
Rumah >Peranti teknologi >AI >Angka ini menggambarkan aplikasi teknik pembelajaran dalam sistem pengesyoran dadah.
Angka ini menggambarkan aplikasi teknik pembelajaran dalam sistem pengesyoran dadah.

- PHPzke hadapan
- 2023-05-08 20:07:211558semak imbas

Pengenalan: Topik perkongsian ini ialah aplikasi teknologi pembelajaran perwakilan graf dalam sistem pengesyoran dadah.
Terutamanya merangkumi empat bahagian berikut:
- Latar belakang dan cabaran penyelidikan
- Syor pakej ubat diskriminatif
- Cadangan Pakej ubat generatif
- Ringkasan dan Tinjauan
1 >
1. Latar belakang penyelidikan- Kekurangan keseluruhan sumber perubatan dan pengagihan yang tidak sekata membawa tekanan yang berat
Syor ubat adalah sub-masalah penjagaan perubatan pintar Mari kita mulakan dengan latar belakang umum penjagaan perubatan pintar di negara kita berkembang dan penduduk yang semakin tua semakin meningkat, , permintaan orang ramai untuk perkhidmatan perubatan berkualiti tinggi terus meningkat. Dua set data dalam angka tersebut Pertama, jumlah lawatan ke institusi perubatan di seluruh negara ialah 6.05 bilion, peningkatan tahun ke tahun sebanyak 22.4%, statistik mengenai keadaan perubatan dan kesihatan pelbagai negara di The Lancet menunjukkan bahawa hanya 57.4% daripada doktor Cina yang mempunyai ijazah sarjana muda ke atas, termasuk doktor, Bilangan pengamal bagi setiap 10,000 orang dalam 16 kategori pekerjaan kesihatan, termasuk jururawat dan pekerja kesihatan masyarakat, di China hanya satu pertiga daripada jumlah itu dalam Amerika Syarikat. Bilangan orang yang didiagnos dan dirawat di negara kita terus meningkat, tetapi sumber perubatan dan standard perubatan masih tidak mencukupi berbanding dengan negara maju Selain itu, terdapat juga masalah pengagihan sumber perubatan yang tidak sekata. Tahap perubatan institusi perubatan primer agak terhad, manakala bekalan institusi peringkat atasan melebihi permintaan. Oleh itu, cara menggunakan sepenuhnya pengalaman diagnosis dan rawatan institusi perubatan peringkat tinggi untuk membantu meningkatkan tahap perubatan institusi perubatan primer merupakan isu penting yang perlu diselesaikan dengan segera.
- Penjagaan perubatan pintar, teknologi kecerdasan buatan telah membawa fajar
Dengan pecutan pendigitalan institusi perubatan dalam beberapa tahun kebelakangan ini, sejumlah besar institusi perubatan di negara saya, terutamanya institusi perubatan peringkat tinggi seperti hospital tertiari, telah mengumpul data rekod perubatan elektronik yang sangat kaya. Jika teknologi kecerdasan buatan data besar boleh digunakan untuk melombong sepenuhnya maklumat ini dan mengekstrak pengetahuan yang berkaitan, ini mungkin membantu kami memahami beberapa kaedah diagnosis dan rawatan serta idea pakar perubatan di institusi peringkat tinggi ini, dan kemudian menyokong tindakan susulan pintar lawatan, analisis imej perubatan, susulan penyakit kronik, dsb. Satu siri aplikasi perubatan pintar hiliran adalah penting.
2. Cabaran PenyelidikanSemakin banyak teknologi AI perubatan semakin digunakan secara meluas keadilan dan kesejagatan perkhidmatan perubatan. Sesetengah teknologi AI, seperti analisis imej perubatan, telah mencapai beberapa hasil yang mengagumkan, tetapi ia jarang digunakan dalam sistem pengesyoran ubat Sebabnya ialah sistem pengesyoran ubat sangat berbeza daripada sistem pengesyoran tradisional, dan terdapat juga masalah teknikal dengan banyak kesukaran .
- Sistem pengesyoran pek

Cabaran pertama ialah senario aplikasi sistem pengesyoran tradisional berdasarkan penapisan kolaboratif dan kaedah lain terutamanya untuk mengesyorkan satu item kepada satu pengguna pada satu masa Input mereka adalah perwakilan satu item dan pengguna tunggal. dan output adalah salah satu daripada dua Skor tahap padanan antara mereka. Walau bagaimanapun, dalam pengesyoran ubat, doktor selalunya perlu menetapkan sekumpulan ubat kepada pesakit pada satu masa. Sistem pengesyoran ubat sebenarnya adalah sistem pengesyoran pakej, dipanggil sistem pengesyoran pakej, yang mengesyorkan satu set ubat kepada pengguna pada masa yang sama. Bagaimana untuk menggabungkan pengesyoran ubat dengan sistem pengesyoran pakej adalah cabaran besar pertama yang kami hadapi.
- Interaksi dadah-dadah
Cabaran kedua sistem pengesyoran ubat ialah interaksi yang pelbagai antara ubat. Sesetengah ubat mempunyai kesan sinergi yang menggalakkan kesan satu sama lain, manakala sesetengah ubat mempunyai antagonisme yang mengimbangi kesan satu sama lain Malah penggunaan gabungan beberapa ubat boleh membawa kepada ketoksikan atau kesan sampingan yang lain. Pesakit dalam gambar menghidap sejenis penyakit buah pinggang Bahagian kiri menunjukkan ubat-ubatan yang ditetapkan oleh doktor untuk pesakit itu mempunyai kesan sinergi dan boleh menggalakkan keberkesanan ubat tersebut. Bahagian kanan menunjukkan ubat frekuensi tinggi bergejala yang dianalisis secara statistik. Dapat dilihat bahawa ubat-ubatan ini mungkin tidak dipilih kerana beberapa kesan antagonis Ubat berikut mungkin toksik kepada beberapa ubat sedia ada, jadi ia tidak digunakan oleh pesakit ini.
Selain itu, kesan interaksi ubat adalah secara individu. Kami mendapati dalam statistik bahawa sebilangan besar ubat dengan kesan antagonis atau toksik digunakan secara serentak. Menurut analisis, doktor sebenarnya menetapkan ubat berdasarkan keadaan pesakit dan mengambil kira kesan interaksi. Sebagai contoh, sesetengah pesakit dengan buah pinggang yang sihat selalunya boleh bertolak ansur dengan sejumlah nefrotoksisiti ubat, jadi kami perlu menjalankan pemodelan dan analisis yang diperibadikan tentang interaksi antara ubat.
3. Teknologi pembelajaran perwakilan graf telah menjadi satu kemungkinan baharu

Ringkasnya, digabungkan dengan cabaran di atas, teknologi pembelajaran perwakilan graf adalah sangat sesuai untuk menyelesaikan masalah yang wujud dalam sistem pengesyoran dadah. Dengan perkembangan pesat rangkaian saraf graf, orang ramai menyedari bahawa teknologi rangkaian saraf graf boleh memodelkan kesan gabungan antara nod dan hubungan antara nod dengan sangat berkesan Ini memberi inspirasi kepada kami bahawa teknologi pembelajaran perwakilan graf mungkin menjadi alat yang berguna untuk membina sistem pengesyoran dadah. Alat yang tajam.
Sebagai contoh, dalam gambar, kita boleh membina pakej ubat menjadi graf berdasarkan interaksi di dalamnya, dan modelkannya melalui rangkaian saraf graf sedia ada . Berdasarkan idea di atas, kami menggunakan teknologi pembelajaran mendalam graf untuk melakukan dua kerja pada sistem pengesyoran dadah, yang masing-masing diterbitkan dalam jurnal WWW dan TOIS. Berikut adalah pengenalan terperinci.
2. Pengesyoran pakej ubat diskriminasi
Pertama sekali, mari perkenalkan pengesyoran pakej ubat yang kami terbitkan di WWW2021 kertas. Artikel ini mengguna pakai kaedah definisi model diskriminatif yang digunakan secara meluas dalam sistem pengesyoran pakej untuk pemodelan, dan juga menggunakan teknologi pembelajaran perwakilan graf sebagai bahagian teknologi teras.
1 Perihalan data
- Data kes elektronik <.>

Mula-mula perkenalkan penerangan data yang digunakan dalam kerja.
Rekod perubatan elektronik yang kami gunakan dalam kerja penyelidikan kami adalah daripada pangkalan data rekod perubatan elektronik sebenar sebuah hospital tertiari yang besar Setiap rekod perubatan elektronik termasuk yang berikut: Jenis maklumat: Pertama, maklumat asas pesakit, termasuk umur pesakit, jantina, insurans perubatan, dsb. kedua, maklumat makmal pesakit, termasuk keabnormalan dalam keputusan makmal yang dibimbangkan oleh doktor, dan jenis keabnormalan: tinggi, rendah, positif atau tidak dan lain-lain; yang ketiga ialah keterangan keadaan yang ditulis oleh doktor untuk pesakit: termasuk maklumat seperti mengapa pesakit dimasukkan ke hospital, serta pemeriksaan fizikal awal dan akhirnya, satu set ubat yang ditetapkan; oleh doktor untuk pesakit.
Data rekod perubatan elektronik ini ialah data heterogen, termasuk maklumat berstruktur seperti umur, jantina, ujian makmal dan maklumat teks tidak berstruktur seperti penerangan keadaan.
- Data Ubat

Untuk mengkaji interaksi antara ubat, kami mengumpul beberapa sifat ubat dan data interaksi daripada dua pangkalan pengetahuan ubat sumber terbuka dalam talian yang besar, DrugBank dan Rangkaian Farmaseutikal. Interaksi dadah adalah huraian bahasa semula jadi berdasarkan beberapa templat Seperti yang ditunjukkan dalam gambar di atas, lajur penerangan bercakap tentang bagaimana ubat tertentu boleh meningkatkan metabolisme atau melemahkan metabolisme nama. Oleh itu, selagi klasifikasi model jelas, semua interaksi ubat dalam pangkalan data boleh ditanda.
Oleh itu Oleh itu, di bawah bimbingan doktor profesional, kami menganggap interaksi ubat tidak menjadi interaksi, sinergi dan antagonisme dalam kategori ketiga , templat telah diberi anotasi dan klasifikasi interaksi ubat diperolehi.
2. Prapemprosesan data dan definisi masalah
Untuk prapemprosesan data, untuk data rekod perubatan elektronik, kami membahagikannya kepada dua Bahagian: Pesakit maklumat asas dan maklumat makmal, kami memprosesnya menjadi vektor satu-panas untuk bahagian teks penerangan penyakit, kami menukarnya menjadi teks panjang tetap melalui beberapa Padding dan Cut off. Untuk data interaksi ubat: kami menukarnya menjadi matriks interaksi dadah.
Pada masa yang sama, masalah ditakrifkan seperti berikut: diberikan sekumpulan penerangan pesakit dan pakej ubat Ground-truth yang sepadan, kami akan melatih pemarkahan yang diperibadikan fungsi, yang Pesakit yang diberikan dan pakej sampel boleh menjadi input dan output skor perlawanan. Jelas sekali, ini adalah bagaimana model diskriminasi ditakrifkan.
3. Gambaran Keseluruhan Model
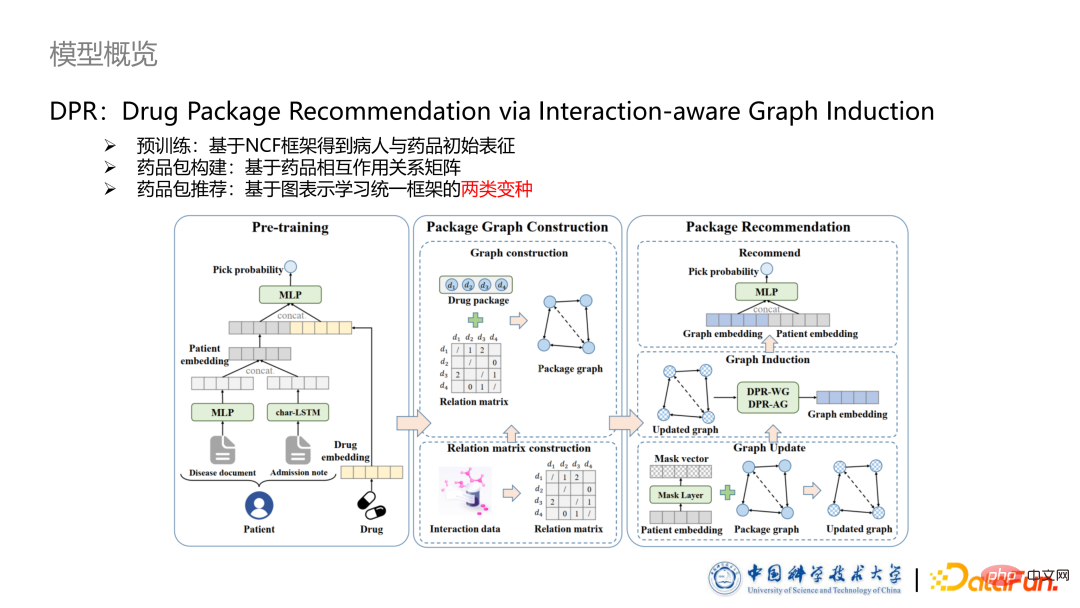
Tajuk kertas yang dicadangkan dalam artikel ini ialah DPR: Syor Pakej Dadah melalui Induksi Graf sedar Interaksi. Model ini terdiri daripada tiga bahagian:
Bahagian pra-latihan Kami memperoleh perwakilan awal pesakit dan ubat berdasarkan rangka kerja NCF.
Bahagian pembinaan pakej ubat, kami mencadangkan kaedah untuk membina bungkusan ubat menjadi graf ubat berdasarkan jenis hubungan interaksi ubat.
Bahagian terakhir ialah rangka kerja pengesyoran untuk pakej ubat berasaskan graf, di mana dua varian berbeza direka bentuk untuk memahami cara membinanya daripada dua perspektif berbeza. interaksi antara ubat model.
- Pra-latihan

Pertama sekali, bahagian pra-latihan dijalankan mengikut kaedah pengesyoran satu sama satu tradisional. Jika diberikan kes, ubat yang doktor gunakan untuk pesakit adalah kes positif, dan ubat yang belum digunakan adalah kes negatif. Pra-latihan oleh BPRLoss, markah ubat terpakai adalah lebih tinggi daripada yang belum digunakan.
Bahagian pra-latihan adalah terutamanya untuk menangkap maklumat kesan ubat asas, menyediakan asas untuk menangkap interaksi yang lebih kompleks kemudian. Untuk bahagian One-hot, kami menggunakan MLP untuk mengekstrak ciri untuk bahagian teks, kami menggunakan LSTM untuk mengekstrak ciri teks.
- Pembinaan graf ubat

Berbanding dengan pengesyoran tradisional, isu teras pengesyoran ubat ialah cara mempertimbangkan interaksi antara ubat dan mendapatkan pencirian pakej ubat. Berdasarkan ini, kertas kerja ini mencadangkan kaedah pemodelan pakej farmaseutikal berdasarkan model grafik.
Pertama, hubungan interaksi ubat yang ditanda akan ditukar menjadi matriks interaksi ubat, di mana nilai yang berbeza mewakili jenis interaksi yang berbeza. Kemudian berdasarkan detik ini, mana-mana pakej ubat yang diberikan boleh ditukar kepada graf ubat heterogen Nod dalam graf sepadan dengan ubat dalam pakej ubat, dan atribut nod adalah bahawa nod sepadan dengan Embedding yang telah dilatih dalam. langkah sebelumnya. Pada masa yang sama, untuk mengelakkan pengiraan yang berlebihan, kami tidak membina graf ubat menjadi graf lengkap, iaitu, kami tidak membenarkan kelebihan antara mana-mana dua ubat, tetapi secara terpilih mengekalkannya, hanya yang berlabel The edges pasangan ubat yang telah dilalui dan tepi yang kekerapannya melebihi ambang tertentu.
- Pembinaan peta dadah
Untuk membina peta dadah Perwakilan Berkesan, Kami mencadangkan dua cara untuk memformalkan atribut kelebihan pada, graf ubat.

Bentuk pertama ialah DPR-WG, yang menggunakan graf berwajaran untuk mewakili graf ubat. Langkah pertama ialah untuk memulakan nilai kelebihan penuh berdasarkan interaksi ubat yang ditanda, di mana -1 mewakili antagonisme, +1 mewakili sinergi, dan 0 mewakili tiada interaksi atau tidak diketahui. Vektor topeng kemudiannya digunakan untuk melakukan kemas kini diperibadikan kepada pemberat tepi dalam graf ubat.
Vektor topeng ini mencerminkan interaksi ubat-ubatan yang berbeza dan tahap impak yang diperibadikan pada pesakit individuIa dikira dengan menggunakan lapisan tak linear ditambah fungsi Sigmoid supaya Nilai setiap dimensi ialah dari 0 hingga 1, dengan itu menyedari peranan pemilihan ciri dan pelarasan peribadi interaksi dadah. Proses kemas kini graf ubat adalah untuk mengira terlebih dahulu faktor kemas kini dalam DPR-WG, dan kemudian mengemas kini faktor kemas kini dengan mendarab atau menambah berat kelebihan yang sepadan. Dalam eksperimen seterusnya, didapati bahawa kaedah kemas kini mempunyai sedikit kesan ke atas keputusan Dalam proses perwakilan graf ubat, kami mereka kaedah untuk mewakili ubat berdasarkan graf berwajaran.
Ringkasnya, kami mula-mula mereka bentuk proses kemas kini maklumat untuk graf berwajaran: mengagregatkan maklumat jiran Semasa proses pengagregatan, berdasarkan berat tepi , peribadikan darjah daripada pengagregatan. Kami kemudian menggunakan mekanisme Perhatian Sendiri untuk mengira berat antara nod yang berbeza, dan menggunakan MLP pengagregatan untuk mengagregat graf untuk mendapatkan perwakilan akhir keseluruhan graf ubat. Selepas itu, perwakilan pesakit dan perwakilan imej ubat dimasukkan ke dalam fungsi pemarkahan, dan output boleh diperolehi untuk cadangan.
Selain itu, artikel ini menggunakan BPRLoss untuk melatih model dan memperkenalkan kaedah pensampelan negatif, sepadan dengan 1 sampel positif dan 10 sampel negatif.

Varian kedua ialah menggunakan graf atribut untuk mewakili graf ubat. Langkah pertama ialah untuk memulakan vektor tepi dengan menggabungkan vektor nod pada kedua-dua hujung tepi melalui MLP. Kemudian vektor topeng juga digunakan untuk mengemas kini vektor tepi Pada masa ini, kaedah kemas kini bukan lagi faktor kemas kini, tetapi mengira vektor kemas kini Vektor kemas kini didarabkan dengan vektor tepi ubat untuk diperolehi vektor tepi yang dikemas kini. Kami direka khas GNN untuk graf atribut Proses penghantaran mesej terlebih dahulu mengira mesej berdasarkan vektor tepi dan nod Pembenaman pada kedua-dua hujung untuk penyebaran diperoleh melalui sekaedah perhatian dan pengagregatan. .
Begitu juga, kita boleh menggunakan BPRLoss untuk latihan vektor boleh mengandungi interaksi antara maklumat kategori Fungsi. Oleh kerana tanda yang dimulakan dalam varian sebelumnya secara semula jadi mengekalkan maklumat ini, tetapi graf varian ini tidak, maklumat ini ditambah dengan memperkenalkan fungsi kehilangan.

Daripada keputusan percubaan, kedua-dua model kami melebihi model diskriminasi lain dalam penunjuk penilaian yang berbeza. Pada masa yang sama, kami juga menjalankan analisis kes: menggunakan kaedah t-SNE untuk menayangkan vektor topeng yang disebut sebelum ini ke ruang dua dimensi. Seperti yang ditunjukkan dalam rajah, sebagai contoh, ubat-ubatan yang digunakan oleh wanita hamil, bayi, dan pesakit hati mempunyai kecenderungan yang sangat jelas untuk berkumpul menjadi kelompok, yang membuktikan keberkesanan kaedah kami.
3. Cadangan pakej ubat generatif
Model diskriminasi di atas hanya boleh digunakan dalam pemilihan pakej ubat sedia ada, tanpa keupayaan untuk menjana pakej ubat baru, akan menjejaskan kesan pengesyoran Seterusnya, kami akan memperkenalkan kerja lanjutan kerja terdahulu yang diterbitkan dalam jurnal TOIS Tujuannya adalah untuk berharap model itu dapat menjana ubat-ubatan baru yang disesuaikan untuk pesakit baru Pakej ubat.
Kerja ini mengekalkan idea teras pembelajaran perwakilan graf dalam kertas sebelumnya, sambil mengubah sepenuhnya definisi masalah, mentakrifkan model sebagai model generatif, dan memperkenalkan urutan Teknologi pembelajaran penjanaan dan pengukuhan telah banyak meningkatkan kesan pengesyoran.
1. Syor diskriminasi -> Syor generatif

Diskriminan Teras perbezaan antara model formula dan model generatif ialah model diskriminasi menjaringkan tahap padanan antara pesakit tertentu dan pakej ubat tertentu, manakala model generatif menjana pakej ubat calon untuk pesakit dan memilih pakej ubat terbaik.
2 kaedah penjanaan heuristik

Bertujuan kepada yang disebutkan di atas menangani kelemahan model diskriminasi, kami mereka bentuk beberapa kaedah penjanaan heuristik: dengan menambah dan memadam beberapa ubat dalam pakej ubat untuk pesakit yang serupa, beberapa pakej ubat yang tidak pernah muncul dalam rekod sejarah dibentuk untuk dipilih model. Keputusan eksperimen membuktikan bahawa kaedah mudah ini sangat berkesan dan menyediakan asas untuk kaedah seterusnya.
3 Gambaran Keseluruhan Model

Perkara berikut diterbitkan dalam Interaksi TOIS -Syor Pakej Ubat yang sedar melalui artikel Gradien Polisi. Model yang dicadangkan dalam artikel ini dipanggil DPG, yang berbeza daripada DPR dalam artikel sebelumnya G di sini ialah Generasi.
Model ini terutamanya mengandungi tiga bahagian, iaitu penyebaran maklumat mengenai gambar rajah interaksi ubat, pencirian pesakit dan modul penjanaan pakej ubat, dan di atas Perbezaan terbesar ialah modul penjanaan pakej ubat.
- Gambarajah Interaksi Dadah

Pertama bina bahagian graf interaksi ubat Artikel ini mengekalkan kaedah rangkaian saraf graf untuk menangkap interaksi antara ubat graf. Dalam model generatif, graf ubat tidak tetap Disebabkan oleh jumlah pengiraan, adalah mustahil untuk membina semua pakej ubat ke dalam graf.
Artikel ini merangkumi semua ubat dalam graf interaksi ubat, dan juga menggunakan graf Atribut untuk pemformalkan graf, sambil mengekalkan fungsi kehilangan pengelasan tepi, mengekalkan maklumat Pembenaman daripada tepi, dan akhirnya GNN berdasarkan graf interaksi ubat ini telah dibina.
Selepas beberapa pusingan (biasanya 2) penghantaran mesej, kami mengeluarkan nod Embedding sebagai ubat Embedding untuk digunakan.
- Percirian pesakit

Bahagian ciri pesakit juga MLP dan LSTM yang digunakan digunakan untuk mengekstrak vektor perwakilan pesakit, dan vektor topeng juga dikira, yang kemudiannya digunakan untuk menangkap vektor perwakilan peribadi pesakit.
- Penjanaan pakej ubat berdasarkan penjanaan urutan
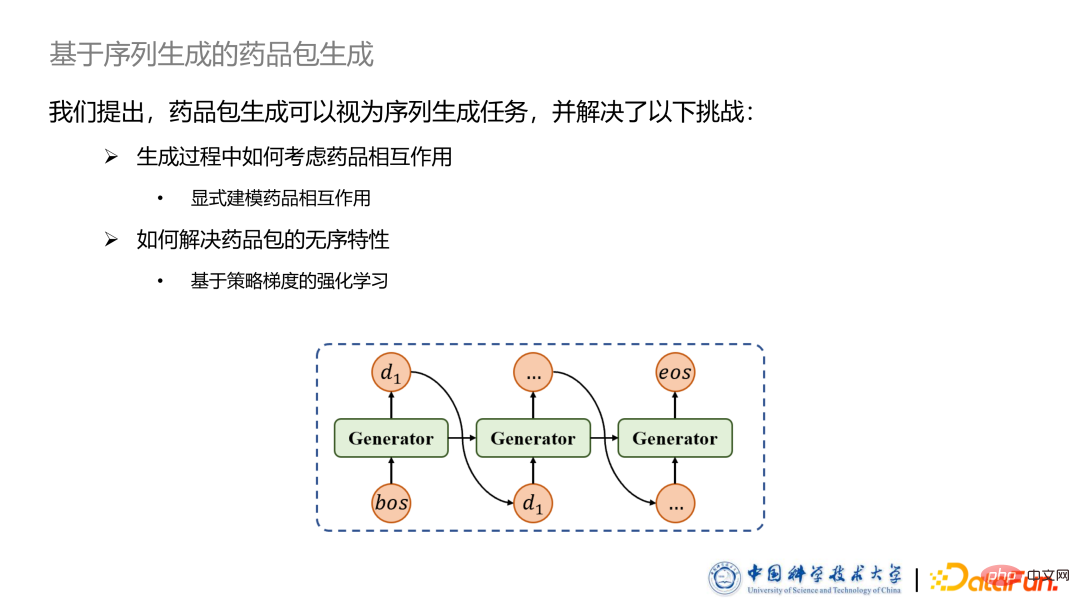
Tugas penjanaan pakej ubat boleh dianggap sebagai tugas penjanaan jujukan, yang dilaksanakan menggunakan rangkaian saraf berulang RNN. Tetapi kaedah ini juga membawa dua cabaran utama:
Cabaran pertama ialah bagaimana untuk mempertimbangkan ubat yang dihasilkan dan ubat sedia ada semasa proses penjanaan antara. Untuk tujuan ini, kami mencadangkan kaedah berdasarkan vektor interaksi ubat untuk memodelkan interaksi antara ubat secara eksplisit.
Cabaran kedua ialah pakej sampel ialah koleksi, yang pada asasnya tidak tertib, tetapi tugas penjanaan jujukan selalunya menyasarkan kaedah jujukan tertib. Untuk tujuan ini, kami mencadangkan kaedah pembelajaran pengukuhan berdasarkan kecerunan dasar, dan menambah kaedah berdasarkan SCST untuk meningkatkan kesan dan kestabilan algoritma ini.
- Penjanaan pakej ubat berdasarkan kemungkinan maksimum

. Kaedah penjanaan jujukan berdasarkan kemungkinan maksimum telah digunakan secara meluas dalam bidang NLP Semasa proses penjanaan, setiap ubat yang dihasilkan bergantung kepada ubat lain yang dihasilkan sebelum ini.
Untuk mengambil kira interaksi antara ubat tanpa membawa beban pengiraan yang berlebihan kepada model, kami mencadangkan untuk secara eksplisit Mengira vektor interaksi antara ubat yang baru dihasilkan dan ubat sebelumnya Kaedah pengiraan vektor ini berasal dari lapisan dalam rangkaian saraf graf sebelumnya.
Pada masa yang sama, kami menambah vektor topeng dan vektor interaksi untuk mendarab elemen yang sepadan untuk memperkenalkan maklumat peribadi pesakit.
Akhir sekali, jumlahkan vektor interaksi semua ubat dan gunakan MLP untuk menggabungkannya untuk mendapatkan vektor interaksi yang komprehensif.
Selepas itu, penyepaduan vektor ini ke dalam model jujukan klasik untuk penjanaan menyelesaikan cabaran pertama.

Berbeza dengan penjanaan urutan klasik, pakej ubat sebenarnya adalah koleksi dan tidak sepatutnya ada ubat pendua, jadi kami Kemudian, sekatan telah ditambah untuk menghalang model daripada menghasilkan ubat yang telah dijana, memastikan hasil yang dihasilkan mestilah satu set. Akhir sekali, kami menggunakan fungsi kehilangan MLE berdasarkan kemungkinan maksimum untuk melatih model.
- Penjanaan pakej ubat berdasarkan pembelajaran pengukuhan

Kelemahan terbesar kaedah di atas berdasarkan kebarangkalian maksimum ialah pakej ubat mempunyai susunan yang ketat Beberapa kaedah untuk menentukan urutan ubat secara buatan, seperti mengisih mengikut kekerapan, menyusun mengikut dahulu surat, dsb., akan memusnahkan dadah Ciri-ciri koleksi pakej juga akan kehilangan sebahagian daripada prestasi model, jadi kami mencadangkan model penjanaan pakej ubat berdasarkan pembelajaran pengukuhan. Matlamat model dalam pembelajaran pengukuhan adalah untuk memaksimumkan fungsi ganjaran yang ditetapkan secara buatan Selepas model menghasilkan pakej ubat yang lengkap, memberikan fungsi kehilangan ganjaran yang bebas daripada perintah boleh mengurangkan pergantungan model pada pesanan.
Artikel ini menggunakan nilai-F sebagai ganjaran, yang merupakan fungsi bebas pesanan dan merupakan indeks penilaian yang kami bimbang. Artikel ini menggunakan nilai-F sebagai indeks penilaian, dan menggunakan kaedah latihan berdasarkan kecerunan dasar dalam kaedah latihan, dan tidak akan disimpulkan secara terperinci di sini.

Antara kaedah latihan berdasarkan kecerunan dasar, kaedah yang terkenal ialah menggunakan garis dasar untuk mengurangkan varians daripada anggaran kecerunan, dengan itu meningkatkan kestabilan latihan. Oleh itu, kami menggunakan kaedah latihan berasaskan SCST iaitu kaedah latihan urutan Kritikal Kendiri. Garis dasar juga datang daripada ganjaran yang diperolehi oleh pakej ubat yang dihasilkan oleh model itu sendiri.
Kami berharap ganjaran pakej ubat yang disampel oleh model berdasarkan kecerunan Polisi adalah lebih tinggi daripada pakej ubat yang dijana oleh carian Greedy tradisional. Berdasarkan ini, artikel ini mereka bentuk fungsi kerugian untuk pembelajaran pengukuhan, seperti yang ditunjukkan dalam rajah Proses derivasi tidak akan diperkenalkan secara terperinci di sini.
- Kemungkinan maksimum pra-latihan + pembelajaran pengukuhan

Selain itu, salah satu ciri pembelajaran pengukuhan ialah latihan adalah sukar, jadi kami menggabungkan dua kaedah latihan di atas, pertama menggunakan kaedah anggaran yang sangat semula jadi untuk melatih model, dan kemudian menggunakan kaedah pembelajaran pengukuhan untuk memperhalusi parameter model.
- Hasil eksperimen
Langkah seterusnya ialah eksperimen daripada hasil model.

Dalam jadual di atas, semua pakej ubat dijana menggunakan carian Greedy. Pertama sekali, prestasi kaedah berdasarkan model generatif secara amnya lebih baik daripada kaedah berdasarkan model diskriminatif Eksperimen ini membuktikan bahawa model generatif akan menjadi pilihan yang lebih baik. Model ini mengatasi semua garis dasar lain dalam nilai F. Selain itu, prestasi model berdasarkan pembelajaran pengukuhan sangat mengatasi model berdasarkan kemungkinan maksimum, membuktikan keberkesanan kaedah pembelajaran pengukuhan.

Seterusnya, kami juga menjalankan satu siri eksperimen ablasi. Kami mengalih keluar graf interaksi, termasuk vektor topeng interaksi dan modul pembelajaran pengukuhan untuk ablasi, dan hasilnya membuktikan bahawa setiap modul kami berkesan. Pada masa yang sama, dapat dilihat bahawa jika modul SCST dibuang, kesan model menurun dengan ketara, yang membuktikan bahawa pembelajaran pengukuhan sememangnya sukar untuk dilatih. Tanpa sekatan Baseline, keseluruhan proses latihan akan menjadi sangat gelisah.

Akhir sekali, kami juga melakukan banyak analisis kes, dan kami dapat melihat bahawa wanita hamil dan bayi mempunyai pilihan peribadi yang jelas. Pada masa yang sama, kami menambah beberapa penyakit biasa tambahan seperti penyakit perut, penyakit jantung, dll. Vektor topeng penyakit ini sangat bertaburan dan tidak membentuk kelompok. Keadaan pesakit dengan penyakit biasa adalah pelbagai, dan tidak akan ada situasi yang diperibadikan secara khusus Tidak seperti wanita hamil dan bayi, terdapat pemeriksaan yang sangat jelas untuk ubat-ubatan Sebagai contoh, ubat pediatrik tertentu perlu ditetapkan, dan beberapa ubat tidak boleh digunakan oleh wanita hamil.
Pada masa yang sama, kami mengunjurkan vektor interaksi dadah Kami dapat melihat bahawa kedua-dua ubat, sinergi dan antagonisme, membentuk dua pertentangan yang berbeza apabila berinteraksi satu sama lain, menunjukkan bahawa model menangkap kesan berbeza yang dibawa oleh dua interaksi yang berbeza.
4 Ringkasan dan Tinjauan
Ringkasnya, penyelidikan kami terutamanya mengenai pemperibadian sedar interaksi pengesyoran pakej ubat. termasuk pengesyoran pakej ubat yang diskriminatif dan pengesyoran pakej ubat generatif.
Kedua-duanya mempunyai persamaan iaitu kedua-duanya menggunakan teknologi pembelajaran perwakilan graf untuk memodelkan interaksi antara ubat, dan kedua-duanya menggunakan vektor topeng untuk mempertimbangkan keadaan pesakit bagi setiap lain. Persepsi kesan yang diperibadikan.
Perbezaan terbesar antara kedua-dua karya ialah perbezaan dalam definisi masalah Untuk model diskriminasi, apa yang kita mahukan ialah fungsi pemarkahan, jadi untuk model generatif , apa yang kita mahukan ialah generasi Telah dibuktikan melalui eksperimen bahawa model generatif sebenarnya adalah definisi masalah yang lebih baik.
Atas ialah kandungan terperinci Angka ini menggambarkan aplikasi teknik pembelajaran dalam sistem pengesyoran dadah.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI