
Rumah >Peranti teknologi >AI >Sangat mudah untuk membina dan melatih rangkaian saraf pertama anda dengan TensorFlow dan Keras
Sangat mudah untuk membina dan melatih rangkaian saraf pertama anda dengan TensorFlow dan Keras

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-09 19:04:06930semak imbas
Teknologi AI berkembang pesat Menggunakan pelbagai model AI canggih, robot sembang, robot humanoid, kereta pandu sendiri, dll. boleh dibina. AI telah menjadi teknologi yang paling pesat berkembang, dan pengesanan objek dan klasifikasi objek adalah trend terkini.
Artikel ini akan memperkenalkan langkah lengkap membina dan melatih model klasifikasi imej dari awal menggunakan rangkaian saraf konvolusi. Artikel ini akan menggunakan set data Cifar-10 awam untuk melatih model ini. Set data ini unik kerana ia mengandungi imej objek harian seperti kereta, kapal terbang, anjing, kucing, dsb. Dengan melatih rangkaian saraf pada objek ini, artikel ini akan membangunkan sistem pintar untuk mengklasifikasikan perkara ini di dunia nyata. Ia mengandungi lebih daripada 60,000 imej 32x32 daripada 10 jenis objek yang berbeza. Menjelang akhir tutorial ini, anda akan mempunyai model yang boleh mengenal pasti objek berdasarkan ciri visualnya.

Rajah 1 Imej sampel set data|Imej daripada dataset.activeloop
Artikel ini akan merangkumi segala-galanya dari awal, jadi jika anda belum mempelajari rangkaian saraf namun pelaksanaan sebenar adalah baik.
Berikut ialah aliran kerja lengkap tutorial ini:
- Mengimport perpustakaan yang diperlukan
- Memuatkan data
- Praprosesan data
- Bina model
- Nilai prestasi model
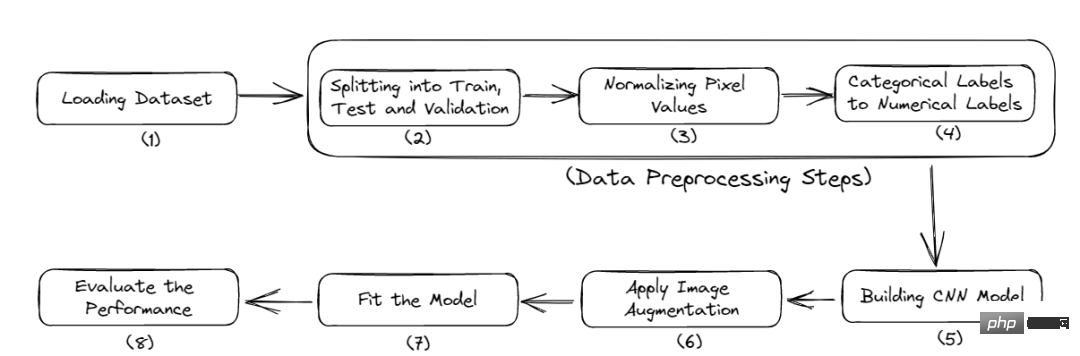
Rajah 2 Proses lengkap
Import perpustakaan yang diperlukan
Mula-mula anda perlu memasang beberapa modul untuk memulakan projek ini. Artikel ini akan menggunakan Google Colab kerana ia menyediakan latihan GPU percuma.
Berikut ialah arahan untuk memasang perpustakaan yang diperlukan:
<code>$ pip install tensorflow, numpy, keras, sklearn, matplotlib</code>
Import perpustakaan ke dalam fail Python.
<code>from numpy import *from pandas import *import matplotlib.pyplot as plotter# 将数据分成训练集和测试集。from sklearn.model_selection import train_test_split# 用来评估我们的训练模型的库。from sklearn.metrics import classification_report, confusion_matriximport keras# 加载我们的数据集。from keras.datasets import cifar10# 用于数据增量。from keras.preprocessing.image import ImageDataGenerator# 下面是一些用于训练卷积Nueral网络的层。from keras.models import Sequentialfrom keras.layers import Dense, Dropout, Activationfrom keras.layers import Conv2D, MaxPooling2D, GlobalMaxPooling2D, Flatten</code>
- Numpy: Ia digunakan untuk pengiraan tatasusunan yang cekap pada set data besar yang mengandungi imej.
- Tensorflow: Ia ialah perpustakaan pembelajaran mesin sumber terbuka yang dibangunkan oleh Google. Ia menyediakan banyak fungsi untuk membina model besar dan berskala.
- Keras: Satu lagi API rangkaian saraf peringkat tinggi yang berjalan di atas TensorFlow.
- Matplotlib: Pustaka Python ini boleh mencipta carta dan memberikan visualisasi data yang lebih baik.
- Sklearn: Ia menyediakan fungsi untuk melaksanakan prapemprosesan data dan tugas pengekstrakan ciri pada set data. Ia mengandungi fungsi terbina dalam untuk mencari metrik penilaian model seperti ketepatan, ketepatan, positif palsu, negatif palsu, dll.
Sekarang, masukkan langkah pemuatan data.
Memuatkan data
Bahagian ini akan memuatkan set data dan melaksanakan pemisahan data ujian latihan.
Memuatkan dan membahagikan data:
<code># 类的数量nc = 10(training_data, training_label), (testing_data, testing_label) = cifar10.load_data()((training_data),(validation_data),(training_label),(validation_label),) = train_test_split(training_data, training_label, test_size=0.2, random_state=42)training_data = training_data.astype("float32")testing_data = testing_data.astype("float32")validation_data = validation_data.astype("float32")</code>
Set data cifar10 dimuatkan terus daripada pustaka set data Keras. Dan data ini juga dibahagikan kepada data latihan dan data ujian. Data latihan digunakan untuk melatih model supaya dapat mengenali corak di dalamnya. Walaupun data ujian tidak dapat dilihat oleh model, ia digunakan untuk menyemak prestasinya, iaitu berapa banyak titik data yang diramalkan dengan betul berbanding dengan jumlah titik data.
label_latihan mengandungi label yang sepadan dengan imej dalam data_latihan.
Kemudian gunakan fungsi train_test_split sklearn terbina dalam untuk memisahkan data latihan kepada data pengesahan sekali lagi. Data pengesahan digunakan untuk memilih dan menala model akhir. Akhir sekali, semua data latihan, ujian dan pengesahan ditukar kepada nombor titik terapung 32-bit.
Kini, pemuatan set data telah selesai. Dalam bahagian seterusnya, artikel ini melakukan beberapa langkah prapemprosesan padanya.
Prapemprosesan data
Prapemprosesan data ialah langkah pertama dan paling kritikal apabila membangunkan model pembelajaran mesin. Ikuti artikel ini untuk mengetahui cara melakukannya.
<code># 归一化training_data /= 255testing_data /= 255validation_data /= 255# 热编码training_label = keras.utils.to_categorical(training_label, nc)testing_label = keras.utils.to_categorical(testing_label, nc)validation_label = keras.utils.to_categorical(validation_label, nc)# 输出数据集print("Training: ", training_data.shape, len(training_label))print("Validation: ", validation_data.shape, len(validation_label))print("Testing: ", testing_data.shape, len(testing_label))</code>
Output:
<code>Training:(40000, 32, 32, 3) 40000Validation:(10000, 32, 32, 3) 10000Testing:(10000, 32, 32, 3) 10000</code>
Set data ini mengandungi imej 10 kategori, setiap imej bersaiz 32x32 piksel. Setiap piksel mempunyai nilai dari 0-255, dan kita perlu menormalkannya antara 0-1 untuk memudahkan proses pengiraan. Selepas itu, kami akan menukar label kategori kepada label yang dikodkan satu-panas. Ini dilakukan untuk menukar data kategori kepada data berangka supaya kami boleh menggunakan algoritma pembelajaran mesin tanpa sebarang masalah.
Sekarang, masukkan pembinaan model CNN.
Membina model CNN
Model CNN berfungsi dalam tiga peringkat. Peringkat pertama terdiri daripada lapisan konvolusi untuk mengekstrak ciri yang berkaitan daripada imej. Peringkat kedua terdiri daripada lapisan pengumpulan untuk mengurangkan saiz imej. Ia juga membantu mengurangkan overfitting model. Peringkat ketiga terdiri daripada lapisan padat yang menukar imej 2D kepada tatasusunan 1D. Akhir sekali, tatasusunan ini dimasukkan ke dalam lapisan bersambung sepenuhnya untuk membuat ramalan akhir.
Berikut ialah kod:
<code>model = Sequential()model.add(Conv2D(32, (3, 3), padding="same", activatinotallow="relu", input_shape=(32, 32, 3)))model.add(Conv2D(32, (3, 3), padding="same", activatinotallow="relu"))model.add(MaxPooling2D((2, 2)))model.add(Dropout(0.25))model.add(Conv2D(64, (3, 3), padding="same", activatinotallow="relu"))model.add(Conv2D(64, (3, 3), padding="same", activatinotallow="relu"))model.add(MaxPooling2D((2, 2)))model.add(Dropout(0.25))model.add(Conv2D(96, (3, 3), padding="same", activatinotallow="relu"))model.add(Conv2D(96, (3, 3), padding="same", activatinotallow="relu"))model.add(MaxPooling2D((2, 2)))model.add(Flatten())model.add(Dropout(0.4))model.add(Dense(256, activatinotallow="relu"))model.add(Dropout(0.4))model.add(Dense(128, activatinotallow="relu"))model.add(Dropout(0.4))model.add(Dense(nc, activatinotallow="softmax"))</code>
Artikel ini menggunakan tiga kumpulan lapisan, setiap kumpulan mengandungi dua lapisan konvolusi, lapisan pengumpulan maksimum dan lapisan tercicir. Lapisan Conv2D menerima input_shape sebagai (32, 32, 3), yang mesti sama saiz dengan imej.
Setiap lapisan Conv2D juga memerlukan fungsi pengaktifan iaitu relu. Fungsi pengaktifan digunakan untuk meningkatkan ketaklinieran dalam sistem. Lebih mudah, ia menentukan sama ada neuron perlu diaktifkan berdasarkan ambang tertentu. Terdapat banyak jenis fungsi pengaktifan, seperti ReLu, Tanh, Sigmoid, Softmax, dsb., yang menggunakan algoritma berbeza untuk menentukan penembakan neuron.
之后,添加了平坦层和全连接层,在它们之间还有几个Dropout层。Dropout层随机地拒绝一些神经元对网层的贡献。它里面的参数定义了拒绝的程度。它主要用于避免过度拟合。
下面是一个CNN模型架构的示例图像。
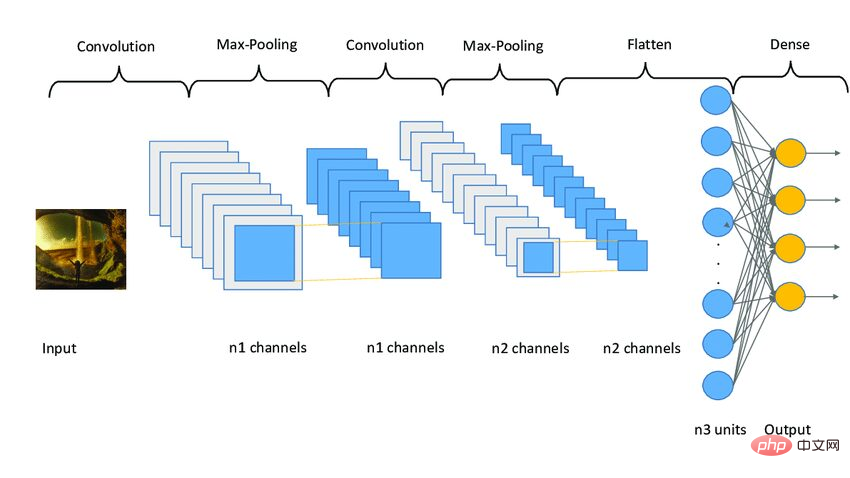
图3 Sampe CNN架构|图片来源:Researchgate
编译模型
现在,本文将编译和准备训练的模型。
<code># 启动Adam优化器opt = keras.optimizers.Adam(lr=0.0001)model.compile(loss="categorical_crossentropy", optimizer=opt, metrics=["accuracy"])# 获得模型的摘要model.summary()</code>
输出:

图4 模型摘要
本文使用了学习率为0.0001的Adam优化器。优化器决定了模型的行为如何响应损失函数的输出而变化。学习率是训练期间更新权重的数量或步长。它是一个可配置的超参数,不能太小或太大。
拟合模型
现在,本文将把模型拟合到我们的训练数据,并开始训练过程。但在此之前,本文将使用图像增强技术来增加样本图像的数量。
卷积神经网络中使用的图像增强技术将增加训练图像,而不需要新的图像。它将通过在图像中产生一定量的变化来复制图像。它可以通过将图像旋转到一定程度、添加噪声、水平或垂直翻转等方式来实现。
<code>augmentor = ImageDataGenerator(width_shift_range=0.4,height_shift_range=0.4,horizontal_flip=False,vertical_flip=True,)# 在augmentor中进行拟合augmentor.fit(training_data)# 获得历史数据history = model.fit(augmentor.flow(training_data, training_label, batch_size=32),epochs=100,validation_data=(validation_data, validation_label),)</code>
输出:

图5 每个时期的准确度和损失
ImageDataGenerator()函数用于创建增强的图像。fit()用于拟合模型。它以训练和验证数据、Batch Size和Epochs的数量作为输入。
Batch Size是在模型更新之前处理的样本数量。一个关键的超参数必须大于等于1且小于等于样本数。通常情况下,32或64被认为是最好的Batch Size。
Epochs的数量代表了所有样本在网络的前向和后向都被单独处理了多少次。100个epochs意味着整个数据集通过模型100次,模型本身运行100次。
我们的模型已经训练完毕,现在我们将评估它在测试集上的表现。
评估模型性能
本节将在测试集上检查模型的准确性和损失。此外,本文还将绘制训练和验证数据的准确率与时间之间和损失与时间之间的关系图。
<code>model.evaluate(testing_data, testing_label)</code>
输出:
<code>313/313 [==============================] - 2s 5ms/step - loss: 0.8554 - accuracy: 0.7545[0.8554493188858032, 0.7545000195503235]</code>
本文的模型达到了75.34%的准确率,损失为0.8554。这个准确率还可以提高,因为这不是一个最先进的模型。本文用这个模型来解释建立模型的过程和流程。CNN模型的准确性取决于许多因素,如层的选择、超参数的选择、使用的数据集的类型等。
现在我们将绘制曲线来检查模型中的过度拟合情况。
<code>def acc_loss_curves(result, epochs):acc = result.history["accuracy"]# 获得损失和准确性loss = result.history["loss"]# 声明损失和准确度的值val_acc = result.history["val_accuracy"]val_loss = result.history["val_loss"]# 绘制图表plotter.figure(figsize=(15, 5))plotter.subplot(121)plotter.plot(range(1, epochs), acc[1:], label="Train_acc")plotter.plot(range(1, epochs), val_acc[1:], label="Val_acc")# 给予绘图的标题plotter.title("Accuracy over " + str(epochs) + " Epochs", size=15)plotter.legend()plotter.grid(True)# 传递值122plotter.subplot(122)# 使用训练损失plotter.plot(range(1, epochs), loss[1:], label="Train_loss")plotter.plot(range(1, epochs), val_loss[1:], label="Val_loss")# 使用 ephocsplotter.title("Loss over " + str(epochs) + " Epochs", size=15)plotter.legend()# 传递真值plotter.grid(True)# 打印图表plotter.show()acc_loss_curves(history, 100)</code>
输出:
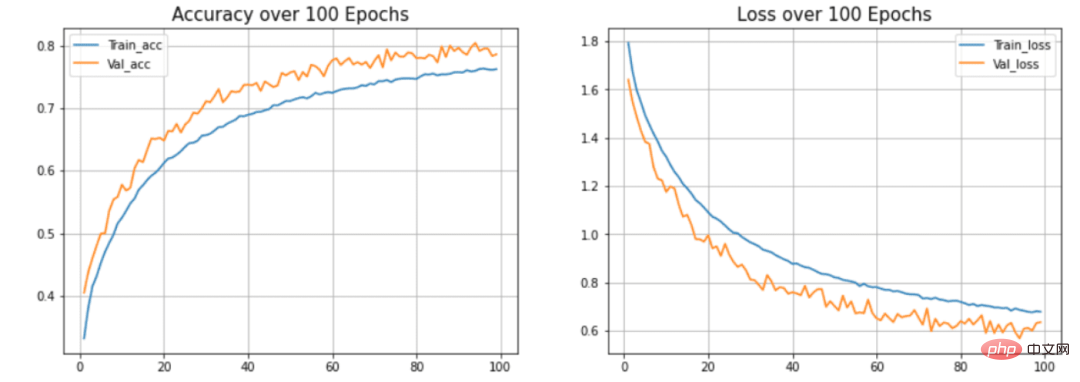
图6 准确度和损失与历时的关系
在本文的模型中,可以看到模型过度拟合测试数据集。(蓝色)线表示训练精度,(橙色)线表示验证精度。训练精度持续提高,但验证误差在20个历时后恶化。
总结
本文展示了构建和训练卷积神经网络的整个过程。最终得到了大约75%的准确率。你可以使用超参数并使用不同的卷积层和池化层来提高准确性。你也可以尝试迁移学习,它使用预先训练好的模型,如ResNet或VGGNet,并在某些情况下可以提供非常好的准确性。
Atas ialah kandungan terperinci Sangat mudah untuk membina dan melatih rangkaian saraf pertama anda dengan TensorFlow dan Keras. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI