
Rumah >Peranti teknologi >AI >DetGPT, yang boleh membaca gambar, berbual, dan melakukan penaakulan dan penentududukan silang mod, berada di sini untuk melaksanakan senario yang rumit.
DetGPT, yang boleh membaca gambar, berbual, dan melakukan penaakulan dan penentududukan silang mod, berada di sini untuk melaksanakan senario yang rumit.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-11 23:28:051325semak imbas
Manusia sentiasa mengimpikan robot yang boleh membantu manusia dalam mengendalikan urusan kehidupan dan pekerjaan. "Tolong bantu saya kurangkan suhu penghawa dingin" dan juga "Tolong bantu saya menulis tapak web pusat beli-belah" semuanya telah direalisasikan dalam beberapa tahun kebelakangan ini dengan pembantu rumah dan Copilot dikeluarkan oleh OpenAI.
Kemunculan GPT-4 seterusnya menunjukkan kepada kita potensi model besar berbilang modal dalam pemahaman visual. Dari segi model bersaiz kecil dan sederhana sumber terbuka, LLAVA dan minigpt-4 berprestasi baik Mereka boleh melihat gambar dan berbual, dan juga boleh meneka resipi dalam gambar makanan untuk manusia. Walau bagaimanapun, model ini masih menghadapi cabaran penting dalam pelaksanaan sebenar: mereka tidak mempunyai keupayaan kedudukan yang tepat, mereka tidak dapat memberikan lokasi tertentu objek dalam gambar, dan mereka tidak dapat memahami arahan manusia yang kompleks untuk mengesan objek tertentu tidak dapat melaksanakan tugas manusia. Dalam senario sebenar, orang ramai menghadapi masalah yang rumit Jika mereka boleh meminta pembantu pintar untuk mendapatkan jawapan yang betul dengan mengambil gambar, fungsi "foto dan tanya" adalah sangat bagus.
Untuk merealisasikan fungsi "foto dan tanya", robot perlu mempunyai pelbagai kebolehan:
1 untuk mendengar Memahami dan memahami niat manusia
2. Keupayaan pemahaman visual: dapat memahami objek dalam gambar yang anda lihat
3. Biasa keupayaan penaakulan deria : Dapat menukar niat manusia yang kompleks kepada sasaran tepat yang boleh diposisikan
4. Keupayaan kedudukan objek: Dapat mengesan dan mengesan objek yang sepadan daripada skrin
Pada masa ini, hanya beberapa model besar (seperti PaLM-E Google) yang memiliki empat keupayaan ini. Walau bagaimanapun, penyelidik dari Universiti Sains dan Teknologi Hong Kong dan Universiti Hong Kong telah mencadangkan model sumber terbuka penuh DetGPT (nama penuh DetectionGPT), yang hanya perlu memperhalusi tiga juta parameter, membolehkan model itu mudah memiliki penaakulan yang kompleks dan setempat. keupayaan kedudukan objek, dan boleh digeneralisasikan kepada skala besar Kebanyakan adegan. Ini bermakna model itu boleh memahami arahan abstrak manusia melalui penaakulan daripada pengetahuannya sendiri dan dengan mudah mengenal pasti objek yang diminati manusia dalam gambar! Mereka telah menjadikan model itu sebagai demo "foto dan soalan" Selamat datang untuk mengalaminya dalam talian: https://detgpt.github.io/
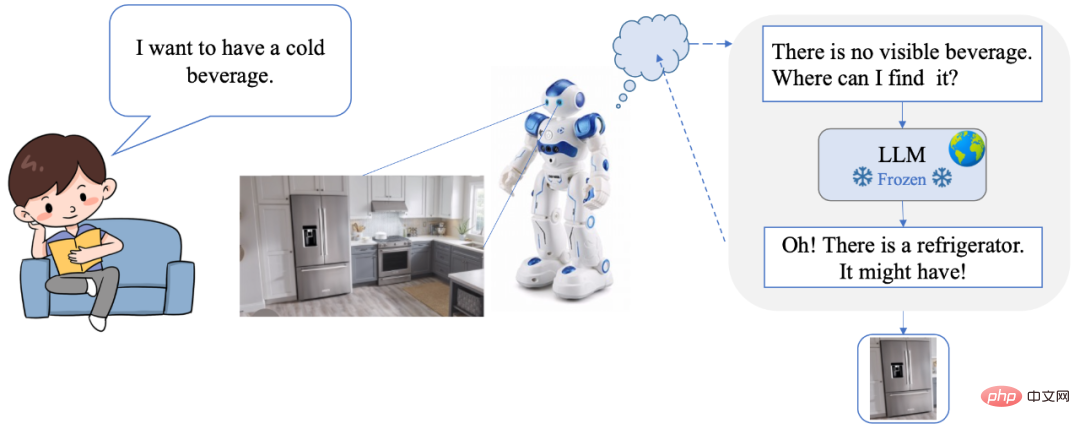
DetGPT membenarkan pengguna mengendalikan segala-galanya dengan semula jadi. bahasa. Memerlukan arahan atau antara muka yang rumit. Pada masa yang sama, DetGPT juga mempunyai penaakulan pintar dan keupayaan pengesanan sasaran, yang boleh memahami dengan tepat keperluan dan niat pengguna. Sebagai contoh, apabila manusia menghantar arahan lisan "Saya mahu minum minuman sejuk", robot mula-mula mencari minuman sejuk di tempat kejadian, tetapi tidak menemuinya. Jadi saya mula berfikir, "Tiada minuman sejuk di tempat kejadian, di mana saya harus mencarinya?" Melalui model penaakulan akal yang kuat, saya memikirkan peti sejuk, jadi saya mengimbas tempat kejadian dan menemui peti sejuk, dan berjaya mengunci lokasi minuman!
- Kod sumber terbuka: https:// www .php.cn/link/10eb6500bd1e4a3704818012a1593cc3
- Percubaan dalam talian demo: https://detgpt.github.io/> Saya dahaga pada musim panas, di manakah minuman ais dalam gambar? DetGPT Mudah difahami Cari peti ais:
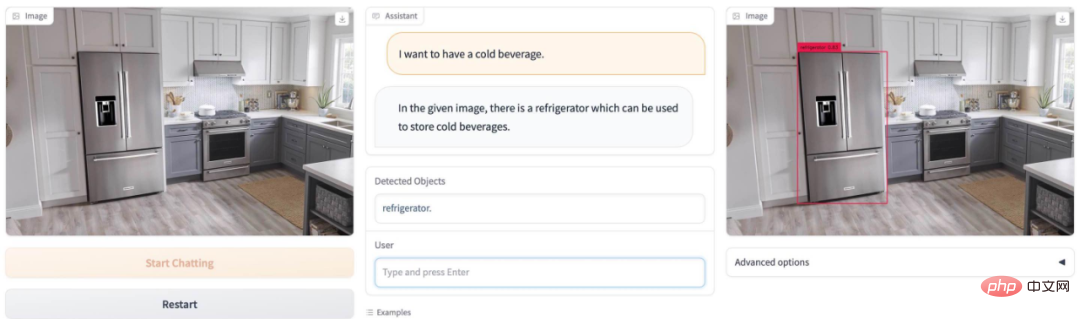 Nak bangun awal esok? DetGPT mudah memilih jam penggera elektronik:
Nak bangun awal esok? DetGPT mudah memilih jam penggera elektronik:
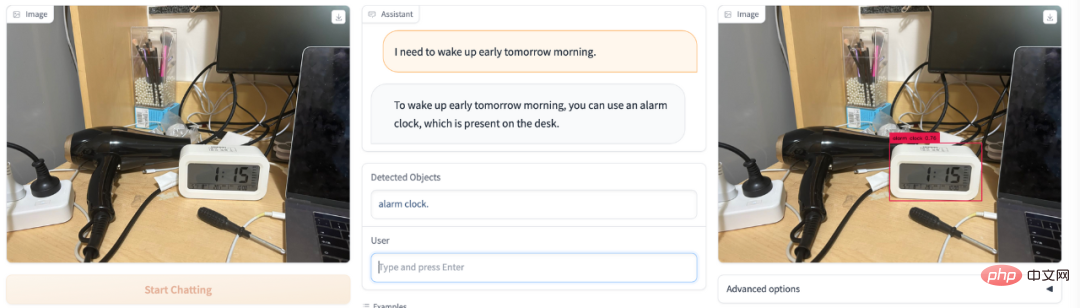 Darah tinggi dan mudah letih? Pergi ke pasar buah-buahan dan tidak tahu buah mana yang hendak dibeli boleh melegakan tekanan darah tinggi? DetGPT bertindak sebagai guru pemakanan anda:
Darah tinggi dan mudah letih? Pergi ke pasar buah-buahan dan tidak tahu buah mana yang hendak dibeli boleh melegakan tekanan darah tinggi? DetGPT bertindak sebagai guru pemakanan anda:
 Tidak dapat mengosongkan permainan Zelda? DetGPT membantu anda melepasi tahap Daughter Kingdom secara menyamar:
Tidak dapat mengosongkan permainan Zelda? DetGPT membantu anda melepasi tahap Daughter Kingdom secara menyamar:
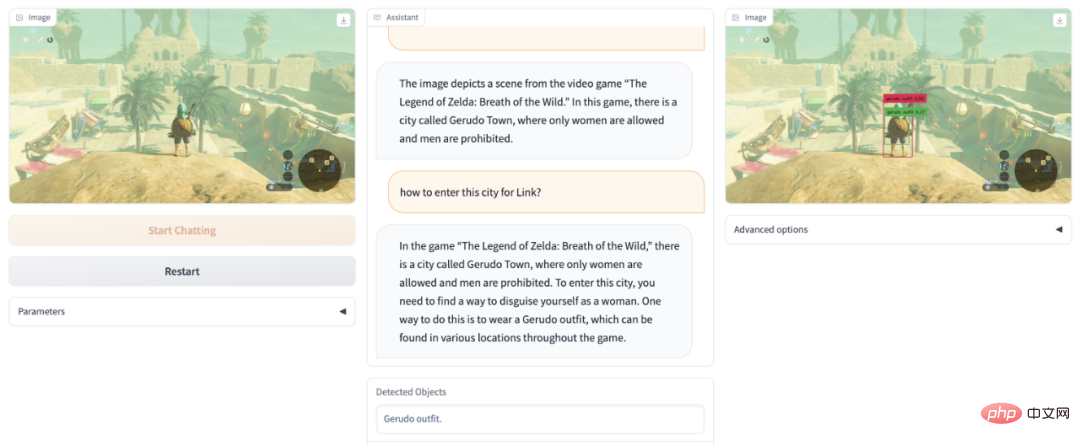
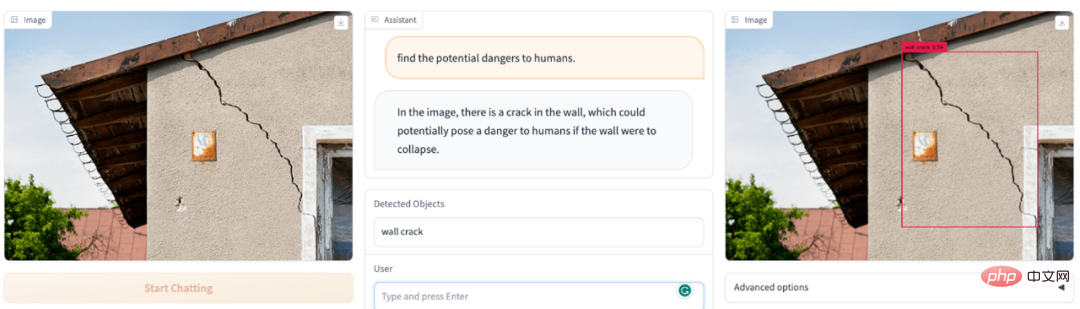
Apakah perkara berbahaya yang terdapat dalam bidang pandangan gambar? DetGPT menjadi pegawai keselamatan anda:
Apakah barang dalam gambar yang berbahaya untuk kanak-kanak? DetGPT masih OK:
Apakah ciri yang ada pada DetGPT?
- Keupayaan untuk memahami objek tertentu dalam gambar telah banyak dipertingkatkan. Berbanding dengan model dialog teks imej berbilang mod sebelumnya, kami boleh mendapatkan dan mencari objek sasaran daripada gambar dengan memahami arahan pengguna, dan bukannya menerangkan keseluruhan gambar.
- Boleh memahami arahan manusia yang kompleks dan menurunkan ambang pengguna untuk bertanya soalan. Sebagai contoh, model boleh memahami masalah "Cari makanan dalam gambar yang boleh mengurangkan tekanan darah tinggi." Pengesanan sasaran tradisional memerlukan jawapan yang diketahui manusia, dan kategori pengesanan "pisang" dipratetap terlebih dahulu.
- DetGPT boleh menaakul berdasarkan pengetahuan LLM sedia ada untuk mengesan objek yang sepadan dengan tepat dalam graf yang boleh menyelesaikan tugasan yang rumit. Untuk tugas yang kompleks seperti "makanan untuk melegakan tekanan darah tinggi." DetGPT boleh menaakul langkah demi langkah untuk tugas yang kompleks ini: Melegakan tekanan darah tinggi -> Kalium boleh melegakan tekanan darah tinggi ->
- Memberi jawapan di luar skop akal budi manusia. Bagi beberapa masalah yang jarang berlaku, seperti manusia tidak mengetahui buah mana yang kaya dengan kalium, model boleh menjawabnya berdasarkan pengetahuan sedia ada.
Arah baharu yang patut diberi perhatian: menggunakan penaakulan akal untuk mencapai pengesanan sasaran set terbuka yang lebih tepat

Tugas pengesanan tradisional memerlukan pratetap kategori objek yang mungkin untuk pengesanan. Tetapi dengan tepat dan menyeluruh menerangkan objek yang akan dikesan adalah tidak mesra atau bahkan tidak realistik untuk manusia. Khususnya, (1) Terhad oleh ingatan/pengetahuan yang terhad, orang tidak boleh sentiasa menyatakan dengan tepat objek sasaran yang mereka ingin kesan. Sebagai contoh, doktor mengesyorkan bahawa orang yang mempunyai tekanan darah tinggi makan lebih banyak buah-buahan untuk menambah kalium, tetapi tanpa mengetahui buah-buahan yang kaya dengan kalium, mereka tidak boleh memberikan nama buah-buahan tertentu untuk dikesan oleh model "Pengenalan buah-buahan" dibuang ke model pengesanan . Manusia hanya perlu mengambil gambar, dan model itu sendiri akan berfikir, menaakul dan mengesan buah-buahan yang kaya dengan kalium. (2) Kategori objek yang boleh dicontohi manusia tidak menyeluruh. Sebagai contoh, jika kita memantau tingkah laku yang tidak mematuhi ketenteraman awam di tempat awam, manusia mungkin hanya boleh menyenaraikan beberapa senario seperti memegang pisau dan merokok tetapi jika kita terus menyerahkan masalah "mengesan tingkah laku yang tidak mematuhi ketenteraman awam" kepada model pengesanan, Jika model itu berfikir dengan sendirinya dan membuat inferens berdasarkan pengetahuannya sendiri, ia boleh menangkap lebih banyak tingkah laku buruk dan membuat generalisasi kepada lebih banyak kategori berkaitan yang perlu dikesan. Lagipun, pengetahuan yang manusia biasa faham adalah terhad, dan jenis objek yang boleh disebut juga terhad. Tetapi jika ada otak seperti ChatGPT untuk bantuan dan penaakulan, arahan yang perlu diberikan oleh manusia akan menjadi lebih mudah, dan. jawapan yang diperolehi Ia juga boleh menjadi lebih tepat dan komprehensif.
Berdasarkan abstraksi dan batasan arahan manusia, penyelidik dari HKUST & HKU mencadangkan arah baharu "pengesanan sasaran inferensi". Ringkasnya, manusia memberikan beberapa tugasan abstrak, dan model boleh memahami dan menaakul dengan sendirinya objek dalam gambar yang boleh menyelesaikan tugas ini, dan mengesannya. Untuk memberikan contoh mudah, apabila manusia menerangkan "Saya mahu minuman sejuk, di mana saya boleh mencarinya", model itu melihat foto dapur, dan ia boleh mengesan "peti sejuk". Topik ini memerlukan gabungan sempurna keupayaan pemahaman imej model berbilang modal dan pengetahuan yang kaya yang disimpan dalam model bahasa yang besar, dan menggunakannya dalam senario tugas pengesanan yang terperinci: menggunakan otak model bahasa untuk memahami arahan abstrak manusia dan dengan tepat cari gambar Objek minat manusia tanpa kategori objek pratetap.
Pengenalan kaedah
"Pengesanan sasaran inferensi" adalah masalah yang sukar, kerana pengesan bukan sahaja perlu memahami dan menaakul tentang arahan berbutir kasar/abstrak pengguna, tetapi juga perlu menganalisis situasi semasa. Lihat maklumat visual untuk mencari objek sasaran. Ke arah ini, penyelidik dari HKUST & HKU telah menjalankan beberapa penerokaan awal. Khususnya, mereka menggunakan pengekod visual terlatih (BLIP-2) untuk mendapatkan ciri visual imej dan menjajarkan ciri visual ke ruang teks melalui fungsi penjajaran. Gunakan model bahasa berskala besar (Robin/Vicuna) untuk memahami soalan pengguna dan menggabungkan maklumat visual yang dilihat untuk menaakul tentang objek yang benar-benar minat pengguna. Nama objek kemudiannya disalurkan kepada pengesan terlatih (Grouding-DINO) untuk ramalan lokasi tertentu. Dengan cara ini, model boleh menganalisis gambar mengikut mana-mana arahan pengguna dan meramalkan lokasi objek yang menarik minat pengguna dengan tepat.
Perlu diperhatikan bahawa kesukaran utama di sini ialah untuk tugasan khusus yang berbeza, model mesti dapat mencapai output khusus tugas tanpa merosakkan keupayaan asal model seperti mungkin. Untuk membimbing model bahasa untuk mengikuti corak tertentu, melakukan penaakulan dan menjana output yang mematuhi format pengesanan sasaran di bawah premis pemahaman imej dan arahan pengguna, pasukan penyelidik menggunakan ChatGPT untuk menjana data arahan silang-modal untuk halus- menala model. Khususnya, berdasarkan 5000 imej coco, mereka memanfaatkan ChatGPT untuk mencipta 30,000 set data penalaan halus teks imej silang mod. Untuk meningkatkan kecekapan latihan, mereka menetapkan parameter model lain dan hanya mempelajari pemetaan linear rentas mod. Keputusan percubaan membuktikan bahawa walaupun hanya lapisan linear diperhalusi, model bahasa boleh memahami ciri imej yang terperinci dan mengikut corak tertentu untuk melaksanakan tugas pengesanan imej berasaskan inferens, menunjukkan prestasi yang cemerlang.
Topik penyelidikan ini mempunyai potensi yang besar. Berdasarkan teknologi ini, bidang robot rumah akan lebih bersinar: orang di rumah boleh menggunakan arahan suara abstrak atau kasar untuk membolehkan robot memahami, mengenal pasti dan mencari item yang diperlukan serta menyediakan perkhidmatan yang berkaitan. Dalam bidang robot perindustrian, teknologi ini akan mempunyai daya hidup yang tidak berkesudahan: robot industri boleh bekerjasama secara lebih semula jadi dengan pekerja manusia, memahami arahan dan keperluan mereka dengan tepat, serta mencapai proses membuat keputusan dan operasi yang bijak. Di barisan pengeluaran, pekerja manusia boleh menggunakan arahan suara berbutir kasar atau input teks untuk membolehkan robot secara automatik memahami, mengenal pasti dan mencari item yang perlu diproses, sekali gus meningkatkan kecekapan dan kualiti pengeluaran.
Berdasarkan model pengesanan sasaran dengan keupayaan penaakulannya sendiri, kami boleh membangunkan robot yang lebih pintar, semula jadi dan cekap untuk menyediakan manusia dengan perkhidmatan yang lebih mudah, cekap dan berperikemanusiaan. Ini adalah kawasan yang mempunyai prospek yang luas. Ia juga memerlukan lebih banyak perhatian penyelidik dan penerokaan lanjut.
Perlu dinyatakan bahawa DetGPT menyokong pelbagai model bahasa dan telah disahkan berdasarkan dua model bahasa: Robin-13B dan Vicuna-13B. Model bahasa siri Robin ialah model dialog yang dilatih oleh pasukan LMFlow Universiti Sains dan Teknologi Hong Kong (https://github.com/OptimalScale/LMFlow Ia telah mencapai keputusan yang setara dengan Vicuna pada tanda aras penilaian kecekapan bahasa berbilang). (muat turun model: https:// github.com/OptimalScale/LMFlow#model-zoo). Heart of the Machine sebelum ini melaporkan bahawa pasukan LMFlow boleh melatih ChatGPT eksklusif hanya dalam masa 5 jam pada kad grafik pengguna 3090. Hari ini, pasukan ini dan Makmal NLP HKU telah membawa satu lagi kejutan pelbagai mod kepada kami.
Atas ialah kandungan terperinci DetGPT, yang boleh membaca gambar, berbual, dan melakukan penaakulan dan penentududukan silang mod, berada di sini untuk melaksanakan senario yang rumit.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI