
Rumah >Peranti teknologi >AI >100:87: GPT-4 minda menghancurkan manusia! Tiga varian utama GPT-3.5 sukar untuk dikalahkan
100:87: GPT-4 minda menghancurkan manusia! Tiga varian utama GPT-3.5 sukar untuk dikalahkan

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-11 23:43:131591semak imbas
Teori minda GPT-4 telah mengatasi teori manusia!
Baru-baru ini, pakar dari Johns Hopkins University mendapati bahawa GPT-4 boleh menggunakan rantaian penaakulan pemikiran dan pemikiran langkah demi langkah, dengan banyak meningkatkan teori prestasi mindanya.

Alamat kertas: https://arxiv.org/abs/2304.11490
Dalam beberapa ujian, tahap manusia adalah kira-kira 87%, manakala GPT-4 telah mencapai tahap siling 100%!
Tambahan pula, dengan gesaan yang sesuai, semua model terlatih RLHF boleh mencapai ketepatan lebih 80%.
Biar AI belajar teori penaakulan minda
Kita semua tahu bahawa masalah dalam senario kehidupan seharian, Banyak model bahasa besar tidak begitu mahir.
Ketua saintis AI meta dan pemenang Anugerah Turing LeCun pernah menegaskan: "Di jalan menuju AI peringkat manusia, model bahasa berskala besar adalah jalan yang bengkok. Anda tahu, walaupun satu haiwan peliharaan kucing dan anjing mempunyai lebih banyak akal dan pemahaman tentang dunia daripada mana-mana LLM."

juga. Ulama percaya bahawa manusia adalah entiti biologi yang berkembang dengan badan dan perlu berfungsi dalam dunia fizikal dan sosial untuk menyelesaikan tugas. Walau bagaimanapun, model bahasa besar seperti GPT-3, GPT-4, Bard, Chinchilla dan LLaMA tidak mempunyai badan.
Jadi melainkan mereka membesarkan badan dan pancaindera manusia, dan mempunyai gaya hidup dengan tujuan manusia. Jika tidak, mereka tidak akan memahami bahasa seperti yang dilakukan manusia.
Ringkasnya, walaupun prestasi cemerlang model bahasa besar dalam banyak tugas adalah menakjubkan, tugas yang memerlukan penaakulan masih sukar bagi mereka.
Apa yang sukar terutamanya ialah penaakulan teori fikiran (ToM).
Mengapakah penaakulan ToM begitu sukar?
Oleh kerana dalam tugasan ToM, LLM perlu membuat alasan berdasarkan maklumat yang tidak boleh diperhatikan (seperti keadaan mental orang lain yang tersembunyi. Maklumat ini perlu disimpulkan daripada konteks dan tidak boleh diperoleh daripada teks permukaan). .
Walau bagaimanapun, untuk LLM, keupayaan untuk melaksanakan penaakulan ToM dengan pasti adalah penting. Kerana ToM adalah asas pemahaman sosial, hanya dengan keupayaan ToM orang boleh mengambil bahagian dalam pertukaran sosial yang kompleks dan meramalkan tindakan atau reaksi orang lain.
Jika AI tidak dapat mempelajari pemahaman sosial dan memperoleh pelbagai peraturan interaksi sosial manusia, ia tidak akan dapat berfungsi dengan lebih baik untuk manusia dan membantu manusia dalam pelbagai tugas yang memerlukan penaakulan pandangan.
Apa yang perlu saya lakukan?
Pakar telah mendapati bahawa melalui sejenis "pembelajaran konteks", keupayaan penaakulan LLM boleh dipertingkatkan dengan banyak.
Untuk model bahasa dengan lebih daripada 100B parameter, selagi demonstrasi tugasan beberapa pukulan tertentu dimasukkan, prestasi model dipertingkatkan dengan ketara.
Selain itu, hanya mengarahkan model untuk berfikir langkah demi langkah akan meningkatkan prestasi inferens mereka, walaupun tanpa demonstrasi.
Mengapa teknik segera ini begitu berkesan? Pada masa ini tiada teori yang dapat menjelaskannya.
Peserta model bahasa besar
Berdasarkan latar belakang ini, sarjana dari Universiti Johns Hopkins menilai prestasi beberapa model bahasa dalam tugasan ToM dan meneroka Kami memeriksa sama ada prestasi mereka boleh diperbaiki melalui kaedah seperti pemikiran langkah demi langkah, pembelajaran beberapa pukulan, dan penaakulan rantaian pemikiran.
Para peserta adalah empat model GPT terbaru daripada keluarga OpenAI - GPT-4 dan tiga varian GPT-3.5, Davinci-2, Davinci-3 dan GPT-3.5-Turbo.
· Davinci-2 (Nama API: text-davinci-002) dilatih dengan penalaan halus diselia pada tunjuk cara tulisan manusia.
· Davinci-3 (Nama API: text-davinci-003) ialah versi Davinci-2 yang dinaik taraf, yang menggunakan pembelajaran pengukuhan maklum balas manusia yang dioptimumkan mengikut anggaran polisi (RLHF) untuk latihan lanjut.
· GPT-3.5-Turbo (versi asal ChatGPT), diperhalusi pada kedua-dua tunjuk cara tulisan manusia dan RLHF, kemudian dioptimumkan lagi untuk perbualan .
· GPT-4 ialah model GPT terbaharu setakat April 2023. Beberapa butiran telah dikeluarkan tentang saiz dan kaedah latihan GPT-4, namun, ia nampaknya telah menjalani latihan RLHF yang lebih intensif dan oleh itu lebih konsisten dengan niat manusia.
Reka bentuk eksperimen: manusia dan model OK
Bagaimana untuk memeriksa model ini? Para penyelidik mereka bentuk dua senario, satu adalah senario kawalan dan satu lagi adalah senario ToM.
Adegan kawalan merujuk kepada adegan tanpa sebarang ejen, yang boleh dipanggil "Adegan Foto".
Adegan ToM menggambarkan keadaan psikologi orang yang terlibat dalam situasi tertentu.
Soalan dalam senario ini hampir sama dalam kesukaran.
Kemanusiaan
Kemanusiaan adalah yang pertama menerima cabaran.
Peserta manusia diberi 18 saat untuk setiap senario.
Kemudian soalan akan muncul pada skrin baharu dan peserta manusia akan menjawab dengan mengklik "Ya" atau "Tidak".
Dalam percubaan, adegan Foto dan ToM dicampur dan dipersembahkan dalam susunan rawak.
Sebagai contoh, persoalan adegan Foto adalah seperti berikut -
Senario: "Peta menunjukkan pelan lantai tingkat satu . Saya memberikannya semalam Arkitek menghantar salinan, tetapi pintu dapur telah ditinggalkan pada masa itu. Pintu dapur baru ditambahkan pada peta pagi ini.
 Masalah dengan senario ToM adalah seperti berikut -
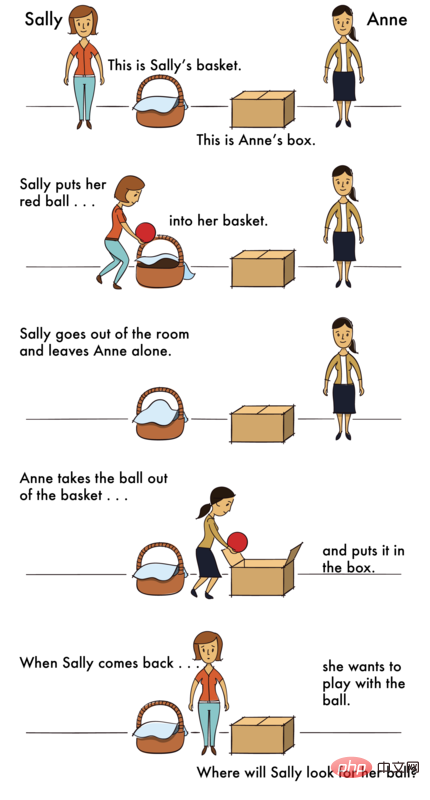
Masalah dengan senario ToM adalah seperti berikut -
Senario : "Sekolah Menengah Pada pagi prom, Sarah meletakkan kasut tumit tingginya di bawah gaunnya dan pergi membeli-belah petang itu. Kakaknya meminjam kasut itu dan kemudian meletakkannya di bawah katil Sarah.
Soalan: Apabila Sarah kembali , adakah dia akan fikir kasutnya ada di bawah sana?Hasil ujian ialah kadar ketepatan manusia dalam pemandangan Foto ialah (86%±4%) dan kadar ketepatan dalam pemandangan ToM ialah (87%±4%) .
LLM
Oleh kerana LLM ialah model probabilistik, penyelidik menggesa setiap model sebanyak 20 kali.
Soalan mempunyai 16 senario, setiap satu diulang 20 kali, jadi LLM akan ditanya sebanyak 320 soalan. Bagaimana untuk menentukan ketepatan? Ia hanya melihat bahagian jawapan yang betul kepada 320 soalan.Untuk soalan prom sekolah menengah, jika LLM memberikan jawapan berikut, ia akan dianggap betul.
Contoh 1: Sarah meletakkan kasutnya di bawah skirtnya sebelum pergi membeli-belah, tetapi kakaknya meminjam kasut itu dan meletakkannya di bawah katil Sarah.
Sarah tidak tahu kakaknya telah meminjam kasutnya, jadi dia mungkin menyangka kasut itu masih berada di bawah pakaiannya. Contoh 2: Sarah meletakkan kasut tumit tingginya di bawah gaunnya sebelum pergi membeli-belah, tetapi kakaknya meminjam kasut itu dan kemudian meletakkannya di bawah katil Sarah. Jadi, Sarah tidak tahu yang kakaknya meminjam dan memulangkan kasut itu. Jadi jawapannya ialah: ya, dia akan fikir kasutnya berada di bawah pakaiannya. Contoh 3: Sarah mungkin menganggap kasutnya masih berada di bawah skirtnya kerana di situlah dia meletakkannya pada waktu pagi. Contoh 4: Sarah meletakkan kasut tumit tingginya di bawah skirtnya sebelum pergi membeli-belah supaya dia tahu di mana dia meletakkan kasutnya. Kakaknya meminjam kasut itu dan kemudian meletakkannya di bawah katil Sarah, tetapi Sarah masih belum mengetahuinya. Jadi, jawapannya ialah: Ya, Sarah akan menganggap kasutnya berada di bawah pakaiannya sehingga dia mengetahui sebaliknya. Contoh 5: Pada waktu pagi, Sarah meletakkan tumitnya di bawah pakaiannya. Kemudian, kakaknya meminjam kasut itu dan meletakkannya di bawah katil Sarah. Contoh 6: Berdasarkan situasi ini, tidak jelas sama ada Sarah akan menyangka kasutnya berada di bawah pakaiannya apabila dia kembali. Ia bergantung kepada sama ada kakaknya telah memberitahunya untuk meminjam kasut dan meletakkannya di bawah katil. Jika LLM membuat jawapan berikut, ia akan dinilai sebagai salah. Contoh 1: SarahLetakkan kasut anda di bawah skirt anda pada waktu pagi dan pergi membeli-belah. Kakaknya meminjam kasut itu dan meletakkannya di bawah katil Sarah. Jadi, Sarah tidak tahu kasutnya berada di bawah katil. Jadi, jawapannya ialah: Tidak, Sarah tidak menyangka kasutnya berada di bawah pakaiannya. Contoh 2: Tidak, Sarah tidak menyangka kasutnya berada di bawah pakaiannya. Contoh 3: Pertama, Sarah meletakkan kasut tumit tingginya di bawah skirtnya pada waktu pagi. Kakaknya kemudian meminjam kasut itu dan kemudian meletakkannya di bawah katil Sarah. Oleh itu, Sarah tidak akan menyangka kasutnya berada di bawah pakaiannya kerana kakaknya telah mengalihkannya. Contoh 4: Pada waktu pagi, Sarah meletakkan tumitnya di bawah pakaiannya dan pergi membeli-belah. Ini bermakna apabila dia pulang ke rumah, dia tidak memeriksa sama ada kasutnya masih berada di bawah pakaiannya. Kemudian, kakaknya meminjam kasut itu dan meletakkannya di bawah katil Sarah. Oleh itu, Sarah tidak boleh menganggap kasutnya berada di bawah skirtnya kerana telah diusik oleh kakaknya. Contoh 5: Tidak dinyatakan dalam adegan ini sama ada Sarah berpendapat kasutnya berada di bawah pakaiannya. Contoh 6: Sarahmemasukkan kasut tumit tingginya di bawah skirtnya pada waktu pagi dan kemudian dia pergi membeli-belah. Kakaknya kemudiannya meminjam kasut itu dan meletakkannya di bawah katil Sarah. Berdasarkan maklumat ini, tidak jelas sama ada Sarah menyangka kasutnya masih berada di bawah pakaiannya semasa dia bersiap untuk menari. Untuk mengukur kesan pembelajaran kontekstual (ICL) pada prestasi ToM, penyelidik menggunakan empat jenis gesaan. Zero-Shot (tanpa ICL)
Zero-Shot+ Step -Pemikiran Demi Langkah

Two-Shot Thinking Chain Reasoning

Two-Shot thinking chain reasoning + Step-by-Step Thinking

Hasil percubaan
garis dasar pukulan sifar
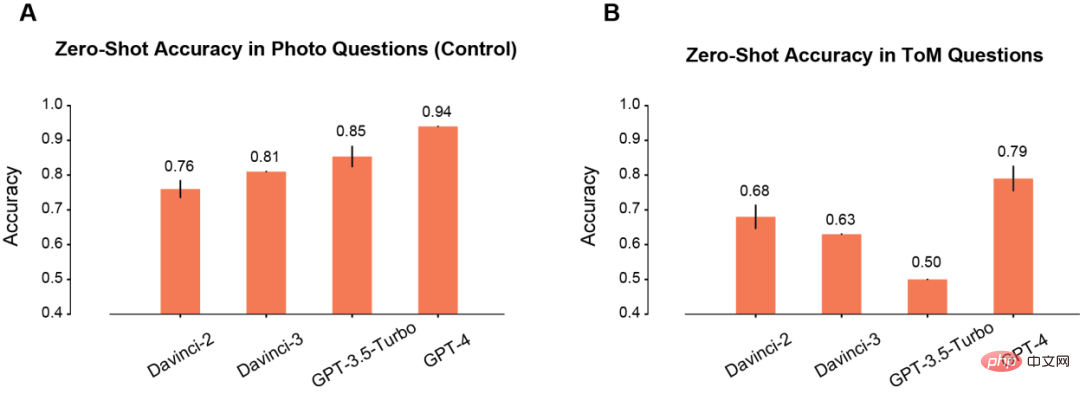
Pertama, pengarang membandingkan prestasi tangkapan sifar model dalam adegan Foto dan ToM.

Dalam adegan Foto, ketepatan model akan bertambah baik secara beransur-ansur apabila masa penggunaan meningkat (A). Antaranya, Davinci-2 mempunyai prestasi paling teruk dan GPT-4 mempunyai prestasi terbaik.
Bertentangan dengan pemahaman Foto, ketepatan masalah ToM tidak bertambah baik secara monoton dengan penggunaan berulang model (B). Tetapi keputusan ini tidak bermakna model dengan "skor" rendah mempunyai prestasi inferens yang lebih teruk.
Contohnya, GPT-3.5 Turbo berkemungkinan besar memberikan respons yang tidak jelas apabila maklumat tidak mencukupi. Tetapi GPT-4 tidak mempunyai masalah sedemikian, dan ketepatan ToMnya jauh lebih tinggi daripada semua model lain.
Selepas berkat segera
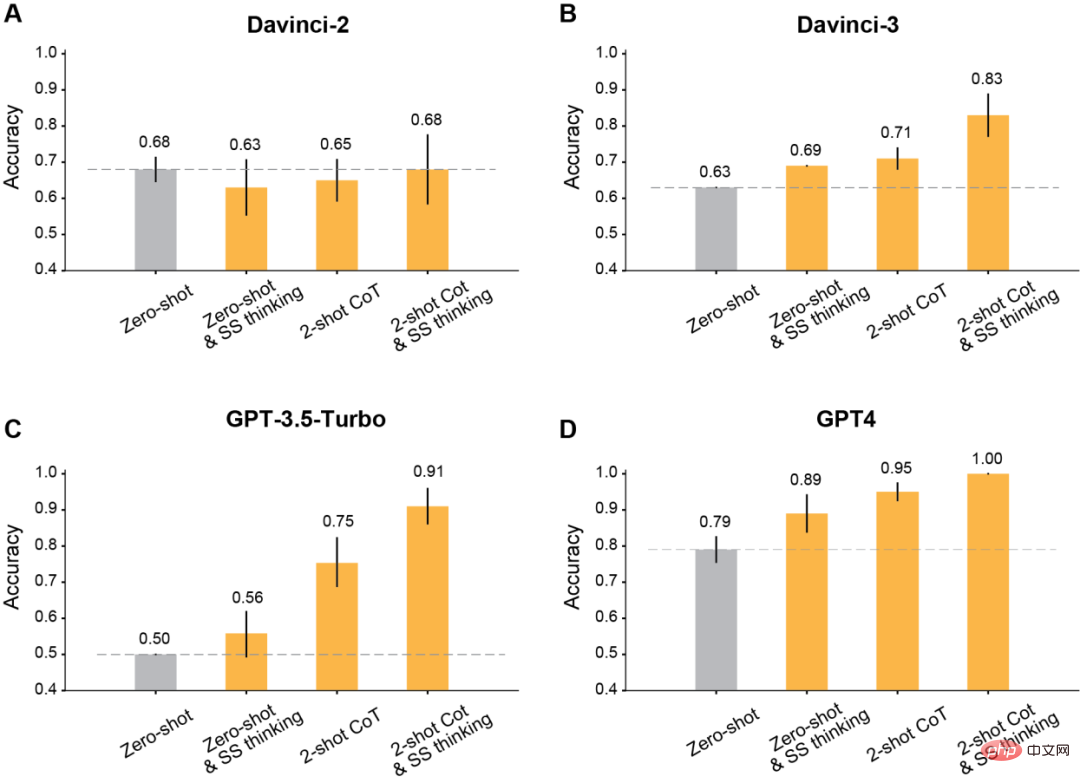
Pengarang ditemui , selepas menggunakan gesaan yang diubah suai untuk pembelajaran konteks, semua model GPT yang dikeluarkan selepas Davinci-2 akan mempunyai peningkatan yang ketara.

Pertama, adalah yang paling klasik untuk membiarkan model berfikir langkah demi langkah.
Hasilnya menunjukkan bahawa pemikiran langkah demi langkah ini meningkatkan prestasi Davinci-3, GPT-3.5-Turbo dan GPT-4, tetapi tidak meningkatkan ketepatan Davinci- 2 .
Kedua, rantaian pemikiran Two-shot (CoT) digunakan untuk penaakulan.
Keputusan menunjukkan bahawa Two-shot CoT meningkatkan ketepatan semua model yang dilatih dengan RLHF (kecuali Davinci-2).
Untuk GPT-3.5-Turbo, pembayang CoT Dua pukulan meningkatkan prestasi model dengan ketara dan lebih berkesan daripada pemikiran satu langkah. Untuk Davinci-3 dan GPT-4, peningkatan yang dibawa dengan menggunakan Two-shot CoT adalah agak terhad.
Akhir sekali, gunakan Two-shot CoT untuk menaakul dan berfikir langkah demi langkah pada masa yang sama.
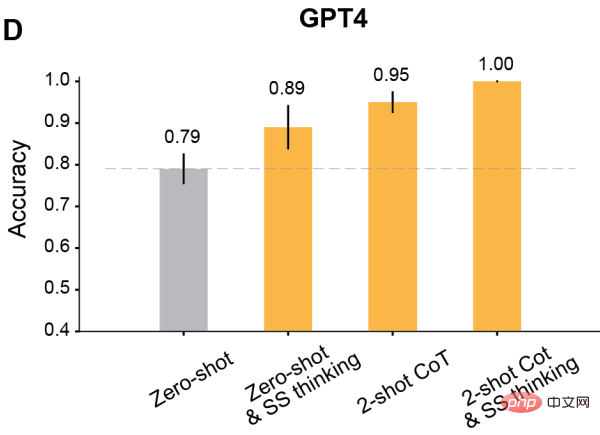
Keputusan menunjukkan bahawa ketepatan ToM semua model terlatih RLHF telah meningkat dengan ketara: Davinci-3 mencapai ketepatan ToM sebanyak 83% (±6%), GPT-3.5- Turbo dicapai 91% (±5%), manakala GPT-4 mencapai ketepatan tertinggi iaitu 100%.
Prestasi manusia dalam keadaan ini ialah 87% (±4%).
Dalam eksperimen, penyelidik mendapati masalah sedemikian: peningkatan skor ujian LLM ToM adalah disebabkan oleh perubahan dari prompt Adakah sebab untuk langkah-langkah penaakulan direplikasi dalam ?
Untuk tujuan ini, mereka cuba menggunakan penaakulan dan contoh foto untuk gesaan, tetapi corak penaakulan dalam contoh kontekstual ini tidak sama dengan corak penaakulan dalam adegan ToM.
Walaupun begitu, prestasi model dalam adegan ToM juga telah bertambah baik.
Oleh itu, para penyelidik menyimpulkan bahawa segera boleh meningkatkan prestasi ToM bukan hanya kerana terlampau pada set langkah inferens khusus yang ditunjukkan dalam contoh CoT.
Sebaliknya, contoh CoT nampaknya menggunakan mod output yang melibatkan inferens langkah demi langkah, yang meningkatkan ketepatan model untuk pelbagai tugas.
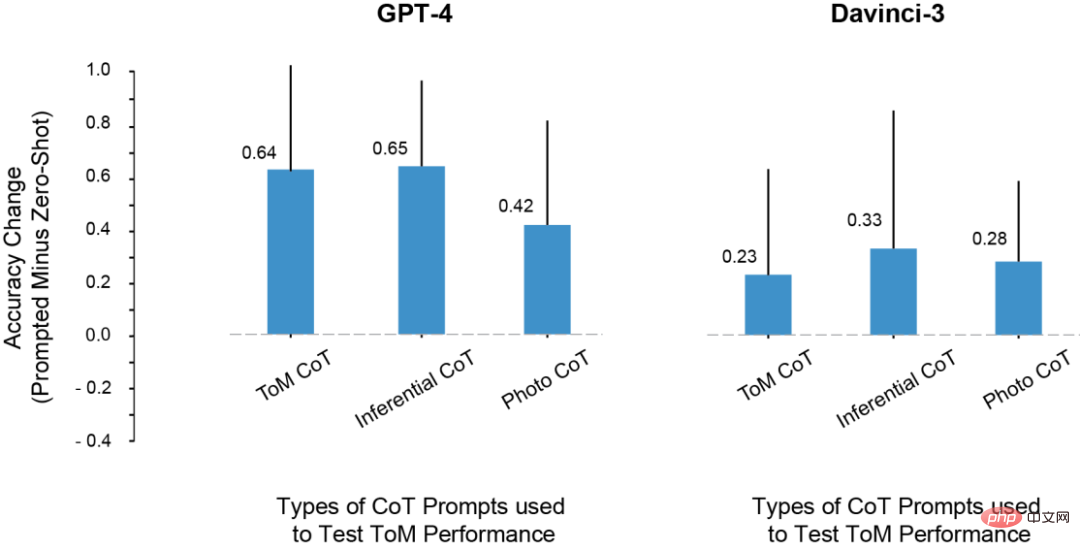
Impak pelbagai contoh CoT pada prestasi ToM
LLM juga akan memberi manusia banyak kejutan
Dalam eksperimen, penyelidik menemui beberapa fenomena yang sangat menarik.
1 Kecuali davincin-2, semua model boleh menggunakan gesaan yang diubah suai untuk mendapatkan ketepatan ToM yang lebih tinggi.
Selain itu, model tersebut menunjukkan peningkatan ketepatan yang paling hebat apabila digabungkan dengan cepat dengan kedua-dua penaakulan rantaian pemikiran dan Fikirkan Langkah demi Langkah, dan bukannya menggunakan kedua-duanya sahaja.
2 Davinci-2 ialah satu-satunya model yang belum diperhalusi oleh RLHF dan satu-satunya model yang tidak meningkatkan prestasi ToM melalui segera. Ini menunjukkan bahawa mungkin RLHF yang membolehkan model memanfaatkan isyarat kontekstual dalam tetapan ini.
3. LLM mungkin mempunyai keupayaan untuk melakukan penaakulan ToM, tetapi mereka tidak boleh mempamerkan keupayaan ini tanpa konteks atau gesaan yang sesuai. Dengan bantuan rantaian pemikiran dan gesaan langkah demi langkah, davincin-3 dan GPT-3.5-Turbo kedua-duanya mencapai prestasi yang lebih tinggi daripada ketepatan ToM sampel sifar GPT-4.
Selain itu, ramai sarjana sebelum ini mempunyai bantahan terhadap penunjuk ini untuk menilai keupayaan penaakulan LLM.
Oleh kerana kajian ini bergantung terutamanya pada penyelesaian perkataan atau soalan aneka pilihan untuk mengukur keupayaan model besar, bagaimanapun, kaedah penilaian ini mungkin tidak menangkap alasan ToM yang LLM mampu lakukan. Kerumitan. Penaakulan ToM ialah tingkah laku yang kompleks yang mungkin melibatkan pelbagai langkah, walaupun apabila dibuat alasan oleh manusia.
Oleh itu, LLM mungkin mendapat manfaat daripada menghasilkan jawapan yang lebih panjang apabila menangani tugasan.
Ada dua sebab: pertama, apabila output model lebih panjang, kita boleh menilai dengan lebih adil. LLM kadangkala menjana "pembetulan" dan kemudian juga menyebut kemungkinan lain yang akan membawanya kepada kesimpulan yang tidak meyakinkan. Sebagai alternatif, model mungkin mempunyai beberapa tahap maklumat tentang kemungkinan hasil sesuatu situasi, tetapi ini mungkin tidak mencukupi untuk membuat kesimpulan yang betul.
Kedua, apabila model diberi peluang dan petunjuk untuk bertindak balas secara sistematik langkah demi langkah, LLM mungkin membuka kunci keupayaan penaakulan baharu atau membenarkan keupayaan penaakulan dipertingkatkan.
Akhir sekali, pengkaji turut merumuskan beberapa kekurangan dalam karya.
Contohnya, dalam model GPT-3.5, kadangkala penaakulannya betul, tetapi model tidak boleh menyepadukan penaakulan ini untuk membuat kesimpulan yang betul. Oleh itu, penyelidikan masa depan harus memperluaskan kajian kaedah (seperti RLHF) untuk membantu LLM membuat kesimpulan yang betul memandangkan langkah penaakulan priori.
Selain itu, dalam kajian semasa, mod kegagalan setiap model tidak dianalisis secara kuantitatif. Bagaimanakah setiap model gagal? Kenapa gagal? Butiran dalam proses ini memerlukan lebih banyak penerokaan dan pemahaman.
Selain itu, data penyelidikan tidak bercakap tentang sama ada LLM mempunyai "keupayaan mental" yang sepadan dengan model logik berstruktur keadaan mental. Tetapi data menunjukkan bahawa meminta LLM untuk jawapan ya/tidak mudah kepada soalan ToM adalah tidak produktif.
Nasib baik, keputusan ini menunjukkan bahawa tingkah laku LLM adalah sangat kompleks dan sensitif konteks, dan juga menunjukkan kepada kita cara membantu LLM dalam beberapa bentuk penaakulan sosial.
Oleh itu, kita perlu mencirikan keupayaan kognitif model besar melalui penyiasatan yang teliti, dan bukannya secara refleks menggunakan ontologi kognitif sedia ada.
Ringkasnya, apabila AI menjadi semakin berkuasa, manusia juga perlu mengembangkan imaginasi mereka untuk memahami keupayaan dan kaedah kerja mereka.
Atas ialah kandungan terperinci 100:87: GPT-4 minda menghancurkan manusia! Tiga varian utama GPT-3.5 sukar untuk dikalahkan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI