
Rumah >Peranti teknologi >AI >Cara melayan ChatGPT secara munasabah: perbincangan mendalam oleh sarjana simbolisme sepuluh tahun.
Cara melayan ChatGPT secara munasabah: perbincangan mendalam oleh sarjana simbolisme sepuluh tahun.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-08 19:28:071633semak imbas
Dalam sepuluh tahun yang lalu, penghubung, dengan sokongan pelbagai model pembelajaran mendalam, telah menerajui simbolisme pada landasan kecerdasan buatan dengan memanfaatkan kuasa data besar dan kuasa pengkomputeran tinggi.
Tetapi setiap kali model pembelajaran mendalam baharu dikeluarkan, seperti ChatGPT yang popular baru-baru ini, selepas memuji prestasinya yang hebat, terdapat perbincangan hangat mengenai kaedah penyelidikan itu sendiri, dan kelemahan serta kecacatan model itu sendiri juga akan dibincangkan.
Baru-baru ini, Dr. Qian Xiaoyi dari Beiming Laboratory, sebagai saintis dan usahawan yang telah mematuhi sekolah simbolik selama sepuluh tahun, menerbitkan penilaian yang agak tenang dan objektif bagi model ChatGPT.
Secara keseluruhannya, kami berpendapat ChatGPT ialah acara penting.
Model pra-latihan mula menunjukkan kesan yang kuat pada tahun yang lalu. Kali ini ia telah mencapai tahap baru dan menarik lebih banyak perhatian dan selepas kejayaan ini, banyak model kerja yang berkaitan dengan bahasa semula jadi manusia akan bermula , malah sebilangan besar daripadanya digantikan oleh mesin.
Tiada teknologi dicapai dalam sekelip mata daripada melihat kelemahannya, seorang pekerja saintifik harus lebih peka terhadap potensinya.
Boundary of Symbolism & Connectionism
Pasukan kami memberi perhatian khusus kepada ChatGPT kali ini, bukan kerana kesan menakjubkan yang dilihat oleh orang ramai, kerana kami masih boleh memahami banyak kesan yang kelihatan menakjubkan pada peringkat teknikal.
Apa yang benar-benar memberi kesan kepada deria kita ialah beberapa tugasnya menembusi sempadan antara genre simbolik dan genre saraf - kebolehan logik ChatGPT nampaknya merangkumi keupayaan ini dalam beberapa tugas seperti pengekodan sendiri dan menilai kod .
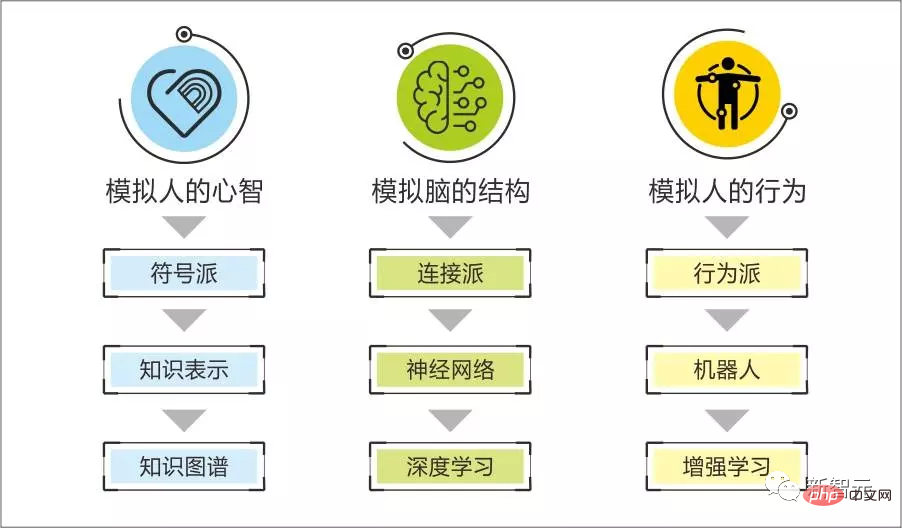
Kami sentiasa percaya bahawa genre simbolik bagus untuk menghasilkan semula kecerdasan logik manusia yang kuat, seperti cara menyelesaikan masalah, menganalisis punca masalah, mencipta alat, dsb.;
Intipati connectionism ialah algoritma statistik, yang digunakan untuk menemui corak lancar daripada sampel, seperti mencari corak apa yang hendak dikatakan dalam ayat seterusnya melalui pencarian manusia yang mencukupi; surat-menyurat melalui teks deskriptif Peraturan pengecaman dan penjanaan imej...
Kita boleh memahami kebolehan ini dan menjadi sangat cemerlang melalui model yang lebih besar, data yang lebih berkualiti tinggi dan peningkatan gelung pembelajaran pengukuhan.
Kami percaya bahawa manusia mempunyai ciri-ciri kedua-dua laluan teknikal simbolik dan saraf, seperti semua proses kognitif reflektif, pembelajaran pengetahuan dan proses aplikasi, sejumlah besar pemikiran reflektif, tingkah laku, corak ekspresi, Motif reflektif dan emosi mudah dijelaskan dan diterbitkan semula secara sistematik berdasarkan perwakilan simbolik.
Apabila anda melihat wajah asing yang mencukupi, anda akan mempunyai keupayaan untuk mengenali wajah asing, dan anda tidak dapat menjelaskan sebabnya
Ia akan muncul secara semula jadi selepas menonton siri TV pertama Tiru lelaki itu keupayaan protagonis untuk bercakap;
Boleh bersembang tanpa berfikir selepas mengalami perbualan yang mencukupi.
Kita boleh membandingkan bahagian logik yang kuat dengan tulang yang sedang membesar, dan "keupayaan yang tidak logik untuk memahami undang-undang" dengan daging yang sedang membesar.
Sukar untuk "tumbuh daging" dengan kebolehan simbol "tumbuh rangka", dan juga sukar bagi saraf untuk "tumbuh rangka" dengan keupayaan "tumbuh daging".
Sama seperti kita mengiringi proses pembinaan AI, sistem simbol pandai memahami dimensi khusus maklumat lawan bicara, menganalisis niat di sebaliknya, membuat kesimpulan peristiwa berkaitan dan memberikan cadangan yang tepat, tetapi ia adalah tidak pandai mencipta perbualan yang lancar dan semula jadi.
Kami juga melihat bahawa walaupun model penjanaan dialog yang diwakili oleh GPT boleh mencipta dialog yang lancar, ia menggunakan ingatan jangka panjang untuk mewujudkan persahabatan yang koheren, menjana motivasi emosi yang munasabah dan menyelesaikan penaakulan logik dengan kedalaman tertentu dalam dialog. Sukar untuk melaksanakan cadangan analisis dalam aspek ini.
"Kebesaran" model besar bukanlah satu kelebihan, tetapi harga yang dibayar oleh algoritma statistik untuk cuba memahami sebahagian daripada peraturan yang diterajui logik yang kukuh yang wujud dalam data permukaan. Ia merangkumi sempadan antara simbol dan saraf.
Setelah memahami lebih mendalam tentang prinsip ChatGPT, kami mendapati bahawa ia hanya menganggap operasi logik yang agak mudah sebagai sejenis penjanaan latihan biasa, dan tidak menembusi skop algoritma statistik asal - juga Itu ialah, penggunaan sistem masih akan meningkat secara geometri apabila kedalaman tugas logik meningkat.
Tetapi mengapa ChatGPT boleh menembusi had model besar asal?
Bagaimana ChatGPT melanggar had teknikal model besar biasa
Mari kami terangkan dalam bahasa bukan teknikal prinsip di sebalik cara ChatGPT melanggar had model besar yang lain.
GPT3 menunjukkan pengalaman yang mengatasi model besar lain apabila ia muncul. Ini berkaitan dengan penyeliaan diri, iaitu pelabelan kendiri data.
Masih mengambil penjanaan dialog sebagai contoh: model besar telah dilatih dengan data besar-besaran untuk menguasai peraturan 60 pusingan dialog dan ayat seterusnya.
Mengapa anda memerlukan begitu banyak data? Mengapakah manusia boleh meniru pertuturan protagonis lelaki selepas menonton siri TV?

Oleh kerana manusia tidak menggunakan pusingan dialog sebelumnya sebagai input untuk memahami peraturan apa yang perlu dikatakan dalam ayat seterusnya, tetapi membentuk pemahaman konteks semasa proses dialog subjektif: keperibadian penutur, jenis emosi semasa dia mempunyai, Motivasi, jenis pengetahuan yang dikaitkan dengannya, ditambah pusingan sebelumnya dialog untuk memahami peraturan apa yang perlu dikatakan dalam ayat seterusnya.
Kita boleh bayangkan bahawa jika model besar mula-mula mengenal pasti unsur kontekstual dialog dan kemudian menggunakannya untuk menjana peraturan ayat seterusnya, berbanding dengan menggunakan dialog asal, keperluan data untuk mencapai kesan yang sama boleh dikurangkan dengan banyak. Oleh itu, sejauh mana penyeliaan kendiri dilakukan adalah faktor penting yang mempengaruhi "kecekapan model" model besar.
Untuk memeriksa sama ada perkhidmatan model besar telah melabelkan sendiri jenis maklumat kontekstual tertentu semasa latihan, anda boleh memeriksa sama ada penjanaan dialog sensitif terhadap maklumat kontekstual tersebut (sama ada dialog yang dijana mencerminkan Pertimbangan maklumat kontekstual ini) kepada hakim.
Tulisan manusia tentang output yang diingini adalah perkara kedua yang akan dimainkan.
ChatGPT menggunakan output bertulis secara manual dalam beberapa jenis tugasan untuk memperhalusi model besar GPT3.5 yang telah mempelajari peraturan am penjanaan dialog.
Inilah semangat model pra-latihan - peraturan dialog adegan tertutup sebenarnya mungkin mencerminkan lebih daripada 99% peraturan am penjanaan dialog manusia, manakala peraturan khusus adegan kurang daripada 1 %. Oleh itu, model besar yang telah dilatih untuk memahami peraturan am dialog manusia dan model kecil tambahan untuk adegan tertutup boleh digunakan untuk mencapai kesan, dan sampel yang digunakan untuk melatih peraturan khusus adegan boleh menjadi sangat kecil.

Mekanisme seterusnya yang akan dimainkan ialah ChatGPT menyepadukan pembelajaran pengukuhan Keseluruhan prosesnya kira-kira seperti ini:
Persediaan permulaan: pra-terlatih. model (GPT-3.5), sekumpulan makmal yang terlatih, satu siri gesaan (arahan atau soalan, dikumpulkan daripada proses penggunaan sejumlah besar pengguna dan reka bentuk laber).
Langkah1: Sampel secara rawak dan dapatkan sebilangan besar gesaan, dan kakitangan data (laber) memberikan respons piawai berdasarkan gesaan. Saintis data boleh memasukkan gesaan ke dalam GPT-3.5 dan merujuk kepada output model untuk membantu dalam menyediakan jawapan kanonik.
Dengan cara ini, data
Model GPT-3.5 diperhalusi melalui pembelajaran diselia berdasarkan set data ini Model yang diperoleh selepas penalaan halus dipanggil GPT-3.X buat sementara waktu.
Langkah2: Sampel beberapa gesaan secara rawak (kebanyakan daripadanya telah dijadikan sampel dalam langkah1), dan hasilkan K jawapan (K>=2) melalui GPT-3.X untuk setiap gesaan.
Laber mengisih respons K Sebilangan besar data perbandingan yang diisih boleh membentuk set data dan model pemarkahan boleh dilatih berdasarkan set data ini.
Langkah3: Gunakan strategi pembelajaran pengukuhan PPO untuk mengemas kini GPT-3.X dan model pemarkahan secara berulang, dan akhirnya mendapatkan model dasar. GPT-3.X memulakan parameter model dasar, sampel beberapa gesaan yang belum diambil sampel dalam langkah1 dan langkah2, menjana output melalui model dasar dan menjaringkan output mengikut model pemarkahan.
Kemas kini parameter model dasar berdasarkan kecerunan dasar yang dijana oleh pemarkahan untuk mendapatkan model dasar yang lebih berkebolehan.
Biarkan model dasar yang lebih kukuh mengambil bahagian dalam langkah 2, dapatkan set data baharu melalui pengisihan dan anotasi laber, dan kemas kininya untuk mendapatkan model pemarkahan yang lebih munasabah.
Apabila model pemarkahan yang dikemas kini mengambil bahagian dalam langkah 3, model strategi yang dikemas kini akan diperolehi. Lakukan langkah 2 dan 3 secara berulang, dan model dasar terakhir ialah ChatGPT.
Jika anda tidak biasa dengan bahasa di atas, berikut adalah metafora yang mudah difahami: Ini seperti meminta ChatGPT belajar seni mempertahankan diri. Tindak balas manusia adalah rutin master seorang peminat seni mempertahankan diri Rangkaian saraf pemarkahan ialah penilai, memberitahu ChatGPT yang beraksi lebih baik dalam setiap permainan.
Jadi ChatGPT boleh melihat perbandingan antara tuan manusia dan GPT3.5 buat kali pertama, memperbaikinya sedikit ke arah tuan manusia berdasarkan GPT3.5, dan kemudian biarkan ChatGPT yang berkembang digunakan sebagai seorang Peminat seni mempertahankan diri mengambil bahagian dalam perbandingan dengan tuan manusia, dan rangkaian saraf pemarkahan memberitahunya lagi di mana jurang itu, supaya ia boleh menjadi lebih baik lagi.
Apakah perbezaan antara rangkaian neural ini dan tradisional?
Rangkaian saraf tradisional secara langsung membenarkan rangkaian saraf meniru tuan manusia, dan model baharu ini membolehkan rangkaian saraf memahami perbezaan antara peminat seni mempertahankan diri dan tuan, supaya ia boleh belajar daripada manusia berdasarkan sedia ada Buat pelarasan halus kepada arahan tuan dan terus perbaiki.
Dapat dilihat daripada prinsip di atas bahawa model besar yang dihasilkan dengan cara ini mengambil sampel berlabel manusia sebagai had prestasi.
Dengan kata lain, ia hanya menguasai corak tindak balas sampel berlabel manusia secara melampau, tetapi ia tidak mempunyai keupayaan untuk mencipta corak tindak balas baharu, kedua, sebagai jenis algoritma statistik, kualiti sampel akan; menjejaskan ketepatan model keluaran Sex, ini adalah kecacatan maut ChatGPT dalam senario carian dan perundingan.
Keperluan yang serupa dengan perundingan kesihatan adalah ketat, yang tidak sesuai untuk model jenis ini disiapkan secara bebas.
Keupayaan pengekodan dan keupayaan penilaian kod yang terkandung oleh ChatGPT datang daripada sejumlah besar kod, anotasi penerangan kod dan rekod pengubahsuaian pada github Ini masih dalam jangkauan algoritma statistik.
Isyarat baik yang dihantar oleh ChatGPT ialah kita sememangnya boleh menggunakan lebih banyak idea seperti "human focusing" dan "reinforcement learning" untuk meningkatkan "model efficiency".
"Besar" bukan lagi satu-satunya penunjuk yang dikaitkan dengan keupayaan model. Contohnya, InstructGPT dengan 1.3 bilion parameter adalah lebih baik daripada GPT-3 dengan 17.5 bilion parameter.
Walau bagaimanapun, kerana penggunaan sumber pengkomputeran melalui latihan hanyalah satu daripada ambang untuk model besar, diikuti dengan data berkualiti tinggi dan berskala besar, kami percaya bahawa landskap perniagaan awal masih: asas untuk pengeluar besar untuk menyediakan model besar Kemudahan pembinaan, kilang kecil membuat aplikasi super berdasarkan ini. Kilang-kilang kecil yang telah menjadi gergasi kemudiannya akan melatih model besar mereka sendiri.
Gabungan simbol dan saraf
Kami percaya bahawa potensi gabungan simbol dan saraf tercermin dalam dua perkara: melatih "daging" pada "tulang" dan menggunakan "daging" pada "tulang".
Jika sampel permukaan mengandungi konteks logik (tulang) yang kuat, seperti dalam contoh latihan dialog sebelum ini, elemen kontekstual ialah tulang, maka adalah sangat mahal untuk hanya melatih peraturan yang mengandungi tulang daripada sampel permukaan. Ini ditunjukkan dalam permintaan untuk sampel dan kos latihan model yang lebih tinggi, iaitu, "kebesaran" model besar.
Jika kita menggunakan sistem simbolik untuk menjana konteks dan menggunakannya sebagai input sampel untuk rangkaian saraf, ia adalah bersamaan dengan mencari corak dalam keadaan latar belakang pengiktirafan logik yang kuat dan melatih "daging" pada "tulang". ".
Jika model besar dilatih dengan cara ini, outputnya akan menjadi sensitif kepada keadaan logik yang kukuh.
Sebagai contoh, dalam tugas penjanaan dialog, kami memasukkan emosi semasa, motivasi, pengetahuan yang berkaitan dan peristiwa berkaitan kedua-dua pihak yang mengambil bahagian dalam dialog tersebut maklumat kontekstual dengan kebarangkalian tertentu. Ini menggunakan "daging" pada "tulang" logik yang kuat.
Sebelum ini, kami menghadapi masalah bahawa simbol tidak dapat mencipta perbualan yang lancar dalam pembangunan AI peringkat teman Jika pengguna tidak mahu bercakap dengan AI, semua keupayaan logik dan emosi di sebalik AI akan. tidak akan dipaparkan, dan tidak akan ada pengoptimuman dan lelaran yang berterusan, kami menyelesaikan kelancaran dialog dengan menggabungkannya dengan model pra-latihan yang serupa dengan yang di atas.
Dari perspektif model besar, hanya mencipta AI dengan model besar tidak mempunyai integriti dan tiga dimensi.
"Holistik" terutamanya ditunjukkan dalam sama ada ingatan jangka panjang berkaitan konteks dipertimbangkan dalam penjanaan dialog.
Sebagai contoh, dalam sembang antara AI dan pengguna pada hari sebelumnya, mereka bercakap tentang pengguna yang mengalami selsema, pergi ke hospital, mengalami pelbagai gejala, dan berapa lama ia bertahan... ; keesokan harinya pengguna tiba-tiba menyatakan, "Sakit tekak saya baik-baik saja".
Dalam model besar yang ringkas, AI akan bertindak balas terhadap kandungan dalam konteks dan akan menyatakan "Mengapa tekak saya sakit?", "Adakah anda pergi ke hospital?"... Ungkapan ini serta-merta dikaitkan dengan percanggahan ingatan jangka panjang, mencerminkan ketidakkonsistenan ingatan jangka panjang.
Dengan menggabungkan dengan sistem simbol, AI boleh mengaitkan daripada "pengguna masih sakit tekak pada hari berikutnya" kepada "pengguna mengalami selsema semalam" kepada "pengguna telah ke hospital", " simptom lain pengguna"... Meletakkan maklumat ini ke dalam konteks boleh menggunakan keupayaan ketekalan kontekstual model besar untuk mencerminkan ketekalan ingatan jangka panjang.
"Deria tiga dimensi" dicerminkan sama ada AI mempunyai obsesi.
Sama ada anda akan taksub dengan emosi, motivasi dan idea anda sendiri seperti manusia. AI yang dicipta oleh model besar yang mudah secara rawak akan mengingatkan seseorang untuk kurang minum ketika bersosial, tetapi apabila digabungkan dengan sistem simbol, ia akan mengetahui bahawa hati pengguna tidak baik dalam ingatan jangka panjang, dan digabungkan dengan yang biasa. merasakan bahawa hati pengguna tidak baik dan tidak boleh minum, mesej yang kuat dan berterusan akan dihasilkan untuk menghalang pengguna daripada minum Adalah disyorkan untuk membuat susulan sama ada pengguna minum alkohol selepas bersosial, dan kekurangan disiplin diri pengguna akan. mempengaruhi mood, sekali gus menjejaskan perbualan seterusnya Ini adalah cerminan deria tiga dimensi.
Adakah model besar itu merupakan kecerdasan buatan umum?
Berdasarkan mekanisme pelaksanaan model pra-latihan, ia tidak menembusi keupayaan algoritma statistik untuk "memahami corak sampel". Ia hanya mengambil kesempatan daripada pembawa komputer untuk membawa keupayaan ini kepada a tahap yang sangat tinggi, malah Ia mencerminkan ilusi bahawa ia mempunyai keupayaan logik tertentu dan keupayaan menyelesaikan.
Model mudah terlatih tidak akan mempunyai kreativiti manusia, keupayaan penaakulan logik yang mendalam dan keupayaan untuk menyelesaikan tugas yang rumit.
Jadi model pra-latihan mempunyai tahap serba boleh tertentu disebabkan oleh penghijrahan kos rendah ke senario tertentu, tetapi ia tidak mempunyai kecerdasan umum manusia yang "mengeneralisasikan perwakilan pintar atasan yang sentiasa berubah-ubah. lapisan melalui mekanisme perisikan asas yang terhad."
Kedua, kami ingin bercakap tentang "kemunculan". Dalam kajian model besar, penyelidik akan mendapati bahawa apabila skala parameter model dan skala data melebihi nilai kritikal tertentu, beberapa penunjuk keupayaan meningkat dengan cepat, menunjukkan kemunculan. kesan .
Malah, mana-mana sistem dengan keupayaan pembelajaran abstrak akan mempamerkan "kemunculan".
Ini berkaitan dengan sifat operasi abstrak - "tidak terobsesi dengan ketepatan sampel atau tekaan individu, tetapi berdasarkan ketepatan statistik keseluruhan sampel atau tekaan."
Jadi apabila saiz sampel mencukupi dan model boleh menyokong penemuan corak terperinci dalam sampel, keupayaan tertentu akan terbentuk secara tiba-tiba.
Dalam projek pemikiran separa simbolik, kita melihat bahawa proses pembelajaran bahasa AI simbolik juga akan "muncul" seperti pemerolehan bahasa kanak-kanak manusia Selepas mendengar dan membaca pada tahap tertentu, mendengar dan membaca Pemahaman dan keupayaan anda untuk bercakap akan bertambah baik dengan pesat.
Ringkasnya, tidak mengapa untuk kita menganggap kemunculan sebagai fenomena, tetapi kita harus mentafsir semua mutasi fungsi sistem dengan mekanisme yang tidak jelas sebagai kemunculan, dan menjangkakan bahawa algoritma mudah boleh muncul dengan kecerdasan keseluruhan manusia pada masa tertentu. Ini bukan sikap saintifik yang ketat.
Kecerdasan Buatan Umum
Konsep kecerdasan buatan wujud hampir dengan kemunculan komputer Pada masa itu, ia adalah idea yang mudah, memindahkan kecerdasan manusia ke dalam komputer titik permulaan, konsep terawal kecerdasan buatan merujuk kepada "kecerdasan buatan umum".
Model kecerdasan manusia ialah kecerdasan am, dan pemindahan model kecerdasan ini kepada komputer ialah kecerdasan buatan am.
Selepas itu, banyak sekolah muncul yang cuba menghasilkan semula mekanisme kecerdasan manusia, tetapi tidak satu pun daripada sekolah ini mencipta keputusan cemerlang, Rich Sutton, saintis cemerlang Deepmind dan pengasas pembelajaran pengukuhan, menyatakan dengan tegas. pandangan:
Pengajaran terbesar yang boleh dipelajari daripada penyelidikan kecerdasan buatan selama 70 tahun yang lalu ialah untuk mencapai hasil dalam jangka pendek, penyelidik lebih suka menggunakan pengalaman dan pengetahuan manusia dalam bidang itu. (meniru mekanisme manusia), Dalam jangka masa panjang, menggunakan kaedah pengkomputeran am berskala adalah yang paling berkesan.
Pencapaian cemerlang model besar hari ini membuktikan ketepatan cadangannya tentang "algoritma", tetapi ini tidak bermakna bahawa jalan mencipta agen pintar dengan "meniru penciptaan dan mencipta manusia" semestinya salah.
Jadi mengapa sekolah terdahulu yang mengikuti manusia mengalami kemunduran satu demi satu? Ini berkaitan dengan keutuhan teras kecerdasan manusia.
Ringkasnya, subsistem yang dibentuk oleh bahasa manusia, kognisi, membuat keputusan emosi dan kebolehan pembelajaran saling menyokong antara satu sama lain dalam merealisasikan kebanyakan tugas, dan tiada subsistem boleh berjalan secara bebas.
Sebagai sistem yang sangat bersepadu, kemunculan lapisan atas datang daripada kerjasama banyak mekanisme asas selagi salah satu daripadanya rosak, ia akan menjejaskan penampilan kesan permukaan ini.
Sama seperti tubuh manusia, ia juga merupakan sistem yang sangat kompleks. Mungkin terdapat sedikit perbezaan antara orang yang sihat dan orang yang sakit, tetapi perbezaan patologi yang halus ini menghalang fungsi seseorang dalam semua dimensi.
Begitu juga, untuk kecerdasan buatan am, kesan 99 langkah pertama mungkin sangat terhad Apabila kita melengkapkan bahagian terakhir teka-teki, fungsi 99 langkah pertama akan menjadi jelas.
Sekolah terdahulu telah melihat sebahagian daripada keseluruhan kecerdasan manusia dari perspektif mereka sendiri, dan telah mencapai keputusan tertentu dalam meniru manusia, tetapi ini hanyalah sebahagian kecil berbanding tenaga yang boleh dikeluarkan oleh keseluruhan sistem.
Kecerdasan Proses dan Tamadun Manusia
Setiap kecerdasan tempatan manusia telah atau sedang jauh diatasi oleh komputer, tetapi walaupun semua kecerdasan tempatan diatasi oleh komputer, kita masih boleh menegaskan bahawa hanya Manusia boleh mencipta tamadun, komputer hanyalah alat.
Kenapa?
Kerana di sebalik penciptaan tamadun terdapat proses pelbagai aktiviti kepintaran manusia, yang bermaksud tamadun manusia berasal dari "process intelligence". Ini adalah arah yang sangat diabaikan pada masa ini.
"Proses kognitif" bukan satu tugas, ia adalah penyusunan banyak tugas dalam satu proses.
Sebagai contoh, jika AI ingin menyembuhkan simptom pesakit, ia adalah tugas "penyelesaian matlamat".
Pertama sekali, kita perlu beralih kepada penyelesaian atribusi, yang dianggap sebagai tugas kognitif Selepas mencari punca yang mungkin, ia menjadi tugas "menyelesaikan kejadian tertentu" untuk menentukan sama ada penyakit yang mungkin telah berlaku. Tugasan ini akan diteruskan lagi.
Anda boleh memperoleh pengetahuan sedia ada melalui bertanya, mencari dan membaca, atau anda boleh menggunakan "kognisi statistik"; selepas kognisi statistik menemui korelasi, anda boleh mendapatkan cerapan lanjut tentang rantaian sebab di belakangnya untuk mencapai campur tangan yang lebih baik. Langkah ini sering beralih kepada penyelesaian pengetahuan kerana kekurangan pengetahuan Untuk mengesahkan tekaan, perlu untuk mereka bentuk eksperimen untuk menyelesaikan kejadian tertentu...
Selepas mempunyai rantai sebab, anda boleh cuba mencapai matlamat sekali lagi dan menjalankan rantaian sebab-akibat mengubah matlamat asal kepada mencipta, menamatkan, mencegah dan mengekalkan peristiwa dalam rantaian sebab-sebab Ini kembali kepada proses "penyelesaian matlamat". 🎜>

Kita boleh bayangkan bahawa jika kita boleh menghasilkan semula kecerdasan keseluruhan manusia pada komputer, supaya mesin dapat menyokong proses penerokaan kognisi secara bebas, mencipta alat, menyelesaikan masalah dan mencapai matlamat, dengan kelebihan pembawa komputer, keseluruhan kecerdasan manusia dan Kepintaran proses diperkuatkan seperti sebelumnya, dan hanya dengan itu kita boleh benar-benar melepaskan kuasa kecerdasan buatan dan menyokong tamadun manusia ke tahap yang lebih tinggi.
Mengenai pengarang

Pengarang Dr. Qian Xiaoyi ialah seorang saintis kecerdasan buatan simbolik, jurutera kanan, bakat bertauliah peringkat tinggi di Hangzhou, dan seorang pengguna awal rangka kerja bionik logik Explorer, pencipta edisi pertama simbol bahasa M. Pengasas, Ketua Pegawai Eksekutif dan Pengerusi Bei Mingxing Mou.
Ph.D. dalam Ekonomi Gunaan dari Shanghai Jiao Tong University, Sarjana Kejuruteraan Kewangan dari CGU Drucker School of Business, Amerika Syarikat, ijazah sarjana muda berganda dalam Matematik dan Kewangan dari Kelas Elit Matematik Yau Shing-tung Zhu Kezhen Kolej Universiti Zhejiang. Beliau telah menyelidik dalam bidang AI am selama 11 tahun dan telah mengetuai pasukan dalam amalan kejuruteraan selama 7 tahun.
Atas ialah kandungan terperinci Cara melayan ChatGPT secara munasabah: perbincangan mendalam oleh sarjana simbolisme sepuluh tahun.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI