
Rumah >Peranti teknologi >AI >Penambahbaikan Keciciran boleh digunakan untuk mengurangkan masalah yang tidak sesuai.
Penambahbaikan Keciciran boleh digunakan untuk mengurangkan masalah yang tidak sesuai.

- 王林ke hadapan
- 2023-05-07 23:43:061380semak imbas
Pada tahun 2012, Hinton et al mencadangkan keciciran dalam kertas kerja mereka "Memperbaiki rangkaian saraf dengan menghalang penyesuaian bersama pengesan ciri". Pada tahun yang sama, kemunculan AlexNet membuka era baharu pembelajaran mendalam. AlexNet menggunakan keciciran untuk mengurangkan dengan ketara overfitting dan memainkan peranan penting dalam kemenangannya dalam pertandingan ILSVRC 2012. Cukuplah untuk mengatakan, tanpa keciciran, kemajuan yang sedang kita lihat dalam pembelajaran mendalam mungkin telah ditangguhkan selama bertahun-tahun.
Sejak pengenalan keciciran, ia telah digunakan secara meluas sebagai regularizer untuk mengurangkan overfitting dalam rangkaian saraf. Keciciran menyahaktifkan setiap neuron dengan kebarangkalian p, menghalang ciri yang berbeza daripada menyesuaikan diri antara satu sama lain. Selepas menggunakan keciciran, kerugian latihan biasanya meningkat manakala ralat ujian berkurangan, sekali gus menutup jurang generalisasi model. Pembangunan pembelajaran mendalam terus memperkenalkan teknologi dan seni bina baharu, tetapi keciciran masih wujud. Ia terus memainkan peranan dalam pencapaian AI terkini, seperti ramalan protein AlphaFold, penjanaan imej DALL-E 2, dsb., menunjukkan kepelbagaian dan keberkesanan.
Walaupun populariti keciciran berterusan, keamatannya (dinyatakan sebagai kadar penurunan p) telah menurun selama bertahun-tahun. Usaha keciciran awal menggunakan kadar penurunan lalai 0.5. Walau bagaimanapun, dalam beberapa tahun kebelakangan ini, kadar penurunan yang lebih rendah sering digunakan, seperti 0.1 Contoh yang berkaitan boleh dilihat dalam latihan BERT dan ViT. Pemacu utama aliran ini ialah ledakan data latihan yang tersedia, menjadikan overfitting semakin sukar. Digabungkan dengan faktor-faktor lain, kita mungkin akan mengalami masalah yang lebih lemah daripada overfitting.
Baru-baru ini dalam kertas kerja "Keciciran Mengurangkan Kekurangan", penyelidik dari Meta AI, University of California, Berkeley dan institusi lain menunjukkan cara menggunakan keciciran untuk menyelesaikan masalah kekurangan.
Alamat kertas: https://arxiv.org/abs/2303.01500
Mereka mula-mula melepasi norma kecerunan Kami mengkaji dinamik latihan keciciran menggunakan beberapa pemerhatian yang menarik, dan kemudian memperoleh penemuan empirikal utama: semasa peringkat awal latihan, keciciran mengurangkan varians kecerunan kumpulan mini dan membolehkan model dikemas kini ke arah yang lebih konsisten. Arah ini juga lebih konsisten dengan arah kecerunan merentas keseluruhan set data, seperti yang ditunjukkan dalam Rajah 1 di bawah.
Hasilnya, model boleh mengoptimumkan kehilangan latihan dengan lebih berkesan pada keseluruhan set latihan tanpa terjejas oleh kumpulan mini individu. Dalam erti kata lain, keciciran mengatasi keturunan kecerunan stokastik (SGD) dan menghalang penyelarasan yang berlebihan yang disebabkan oleh kerawanan kumpulan mini sampel pada awal latihan.
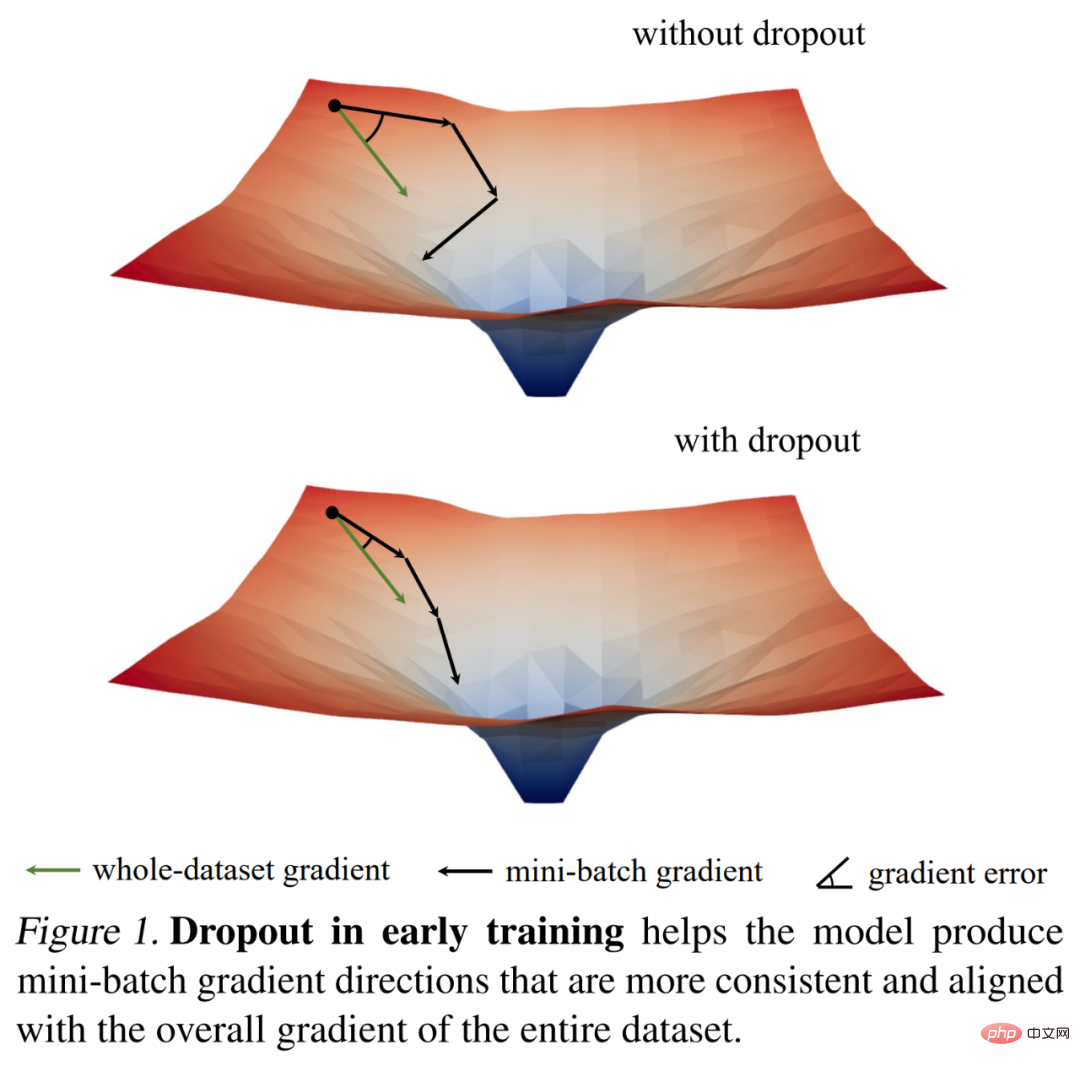
Berdasarkan penemuan ini, penyelidik mencadangkan keciciran awal (iaitu, keciciran hanya digunakan pada peringkat awal latihan) untuk membantu model Underfitted lebih sesuai. Keciciran awal mengurangkan kehilangan latihan terakhir berbanding keciciran tanpa keciciran dan keciciran standard. Sebaliknya, untuk model yang sudah menggunakan keciciran standard, penyelidik mengesyorkan mengalih keluar keciciran dalam zaman latihan awal untuk mengurangkan keterlaluan. Mereka memanggil kaedah ini keciciran lewat dan menunjukkan bahawa ia boleh meningkatkan ketepatan generalisasi model besar. Rajah 2 di bawah membandingkan keciciran standard, keciciran awal dan lewat.

Penyelidik menggunakan model yang berbeza untuk menilai keciciran awal dan keciciran lewat pada klasifikasi imej dan tugas hiliran, dan keputusan menunjukkan Kedua-duanya konsisten menghasilkan keputusan yang lebih baik daripada keciciran standard dan tiada keciciran. Mereka berharap penemuan mereka dapat memberikan cerapan baru tentang keciciran dan overfitting serta memberi inspirasi kepada pembangunan lanjut pengatur rangkaian saraf.
Analisis dan Pengesahan
Sebelum mencadangkan keciciran awal dan keciciran lewat, kajian ini meneroka sama ada keciciran boleh digunakan sebagai alat untuk mengurangkan kekurangan. Kajian ini melakukan analisis terperinci tentang dinamik latihan keciciran menggunakan alat dan metrik yang dicadangkan, dan membandingkan proses latihan dua ViT-T/16 pada ImageNet (Deng et al., 2009): satu tanpa keciciran sebagai garis dasar; yang lain Seorang mempunyai kadar keciciran 0.1 sepanjang latihan.
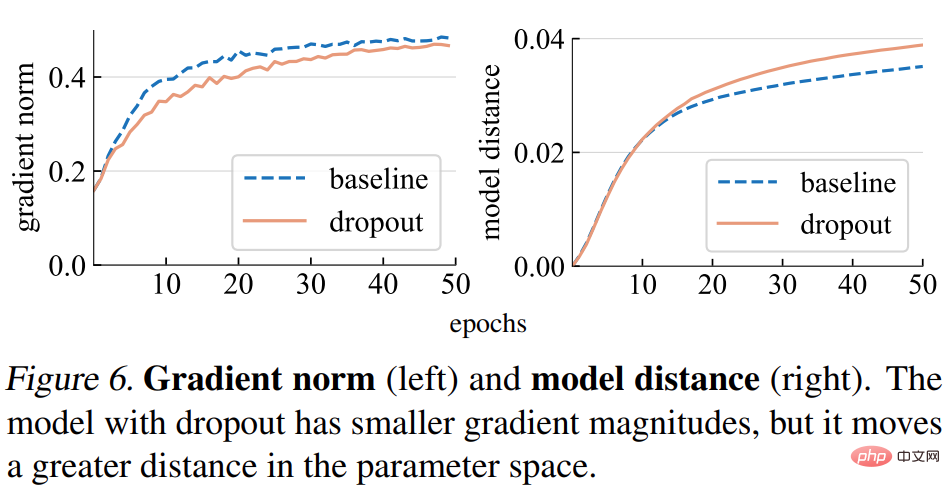
Norma kecerunan (norma). Kajian ini terlebih dahulu menganalisis kesan keciciran terhadap kekuatan kecerunan g. Seperti yang ditunjukkan dalam Rajah 6 (kiri) di bawah, model tercicir menghasilkan kecerunan dengan norma yang lebih kecil, menunjukkan bahawa ia mengambil langkah yang lebih kecil dengan setiap kemas kini kecerunan.
Jarak model. Memandangkan saiz langkah kecerunan adalah lebih kecil, kami menjangkakan model keciciran bergerak pada jarak yang lebih kecil berbanding dengan titik awalnya daripada model garis dasar. Seperti yang ditunjukkan dalam Rajah 6 (kanan) di bawah, kajian memplot jarak setiap model daripada permulaan rawaknya. Walau bagaimanapun, yang menghairankan, model tercicir sebenarnya bergerak lebih jauh daripada model garis dasar, bertentangan dengan jangkaan asal kajian berdasarkan norma kecerunan.
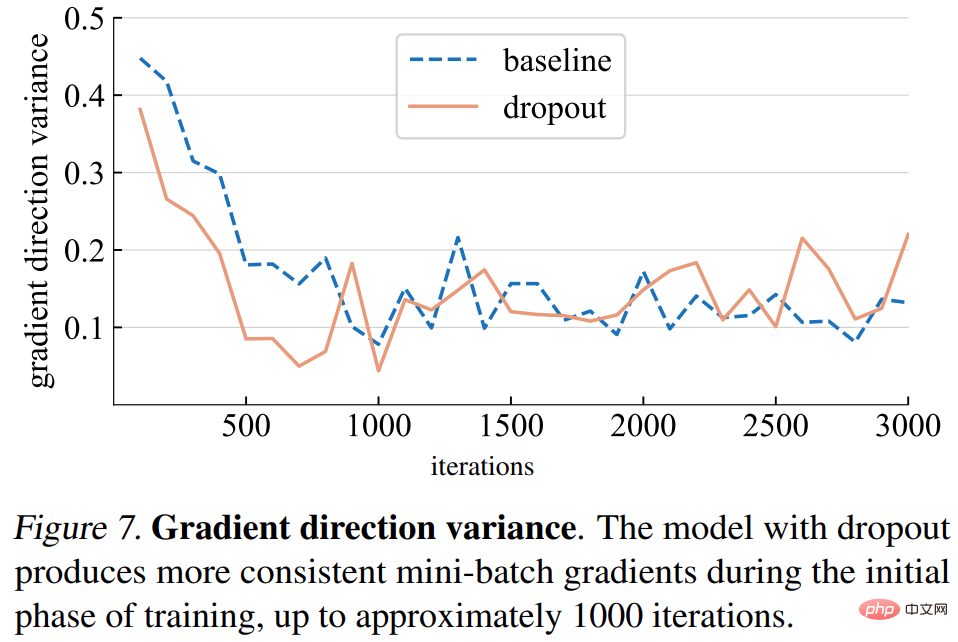
Varians arah kecerunan. Kajian itu mula-mula membuat hipotesis bahawa model tercicir menghasilkan arah kecerunan yang lebih konsisten merentas kelompok mini. Varians yang ditunjukkan dalam Rajah 7 di bawah secara amnya konsisten dengan andaian. Sehingga bilangan lelaran tertentu (kira-kira 1000), varians kecerunan bagi kedua-dua model tercicir dan model garis dasar turun naik pada tahap yang rendah.
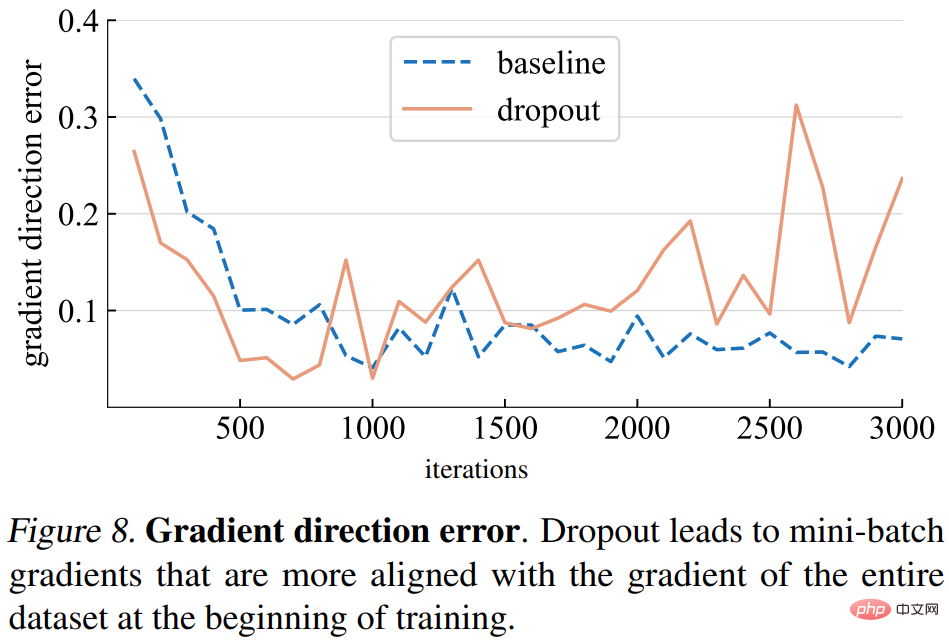
Ralat arah kecerunan. Walau bagaimanapun, apakah arah kecerunan yang sepatutnya? Untuk menyesuaikan data latihan, matlamat asas adalah untuk meminimumkan kehilangan keseluruhan set latihan, bukan hanya kehilangan mana-mana satu kumpulan mini. Kajian ini mengira kecerunan model tertentu ke atas keseluruhan set latihan, dengan keciciran ditetapkan kepada mod inferens untuk menangkap kecerunan model penuh. Ralat arah kecerunan ditunjukkan dalam Rajah 8 di bawah.
Berdasarkan analisis di atas, kajian ini mendapati bahawa menggunakan keciciran seawal mungkin berpotensi meningkatkan keupayaan model untuk sesuai dengan data latihan. Sama ada kesesuaian yang lebih baik dengan data latihan diperlukan bergantung pada sama ada model kurang muat atau terlalu muat, yang mungkin sukar untuk ditakrifkan dengan tepat. Kajian menggunakan kriteria berikut:
- Jika model digeneralisasikan dengan lebih baik di bawah keciciran standard, ia dianggap sebagai terlalu muat; Jika model berprestasi lebih baik tanpa keciciran, model itu dianggap kurang dipasang.
- Keadaan model bergantung bukan sahaja pada seni bina model, tetapi juga pada set data yang digunakan dan parameter latihan lain.
Kemudian, kajian mencadangkan dua kaedah, keciciran awal dan keciciran lewat
keciciran awal. Secara lalai, model yang kurang dipasang tidak menggunakan keciciran. Untuk meningkatkan keupayaannya untuk menyesuaikan diri dengan data latihan, kajian ini mencadangkan keciciran awal: menggunakan keciciran sebelum lelaran tertentu dan kemudian melumpuhkan keciciran semasa proses latihan yang lain. Eksperimen penyelidikan menunjukkan bahawa keciciran awal mengurangkan kehilangan latihan terakhir dan meningkatkan ketepatan.
keciciran lewat. Keciciran standard sudah disertakan dalam tetapan latihan untuk model overfitting. Pada peringkat awal latihan, keciciran mungkin secara tidak sengaja menyebabkan overfitting, yang tidak diingini. Untuk mengurangkan overfitting, kajian ini mencadangkan keciciran lewat: keciciran tidak digunakan sebelum lelaran tertentu, tetapi digunakan dalam latihan yang lain.
Kaedah yang dicadangkan dalam kajian ini adalah mudah dari segi konsep dan pelaksanaan, seperti yang ditunjukkan dalam Rajah 2. Pelaksanaan memerlukan dua hiperparameter: 1) bilangan zaman untuk menunggu sebelum menghidupkan atau mematikan keciciran 2) kadar keciciran p, yang serupa dengan kadar keciciran standard. Kajian ini menunjukkan bahawa kedua-dua hiperparameter ini dapat memastikan keteguhan kaedah yang dicadangkan.
Eksperimen dan hasil
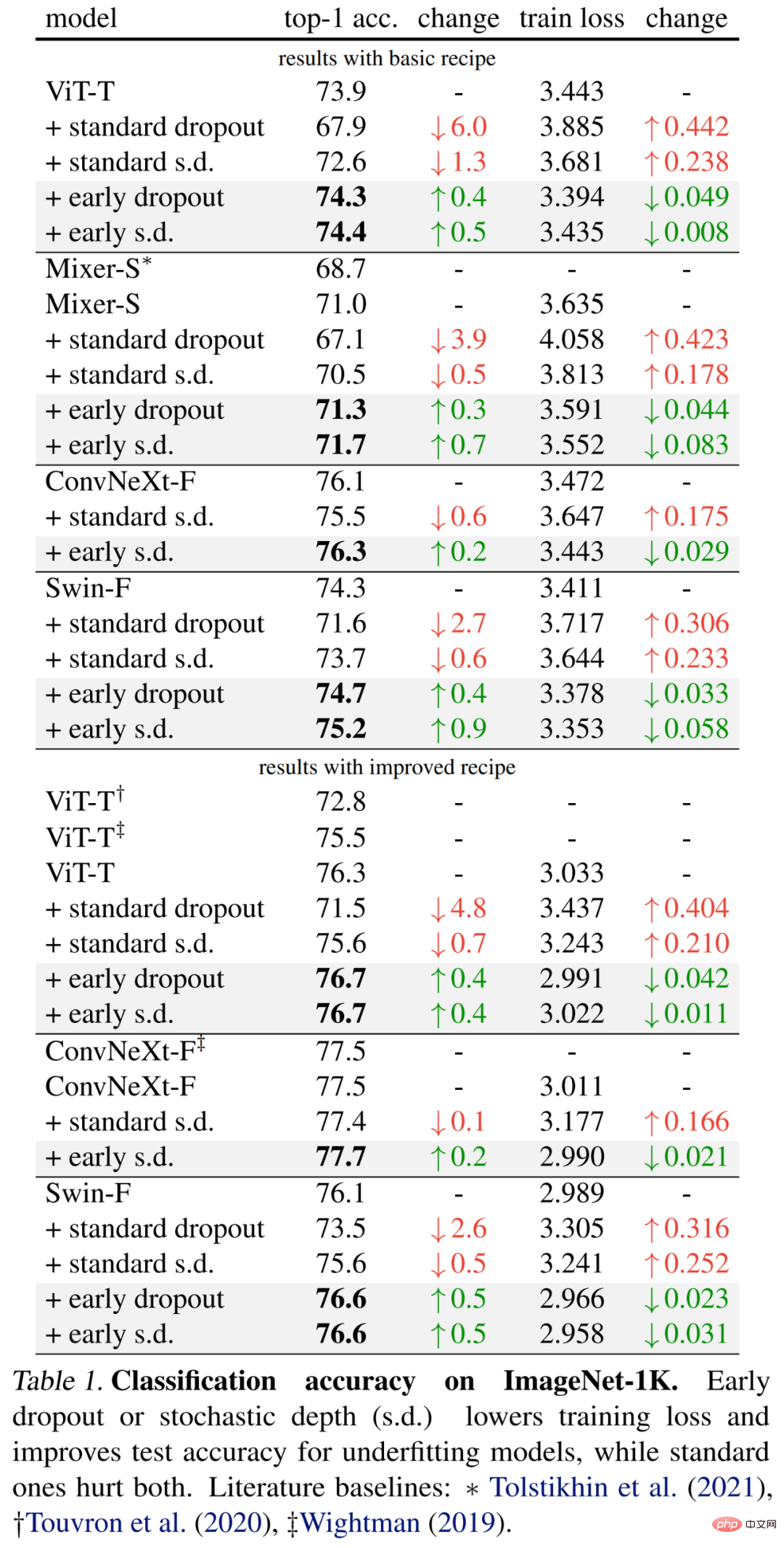
Para penyelidik menjalankan penilaian empirikal pada dataset klasifikasi ImageNet-1K dengan 1000 kelas dan imej latihan 1.2M, dan melaporkan ketepatan pengesahan 1 teratas .Keputusan khusus pertama kali ditunjukkan dalam Jadual 1 (bahagian atas) di bawah terus meningkatkan ketepatan ujian dan mengurangkan kehilangan latihan, menunjukkan bahawa keciciran pada peringkat awal membantu model sesuai. lebih baik. Para penyelidik juga menunjukkan hasil perbandingan menggunakan kadar penurunan 0.1 berbanding keciciran standard dan kedalaman stokastik (s.d.), yang kedua-duanya mempunyai kesan negatif ke atas model.
Selain itu, penyelidik menambah baik kaedah untuk model kecil ini dengan menggandakan tempoh latihan dan mengurangkan keamatan campuran dan potongan. Keputusan dalam Jadual 1 di bawah (bawah) menunjukkan peningkatan yang ketara dalam ketepatan garis dasar, kadangkala ketara melebihi hasil kerja sebelumnya.
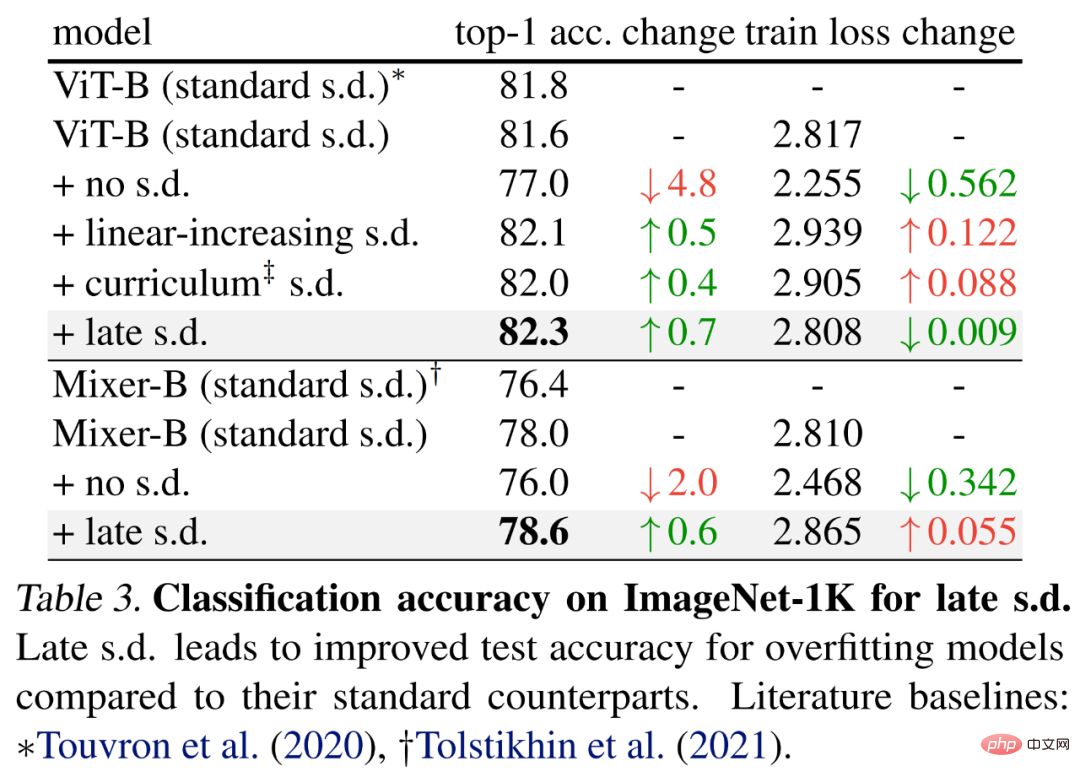
Untuk menilai keciciran lewat, penyelidik memilih model yang lebih besar, iaitu ViT-B dan Mixer-B dengan parameter 59M dan 86M masing-masing, menggunakan asas kaedah latihan.
Keputusan ditunjukkan dalam Jadual 3 di bawah. Berbanding dengan s.d standard, s.d lewat meningkatkan ketepatan ujian. Penambahbaikan ini dicapai sambil mengekalkan ViT-B atau meningkatkan kehilangan latihan Mixer-B, menunjukkan bahawa lewat s.d berkesan mengurangkan overfitting.
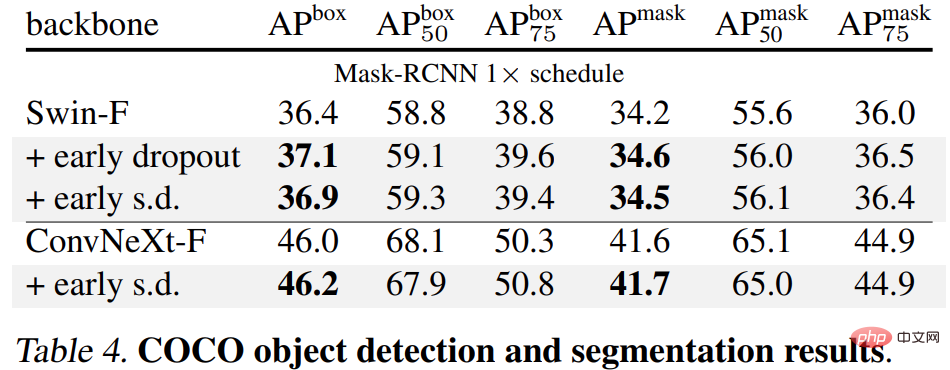
Akhir sekali, penyelidik memperhalusi model ImageNet-1K yang telah terlatih pada tugas hiliran dan menilainya . Tugas hiliran termasuk pengesanan dan pembahagian objek COCO, pembahagian semantik ADE20K dan pengelasan hiliran pada lima set data termasuk C-100. Matlamatnya adalah untuk menilai perwakilan yang dipelajari semasa fasa penalaan halus tanpa menggunakan keciciran awal atau keciciran lewat.
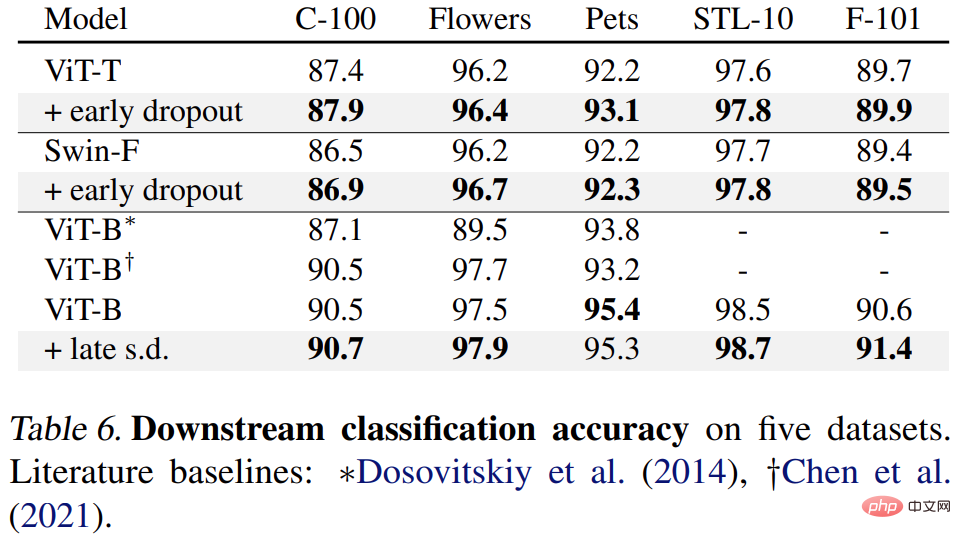
Keputusan ditunjukkan dalam Jadual 4, 5 dan 6 di bawah Pertama, apabila diperhalusi pada COCO, model yang dilatih menggunakan keciciran awal atau s.d sentiasa mengekalkan kelebihan.
Kedua, untuk tugas pembahagian semantik ADE20K, model yang telah dilatih menggunakan kaedah ini adalah lebih baik daripada model garis dasar .
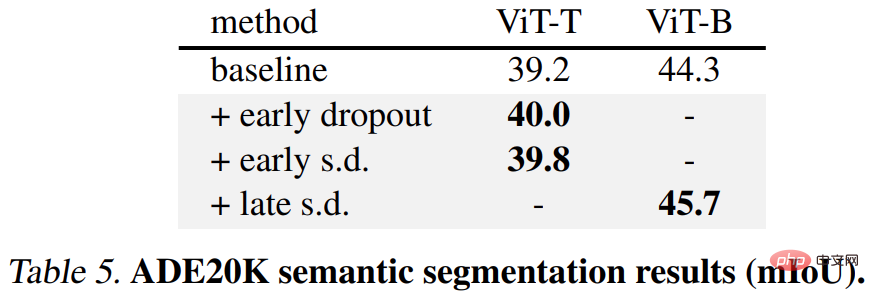
Akhir sekali, terdapat tugas pengelasan hiliran Kaedah ini meningkatkan prestasi generalisasi pada kebanyakan tugas pengelasan.
Untuk butiran lanjut teknikal dan keputusan percubaan, sila rujuk kertas asal.
Atas ialah kandungan terperinci Penambahbaikan Keciciran boleh digunakan untuk mengurangkan masalah yang tidak sesuai.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI