
Rumah >Peranti teknologi >AI >Penggunaan algoritma pengesyoran Alibaba yang boleh dijelaskan
Penggunaan algoritma pengesyoran Alibaba yang boleh dijelaskan

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-10 16:52:061033semak imbas
1. Pengenalan kepada perniagaan cadangan
Pertama, mari kita perkenalkan latar belakang perniagaan Alibaba Health dan analisis situasi semasa.
1. Paparan senario pengesyoran
Cadangan yang boleh ditafsir, contohnya, seperti yang ditunjukkan dalam gambar di bawah tentang Dangdang. com "Disyorkan berdasarkan produk yang anda semak imbas" (memberitahu pengguna sebab pengesyoran itu) dan "1000+ Koleksi Kawalan Rumah" Taobao dan "2000+ Pembelian Tambahan Pakar Digital" adalah semua pengesyoran yang boleh ditafsirkan, yang menerangkan produk yang disyorkan dengan menyediakan pengguna maklumat.

Cadangan yang boleh ditafsir dalam gambar di sebelah kiri mempunyai idea pelaksanaan yang agak mudah: pengesyoran itu terutamanya termasuk penarikan balik dan pengisihan Terdapat dua modul utama, dan ingat semula selalunya melibatkan ingat semula berbilang saluran Ingat semula tingkah laku pengguna juga merupakan kaedah ingat semula yang biasa. Produk yang telah melalui modul pengisihan boleh dinilai Jika produk datang daripada kumpulan ingat semula tingkah laku pengguna, ulasan pengesyoran yang sepadan boleh ditambah selepas produk yang disyorkan. Walau bagaimanapun, kaedah ini selalunya mempunyai ketepatan yang rendah dan tidak memberikan pengguna maklumat yang berkesan.
Sebagai perbandingan, dalam contoh di sebelah kanan, teks penerangan yang sepadan boleh memberikan pengguna lebih banyak maklumat, seperti maklumat kategori produk, dll., tetapi kaedah ini selalunya memerlukan lebih banyak campur tangan manual, daripada ciri kepada teks Pautan output diproses secara manual.
Bagi Ali Health, disebabkan kekhususan industri, mungkin terdapat lebih banyak sekatan daripada senario lain. Peraturan berkaitan menetapkan bahawa maklumat teks seperti "jualan hangat, kedudukan dan pengesyoran" tidak dibenarkan dipaparkan dalam iklan untuk "tiga produk dan satu peranti" (ubat, makanan kesihatan, makanan formula untuk tujuan perubatan khas dan peranti perubatan). Oleh itu, Alibaba Health perlu mengesyorkan produk berdasarkan perniagaan Alibaba Health atas premis mematuhi peraturan di atas.
2. Keadaan perniagaan Ali Health
Ali Health kini mempunyai dua jenis kedai: kedai kendalian sendiri Ali Health dan industri Ali Health kedai-kedai. Antaranya, kedai kendalian sendiri terutamanya termasuk farmasi besar, kedai luar negara dan kedai utama farmaseutikal, manakala kedai industri kesihatan Alibaba terutamanya melibatkan kedai utama pelbagai kategori dan kedai persendirian.
Dari segi produk, Alibaba Health terutamanya meliputi tiga kategori utama produk: komoditi konvensional, komoditi OTC dan ubat preskripsi. Produk biasa ditakrifkan sebagai produk yang bukan ubat Pengesyoran untuk produk biasa boleh memaparkan lebih banyak maklumat, seperti kategori jualan teratas, lebih daripada n+ orang yang mengumpul/membeli, dsb. Pengesyoran untuk produk farmaseutikal seperti OTC dan ubat preskripsi tertakluk pada peraturan yang sepadan dan pengesyoran perlu lebih disepadukan dengan kebimbangan pengguna, seperti maklumat tentang petunjuk berfungsi, kitaran ubat, kontraindikasi dan maklumat lain.
Maklumat yang dinyatakan di atas yang boleh digunakan untuk teks pengesyoran ubat terutamanya datang daripada sumber utama berikut:
- Ulasan produk (tidak termasuk ubat preskripsi).
- Halaman butiran produk.
- Arahan dan maklumat lain.
2. Penyediaan data asas
Bahagian kedua terutamanya memperkenalkanCiri-ciri produk adalah Bagaimana untuk mengekstrak dan mengekod .
1 Pengekstrakan ciri produk
Berikut mengambil Huoxiang Zhengqi Water sebagai contoh untuk menunjukkan cara mengekstrak data daripada data di atas Sumber untuk mengekstrak ciri utama:

- Tajuk
Untuk meningkatkan penarikan balik produk, peniaga sering menambah lebih banyak kata kunci pada tajuk Oleh itu, kata kunci boleh diekstrak melalui perihalan tajuk peniaga itu sendiri.
- Gambar butiran produk
Boleh meminjam teknologi OCR berdasarkan barang Maklumat produk yang lebih komprehensif seperti fungsi produk, titik jualan utama dan titik jualan teras boleh diekstrak daripada imej terperinci.
- Data ulasan pengguna
Oleh pengguna berdasarkan fungsi Skor emosi boleh digunakan untuk menimbang dan mengurangkan berat kata kunci produk yang sepadan. Sebagai contoh, untuk Air Huoxiang Zhengqi yang "mencegah strok haba", berat yang sepadan boleh diproses berdasarkan skor emosi "mencegah strok haba" dalam ulasan pengguna.
- Arahan Dadah
Melalui pelbagai sumber data di atas , boleh mengekstrak kata kunci daripada maklumat dan membina perpustakaan kata kunci. Memandangkan terdapat banyak pengulangan dan sinonim dalam kata kunci yang diekstrak, sinonim perlu digabungkan dan digabungkan dengan pengesahan manual untuk menjana tesaurus standard. Akhir sekali, satu perhubungan senarai tag produk tunggal boleh dibentuk, yang boleh digunakan untuk pengekodan dan penggunaan seterusnya dalam model.
2. Pengekodan ciri
Berikut menerangkan cara mengekod ciri. Pengekodan ciri terutamanya berdasarkan kaedah word2vec untuk pembenaman perkataan.
Data pasangan produk pembelian sejarah sebenar boleh dibahagikan kepada tiga kategori berikut:
(1) Penyemakan Imbas Biasa pasangan produk: Pengguna yang mengklik satu demi satu dalam tempoh masa (30 minit) ditakrifkan sebagai data semak imbas bersama.
(2) Pasangan produk yang dibeli bersama: Pembelian bersama boleh ditakrifkan secara meluas sebagai perkara utama yang sama pesanan Sub-pesanan boleh dianggap sebagai sepasang barang yang dibeli bersama, bagaimanapun, mengambil kira tabiat pesanan pengguna sebenar, data produk pesanan yang dibuat oleh pengguna yang sama dalam tempoh masa tertentu (10 minit) ditentukan.
(3) Pasangan produk yang dibeli selepas menyemak imbas: Pengguna yang sama membeli produk B selepas mengklik A, dan A dan B adalah saling eksklusif Semak imbas dan beli data.
Dengan menganalisis data sejarah, didapati bahawa data pembelian selepas menyemak imbas mempunyai tahap persamaan yang tinggi antara produk: selalunya fungsi teras ubat adalah serupa, dengan hanya sedikit perbezaan. Tentukan ia sebagai sepasang produk yang serupa, yang merupakan sampel positif.
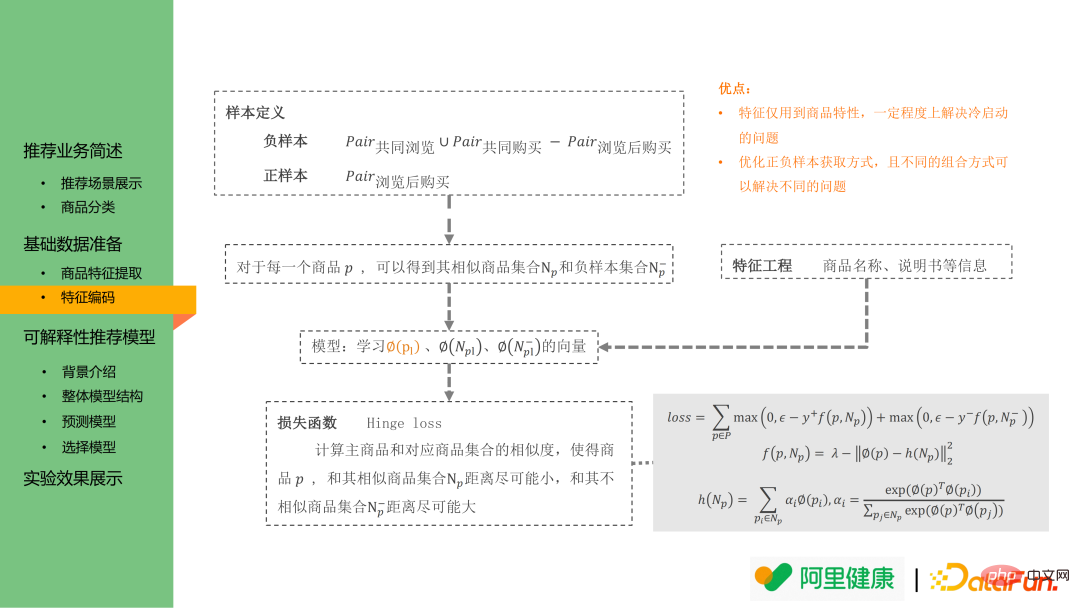
Model pengekodan ciri masih berdasarkan idea Word2vec: terutamanya berharap agar penyisipan antara yang serupa produk/label akan lebih dekat . Oleh itu, sampel positif dalam pembenaman perkataan ditakrifkan sebagai pasangan produk yang disebutkan di atas yang dibeli selepas menyemak imbas sampel negatif ialah gabungan pasangan produk yang dilayari bersama dan pasangan produk yang dibeli bersama tolak data pasangan produk yang dibeli selepas menyemak imbas.
Berdasarkan takrifan pasangan sampel positif dan negatif di atas, menggunakan kehilangan engsel, pembenaman setiap produk boleh dipelajari untuk peringkat ingat i2i, dan pembenaman tag/kata kunci juga boleh dipelajari dalam senario ini untuk kegunaan seterusnya kepada model.
Kaedah di atas mempunyai dua kelebihan:
(1) Ciri ini hanya menggunakan ciri produk, yang boleh menyelesaikan masalah sejuk untuk Isu permulaan: Untuk produk yang baru dilancarkan, anda masih boleh mendapatkan teg yang sepadan melalui tajuk, butiran produk dan maklumat lain.
(2) Takrif sampel positif dan negatif boleh digunakan dalam senario pengesyoran yang berbeza: jika sampel positif ditakrifkan sebagai pasangan produk yang dibeli bersama, pembenaman produk terlatih boleh digunakan dalam "pengsyoran pembelian kolokasi" senario.
3. Model pengesyoran yang boleh dijelaskan
1 Pengenalan kepada latar belakang model yang boleh dijelaskan
Industri kini agak matang Jenis boleh tafsir terutamanya termasuk kebolehtafsiran terbina dalam (model-intrinsik) dan kebolehtafsiran bebas model (model-agnostik).
Ia mempunyai model kebolehtafsiran terbina dalam, seperti XGBoost biasa, dsb. Walau bagaimanapun, walaupun XGBoost ialah model hujung ke hujung, kepentingan cirinya adalah berdasarkan set data keseluruhan, yang tidak memenuhi pengesyoran diperibadikan daripada "beribu-ribu orang dan beribu-ribu muka" Memerlukan.
Kebolehtafsiran bebas model terutamanya merujuk kepada membina semula model simulasi logik dan menerangkan model, seperti SHAP, yang boleh menganalisis satu kes dan menentukan sebab nilai ramalan berbeza daripada nilai sebenar. Walau bagaimanapun, SHAP adalah kompleks dan memakan masa, dan tidak dapat memenuhi keperluan prestasi dalam talian selepas pengubahsuaian prestasi.
Oleh itu, adalah perlu untuk membina model hujung ke hujung yang boleh mengeluarkan kepentingan ciri setiap sampel.
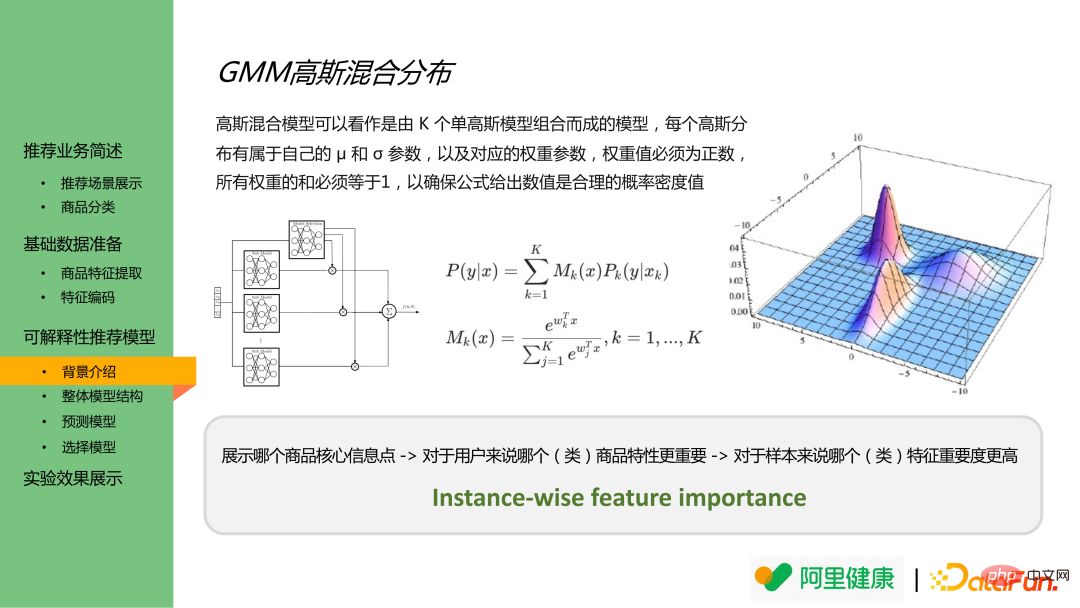
Taburan campuran Gaussian ialah gabungan beberapa taburan Gaussian, yang boleh mengeluarkan nilai hasil taburan tertentu dan kebarangkalian bahawa setiap hasil sampel tergolong dalam taburan tertentu . Oleh itu, analogi boleh dibuat untuk memahami ciri terperingkat sebagai data dengan taburan yang berbeza, dan memodelkan keputusan ramalan ciri yang sepadan dan kepentingan ramalan dalam keputusan sebenar.
2. Gambar rajah struktur model
Gambar di bawah ialah gambar rajah struktur model keseluruhan Gambar kiri menunjukkan model yang dipilih, yang boleh digunakan untuk memaparkan kepentingan ciri . Gambar yang betul ialah Model ramalan yang sepadan dengan ciri.
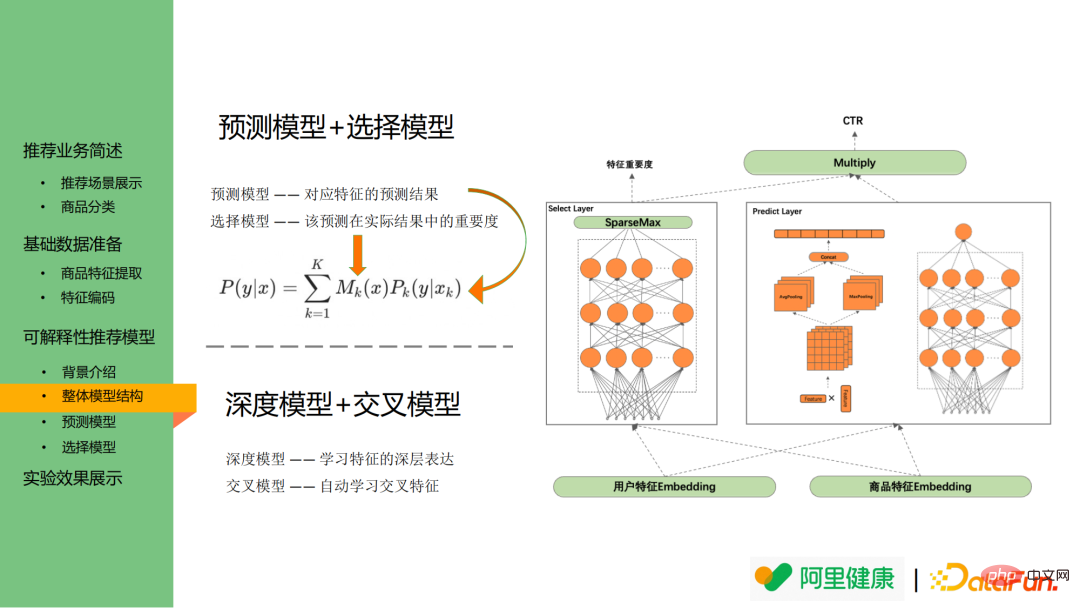
Secara khusus, model ramalan digunakan untuk meramalkan kebarangkalian ramalan/klik ciri yang sepadan, manakala model pemilihan digunakan untuk menerangkan taburan ciri yang lebih penting dan boleh digunakan sebagai penerangan Paparan teks seksual.
3. Model ramalan
Gambar di bawah menunjukkan keputusan model ramalan terutamanya menggunakan idea DeepFM dan termasuk model yang mendalam dan model silang. Model dalam digunakan terutamanya untuk mempelajari perwakilan mendalam ciri, manakala model silang digunakan untuk mempelajari ciri silang.
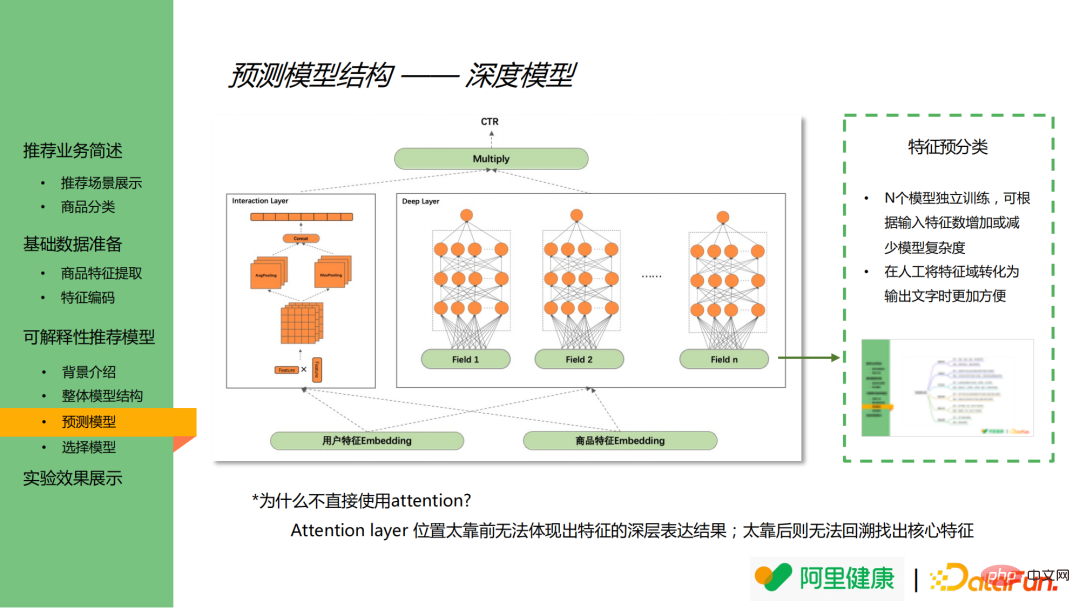
Dalam model dalam, ciri-ciri dikumpulkan terlebih dahulu (dengan mengandaikan terdapat N kumpulan secara keseluruhan), seperti harga, kategori dan ciri-ciri lain yang berkaitan digabungkan menjadi harga, kategori kategori ( medan medan dalam rajah), menjalankan latihan model berasingan untuk setiap set ciri, dan dapatkan keputusan model berdasarkan set ciri ini.
Penggabungan dan pengelompokan model terlebih dahulu mempunyai dua kelebihan berikut:
(1) Melalui latihan bebas model N, kerumitan model boleh diubah dengan menambah atau mengurangkan ciri input, Ini menjejaskan prestasi dalam talian.
(2) Ciri penggabungan dan pengelompokan boleh mengurangkan magnitud ciri dengan ketara, menjadikannya lebih mudah untuk menukar domain ciri kepada teks secara manual.
Perlu dinyatakan bahawa lapisan perhatian secara teorinya boleh digunakan untuk menganalisis kepentingan ciri, tetapi sebab utama untuk tidak memperkenalkan perhatian dalam model ini adalah seperti berikut:
(1) Jika perhatian adalah Jika lapisan diletakkan terlalu jauh ke hadapan, ia tidak akan dapat mencerminkan hasil ekspresi mendalam bagi ciri-ciri; dan cari ciri teras.
Bagi model ramalan:
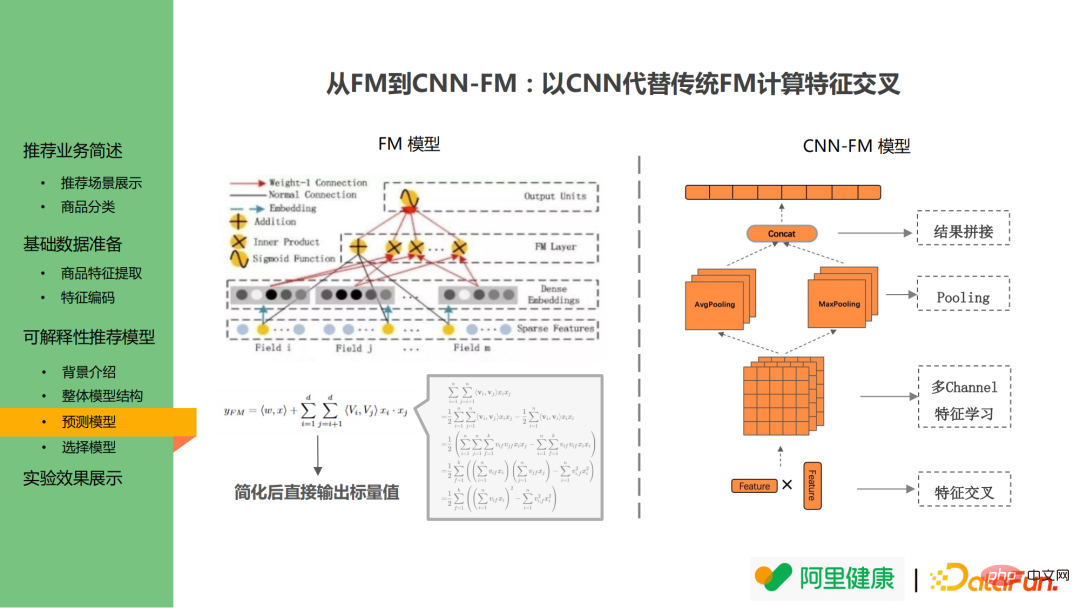 Lapisan silang tidak mengikut model FM tetapi menggunakan CNN dan bukannya struktur FM dalam DeepFM. Model FM mempelajari hasil silang berpasangan bagi ciri dan secara langsung mengira hasil silang berpasangan melalui formula matematik untuk mengelakkan letupan dimensi semasa pengiraan Walau bagaimanapun, ia menjadikannya mustahil untuk mengesan kembali kepentingan ciri gantikan struktur asal: N digunakan Ciri didarab untuk mencapai persimpangan ciri, dan kemudian operasi CNN yang sepadan dilakukan. Ini membolehkan nilai ciri dikesan kembali selepas pengumpulan, concat dan operasi lain selepas input.
Lapisan silang tidak mengikut model FM tetapi menggunakan CNN dan bukannya struktur FM dalam DeepFM. Model FM mempelajari hasil silang berpasangan bagi ciri dan secara langsung mengira hasil silang berpasangan melalui formula matematik untuk mengelakkan letupan dimensi semasa pengiraan Walau bagaimanapun, ia menjadikannya mustahil untuk mengesan kembali kepentingan ciri gantikan struktur asal: N digunakan Ciri didarab untuk mencapai persimpangan ciri, dan kemudian operasi CNN yang sepadan dilakukan. Ini membolehkan nilai ciri dikesan kembali selepas pengumpulan, concat dan operasi lain selepas input.
Selain kelebihan di atas, kaedah ini juga mempunyai kelebihan lain: walaupun versi semasa hanya menukar satu ciri kepada satu teks penerangan tunggal, ia masih diharapkan untuk mencapai penukaran interaksi berbilang ciri dalam masa hadapan. Sebagai contoh, jika pengguna terbiasa membeli produk berharga rendah untuk 100 yuan, tetapi jika produk dengan harga asal 50,000 yuan didiskaun kepada 500 yuan, dan pengguna membeli produk tersebut, model itu mungkin mentakrifkannya sebagai pengguna berbelanja tinggi. Tetapi dalam amalan, pengguna mungkin membuat pesanan disebabkan oleh dua faktor jenama mewah dan diskaun yang tinggi, jadi logik gabungan perlu dipertimbangkan. Untuk model CNN-FM, peta ciri boleh digunakan terus untuk mengeluarkan gabungan ciri pada peringkat kemudian.
4. Model pemilihan
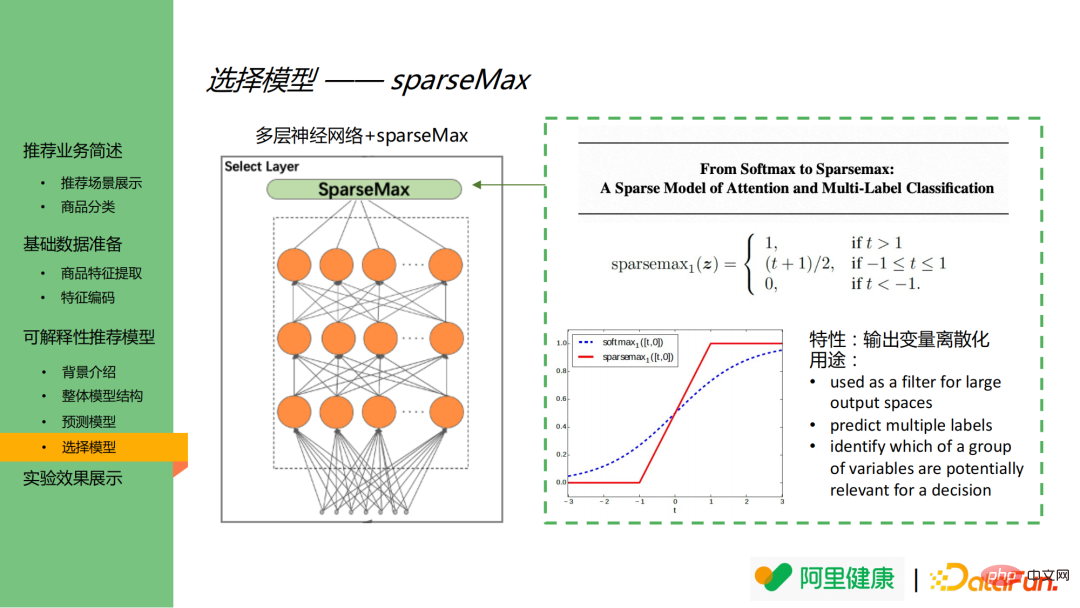
Model pemilihan terdiri daripada MLP dan sparseMax. Perlu dinyatakan bahawa fungsi pengaktifan dalam model pemilihan adalah sparsemax dan bukannya softmax yang lebih biasa. Di sebelah kanan imej adalah definisi fungsi sparsemax dan carta perbandingan fungsi softmax dan sparsemax.
Seperti yang dapat dilihat dari gambar di sebelah kanan bawah, softmax masih akan memberikan nilai yang lebih kecil kepada nod output dengan kepentingan yang lebih rendah, ia akan menyebabkan dimensi ciri meletup, dan ia mudah untuk menyebabkan ciri penting menjadi tidak penting Output antara ciri tidak dapat dibezakan. SparseMax boleh mendiskrisikan output dan akhirnya hanya mengeluarkan ciri yang lebih penting.
4. Paparan kesan eksperimen
1. data terutamanya datang daripada data klik pendedahan pada halaman utama farmasi besar Untuk mengelakkan pemasangan berlebihan, beberapa data klik pendedahan pemandangan lain juga diperkenalkan, dan nisbah data ialah 4:1.
2. Penunjuk luar talian
Dalam senario luar talian, AUC model ini ialah 0.74.
3 Penunjuk dalam talian
Memandangkan adegan dalam talian sudah mempunyai model CTR, pertimbangkan bahawa versi baharu algoritma bukan sahaja akan menggantikan model, tetapi juga memaparkan yang sepadan Teks penerangan tidak mengawal pembolehubah, jadi percubaan ini tidak langsung menggunakan ujian AB. Sebaliknya, teks sebab pengesyoran akan dipaparkan jika dan hanya jika nilai ramalan model CTR dalam talian dan versi baharu algoritma adalah lebih tinggi daripada ambang tertentu. Selepas pergi ke dalam talian, PCTR algoritma baharu meningkat sebanyak 9.13%, dan UCTR meningkat sebanyak 3.4%.5. Sesi Soal Jawab
S1: Apakah model yang digunakan untuk menjana leksikon standard dan menggabungkan sinonim? Sejauh mana keberkesanannya? Berapa banyak lagi kerja penentukuran manual yang diperlukan?
J1: Apabila menggabungkan sinonim, model akan digunakan untuk mempelajari standard teks dan menyediakan perpustakaan perbendaharaan kata asas. Tetapi sebenarnya, pengesahan manual mengambil bahagian yang lebih besar. Oleh kerana senario perniagaan kesihatan/farmaseutikal mempunyai keperluan yang lebih tinggi untuk ketepatan algoritma, sisihan dalam perkataan individu boleh menyebabkan penyelewengan besar dalam makna sebenar. Secara keseluruhan, bahagian pengesahan manual akan lebih besar daripada algoritma.
S2: Bolehkah model LIME digunakan sebagai penjelasan untuk model pengesyoran?
A2: Ya. Terdapat banyak model lain yang boleh melakukan cadangan yang boleh dijelaskan. Oleh kerana pekongsi biasanya biasa dengan GMM, model di atas telah dipilih.
S3: Bagaimanakah model pemilihan dan model ramalan dipautkan?
A3: Dengan mengandaikan terdapat N set kumpulan ciri, kedua-dua model ramalan dan model pemilihan akan menghasilkan vektor 1*N-dimensi, dan akhirnya keputusan ramalan model dan model pemilihan akan dibandingkan.
S4: Bagaimana untuk menjana teks yang boleh ditafsir?
A
4: Pada masa ini tiada model pembelajaran mesin yang sesuai untuk penjanaan teks, dan kaedah manual digunakan terutamanya. Jika harga ialah ciri teras yang penting bagi pengguna, mereka akan memilih untuk menganalisis data sejarah dan mengesyorkan produk dengan prestasi kos tinggi. Tetapi buat masa ini, ia terutamanya kerja manual. Diharapkan terdapat model yang sesuai untuk penjanaan teks pada masa hadapan, tetapi memandangkan kekhususan senario perniagaan, teks yang dijana oleh model masih perlu disahkan secara manual.S5: Apakah logik penapisan model?
A5: Untuk pemilihan pengedaran neutron GMM, pengedaran terutamanya dipelajari melalui Mk dalam GMM, dan ditapis berdasarkan nilai tinggi dan rendah Mk.
S6: Adakah anotasi perbendaharaan kata mempunyai jenis atribut?
A6: Memenuhi piawaian untuk perkataan atribut, seperti penyakit, fungsi, pantang larang, dsb. dalam penerangan produk.
S7: Bolehkah teks yang boleh ditafsir menggunakan idea pengisian slot? Iaitu, sediakan templat yang berbeza dan pilih templat yang berbeza mengikut berat perkataan?
J7: Ya, penggunaan sebenar sekarang ialah pengisian slot.
Itu sahaja perkongsian hari ini, terima kasih semua.
Atas ialah kandungan terperinci Penggunaan algoritma pengesyoran Alibaba yang boleh dijelaskan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI