjana ekspresi, yang merupakan perwakilan logik dan tidak akan dilaksanakan Ia hanya akan dilaksanakan dalam peringkat penjanaan hasil akhir. Selain itu, data dalam keseluruhan proses distrim, dan tidak akan ada memori tertunggak.
Anda dapat melihat bahawa terdapat dua proses penapisan dan pengiraan, kedua-duanya tidak menyalin pengiraan tertunda, yang merupakan mekanisme malas, digunakan di sini. Jika setiap proses benar-benar dikira, apatah lagi penggunaan memori, kos masa sahaja akan menjadi besar.
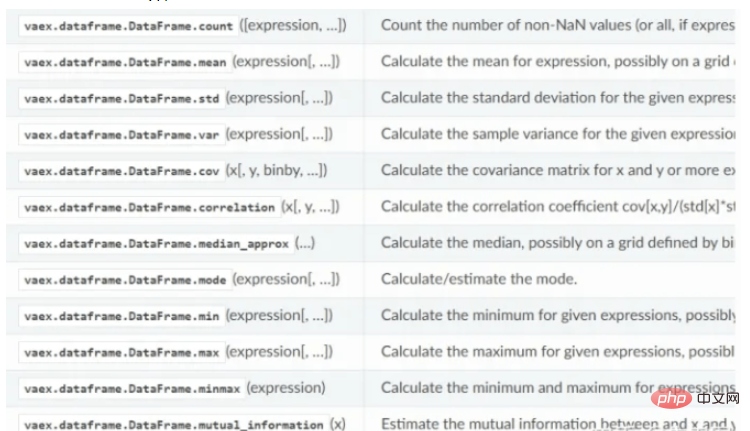
Fungsi pengiraan statistik Vaex:
Paparan visual
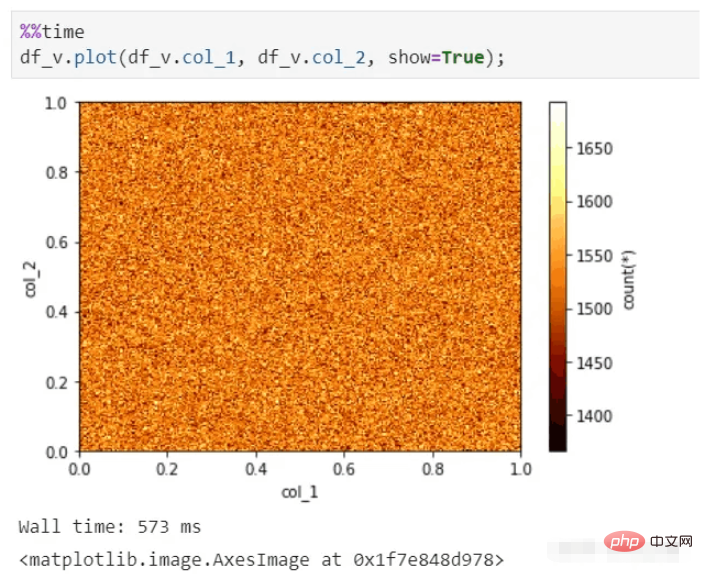
Vaex juga boleh melakukan paparan visual yang pantas, walaupun untuk berpuluh bilion data Kumpul dan masih boleh menghasilkan gambar dalam beberapa saat.
fungsi visualisasi vaix:
Kesimpulan
vaex agak serupa dengan gabungan percikan dan panda , lebih besar jumlah data, lebih banyak kelebihannya dapat dilihat. Selagi cakera keras anda boleh menyimpan seberapa banyak data yang diperlukan, ia boleh menganalisis data dengan cepat.
Vaex masih berkembang pesat, menyepadukan lebih banyak fungsi panda pada github ialah 5k, dan potensi pertumbuhannya sangat besar.
Lampirkan: kod penjanaan set data hdf5 (4 lajur dan 100 juta baris data)
import pandas as pd import vaex df = pd.DataFrame(np.random.rand(100000000,4),columns=['col_1','col_2','col_3','col_4']) df.to_csv('example.csv',index=False) vaex.read('example.csv',convert='example1.hdf5')
Sila ambil perhatian bahawa jangan gunakan panda untuk menjana hdf5 secara langsung di sini, kerana formatnya akan tidak serasi dengan vaex.

Atas ialah kandungan terperinci Bagaimana Python Vaex boleh menganalisis volum data besar 100G dengan cepat. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!