
Rumah >Peranti teknologi >AI >Qingbei Microsoft mendalami GPT dan memahami pembelajaran kontekstual! Ia pada asasnya sama seperti penalaan halus, kecuali parameter tidak berubah.
Qingbei Microsoft mendalami GPT dan memahami pembelajaran kontekstual! Ia pada asasnya sama seperti penalaan halus, kecuali parameter tidak berubah.

- 王林ke hadapan
- 2023-05-10 21:37:041092semak imbas
Salah satu ciri penting model bahasa pra-latihan berskala besar ialah keupayaan Pembelajaran Dalam Konteks (ICL), iaitu, melalui beberapa pasangan label input teladan, anda boleh belajar tanpa mengemas kini parameter Baharu label input diramalkan.
Walaupun prestasi telah bertambah baik, dari mana datangnya keupayaan ICL model besar masih menjadi persoalan terbuka.
Untuk lebih memahami cara ICL berfungsi, penyelidik dari Universiti Tsinghua, Universiti Peking dan Microsoft bersama-sama menerbitkan kertas kerja yang mentafsir model bahasa sebagai pengoptimum meta (pengoptimum meta), dan memahami ICL sebagai penalaan halus yang tersirat.

Pautan kertas: https://arxiv.org/abs/2212.10559
Secara teorinya, artikel ini menjelaskan bahawa terdapat dua bentuk dalam perhatian Transformer berdasarkan pengoptimuman keturunan kecerunan, dan berdasarkan ini, pemahaman ICL adalah seperti berikut. GPT mula-mula menjana kecerunan meta berdasarkan kejadian tunjuk cara, dan kemudian menggunakan kecerunan meta ini pada GPT asal untuk membina model ICL.
Dalam eksperimen, penyelidik membandingkan secara komprehensif tingkah laku ICL dan penalaan halus yang jelas berdasarkan tugas sebenar untuk memberikan bukti empirikal yang menyokong pemahaman ini.
Hasilnya membuktikan bahawa ICL berprestasi serupa dengan penalaan halus yang jelas pada tahap ramalan, tahap perwakilan dan tahap tingkah laku perhatian.
Di samping itu, diilhamkan oleh pemahaman pengoptimuman meta, melalui analogi dengan algoritma penurunan kecerunan berasaskan momentum, artikel itu juga mereka bentuk perhatian berasaskan momentum , berbanding Perhatian biasa mempunyai prestasi yang lebih baik, yang sekali lagi menyokong ketepatan pemahaman ini dari aspek lain, dan juga menunjukkan potensi menggunakan pemahaman ini untuk mereka bentuk model lagi.
Prinsip ICL
Penyelidik mula-mula menjalankan analisis kualitatif mekanisme perhatian linear dalam Transformer untuk mengetahui perbezaan antaranya dan pengoptimuman berasaskan kecerunan bentuk. ICL kemudiannya dibandingkan dengan penalaan halus yang jelas dan pautan diwujudkan antara kedua-dua bentuk pengoptimuman ini.
Perhatian pengubah ialah pengoptimuman meta
Biar X menjadi perwakilan input bagi keseluruhan pertanyaan dan X' ialah contoh Pencirian, q ialah vektor pertanyaan, kemudian di bawah tetapan ICL, hasil perhatian kepala dalam model adalah seperti berikut:
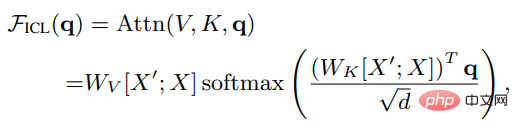
Seperti yang anda lihat, penskalaan dikeluarkan Selepas pemfaktoran akar d dan softmax, mekanisme perhatian standard boleh dianggarkan sebagai:
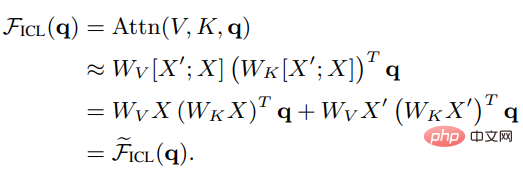
Tetapkan Wzsl kepada Zero-Shot Learning (ZSL) Selepas parameter awal, perhatian Transformer boleh ditukar kepada bentuk dwi berikut:
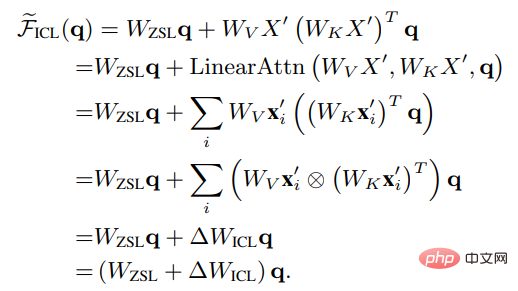
Dapat dilihat bahawa ICL boleh ditafsirkan sebagai proses pengoptimuman meta (meta-optimization):
1 Gunakan model bahasa yang telah dilatih berdasarkan Transformer sebagai pengoptimum meta; 🎜>
2. Melalui pengiraan Arah positif, hitung kecerunan meta berdasarkan contoh tunjuk cara; kepada model bahasa asal untuk mewujudkan model ICL.ICL dan perbandingan penalaan halus
Untuk membandingkan pengoptimuman meta dan pengoptimuman eksplisit ICL, penyelidik mereka bentuk tetapan penalaan halus khusus sebagai garis dasar untuk perbandingan: mempertimbangkan ICL Ia hanya memberi kesan langsung kepada kunci dan nilai perhatian, jadi penalaan halus hanya mengemas kini parameter unjuran kunci dan nilai.
Begitu juga dalam bentuk perhatian linear yang tidak ketat, hasil perhatian kepala yang ditala halus boleh dinyatakan sebagai:
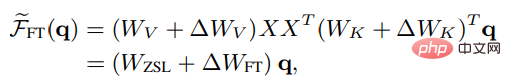
Untuk membuat perbandingan yang lebih adil dengan ICL, sekatan tetapan penalaan halus telah ditetapkan lagi seperti berikut dalam percubaan:
1 Nyatakan contoh latihan sebagai contoh tunjuk cara untuk ICL; 🎜>3. Gunakan yang digunakan oleh ICL Templat memformat setiap contoh latihan dan memperhalusinya menggunakan objektif pemodelan bahasa kausal.
Selepas perbandingan, boleh didapati bahawa ICL dan penalaan halus mempunyai banyak atribut biasa
, terutamanya termasuk empat aspek.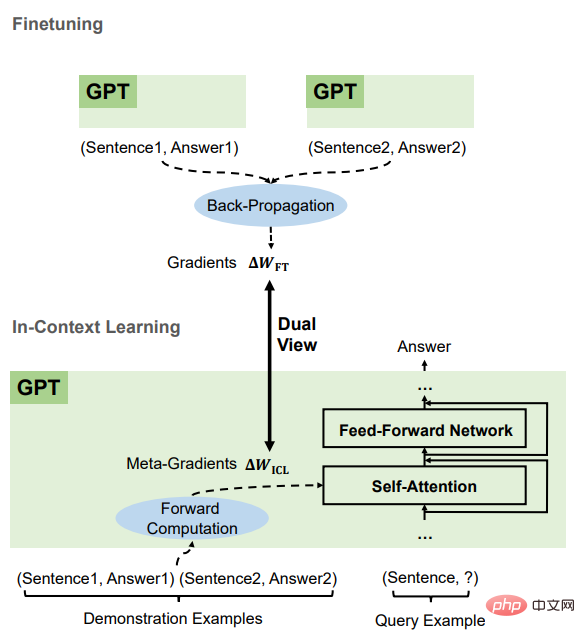
Kedua-duanya adalah keturunan kecerunan
Ia boleh didapati bahawa kedua-dua ICL dan fine- penalaan dilakukan pada Kemas Kini Wzsl, iaitu keturunan kecerunan, satu-satunya perbezaan ialah ICL menghasilkan kecerunan meta melalui pengiraan ke hadapan, manakala penalaan halus memperoleh kecerunan sebenar melalui perambatan belakang.
Maklumat latihan yang sama
Meta-gradient ICL diperolehi berdasarkan contoh demonstrasi, kecerunan penalaan halus juga diperoleh daripada sampel latihan yang sama, iaitu, ICL dan penalaan halus berkongsi sumber maklumat latihan yang sama.
Susunan sebab akibat bagi contoh latihan adalah sama
ICL dan halus- contoh latihan perkongsian penalaan Untuk susunan sebab, ICL menggunakan Transformer penyahkod sahaja, jadi token seterusnya dalam contoh tidak akan menjejaskan token sebelumnya untuk penalaan halus, kerana susunan contoh latihan adalah sama dan hanya satu zaman dilatih , token seterusnya juga boleh dijamin Sampel tidak mempunyai kesan ke atas sampel sebelumnya.
semua bertindak atas perhatian
Berbanding dengan pembelajaran sifar pukulan, ICL The direct kesan penalaan halus dan penalaan halus adalah terhad kepada pengiraan kunci dan nilai dalam perhatian. Untuk ICL, parameter model tidak berubah, dan ia mengekod maklumat contoh ke dalam kunci dan nilai tambahan untuk mengubah tingkah laku perhatian untuk batasan yang diperkenalkan dalam penalaan halus, maklumat latihan hanya boleh menjejaskan unjuran kunci perhatian dan nilai dalam matriks. Berdasarkan ciri umum antara ICL dan penalaan halus ini, para penyelidik percaya bahawa adalah munasabah untuk memahami ICL sebagai sejenis penalaan halus tersirat.
Bahagian eksperimen
Tugasan dan set data
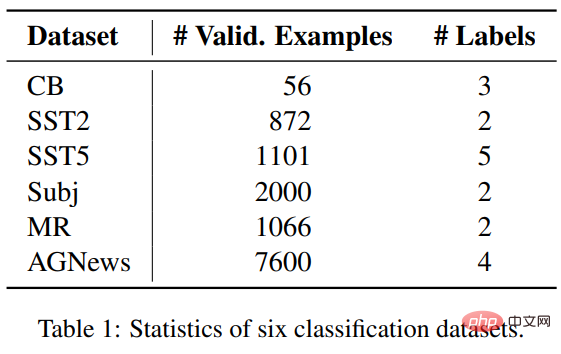
Data Penyelidik Enam set merentas tiga tugas klasifikasi telah dipilih untuk membandingkan ICL dan penalaan halus, termasuk empat set data SST2, SST-5, MR dan Subj untuk klasifikasi sentimen AGNews ialah set data klasifikasi topik CB digunakan untuk penaakulan bahasa Semulajadi;
Tetapan eksperimen
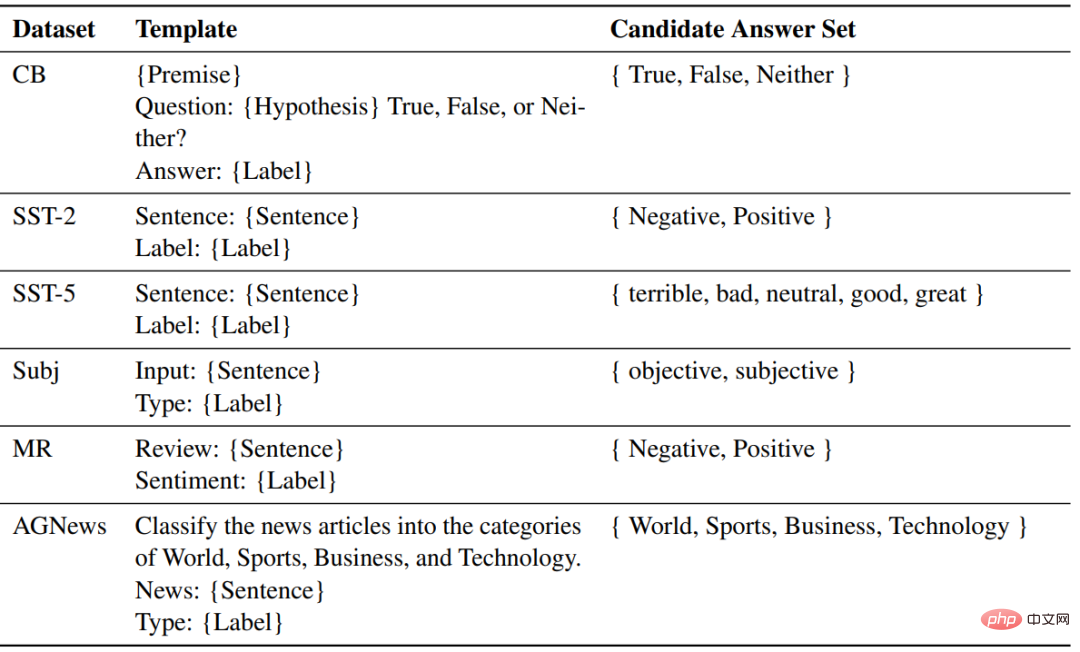
Bahagian model yang digunakan Dua model bahasa pra-latihan yang serupa dengan GPT telah dikeluarkan oleh fairseq, dengan saiz parameter masing-masing 1.3B dan 2.7B Untuk setiap tugasan, templat yang sama digunakan untuk ZSL, ICL. dan sampel yang diperhalusi untuk pemformatan.
Keputusan
Kadar ketepatan
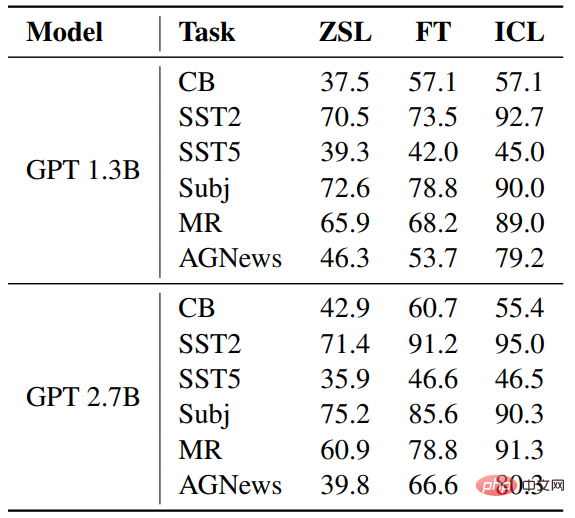
Berbanding dengan ZSL, kedua-dua ICL dan penalaan halus telah mencapai peningkatan yang ketara, yang bermakna pengoptimuman mereka akan membantu tugasan hiliran ini. Tambahan pula, ICL adalah lebih baik daripada penalaan halus dalam beberapa kes.
Rec2FTP (Recall to Finetuning Predictions)
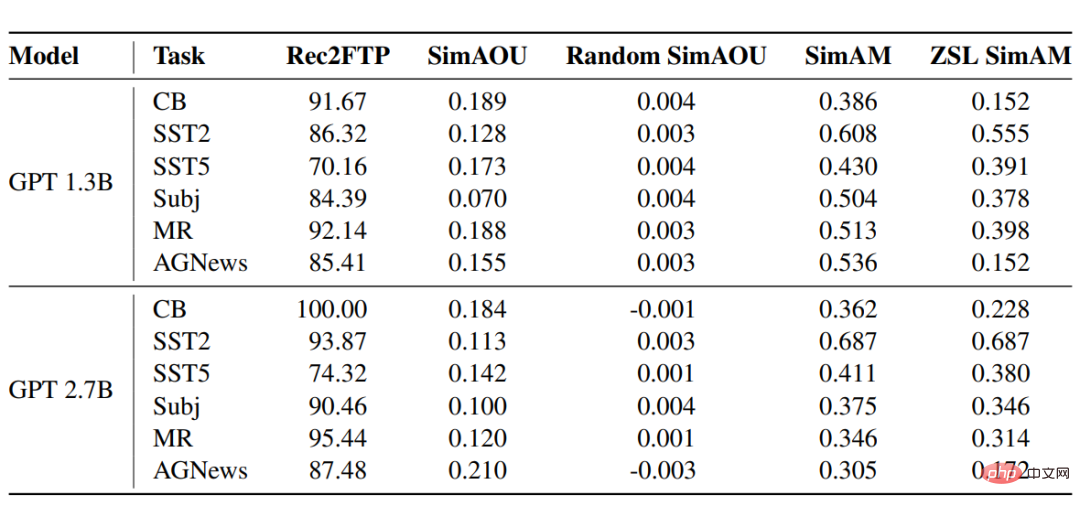
Hasil pemarkahan model GPT pada enam set data menunjukkan bahawa secara purata, ICL boleh meramalkan 87.64% daripada contoh dengan betul, manakala penalaan halus boleh membetulkan ZSL. Pada peringkat ramalan, ICL boleh merangkumi kebanyakan gelagat yang betul untuk penalaan halus.
SimAOU (Kesamaan Pengemaskinian Output Perhatian) Persamaan adalah lebih tinggi daripada kemas kini rawak, yang juga bermakna bahawa pada peringkat perwakilan, ICL cenderung untuk mengubah keputusan perhatian dalam arah yang sama seperti perubahan penalaan halus.
SimAM (Peta Persamaan Perhatian)
Sebagai metrik garis dasar SimAM, ZSL SimAM mengira Persamaan perhatian ICL antara pemberat dan pemberat perhatian ZSL. Dengan membandingkan kedua-dua metrik ini, dapat diperhatikan bahawa berbanding dengan ZSL, ICL cenderung untuk menghasilkan pemberat perhatian yang sama seperti penalaan halus.
Begitu juga, pada tahap tingkah laku perhatian, keputusan eksperimen membuktikan bahawa ICL berkelakuan serupa dengan penalaan halus.
Atas ialah kandungan terperinci Qingbei Microsoft mendalami GPT dan memahami pembelajaran kontekstual! Ia pada asasnya sama seperti penalaan halus, kecuali parameter tidak berubah.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI