
Rumah >Peranti teknologi >AI >Lava Alpaca LLaVA ada di sini: seperti GPT-4, anda boleh melihat gambar dan berbual, tiada kod jemputan diperlukan dan anda boleh bermain dalam talian
Lava Alpaca LLaVA ada di sini: seperti GPT-4, anda boleh melihat gambar dan berbual, tiada kod jemputan diperlukan dan anda boleh bermain dalam talian

- PHPzke hadapan
- 2023-05-12 14:28:141332semak imbas

Bilakah keupayaan pengecaman imej GPT-4 akan berada dalam talian? Masih tiada jawapan untuk soalan ini.
Tetapi komuniti penyelidik tidak sabar lagi dan telah memulakan DIY Yang paling popular ialah projek yang dipanggil MiniGPT-4. MiniGPT-4 menunjukkan banyak keupayaan yang serupa dengan GPT-4, seperti menjana penerangan imej terperinci dan mencipta tapak web daripada draf tulisan tangan. Selain itu, pengarang memerhatikan keupayaan lain yang muncul dari MiniGPT-4, termasuk mencipta cerita dan puisi berdasarkan imej yang diberikan, menyediakan penyelesaian kepada masalah yang ditunjukkan dalam imej, mengajar pengguna cara memasak berdasarkan foto makanan, dsb. Projek itu menerima hampir 10,000 bintang dalam masa 3 hari selepas pelancarannya.

Projek yang akan kami perkenalkan hari ini - LLaVA (Large Language and Vision Assistant) adalah serupa dan merupakan projek yang dibangunkan oleh University of Wisconsin -Madison dan Microsoft Model berbilang modal besar yang dikeluarkan bersama oleh penyelidik dari Institut dan Universiti Columbia.

- Pautan kertas: https://arxiv.org/pdf/2304.08485.pdf
- Pautan projek: https://llava-vl.github.io/
Model ini menunjukkan beberapa Imej dan keupayaan pemahaman teks hampir dengan GPT-4 berbilang modal: ia mencapai skor relatif 85.1% berbanding GPT-4. Apabila diperhalusi pada Science QA, sinergi LLaVA dan GPT-4 mencapai SoTA baharu dengan ketepatan 92.53%.

Berikut ialah keputusan percubaan Heart of the Machine (lihat lebih banyak keputusan di akhir artikel):

Paper Overview
Manusia berinteraksi dengan dunia melalui pelbagai saluran seperti penglihatan dan bahasa, kerana saluran yang berbeza mempunyai kelebihan tersendiri dalam mewakili dan menyampaikan konsep tertentu, cara berbilang saluran untuk lebih memahami dunia. Salah satu aspirasi teras kecerdasan buatan adalah untuk membangunkan pembantu sejagat yang boleh mengikut arahan berbilang modal dengan berkesan, seperti arahan visual atau lisan, memenuhi niat manusia, dan menyelesaikan pelbagai tugas dalam persekitaran sebenar.
Untuk tujuan ini, terdapat trend dalam komuniti untuk membangunkan model visual berdasarkan peningkatan bahasa. Model jenis ini mempunyai keupayaan hebat dalam pemahaman visual dunia terbuka, seperti pengelasan, pengesanan, pembahagian dan grafik, serta penjanaan visual dan keupayaan penyuntingan visual. Setiap tugasan diselesaikan secara bebas oleh model visual yang besar, dengan keperluan tugasan dipertimbangkan secara tersirat dalam reka bentuk model. Tambahan pula, bahasa digunakan hanya untuk menerangkan kandungan imej. Walaupun ini menjadikan bahasa memainkan peranan penting dalam memetakan isyarat visual kepada semantik linguistik (saluran biasa untuk komunikasi manusia), ia menghasilkan model yang selalunya mempunyai antara muka tetap dengan batasan dalam interaktiviti dan kebolehsuaian kepada arahan pengguna.
Model Bahasa Besar (LLM), sebaliknya, telah menunjukkan bahawa bahasa boleh memainkan peranan yang lebih luas: sebagai antara muka interaktif universal untuk pembantu pintar universal. Dalam antara muka biasa, pelbagai arahan tugasan boleh dinyatakan secara eksplisit dalam bahasa dan membimbing pembantu rangkaian saraf terlatih hujung-ke-hujung untuk menukar mod untuk menyelesaikan tugasan. Sebagai contoh, kejayaan ChatGPT dan GPT-4 baru-baru ini menunjukkan kuasa LLM dalam mengikut arahan manusia untuk menyelesaikan tugas dan mencetuskan gelombang pembangunan LLM sumber terbuka. Antaranya, LLaMA ialah LLM sumber terbuka dengan prestasi yang serupa dengan GPT-3. Alpaca, Vicuna, GPT-4-LLM menggunakan pelbagai sampel surih arahan berkualiti tinggi yang dihasilkan mesin untuk meningkatkan keupayaan penjajaran LLM, menunjukkan prestasi yang mengagumkan berbanding LLM proprietari. Malangnya, input kepada model ini adalah teks sahaja.
Dalam artikel ini, penyelidik mencadangkan kaedah penalaan arahan visual, yang merupakan percubaan pertama untuk melanjutkan penalaan arahan kepada ruang berbilang mod, membuka jalan untuk membina pembantu visual am.
Secara khusus, kertas kerja ini memberikan sumbangan berikut:
- Data arahan berbilang mod. Salah satu cabaran utama hari ini ialah kekurangan data arahan visual dan lisan. Kertas kerja ini mencadangkan pendekatan penyusunan semula data menggunakan ChatGPT/GPT-4 untuk menukar pasangan teks imej ke dalam format arahan yang sesuai; Para penyelidik membangunkan model multimodal besar (LMM) - LLaVA - dengan menyambungkan pengekod visual sumber terbuka CLIP dan penyahkod bahasa LLaMA, dan melakukan penalaan halus hujung ke hujung pada data arahan visual-verbal yang dijana. Penyelidikan empirikal mengesahkan keberkesanan menggunakan data yang dijana untuk penalaan arahan LMM, dan menyediakan teknik yang lebih praktikal untuk membina arahan universal yang mengikut agen visual. Menggunakan GPT-4, kami mencapai prestasi terkini pada Science QA, set data inferens berbilang modal.
- Sumber terbuka. Para penyelidik mengeluarkan aset berikut kepada orang ramai: data arahan berbilang modal yang dijana, perpustakaan kod untuk penjanaan data dan latihan model, pusat pemeriksaan model dan demonstrasi sembang visual.
- LLaVA Architecture
Untuk imej input X_v, artikel ini menggunakan pengekod visual CLIP terlatih ViT-L/14 untuk pemprosesan dan mendapatkan ciri visual Z_v=g ( X_v). Ciri mesh sebelum dan selepas lapisan Transformer terakhir digunakan dalam eksperimen. Artikel ini menggunakan lapisan linear ringkas untuk menyambungkan ciri imej ke dalam ruang pembenaman perkataan. Khususnya, matriks unjuran yang boleh dilatih W digunakan untuk mengubah Z_v menjadi token pembenaman bahasa H_q, yang mempunyai dimensi yang sama seperti ruang pembenaman perkataan dalam model bahasa: 
Selepas itu, satu siri penanda visual H_v diperolehi. Skim unjuran mudah ini adalah ringan, kos rendah dan boleh mengulangi dengan cepat pada eksperimen tertumpu data. Seseorang juga boleh mempertimbangkan skim yang lebih kompleks (tetapi mahal) untuk menggabungkan ciri imej dan bahasa, seperti mekanisme perhatian silang berpagar dalam Flamingo dan Q-bekas dalam BLIP-2, atau pengekod visual lain yang menyediakan ciri peringkat objek, seperti SAM. 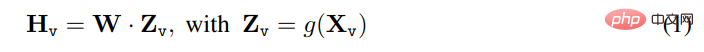
Hasil eksperimen
Bot sembang pelbagaimod
Pengkaji membangunkan produk contoh Robot sembang untuk menunjukkan pemahaman imej LLaVA dan keupayaan dialog. Untuk mengkaji lebih lanjut bagaimana LLaVA memproses input visual dan menunjukkan keupayaannya untuk memproses arahan, penyelidik mula-mula menggunakan contoh daripada kertas GPT-4 asal, seperti yang ditunjukkan dalam Jadual 4 dan 5. Gesaan yang digunakan perlu sesuai dengan kandungan imej. Sebagai perbandingan, artikel ini memetik gesaan dan keputusan model multimodal GPT-4 daripada kertas mereka.

Anehnya, walaupun LLaVA dilakukan menggunakan set data arahan berbilang modal kecil ( (kira-kira 80K imej unik ), tetapi ia menunjukkan keputusan inferens yang hampir sama dengan model berbilang modal GPT-4 pada dua contoh di atas. Ambil perhatian bahawa kedua-dua imej berada di luar skop set data LLaVA, yang mampu memahami adegan dan menjawab arahan soalan. Sebaliknya, BLIP-2 dan OpenFlamingo menumpukan pada menerangkan imej dan bukannya menjawab arahan pengguna dengan cara yang sesuai. Lebih banyak contoh ditunjukkan dalam Rajah 3, Rajah 4, dan Rajah 5. 



Keputusan penilaian kuantitatif ditunjukkan dalam Jadual 3.

ScienceQA
ScienceQA mengandungi 21k pelbagai mod pelbagai pilihan Soalan , melibatkan 3 tema, 26 topik, 127 kategori dan 379 kemahiran, dengan kepelbagaian domain yang kaya. Set data penanda aras dibahagikan kepada bahagian latihan, pengesahan dan ujian dengan 12726, 4241 dan 4241 sampel masing-masing. Artikel ini membandingkan dua kaedah perwakilan, termasuk model GPT-3.5 (text-davinci-002) dan model GPT-3.5 tanpa versi Chain of Thought (CoT), LLaMA-Adapter dan Multimodal Thought Chain (MM- CoT) [57]. ], iaitu kaedah SoTA semasa pada set data ini, dan hasilnya ditunjukkan dalam Jadual 6.

Maklum balas percubaan
Pada halaman penggunaan visualisasi yang diberikan dalam kertas, Machine Heart juga cuba memasukkan beberapa gambar dan arahan. Yang pertama ialah tugas berbilang orang biasa dalam Soal Jawab. Ujian telah menunjukkan bahawa sasaran yang lebih kecil diabaikan semasa mengira orang, terdapat ralat pengecaman untuk orang yang bertindih, dan terdapat juga ralat pengecaman untuk jantina.


Seterusnya, kami mencuba beberapa tugas generasi, seperti menamakan gambar atau bercerita berdasarkan cerita bergambar. Hasil output oleh model masih berat sebelah ke arah memahami kandungan imej, dan keupayaan penjanaan perlu diperkukuh.


Dalam foto ini, bilangan orang masih boleh dikenal pasti dengan tepat walaupun mayat bertindih. Dari perspektif penerangan gambar dan keupayaan memahami, masih terdapat sorotan dalam karya artikel ini, dan terdapat ruang untuk penciptaan kedua.
Atas ialah kandungan terperinci Lava Alpaca LLaVA ada di sini: seperti GPT-4, anda boleh melihat gambar dan berbual, tiada kod jemputan diperlukan dan anda boleh bermain dalam talian. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI