
Rumah >pembangunan bahagian belakang >Tutorial Python >Analisis contoh tatabahasa biasa ungkapan biasa Python
Analisis contoh tatabahasa biasa ungkapan biasa Python

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-12 09:04:05974semak imbas
Ikhtisar ungkapan biasa
Ungkapan biasa ialah jujukan aksara khas yang boleh membantu anda menyemak dengan mudah sama ada rentetan sepadan dengan corak tertentu. Python telah menambah modul semula sejak versi 1.5, yang menyediakan corak ekspresi biasa gaya Perl. Modul semula membawa fungsi ekspresi tetap penuh kepada bahasa Python. Ungkapan biasa ialah alat pemprosesan aksara yang berkuasa Intipatinya ialah urutan aksara, yang boleh menyemak dengan mudah sama ada rentetan sepadan dengan corak tertentu bagi urutan aksara yang kami tentukan
Dalam ular sawa, ungkapan biasa Ia boleh digunakan melalui import semula modul. Artikel ini akan memperkenalkan penggunaan ungkapan biasa
Aksara biasa yang ditulis dalam ungkapan biasa semuanya bermaksud: padankan secara langsung
Tetapi terdapat beberapa Aksara khas, istilah meta . Ia muncul dalam rentetan ungkapan biasa, bukan untuk memadankannya secara langsung, tetapi untuk menyatakan beberapa makna istimewa
Karakter meta khas ini termasuk yang berikut:
. * + ? [ ] ^ $ { } | ( )
Mari perkenalkan mereka makna masing-masing:
1 Padanan titik semua aksara
Menunjukkan untuk memadankan mana-mana aksara kecuali pemisah baris
Contohnya, anda ingin memilih semua warna daripada teks. di bawah.
Epal itu hijau
Oren itu oren
Pisang itu kuning
Gagak hitam
Iaitu, cari semua warna Israel Perkataan yang berakhir dengan dan termasuk watak sebelumnya. Anda juga boleh menulis ungkapan biasa seperti ini Warna
di mana titik mewakili sebarang aksara, sila ambil perhatian bahawa ia adalah sebarang aksara.
Gabungan warna bermaksud mencari sebarang aksara diikuti dengan warna perkataan, dan rentetan dua perkataan digabungkan
Contoh:
# 导入re模块
import re
#输入文本内容
content='''苹果是绿色的
橙子是橙色的
香蕉是黄色的
乌鸦是黑色的'''
p=re.compile(r'.色')#r表示不要进行python语法中对字符串的转译
for one in p.findall(content):
print(one)
2. Asterisk - Ulang padanan beberapa kali
* - Menunjukkan pemadanan subungkapan sebelumnya dalam beberapa kali, termasuk 0 kali
Contohnya, anda ingin memilih setiap baris daripada teks berikut Kandungan rentetan selepas koma, termasuk koma itu sendiri. Ambil perhatian bahawa koma di sini ialah koma teks.
Epal adalah hijau
Oren adalah oren
Pisang adalah kuning
Gagak adalah hitam
Monyet
Anda boleh menulis ungkapan biasa seperti ini, .*.
Contoh:
# 导入re模块
import re
#输入文本内容
content='''苹果,是绿色的
橙子,是橙色的
香蕉,是黄色的
乌鸦,是黑色的
猴子,'''
p=re.compile(r',.*')#r表示不要进行python语法中对字符串的转译
for one in p.findall(content):
print(one)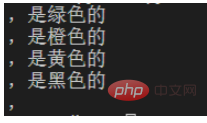
Dengan cara ini, rentetan berikut termasuk koma dipadankan
3
+ bermaksud memadankan subungkapan sebelumnya satu kali atau lebih, tidak termasuk 0 kali
Contohnya, masih dalam contoh di atas, anda perlu memilih hujung setiap baris daripada rentetan teks, termasuk koma itu sendiri. Tetapi tambah syarat, jika tiada kandungan selepas koma, jangan pilihnya.
Tiada kandungan selepas koma dalam baris terakhir teks di bawah, jadi jangan pilihnya
Epal berwarna hijau
Oren adalah oren
Pisang adalah kuning
gagak ialah monyet
hitam,
boleh ditulis seperti ini, .+
Contoh:
# 导入re模块
import re
#输入文本内容
content='''苹果,是绿色的
橙子,是橙色的
香蕉,是黄色的
乌鸦,是黑色的
猴子,'''
p=re.compile(r',.+')#r表示不要进行python语法中对字符串的转译
for one in p.findall(content):
print(one)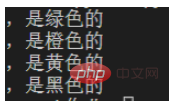
Dengan cara ini, tiada kandungan selepas koma dalam baris terakhir, jadi baris terakhir tidak sepadan dengan
4 kurungan kerinting - sepadan dengan bilangan kali yang ditentukan
Kurungan kerinting menunjukkan bahawa aksara sebelumnya sepadan dengan masa yang Ditentukan
Contohnya, teks berikut
merah, hijau, hitam, hijau
ungkapan minyak {3,4} Ia bermaksud memadankan aksara minyak berturut-turut sekurang-kurangnya 3 kali dan paling banyak 4 kali
Contoh:
# 导入re模块
import re
#输入文本内容
content='''红彤彤,绿油油,黑乎乎,绿油油油油'''
p=re.compile(r'绿油{3,4}')#r表示不要进行python语法中对字符串的转译
for one in p.findall(content):
print(one)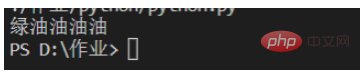
Di sini ia sepadan dengan hijau diikuti minyak sekurang-kurangnya 3 kali dan paling banyak 4 kali rentetan
5. Tanda soal-mod tamak dan mod tidak tamak
Kita perlu mengekstrak semua tag html dalam rentetan berikut

Dapatkan senarai sedemikian

Mudah untuk difikirkan menggunakan ungkapan biasa <.>
untuk menulis kod berikut
# 导入re模块 import re #输入文本内容 source='<html><head><title>Title</title>' p=re.compile(r'<.*>')#r表示不要进行python语法中对字符串的转译 print(p.findall(source))
Tetapi hasil daripada operasi ialah keseluruhan rentetan dipadankan

Apa yang sedang berlaku? Ternyata dalam ungkapan biasa, ’*’, ’+’, ’?' adalah tamak apabila menggunakannya, ia akan memadankan sebanyak mungkin kandungan, jadi, <.> (mewakili sebarang bilangan ulangan) padanan sehingga penghujung rentetan
为了解决整个问题,就需要使用非贪婪模式,也就是在星号后面加上?,变成这样<.>
代码改为
# 导入re模块 import re #输入文本内容 source='<html><head><title>Title</title>' p=re.compile(r'<.*?>')#r表示不要进行python语法中对字符串的转译 print(p.findall(source))

这样就单独去匹配出来了每一个标签
6、方括号-匹配几个字符之一
方括号表示要匹配某几种类型字符。
比如
[abc]可以匹配a,b,c里面的任意一个字符。等价于[a-c]
a-c中间的-表示一个范围从a到c
如果你想匹配所有小写字母,可以使用[a-z]
一些元字符在方括号内便失去了魔法,变得和普通字符一样了。
比如
[akm.]匹配a k m .里面的任意一个字符
在这里. 在括号不再表示匹配任意字符了,而就是表示匹配.这个字符
例如:
| 实例 | 描述 |
|---|---|
| [pP]ython | 匹配“Python”或者“python” |
| rub[ye] | 匹配“ruby”或者“rube” |
7、起始位置和单行、多行模式
^表示匹配文本的起始位置
正则表达式可以设定单行模式和多行模式
如果是单行模式,表示匹配整个文本的开头位置。
如果是多行模式,表示匹配文本每行的开头位置。
比如,下面的文本中,每行最前面的数字表示水果的编号,最后的数字表示价格
001-苹果价格-60,
002-橙子价格-70,
003-香蕉价格-80,
范例:
# 导入re模块
import re
#输入文本内容
source='''001-苹果-60
002-橙子-70
003-香蕉-80'''
p=re.compile(r'^\d+')#r表示不要进行python语法中对字符串的转译
for one in p.findall(source):
print(one)运行结果如下

如果去掉complie的第二个参数re.M,运行结果如下

就只进行一行匹配,
因为在单行模式下,^只会匹配整个文本的开头位置
$表示匹配文本的结束位置
如果是单行模式,表示匹配整个文本的结束位置。
如果是多行模式,表示匹配文本每行的结束位置。
比如,下面的文本中,每行最前面的数字表示水果的编号,最后的数字表示价格
001-苹果价格-60,
002-橙子价格-70,
003-香蕉价格-80,
如果我们要提取所有的水果编号,用这样的正则表达式\d+$
范例:
# 导入re模块
import re
#输入文本内容
source='''001-苹果-60
002-橙子-70
003-香蕉-80'''
p=re.compile(r'^\d+$',re.M)#re.M进行多行匹配
for one in p.findall(source):
print(one)
成功匹配到每行最后的价格
8、括号-组选择
主括号称之为正则表达式的组选择。是从正则表达式匹配的内容里面扣取出其中的某些部分
前面,我们有个例子,从下面的文本中,选择每行逗号前面的字符串,也包括逗号本身。
苹果,苹果是绿色的
橙子,橙子是橙色的
香蕉,香蕉是黄色的
就可以这样写正则表达式个^.*,。
但是,如果我们要求不要包括逗号呢?
当然不能直接这样写^.*
因为最后的逗号是特征所在,如果去掉它,就没法找逗号前面的了。
但是把逗号放在正则表达式中,又会包含逗号。
解决问题的方法就是使用组选择符:括号。
我们这样写^(.*),
我们把要从整个表达式中提取的部分放在括号中,这样水果的名字就被单独的放在组group中了。
对应的Python代码如下
# 导入re模块
import re
#输入文本内容
source='''苹果,苹果是绿色的
橙子,橙子是橙色的
香蕉,香蕉是黄色的'''
p=re.compile(r'^(.*),',re.M)#re.M进行多行匹配
for one in p.findall(source):
print(one)
这样我们就可以把,前的字符取出来了
9、反斜杠-对元字符的转义
反斜杠\在正则表达式中有多种用途
比如,我们要在下面的文本中搜索所有点前面的字符串,也包括点本身
苹果.是绿色的
橙子.是橙色的
香蕉.是黄色的
如果,我们这样写正则表达式.*.,聪明的你肯定发现不对劲。
因为点是一个元字符,直接出现在正则表达式中,表示匹配任意的单个字符,不能表示.这个字符的本身的意思了
怎么办呢?
如果我们要搜索的内容本身就包含元字符,就可以使用反斜杠进行转义
这里我们就应用这样的表达式.*\.
范例:
# 导入re模块
import re
#输入文本内容
source='''苹果.是绿色的
橙子.是橙色的
香蕉.是黄色的'''
p=re.compile(r'.*\.')#r表示不要进行python语法中对字符串的转译
for one in p.findall(source):
print(one)
成功匹配!
利用反斜杠还可以匹配某种字符类型
反斜杠后面接一些字符,表示匹配某种类型的一个字符
| 字符 | 功能 |
|---|---|
| \d | 匹配0~9之间的任意一个数字字符,等价于表达式[0-9] |
| \D | 匹配任意一个不上0-9之间的数字字符,等价于表达是[^0-9] |
| \s | 匹配任意一个空白字符,包括空格、tab、换行符等、等价于[\t\n\r\f\v] |
| \S | 匹配任意一个非空白字符,等价于[^\t\tn\r\f\v] |
| \w | 匹配任意一个文字字符,包括大小写、数字、下划线、等于[a-zA-A0-9] |
| \W | 匹配任意一个非文字字符,等价于表达式[^a-zA-Z0-9] |
反斜杠也可以用在方括号里面,比如[\s,.]:表示匹配任何空白字符,或者逗号,或者点
10、修饰符-可选标志
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位OR(I)它们来指定。如re.l | re.M被设置成Ⅰ和M标志:
| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响^和$ |
| re.S | 使.匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响lw,W,Nb,\B. |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解 |
11、使用正则表达式切割字符串
字符串对象的split()方法只适应于非常简单的字符串分割情形。当你需要更加灵活的切割字符串的时候,就不好用了。
比如,我们需要从下面字符串中提取武将的名字。
我们发现这些名字之间,有的是分号隔开,有的是逗号隔开,有的是空格隔开,而且分割符号周围还有不定数量的空格
names =“关羽;张飞,赵云,马超,黄忠 李逵”
这时,最好使用正则表达式里面的split方法:
范例:
# 导入re模块 import re #输入文本内容 names ="关羽;张飞,赵云,马超,黄忠 李逵" namelist=re.split(r'[;,\s]\s*',names) print(namelist)

正则表达式[;,ls]\s*指定了,分割符为分号、逗号、空格里面的任意一种均可,并且该符号周围可以有不定数量的空格。
Atas ialah kandungan terperinci Analisis contoh tatabahasa biasa ungkapan biasa Python. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!