
Rumah >pembangunan bahagian belakang >Tutorial Python >Cara menggunakan python untuk melaksanakan fungsi pengecaman pertuturan di bawah Linux
Cara menggunakan python untuk melaksanakan fungsi pengecaman pertuturan di bawah Linux

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-11 08:04:051751semak imbas
Pengenalan kepada cara pengecaman pertuturan berfungsi
Pengecaman pertuturan berasal daripada penyelidikan yang dilakukan di Bell Labs pada awal 1950-an. Sistem pengecaman pertuturan awal hanya boleh mengecam seorang pembesar suara dan perbendaharaan kata hanya kira-kira sedozen perkataan. Sistem pengecaman pertuturan moden telah berjalan jauh untuk mengenali berbilang pembesar suara dan mempunyai perbendaharaan kata yang besar yang mengenali berbilang bahasa.
Bahagian pertama pengecaman pertuturan sudah tentu pertuturan. Melalui mikrofon, pertuturan ditukar daripada bunyi fizikal kepada isyarat elektrik, dan kemudian kepada data melalui penukar analog-ke-digital. Setelah didigitalkan, beberapa model boleh digunakan untuk menyalin audio kepada teks.
Kebanyakan sistem pengecaman pertuturan moden bergantung pada Hidden Markov Models (HMM). Prinsip kerjanya ialah: isyarat pertuturan boleh dianggarkan sebagai proses pegun pada skala masa yang sangat singkat (seperti 10 milisaat), iaitu proses yang ciri statistiknya tidak berubah mengikut masa.
Banyak sistem pengecaman pertuturan moden menggunakan rangkaian saraf sebelum pengecaman HMM untuk memudahkan isyarat pertuturan melalui transformasi ciri dan teknik pengurangan dimensi. Pengesan aktiviti suara (VAD) juga boleh digunakan untuk mengurangkan isyarat audio kepada bahagian yang mungkin hanya mengandungi pertuturan.
Nasib baik untuk pengguna Python, beberapa perkhidmatan pengecaman pertuturan tersedia dalam talian melalui API, dan kebanyakannya turut menyediakan SDK Python.
Pilih pakej pengecaman pertuturan python yang sesuai
Terdapat beberapa pakej pengecaman pertuturan siap sedia dalam PyPI. Ini termasuk:
apiai
google-cloud-speech
pocketsphinx
SpeechRcognition
watson-developer-cloud
wit
Sesetengah pakej (seperti kecerdasan dan apiai) menyediakan beberapa Built -dalam keupayaan di luar pengecaman pertuturan asas, seperti pemprosesan bahasa semula jadi untuk mengenal pasti niat penutur. Pakej perisian lain, seperti Google Cloud Speech, memfokuskan pada penukaran pertuturan ke teks.
Antaranya, SpeechRecognition menonjol kerana kemudahan penggunaannya.
Mengecam pertuturan memerlukan input audio dan mendapatkan semula input audio dalam Pengecaman Pertuturan adalah sangat mudah. Ia tidak memerlukan membina skrip untuk mengakses mikrofon dan memproses fail audio dari awal. Ia hanya mengambil masa beberapa minit untuk melengkapkan pengambilan dan jalankan secara automatik.
Pasang SpeechRecognition
SpeechRecognition serasi dengan Python2.6, 2.7 dan 3.3+, tetapi beberapa langkah pemasangan tambahan diperlukan jika digunakan dalam Python 2. Anda boleh menggunakan arahan pip untuk memasang SpeechRecognition dari terminal: pip3 install SpeechRecognition
Selepas pemasangan selesai, anda boleh membuka tetingkap penterjemah untuk mengesahkan pemasangan:

Nota : Jangan tutup sesi ini, anda akan menggunakannya dalam beberapa langkah seterusnya.
Jika berurusan dengan fail audio sedia ada, hubungi SpeechRecognition terus, memberi perhatian kepada beberapa kebergantungan untuk kes penggunaan tertentu. Juga ambil perhatian, pasang pakej PyAudio untuk mendapatkan input mikrofon
Kelas Pengecam
Teras SpeechRecognition ialah kelas pengecam.
Tujuan utama API Pengecam adalah untuk mengenali pertuturan Setiap API mempunyai pelbagai tetapan dan fungsi untuk mengecam pertuturan sumber audio Di sini saya memilih recognizer(): CMU Sphinx - memerlukan pemasangan PocketSphinx (menyokong Pengecaman pertuturan luar talian ) Kemudian kita perlu memasang PocketSphinx melalui arahan pip Semasa proses pemasangan, sejumlah besar ralat dalam fon merah juga cenderung berlaku.
Nota:
Kelas AudioFile boleh digunakan melalui laluan fail audio Memulakan dan menyediakan antara muka pengurus konteks untuk membaca dan memproses kandungan fail.
SpeechRecognition pada masa ini menyokong jenis fail:
- WAV: mestilah dalam format PCM/LPCM
- AIFF
- AIFF-CFLAC: mestilah format FLAC awal; format OGG-FLAC tidak tersedia
(1) Buka terminal
(2) Masukkan direktori di mana fail ujian suara terletak (penulis blog ialah desktop)
(3) Buka penterjemah python
(4) Masukkan arahan yang berkaitan seperti yang ditunjukkan di bawah
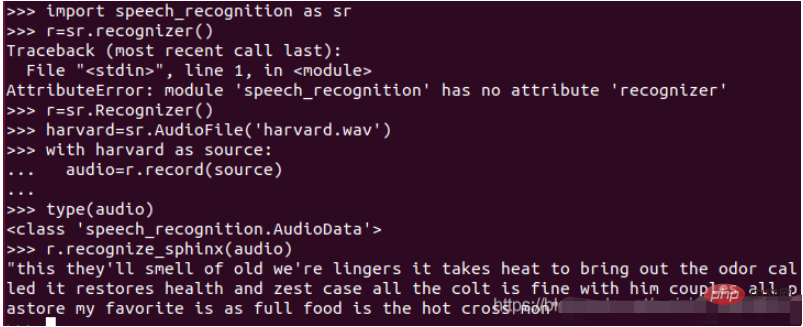
Dengan cuba menyalin kesan yang tidak baik, kita boleh cuba memanggil perintah adjust_for_ambient_noise() kelas Recognizer.
Penggunaan mikrofon
Untuk menggunakan SpeechRecognizer untuk mengakses mikrofon, anda mesti memasang pakej PyAudio.
Jika anda menggunakan Linux berasaskan Debian (seperti Ubuntu), anda boleh menggunakan apt untuk memasang PyAudio: sudo apt-get install python-pyaudio python3-pyaudioAnda mungkin masih perlu mendayakan pip3 install pyaudio selepas pemasangan selesai, terutamanya jika dijalankan dalam keadaan maya.
Selepas memasang pyaudio, anda boleh menggunakan python untuk melaksanakan rakaman suara dan menjana fail berkaitan.
Nota tentang penggunaan pocketsphinx:
Format fail yang disokong: wav
Keperluan penyahkodan untuk fail audio: 16KHZ, mono
Gunakan python untuk merakam dan menjana fail yang berkaitan Kod program adalah seperti berikut:
from pyaudio import PyAudio, paInt16
import numpy as np
import wave
class recoder:
NUM_SAMPLES = 2000
SAMPLING_RATE = 16000
LEVEL = 500
COUNT_NUM = 20
SAVE_LENGTH = 8
Voice_String = []
def savewav(self,filename):
wf = wave.open(filename, 'wb')
wf.setnchannels(1)
wf.setsampwidth(2)
wf.setframerate(self.SAMPLING_RATE)
wf.writeframes(np.array(self.Voice_String).tostring())
wf.close()
def recoder(self):
pa = PyAudio()
stream = pa.open(format=paInt16, channels=1, rate=self.SAMPLING_RATE, input=True,frames_per_buffer=self.NUM_SAMPLES)
save_count = 0
save_buffer = []
while True:
string_audio_data = stream.read(self.NUM_SAMPLES)
audio_data = np.fromstring(string_audio_data, dtype=np.short)
large_sample_count = np.sum(audio_data > self.LEVEL)
print(np.max(audio_data))
if large_sample_count > self.COUNT_NUM:
save_count = self.SAVE_LENGTH
else:
save_count -= 1
if save_count < 0:
save_count = 0
if save_count > 0:
save_buffer.append(string_audio_data )
else:
if len(save_buffer) > 0:
self.Voice_String = save_buffer
save_buffer = []
print("Recode a piece of voice successfully!")
return True
else:
return False
if __name__ == "__main__":
r = recoder()
r.recoder()
r.savewav("test.wav")Nota: Pastikan anda memberi perhatian kepada ruang apabila melaksanakan menggunakan penterjemah python! ! !
Fail hasil akhir berada dalam direktori tempat penterjemah Python berada Anda boleh memainkannya melalui main untuk mengujinya Jika main tidak dipasang, anda boleh memasangnya melalui arahan apt.
Pengecaman pertuturan bahasa Cina
Selepas menyiapkan kerja sebelumnya, kami mempunyai pemahaman tertentu tentang proses pengecaman pertuturan, tetapi sebagai orang Cina, kami perlu melakukan pengecaman pertuturan bahasa Cina.
Kami perlu memuat turun model kemasukan dan bahasa Mandarin yang sepadan daripada kit alat pengecaman pertuturan CMU Sphinx.
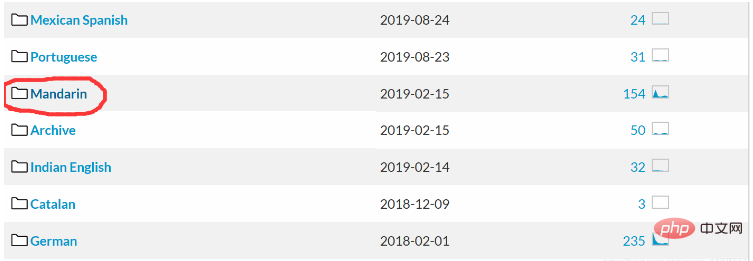
Perkataan yang ditanda dalam gambar adalah bahasa Mandarin! Muat turun kit alat pengecaman pertuturan yang berkaitan.
Tetapi kita perlu menukar zh_broadcastnews_64000_utf8.DMP ke dalam language-model.lm.bin dan kemudian nyahzip zh_broadcastnews_16k_ptm256_8000.tar.bz2 untuk mendapatkan folder _zh00broadcast6_zh00m
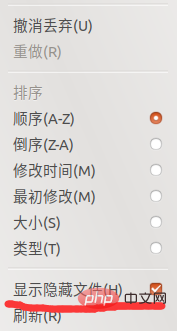
Belajar daripada kaedah blogger tadi dan cari folder speech_recognition di bawah Ubuntu. Mungkin terdapat ramai rakan yang tidak dapat mencari folder yang berkaitan, tetapi mereka sebenarnya berada di bawah fail tersembunyi. Anda boleh mengklik pada tiga bar di sudut kanan atas folder. Seperti yang ditunjukkan dalam gambar di bawah:

Kemudian tandai Tunjukkan fail tersembunyi, seperti yang ditunjukkan dalam gambar di bawah:
Kemudian Anda boleh mencarinya dengan mengikuti direktori berikut:

Kemudian namakan semula en-US asal kepada en-US-bak, buat folder baharu en-US dan nyahzip kepada zh_broadcastnews_ptm256_8000, tukar acoustic-model kepada chinese.lm.bin, tukar akhiran language-model.lm.bin kepada pronounciation-dictionary.dic dan salin ketiga-tiga fail ini ke en-US. Pada masa yang sama, salin LICENSE.txt dalam direktori fail en-US asal ke folder semasa. dictAkhir sekali, terdapat fail berikut dalam folder ini:
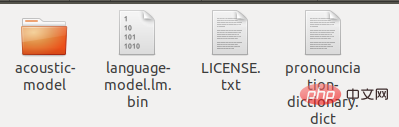
Dalam ini Buka penterjemah python dalam direktori fail dan masukkan kandungan berikut:
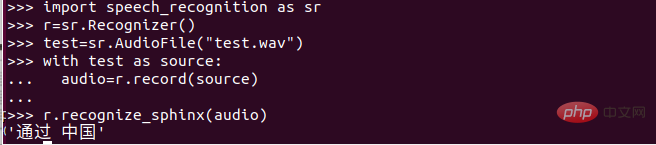
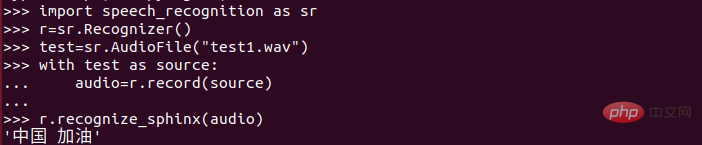
Cari 4 folder yang baru anda salin. Terdapat folder sebutan-kamus.dict Selepas membukanya, kandungan berikut ditemui:

Pendekatan saya ialah:
(1) Simpan kandungan di atas tanda merah dalam gambar, dan padamkan kandungan di bawah tanda merah. Sudah tentu, atas sebab insurans, anda disyorkan untuk membuat sandaran fail ini!
(2) Masukkan kandungan yang anda ingin kenal pasti di bawah garis merah! (Input mengikut peraturan, berbeza dengan pinyin!!!) Situasi radang paru-paru baru semakin baik baru-baru ini Ayat yang paling banyak didengar ialah "Ayuh, China". teks! Harap-harap sekolah boleh mula cepat, hahahaha.

Sintesis pertuturan
Pemahaman peribadi saya tentang sintesis pertuturan ialah teks ke pertuturan. Walau bagaimanapun, anda boleh menetapkan client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) result = client.synthesis('你好百度', 'zh', 1, { 'vol': 5,'spd': 3,'pit':9,'per': 3}) kelantangan, nada, kelajuan, lelaki/perempuan/loli/percuma dalam ayat ini.
Atas ialah kandungan terperinci Cara menggunakan python untuk melaksanakan fungsi pengecaman pertuturan di bawah Linux. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!