
Rumah >Peranti teknologi >AI >Mengintegrasikan model siri masa untuk meningkatkan ketepatan ramalan
Mengintegrasikan model siri masa untuk meningkatkan ketepatan ramalan

- PHPzke hadapan
- 2023-05-11 09:10:051113semak imbas
Gunakan Catboost untuk mengekstrak isyarat daripada model RNN, ARIMA dan Nabi untuk ramalan.
Mengintegrasikan pelbagai pelajar lemah boleh meningkatkan ketepatan ramalan, tetapi jika model kami sudah sangat berkuasa, pembelajaran ensemble selalunya boleh menjadi icing pada kek. Pustaka pembelajaran mesin popular scikit-learn menyediakan StackingRegressor yang boleh digunakan untuk tugasan siri masa. Tetapi StackingRegressor mempunyai had; ia hanya menerima kelas dan API model pembelajaran scikit yang lain. Jadi model seperti ARIMA yang tidak tersedia dalam scikit-learn atau model daripada rangkaian neural dalam tidak boleh digunakan. Dalam post ini saya akan tunjukkan cara menyusun ramalan model yang boleh kita lihat.

Kami akan menggunakan pakej berikut:
pip install --upgrade scalecast conda install tensorflow conda install shap conda install -c conda-forge cmdstanpy pip install prophet
Dataset
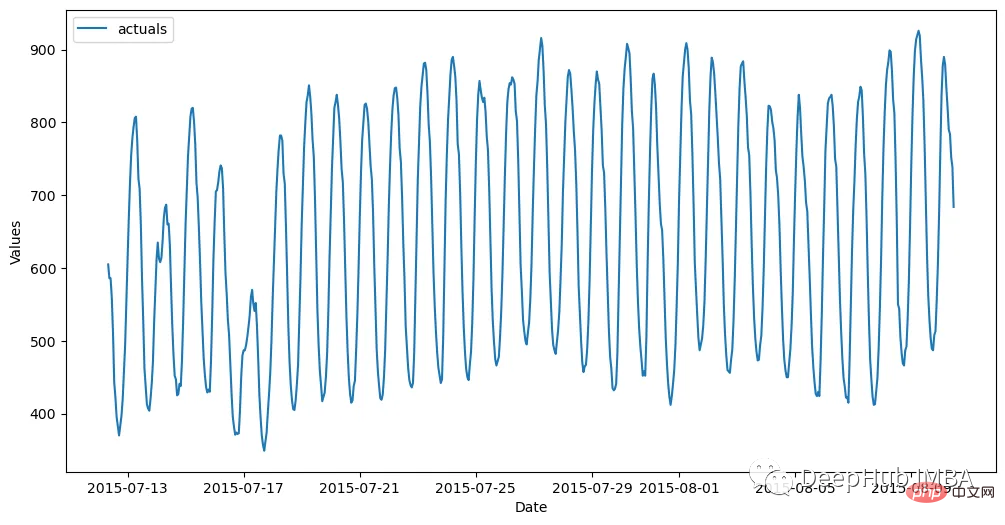
Data set dijana setiap jam dan dibahagikan kepada set latihan (700 pemerhatian) dan set ujian (48 pemerhatian). Kod berikut membaca data dan menyimpannya dalam objek Forecaster:
import pandas as pd import numpy as np from scalecast.Forecaster import Forecaster from scalecast.util import metrics import matplotlib.pyplot as plt import seaborn as sns def read_data(idx = 'H1', cis = True, metrics = ['smape']): info = pd.read_csv( 'M4-info.csv', index_col=0, parse_dates=['StartingDate'], dayfirst=True, ) train = pd.read_csv( f'Hourly-train.csv', index_col=0, ).loc[idx] test = pd.read_csv( f'Hourly-test.csv', index_col=0, ).loc[idx] y = train.values sd = info.loc[idx,'StartingDate'] fcst_horizon = info.loc[idx,'Horizon'] cd = pd.date_range( start = sd, freq = 'H', periods = len(y), ) f = Forecaster( y = y, # observed values current_dates = cd, # current dates future_dates = fcst_horizon, # forecast length test_length = fcst_horizon, # test-set length cis = cis, # whether to evaluate intervals for each model metrics = metrics, # what metrics to evaluate ) return f, test.values f, test_set = read_data() f # display the Forecaster object
Hasilnya seperti ini:
Model
Sebelum kita mula membina model, kita perlu menjana ramalan paling mudah daripadanya. Kaedah naif ialah menyebarkan ke hadapan 24 pemerhatian terkini.
f.set_estimator('naive')
f.manual_forecast(seasonal=True)
Kemudian gunakan ARIMA, LSTM dan Nabi sebagai penanda aras.
ARIMA
Purata Pergerakan Bersepadu Autoregresif ialah teknik siri masa yang popular dan mudah yang menggunakan ketinggalan dan ralat siri untuk meramal masa depannya secara linear. Melalui EDA, kami menentukan bahawa siri ini sangat bermusim. Jadi saya akhirnya memilih untuk menggunakan model tertib ARIMA bermusim (5,1,4) x(1,1,1,24).
