

 Peranti teknologiAIKaedah teras ChatGPT boleh digunakan untuk lukisan AI, dan kesannya melonjak sebanyak 47%.
Peranti teknologiAIKaedah teras ChatGPT boleh digunakan untuk lukisan AI, dan kesannya melonjak sebanyak 47%.Kaedah teras ChatGPT boleh digunakan untuk lukisan AI, dan kesannya melonjak sebanyak 47%.

Terdapat kaedah latihan teras sedemikian dalam ChatGPT yang dipanggil "Pembelajaran Pengukuhan dengan Maklum Balas Manusia (RLHF)".
Ia boleh menjadikan model lebih selamat dan hasil keluarannya lebih konsisten dengan niat manusia.
Kini, penyelidik dari Google Research dan UC Berkeley telah mendapati bahawa menggunakan kaedah ini pada lukisan AI boleh "merawat" situasi di mana imej tidak betul-betul sepadan dengan input, dan kesannya sangat baik -
Sehingga 47% peningkatan boleh dicapai.

△ Kiri adalah Stable Diffusion, kanan ialah kesan yang lebih baik
Pada masa ini, dua model popular dalam bidang AIGC nampaknya telah menemui "resonans" tertentu.
Bagaimana untuk menggunakan RLHF untuk lukisan AI?
RLHF, nama penuh "Pembelajaran Pengukuhan daripada Maklum Balas Manusia", ialah teknologi pembelajaran pengukuhan yang dibangunkan bersama oleh OpenAI dan DeepMind pada 2017.
Seperti namanya, RLHF menggunakan penilaian manusia terhadap hasil keluaran model (iaitu maklum balas) untuk terus mengoptimumkan model Dalam LLM, ia boleh menjadikan "nilai model" lebih konsisten dengan nilai manusia.
Dalam model penjanaan imej AI, ia boleh menjajarkan sepenuhnya imej yang dijana dengan gesaan teks.
Khususnya, pertama, kumpulkan data maklum balas manusia.
Di sini, penyelidik menjana sejumlah lebih daripada 27,000 "pasangan imej teks" dan kemudian meminta beberapa manusia untuk menjaringkannya.
Demi kesederhanaan, gesaan teks hanya termasuk empat kategori berikut, berkaitan dengan kuantiti, warna, latar belakang dan pilihan pengadunan hanya dibahagikan kepada "baik", "buruk" dan "jangan tahu (langkau)" ".

Kedua, pelajari fungsi ganjaran.
Langkah ini adalah untuk menggunakan set data yang terdiri daripada penilaian manusia yang baru diperolehi untuk melatih fungsi ganjaran, dan kemudian menggunakan fungsi ini untuk meramalkan kepuasan manusia dengan output model (bahagian merah formula).
Dengan cara ini, model mengetahui sejauh mana hasilnya sepadan dengan teks.
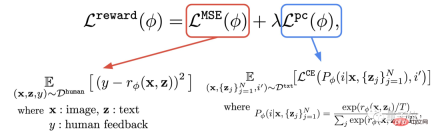
Selain fungsi ganjaran, penulis juga mencadangkan tugas tambahan (bahagian biru formula).
Iaitu, selepas penjanaan imej selesai, model akan memberikan sekumpulan teks, tetapi hanya satu daripadanya ialah teks asal, dan biarkan model ganjaran "menyemak dengan sendirinya" sama ada imej itu sepadan dengan teks.
Operasi terbalik ini boleh menjadikan kesan "insurans berganda" (ia boleh membantu pemahaman langkah 2 dalam gambar di bawah).
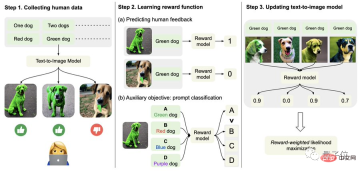
Akhir sekali, ia diperhalusi.
Iaitu, model penjanaan imej teks dikemas kini melalui pemaksimuman kemungkinan wajaran ganjaran (istilah pertama formula di bawah).
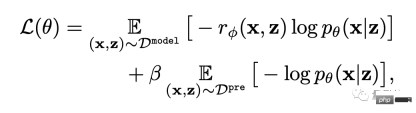
Untuk mengelakkan overfitting, penulis meminimumkan nilai NLL (istilah kedua formula) pada set data pra-latihan. Pendekatan ini serupa dengan InstructionGPT ("pendahulu langsung" ChatGPT).
Kesan meningkat sebanyak 47%, tetapi kejelasan menurun sebanyak 5%
Seperti yang ditunjukkan dalam siri kesan berikut, berbanding dengan Stable Diffusion asal, model yang diperhalusi dengan RLHF boleh :
(1) Dapatkan "dua" dan "hijau" dalam teks dengan lebih betul; abaikan "laut" Sebagai keperluan latar belakang;
(3) Jika anda mahukan harimau merah, ia boleh memberikan hasil yang "lebih merah".
 Daripada data khusus, kepuasan manusia terhadap model yang diperhalusi ialah 50%, iaitu peningkatan sebanyak 47% berbanding model asal (3%).
Daripada data khusus, kepuasan manusia terhadap model yang diperhalusi ialah 50%, iaitu peningkatan sebanyak 47% berbanding model asal (3%).
Kita juga boleh melihat dengan jelas dari gambar di bawah bahawa serigala di sebelah kanan jelas lebih kabur daripada yang di sebelah kiri:
Ya Oleh itu, penulis mencadangkan bahawa keadaan boleh diperbaiki menggunakan set data penilaian manusia yang lebih besar dan kaedah pengoptimuman (RL) yang lebih baik.
 Mengenai pengarang
Mengenai pengarang

Memandangkan saintis penyelidikan Google AI Kimin Lee, Ph.D dari Institut Sains dan Teknologi Korea, penyelidikan pasca doktoral telah dijalankan di UC Berkeley.

Tiga pengarang Cina:
Liu Hao, pelajar kedoktoran di UC Berkeley, yang minat penyelidikan utamanya ialah rangkaian saraf maklum balas.
Du Yuqing ialah pelajar PhD di UC Berkeley Halatuju penyelidikan utamanya ialah kaedah pembelajaran pengukuhan tanpa pengawasan.
Shixiang Shane Gu (Gu Shixiang), pengarang yang sepadan, belajar di bawah Hinton, salah satu daripada tiga gergasi, untuk ijazah sarjana mudanya, dan lulus dari Universiti Cambridge dengan ijazah kedoktorannya.

△ Gu Shixiang
Perlu dinyatakan bahawa semasa menulis artikel ini, dia masih seorang Googler, dan kini dia telah beralih kepada OpenAI, di mana dia terus melaporkan kepada Laporan daripada orang yang bertanggungjawab ke atas ChatGPT.
Alamat kertas:
https://arxiv.org/abs/2302.12192
Pautan rujukan: [1]https://www.php .cn/link/4d42d2f5010c1c13f23492a35645d6a7
[2]https://openai.com/blog/instruction-following/
Atas ialah kandungan terperinci Kaedah teras ChatGPT boleh digunakan untuk lukisan AI, dan kesannya melonjak sebanyak 47%.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Mengubah Pelaporan Kewangan dengan AI dan NLG - Analytics VidhyaApr 15, 2025 am 10:35 AM
Mengubah Pelaporan Kewangan dengan AI dan NLG - Analytics VidhyaApr 15, 2025 am 10:35 AMPelaporan Kewangan berkuasa AI: merevolusikan pandangan melalui generasi bahasa semula jadi Dalam persekitaran perniagaan dinamik hari ini, analisis kewangan yang tepat dan tepat pada masanya adalah penting untuk membuat keputusan strategik. Pelaporan kewangan tradisional
 Adakah robot Google Deepmind ini akan bermain di Sukan Olimpik 2028?Apr 15, 2025 am 10:16 AM
Adakah robot Google Deepmind ini akan bermain di Sukan Olimpik 2028?Apr 15, 2025 am 10:16 AMRobot Tenis Jadual Google Deepmind: Era Baru dalam Sukan dan Robotik Sukan Olimpik Paris 2024 mungkin berakhir, tetapi era baru dalam sukan dan robotik adalah berkemungkinan, terima kasih kepada Google Deepmind. Penyelidikan terobosan mereka ("Mencapai Kompet Tahap Manusia
 Membina WebApp Wawasan Makanan dengan Model Gemini Flash 1.5Apr 15, 2025 am 10:15 AM
Membina WebApp Wawasan Makanan dengan Model Gemini Flash 1.5Apr 15, 2025 am 10:15 AMMembuka Kecekapan dan Skala dengan Gemini Flash 1.5: WebApp Wawasan Makanan Flask Dalam landskap AI yang pesat berkembang, kecekapan dan skalabiliti adalah yang paling utama. Pemaju semakin mencari model berprestasi tinggi yang meminimumkan kos dan latenc
 Melaksanakan ejen AI menggunakan llamaindexApr 15, 2025 am 10:11 AM
Melaksanakan ejen AI menggunakan llamaindexApr 15, 2025 am 10:11 AMMemanfaatkan kuasa agen AI dengan llamaindex: panduan langkah demi langkah Bayangkan pembantu peribadi yang memahami permintaan anda dan melaksanakannya dengan sempurna, sama ada pengiraan cepat atau mengambil berita pasaran terkini. Artikel ini meneroka
 5 kaedah untuk menukar fail .ipynb ke pdf- analitik vidhyaApr 15, 2025 am 10:06 AM
5 kaedah untuk menukar fail .ipynb ke pdf- analitik vidhyaApr 15, 2025 am 10:06 AMFail Notebook Jupyter (.iPynb) digunakan secara meluas dalam analisis data, pengkomputeran saintifik, dan pengekodan interaktif. Walaupun buku nota ini bagus untuk membangun dan berkongsi kod dengan saintis data lain, kadang -kadang anda perlu mengubahnya menjadi format yang lebih umum, seperti PDF. Panduan ini akan membimbing anda melalui pelbagai cara untuk menukar fail .ipynb ke PDF, serta petua, amalan terbaik, dan cadangan penyelesaian masalah. Jadual Kandungan Mengapa menukar .ipynb ke pdf? Cara menukar fail .ipynb ke pdf Menggunakan UI Notebook Jupyter Menggunakan NBConve
 Panduan Komprehensif mengenai Kes Kuantisasi dan Penggunaan LLMApr 15, 2025 am 10:02 AM
Panduan Komprehensif mengenai Kes Kuantisasi dan Penggunaan LLMApr 15, 2025 am 10:02 AMPengenalan Model bahasa yang besar (LLMs) merevolusi pemprosesan bahasa semulajadi, tetapi saiz besar dan tuntutan pengiraannya membatasi penggunaan. Kuantisasi, teknik untuk mengecilkan model dan kos pengiraan yang lebih rendah, adalah solu penting
 Panduan komprehensif untuk selenium dengan pythonApr 15, 2025 am 09:57 AM
Panduan komprehensif untuk selenium dengan pythonApr 15, 2025 am 09:57 AMPengenalan Panduan ini meneroka gabungan kuat selenium dan python untuk automasi dan ujian web. Selenium mengautomasikan interaksi pelayar, meningkatkan kecekapan ujian untuk aplikasi web yang besar. Tutorial ini memberi tumpuan o
 Panduan untuk Memahami Syarat InteraksiApr 15, 2025 am 09:56 AM
Panduan untuk Memahami Syarat InteraksiApr 15, 2025 am 09:56 AMPengenalan Istilah interaksi dimasukkan dalam pemodelan regresi untuk menangkap kesan dua atau lebih pembolehubah bebas dalam pemboleh ubah bergantung. Kadang -kadang, ia bukan hanya hubungan mudah antara kawalan


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

VSCode Windows 64-bit Muat Turun
Editor IDE percuma dan berkuasa yang dilancarkan oleh Microsoft

EditPlus versi Cina retak
Saiz kecil, penyerlahan sintaks, tidak menyokong fungsi gesaan kod

SublimeText3 Linux versi baharu
SublimeText3 Linux versi terkini

Dreamweaver CS6
Alat pembangunan web visual

DVWA
Damn Vulnerable Web App (DVWA) ialah aplikasi web PHP/MySQL yang sangat terdedah. Matlamat utamanya adalah untuk menjadi bantuan bagi profesional keselamatan untuk menguji kemahiran dan alatan mereka dalam persekitaran undang-undang, untuk membantu pembangun web lebih memahami proses mengamankan aplikasi web, dan untuk membantu guru/pelajar mengajar/belajar dalam persekitaran bilik darjah Aplikasi web keselamatan. Matlamat DVWA adalah untuk mempraktikkan beberapa kelemahan web yang paling biasa melalui antara muka yang mudah dan mudah, dengan pelbagai tahap kesukaran. Sila ambil perhatian bahawa perisian ini