f.set_estimator('arima')
f.manual_forecast(
order = (5,1,4),
seasonal_order = (1,1,1,24),
call_me = 'manual_arima',
)
LSTM
Jika ARIMA adalah model siri masa yang agak mudah, maka LSTM adalah salah satu kaedah yang lebih maju. Ia ialah teknik pembelajaran mendalam dengan banyak parameter, termasuk mekanisme untuk menemui corak jangka panjang dan jangka pendek dalam data berjujukan, yang secara teorinya menjadikannya sesuai untuk siri masa. Di sini sedang membina model ini menggunakan aliran tensor
f.set_estimator('rnn')
f.manual_forecast(
lags = 48,
layers_struct=[
('LSTM',{'units':100,'activation':'tanh'}),
('LSTM',{'units':100,'activation':'tanh'}),
('LSTM',{'units':100,'activation':'tanh'}),
],
optimizer = 'Adam',
epochs = 15,
plot_loss = True,
validation_split=0.2,
call_me = 'rnn_tanh_activation',
)
f.manual_forecast(
lags = 48,
layers_struct=[
('LSTM',{'units':100,'activation':'relu'}),
('LSTM',{'units':100,'activation':'relu'}),
('LSTM',{'units':100,'activation':'relu'}),
],
optimizer = 'Adam',
epochs = 15,
plot_loss = True,
validation_split=0.2,
call_me = 'rnn_relu_activation',
)
Nabi
Walaupun popular, ada yang mendakwa bahawa ketepatannya tidak mengagumkan, terutamanya kerana Ekstrapolasi arah aliran kadangkala tidak realistik, dan ia tidak mengambil kira corak tempatan melalui pemodelan autoregresif. Tetapi ia juga mempunyai ciri tersendiri. 1. Ia secara automatik menggunakan kesan percutian pada model dan juga mengambil kira beberapa jenis bermusim. Ini semua boleh dilakukan dengan minimum yang diperlukan oleh pengguna, jadi saya suka menggunakannya sebagai isyarat dan bukannya ramalan akhir.
f.set_estimator('prophet')
f.manual_forecast()
Membandingkan Keputusan
Sekarang kami telah menjana ramalan untuk setiap model, mari lihat prestasinya pada set pengesahan, yang kami latih pada 48 pemerhatian terakhir dalam set itu.
results = f.export(determine_best_by='TestSetSMAPE') ms = results['model_summaries'] ms[ [ 'ModelNickname', 'TestSetLength', 'TestSetSMAPE', 'InSampleSMAPE', ] ]
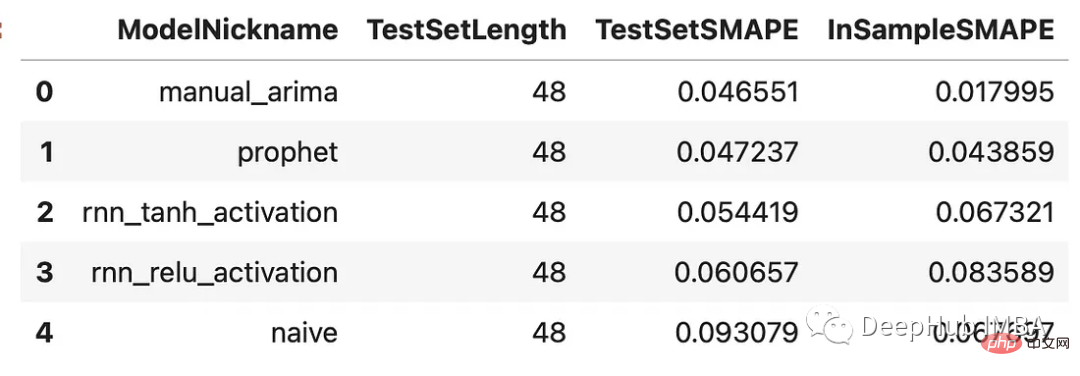
Setiap model mengatasi kaedah naif. Model ARIMA menunjukkan prestasi terbaik dengan peratusan ralat sebanyak 4.7%, diikuti oleh model Nabi. Mari lihat semua ramalan berbanding set pengesahan: Persembahan semuanya munasabah, tanpa sisihan besar antara mereka. Mari susun mereka!
Model Bertindan
Setiap model bertindan memerlukan penganggar akhir yang akan menapis pelbagai anggaran daripada model lain, mencipta set ramalan baharu. Kami akan menindih hasil sebelumnya dengan penganggar Catboost. Catboost ialah program berkuasa yang diharapkan dapat menyempurnakan isyarat terbaik daripada setiap model yang telah digunakan.

f.plot(order_by="TestSetSMAPE",ci=True) plt.show()Kod di atas menambah ramalan daripada setiap model yang dinilai pada objek Peramal. Ia memanggil ramalan ini sebagai "isyarat." Mereka dilayan sama seperti mana-mana kovariat lain yang disimpan dalam objek yang sama. 48 siri lag terakhir juga ditambahkan di sini sebagai regressor tambahan yang boleh digunakan oleh model Catboost untuk membuat ramalan. Sekarang mari kita panggil tiga model Catboost: satu menggunakan semua isyarat dan ketinggalan yang tersedia, satu menggunakan isyarat sahaja dan satu hanya menggunakan ketinggalan.
f.add_signals(
f.history.keys(), # add signals from all previously evaluated models
)
f.add_ar_terms(48)
f.set_estimator('catboost')Di bawah anda boleh membandingkan keputusan semua model. Kami akan melihat dua metrik: SMAPE dan min ralat skala mutlak (MASE). Ini adalah dua metrik yang digunakan dalam pertandingan M4 sebenar. f.manual_forecast(
Xvars='all',
call_me='catboost_all_reg',
verbose = False,
)
f.manual_forecast(
Xvars=[x for x in f.get_regressor_names() if x.startswith('AR')],
call_me = 'catboost_lags_only',
verbose = False,
)
f.manual_forecast(
Xvars=[x for x in f.get_regressor_names() if not x.startswith('AR')],
call_me = 'catboost_signals_only',
verbose = False,
)
可以看到,通过组合来自不同类型模型的信号生成了两个优于其他估计器的估计器:使用所有信号训练的Catboost模型和只使用信号的Catboost模型。这两种方法的样本误差都在2.8%左右。下面是对比图:
fig, ax = plt.subplots(figsize=(12,6)) f.plot( models = ['catboost_all_reg','catboost_signals_only'], ci=True, ax = ax ) sns.lineplot( x = f.future_dates, y = test_set, ax = ax, label = 'held out actuals', color = 'darkblue', alpha = .75, ) plt.show()

哪些信号最重要?
为了完善分析,我们可以使用shapley评分来确定哪些信号是最重要的。Shapley评分被认为是确定给定机器学习模型中输入的预测能力的最先进的方法之一。得分越高,意味着输入在特定模型中越重要。
f.export_feature_importance('catboost_all_reg')

上面的图只显示了前几个最重要的预测因子,但我们可以从中看出,ARIMA信号是最重要的,其次是序列的第一个滞后,然后是Prophet。RNN模型的得分也高于许多滞后模型。如果我们想在未来训练一个更轻量的模型,这可能是一个很好的起点。
总结
在这篇文章中,我展示了在时间序列上下文中集成模型的力量,以及如何使用不同的模型在时间序列上获得更高的精度。这里我们使用scalecast包,这个包的功能还是很强大的,如果你喜欢,可以去它的主页看看:https://github.com/mikekeith52/scalecast
本文的数据集是M4的时序竞赛:https://github.com/Mcompetitions/M4-methods
使用代码在这里:https://scalecast-examples.readthedocs.io/en/latest/misc/stacking/custom_stacking.html
Atas ialah kandungan terperinci Mengintegrasikan model siri masa untuk meningkatkan ketepatan ramalan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI